16. Загрузка данных
В этой главе мы загрузим наборы данных из сетевого источника и создадим работоспособные визуализации этих данных. В Интернете можно найти невероятно разнообразную информацию, бульшая часть которой еще не подвергалась основательному анализу. Умение анализировать данные позволит вам выявить связи и закономерности, не найденные никем другим.
В этой главе рассматривается работа с данными в двух популярных форматах, CSV и JSON. Модуль Python csv будет применен для обработки погодных данных в формате CSV (с разделением запятыми) и анализа динамики высоких и низких температур в двух разных местах. Затем библиотека matplotlib будет использована для построения на базе загруженных данных диаграммы изменения температур. Позднее в этой главе модуль json будет использован для обращения к данным численности населения, хранимым в формате JSON, а при помощи модуля Pygal будет построена карта распределения населения по странам.
К концу этой главы вы будете готовы к работе с разными типами и форматами наборов данных и начнете лучше понимать принципы построения сложных визуализаций. Возможность загрузки и визуализации сетевых данных разных типов и форматов крайне важна для работы с разнообразными массивами данных в реальном мире.
Формат CSV
Один из простейших вариантов хранения — запись данных в текстовый файл как серий значений, разделенных запятыми; такой формат хранения получил название CSV (от Comma Separated Values, то есть «значения, разделенные запятыми»). Например, одна строка погодных данных в формате CSV может выглядеть так:
2014-1-5,61,44,26,18,7,-1,56,30,9,30.34,30.27,30.15,,,,10,4,,0.00,0,,195
Это погодные данные за 5 января 2014 г. в Ситке (Аляска). В данных указаны максимальная и минимальная температуры, а также ряд других показателей за этот день. У человека могут возникнуть проблемы с чтением данных CSV, но этот формат хорошо подходит для программной обработки и извлечения значений, а это ускоряет процесс анализа.
Начнем с небольшого набора погодных данных в формате CSV, записанного в Ситке; файл с данными можно загрузить среди ресурсов книги по адресу https://www.nostarch.com/pythoncrashcourse/. Скопируйте файл sitka_weather_07-2014.csv в каталог, в котором сохраняются программы этой главы. (После загрузки ресурсов книги в вашем распоряжении появятся все необходимые файлы для этого проекта.)
Примечание
Погодные данные для этого проекта были загружены с сайта http://www.wunderground.com/history/.
Разбор заголовка файлов CSV
Модуль Python csv из стандартной библиотеки разбирает строки файла CSV и позволяет быстро извлечь нужные значения. Начнем с первой строки файла, которая содержит серию заголовков данных:
highs_lows.py
import csv
filename = 'sitka_weather_07-2014.csv'
(1) with open(filename) as f:
(2) . .reader = csv.reader(f)
(3) . .header_row = next(reader)
. .print(header_row)
После импортирования модуля csv имя обрабатываемого файла сохраняется в переменной filename. Затем файл открывается, а полученный объект сохраняется в переменной f (1) . Далее программа вызывает метод csv.reader() и передает ему объект файла в аргументе, чтобы создать объект чтения данных для этого файла (2). Объект чтения данных сохраняется в переменной reader.
Модуль csv содержит функцию next(), которая возвращает следующую строку файла для полученного объекта чтения данных. В следующем листинге функция next() вызывается только один раз для получения первой строки файла, содержащей заголовки (3). Возвращенные данные сохраняются в header_row. Как видите, header_row содержит осмысленные имена заголовков, которые сообщают, какая информация содержится в каждой строке данных:
['AKDT', 'Max TemperatureF', 'Mean TemperatureF', 'Min TemperatureF',
'Max Dew PointF', 'MeanDew PointF', 'Min DewpointF', 'Max Humidity',
' Mean Humidity', ' Min Humidity', ' Max Sea Level PressureIn',
' Mean Sea Level PressureIn', ' Min Sea Level PressureIn',
' Max VisibilityMiles', ' Mean VisibilityMiles', ' Min VisibilityMiles',
' Max Wind SpeedMPH', ' Mean Wind SpeedMPH', ' Max Gust SpeedMPH',
'PrecipitationIn', ' CloudCover', ' Events', ' WindDirDegrees']
Объект reader обрабатывает первую строку значений, разделенных запятыми, и сохраняет все значения в строке в списке. Заголовок AKDT означает «Alaska Daylight Time» (Аляска, летнее время). Позиция заголовка указывает на то, что первым значением в каждой из следующих строк является дата или время. Заголовок Max TemperatureF сообщает, что второе значение в каждой строке содержит максимальную температуру в этот день по шкале Фаренгейта. По именам заголовков можно определить, какая информация хранится в файле.
Примечание
Форматирование заголовков не всегда последовательно; иногда встречаются лишние пробелы, единицы измерения находятся в неожиданных местах. В необработанных файлах данных это бывает достаточно часто, но не создает проблем.
Печать заголовков и их позиций
Чтобы читателю было проще понять структуру данных в файле, выведем каждый заголовок и его позицию в списке:
highs_lows.py
...
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
. .
(1) . .for index, column_header in enumerate(header_row):
. . . .print(index, column_header)
Мы применяем к списку функцию enumerate() (1) для получения индекса каждого элемента и его значения. (Обратите внимание: строка print(header_row) удалена ради этой более подробной версии.)
Результат с индексами всех заголовков выглядит так:
0 AKDT
1 Max TemperatureF
2 Mean TemperatureF
3 Min TemperatureF
...
20 CloudCover
21 Events
22 WindDirDegrees
Из этих данных видно, что даты и максимальные температуры за эти дни находятся в столбцах 0 и 1. Чтобы проанализировать температурные данные, мы обработаем каждую запись данных в файле sitka_weather_07-2014.csv и извлечем элементы с индексами 0 и 1.
Извлечение и чтение данных
Итак, нужные столбцы данных известны; попробуем прочитать часть этих данных. Начнем с чтения максимальной температуры за каждый день:
highs_lows.py
import csv
# Чтение максимальных температур из файла.
filename = 'sitka_weather_07-2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
(1) . .highs = []
(2) . .for row in reader:
(3) . . . .highs.append(row[1])
. . . .
. .print(highs)
Программа создает пустой список с именем highs (1) и перебирает остальные строки в файле (2). Объект reader продолжает с того места, на котором он остановился в ходе чтения файла CSV, и автоматически возвращает каждую строку после текущей позиции. Так как заголовок уже прочитан, цикл продолжается со второй строки, в которой начинаются фактические данные. При каждом проходе цикла значение с индексом 1 (второй столбец) присоединяется к списку highs (3).
В результате будет получен список highs со следующим содержимым:
['64', '71', '64', '59', '69', '62', '61', '55', '57', '61', '57', '59', '57',
'61', '64', '61', '59', '63', '60', '57', '69', '63', '62', '59', '57', '57',
'61', '59', '61', '61', '66']
Мы извлекли максимальную температуру для каждого дня и аккуратно сохранили полученные данные в строковом формате в списке.
Затем преобразуем строки в числа при помощи функции int(), чтобы данные можно было передать matplotlib:
highs_lows.py
...
highs = []
for row in reader:
(1) . . . .high = int(row[1])
. . . .highs.append(high)
. . . .
print(highs)
Строки преобразуются в целые числа в точке (1) перед добавлением температур в список. Результат представляет собой список максимальных температур в числовом формате:
[64, 71, 64, 59, 69, 62, 61, 55, 57, 61, 57, 59, 57, 61, 64, 61, 59, 63, 60, 57,
69, 63, 62, 59, 57, 57, 61, 59, 61, 61, 66]
Следующим шагом станет построение визуализации этих данных.
Нанесение данных на диаграмму
Для наглядного представления температурных данных мы сначала создадим простую диаграмму дневных максимумов температуры с использованием matplotlib:
highs_lows.py
import csv
from matplotlib import pyplot as plt
# Чтение максимальных температур из файла.
...
# Нанесение данных на диаграмму.
fig = plt.figure(dpi=128, figsize=(10, 6))
(1) plt.plot(highs, c='red')
# Форматирование диаграммы.
(2)plt.title("Daily high temperatures, July 2014", fontsize=24)
(3)plt.xlabel('', fontsize=16)
plt.ylabel("Temperature (F)", fontsize=16)
plt.tick_params(axis='both', which='major', labelsize=16)
plt.show()
Мы передаем при вызове plot() список highs (1) и аргумент c='red' для отображения точек красным цветом. (Максимумы будут выводиться красным цветом, а минимумы синим.) Затем указываются другие аспекты форматирования (например, размер шрифта и метки) (2), уже знакомые вам по главе 15. Так как даты еще не добавлены, метки для оси x не задаются, но вызов plt.xlabel() изменяет размер шрифта, чтобы метки по умолчанию лучше читались (3). На рис. 16.1 показана полученная диаграмма: это простой график температурных максимумов за июль 2014 г. в Ситке (штат Аляска).

Рис. 16.1. График ежедневных температурных максимумов в июле 2014 г. в Ситке (штат Аляска)
Модуль datetime
Теперь нанесем даты на график, чтобы с ним было удобнее работать. Первая дата из файла погодных данных хранится во второй строке файла:
2014-7-1,64,56,50,53,51,48,96,83,58,30,19,...
Данные будут читаться в строковом формате, поэтому нам понадобится способ преобразовать строку '2014-7-1' в объект, представляющий эту дату. Чтобы построить объект, соответствующий 1 июля 2014 года, мы воспользуемся методом strptime() из модуля datetime. Посмотрим, как работает strptime() в терминальном окне:
>>> from datetime import datetime
>>> first_date = datetime.strptime('2014-7-1', '%Y-%m-%d')
>>> print(first_date)
2014-07-01 00:00:00
Сначала необходимо импортировать класс datetime из модуля datetime. Затем вызывается метод strptime(), первый аргумент которого содержит строку с датой. Второй аргумент сообщает Python, как отформатирована дата. В данном примере значение '%Y-' сообщает Python, что часть строки, предшествующая первому дефису, должна интерпретироваться как год из четырех цифр; '%m-' приказывает Python интерпретировать часть строки перед вторым дефисом как число, представляющее месяц; наконец, '%d' приказывает Python интерпретировать последнюю часть строки как день месяца от 1 до 31.
Метод strptime() может получать различные аргументы, которые описывают, как должна интерпретироваться запись даты. В табл. 16.1 перечислены некоторые из таких аргументов.
Таблица 16.1. Аргументы форматирования даты и времени из модуля datetime
|
Аргумент |
Описание |
|
%A |
Название дня недели — например, Monday |
|
%B |
Название месяца — например, January |
|
%m |
Порядковый номер месяца (от 01 до 12) |
|
%d |
День месяца (от 01 до 31) |
|
%Y |
Год из четырех цифр (например, 2015) |
|
%y |
Две последние цифры года (например, 15) |
|
%H |
Часы в 24-часовом формате (от 00 до 23) |
|
%I |
Часы в 12-часовом формате (от 01 до 12) |
|
%p |
AM или PM |
|
%M |
Минуты (от 00 до 59) |
|
%S |
Секунды (от 00 до 59) |
Представление дат на диаграмме
Научившись обрабатывать данные в файлах CSV, вы сможете улучшить диаграмму температурных данных. Для этого мы извлечем из файла даты ежедневных максимумов и передадим даты и максимумы функции plot():
highs_lows.py
import csv
from datetime import datetime
from matplotlib import pyplot as plt
# Чтение дат и температурных максимумов из файла.
filename = 'sitka_weather_07-2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
. .
(1) . .dates, highs = [], []
for row in reader:
(2) . . . .current_date = datetime.strptime(row[0], "%Y-%m-%d")
. . . .dates.append(current_date)
. . . .
high = int(row[1])
highs.append(high)
# Нанесение данных на диаграмму.
fig = plt.figure(dpi=128, figsize=(10, 6))
(3)plt.plot(dates, highs, c='red')
# Форматирование диаграммы.
plt.title("Daily high temperatures, July 2014", fontsize=24)
plt.xlabel('', fontsize=16)
(4)fig.autofmt_xdate()
plt.ylabel("Temperature (F)", fontsize=16)
plt.tick_params(axis='both', which='major', labelsize=16)
plt.show()

Рис. 16.2. График с датами на оси x стал более понятным
Мы создаем два пустых списка для хранения дат и температурных максимумов из файла (1) . Затем программа преобразует данные, содержащие информацию даты (row[0]), в объект datetime (2), который присоединяется к dates. Значения дат и температурных максимумов передаются plot() в точке (3). Вызов fig.autofmt_xdate() в точке (4) выводит метки дат по диагонали, чтобы они не перекрывались. На рис. 16.2 изображена новая версия графика.
Расширение временного диапазона
Итак, график успешно создан. Добавим на него новые данные для получения более полной картины погоды в Ситке. Скопируйте файл sitka_weather_2014.csv, содержащий погодные данные для Ситки за целый год, в каталог с программами этой главы.
А теперь мы можем сгенерировать график с погодными данными за год:
highs_lows.py
...
# Чтение дат и температурных максимумов из файла.
(1) filename = 'sitka_weather_2014.csv'
with open(filename) as f:
...
# Форматирование диаграммы.
(2)plt.title("Daily high temperatures - 2014", fontsize=24)
plt.xlabel('', fontsize=16)
...
Значение filename изменено, чтобы в программе использовался новый файл данных sitka_weather_2014.csv (1) , а заголовок диаграммы приведен в соответствие с содержимым (2).
На рис. 16.3 изображена полученная диаграмма.

Рис. 16.3. Данные за год
Нанесение на диаграмму второй серии данных
Обновленный график на рис. 16.3 содержит значительное количество полезных данных, но график можно сделать еще полезнее, добавив на него данные температурных минимумов. Для этого необходимо прочитать температурные минимумы из файла данных и нанести их на график:
highs_lows.py
...
# Чтение дат, температурных максимумов и минимумов из файла.
filename = 'sitka_weather_2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
. .
(1) . .dates, highs, lows = [], [], []
for row in reader:
current_date = datetime.strptime(row[0], "%Y-%m-%d")
dates.append(current_date)
. . . .
high = int(row[1])
highs.append(high)
. . . .
(2) . . . .low = int(row[3])
. . . .lows.append(low)
# Нанесение данных на диаграмму.
fig = plt.figure(dpi=128, figsize=(10, 6))
plt.plot(dates, highs, c='red')
(3)plt.plot(dates, lows, c='blue')
# Формат диаграммы.
x plt.title("Daily high and low temperatures - 2014", fontsize=24)
...

Рис. 16.4. Две серии данных на одной диаграмме
В точке (1) создается пустой список lows для хранения температурных минимумов, после чего программа извлекает и сохраняет температурный минимум для каждой даты из четвертой позиции каждой строки данных (row[3]) (2). В точке (3) добавляется вызов plot() для температурных минимумов, которые окрашиваются в синий цвет. Затем остается лишь обновить заголовок диаграммы (4).
На рис. 16.4 изображена полученная диаграмма.
Цветовое выделение части диаграммы
После добавления двух серий данных можно переходить к анализу диапазона температур по дням. Пора сделать последний штрих в оформлении диаграммы: затушевать диапазон между минимальной и максимальной дневной температурой. Для этого мы воспользуемся методом fill_between(), который получает серию значений x и две серии значений y и заполняет область между двумя значениями y:
highs_lows.py
...
# Нанесение данных на диаграмму.
fig = plt.figure(dpi=128, figsize=(10, 6))
(1) plt.plot(dates, highs, c='red', alpha=0.5)
plt.plot(dates, lows, c='blue', alpha=0.5)
(2)plt.fill_between(dates, highs, lows, facecolor='blue', alpha=0.1)
...
Аргумент alpha (1) определяет степень прозрачности вывода. Значение 0 означает полную прозрачность, а 1 (по умолчанию) — полную непрозрачность. Со значением alpha=0.5 красные и синие линии на графике становятся более светлыми.
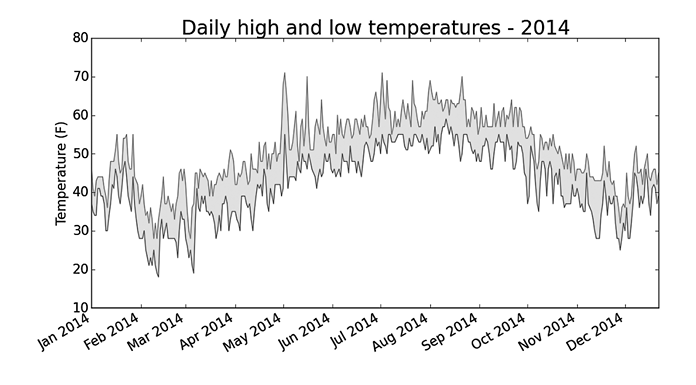
Рис. 16.5. Область между двумя наборами данных закрашена
В точке (2) fill_between() передается список dates для значений x и две серии значений y highs и lows. Аргумент facecolor определяет цвет закрашиваемой области; мы назначаем ему низкое значение alpha=0.1, чтобы заполненная область соединяла две серии данных, не отвлекая зрителя от передаваемой информации. На рис. 16.5 показана диаграмма с закрашенной областью между highs и lows.
Закрашенная область подчеркивает величину расхождения между двумя наборами данных.
Проверка ошибок
Программа highs_lows.py должна нормально работать для погодных данных любого места. Однако на некоторых метеорологических станциях происходят сбои, и станциям не удается собрать данные (полностью или частично). Отсутствие данных может привести к исключениям; если исключения не будут обработаны, то программа аварийно завершится.
Для примера попробуем построить график температур для Долины Смерти (штат Калифорния). Скопируйте файл death_valley_2014.csv в каталог с программами этой главы, после чего внесите изменения в highs_lows.py для работы с другим набором данных:
highs_lows.py
...
# Чтение дат, температурных максимумов и минимумов из файла.
filename = 'death_valley_2014.csv'
with open(filename) as f:
...
При запуске программы происходит ошибка, как видно из последней строки следующего вывода:
Traceback (most recent call last):
File "highs_lows.py", line 17, in
. .high = int(row[1])
ValueError: invalid literal for int() with base 10: ''
Трассировка показывает, что Python не может обработать максимальную температуру для одной из дат, потому что не может преобразовать пустую строку ('') в целое число. Чтобы понять причину, достаточно заглянуть в файл death_valley_2014.csv:
2014-2-16,,,,,,,,,,,,,,,,,,,0.00,,,-1
Похоже, 16 февраля 2014 года данные не сохранялись; строка максимальной температуры пуста. Чтобы решить проблему, мы будем выполнять проверку ошибок при чтении данных из файла для обработки исключений, которые могут возникнуть при разборе наборов данных. Вот как это делается:
highs_lows.py
...
# Чтение дат, температурных максимумов и минимумов из файла.
filename = 'death_valley_2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
dates, highs, lows = [], [], []
for row in reader:
(1) . . . .try:
. . . . . .current_date = datetime.strptime(row[0], "%Y-%m-%d")
. . . . . .high = int(row[1])
. . . . . .low = int(row[3])
. . . .except ValueError:
(2) . . . . . .print(current_date, 'missing data')
. . . .else:
(3) . . . . . .dates.append(current_date)
. . . . . .highs.append(high)
. . . . . .lows.append(low)
# Plot data.
...
# Форматирование диаграммы
(4)title = "Daily high and low temperatures - 2014\nDeath Valley, CA"
plt.title(title, fontsize=20)
...
При анализе каждой строки данных мы пытаемся извлечь дату, максимальную и минимальную температуру (1) . Если каких-либо данных не хватает, Python выдает ошибку ValueError, а мы обрабатываем ее — выводим сообщение с датой, для которой отсутствуют данные (2). После вывода ошибки цикл продолжает обработку следующей порции данных. Если все данные, относящиеся к некоторой дате, прочитаны без ошибок, выполняется блок else, а данные присоединяются к соответствующим спискам (3). Так как на диаграмме отображается информация для нового места, заголовок изменяется, и в него включается название места (4).

Рис. 16.6. Максимальная и минимальная температура в Долине Смерти
При выполнении highs_lows.py мы видим, что данные отсутствуют только для одной даты:
2014-02-16 missing data
Полученная диаграмма изображена на рис. 16.6.
Сравнивая эту диаграмму с диаграммой для Ситки, мы видим, что в Долине Смерти теплей, чем на юго-востоке Аляски (как и следовало ожидать), но при этом температурный диапазон в пустыне более широкий. Высота закрашенной области наглядно демонстрирует этот факт.
Во многих наборах данных, с которыми вы будете работать, будут встречаться отсутствующие, неправильно отформатированные или некорректные данные. В таких ситуациях воспользуйтесь теми инструментами, которые вы освоили в первой половине книги. В данном примере для обработки отсутствующих данных использовался блок try-except-else. Иногда команда continue используется для пропуска части данных, или же данные удаляются после извлечения вызовом remove() или del. Используйте любое работающее решение — лишь бы в результате у вас получилась осмысленная, точная визуализация.
Упражнения
16-1. Сан-Франциско: к какому месту ближе температура в Сан-Франциско: к Ситке или Долине Смерти? Постройте температурную диаграмму для Сан-Франциско и сравните. (Погодные данные практически для любого места можно загрузить по адресу http://www.wunderground.com/history/. Введите название места и диапазон дат, прокрутите страницу и найдите ссылку Comma-Delimited File. Щелкните правой кнопкой мыши на ссылке и сохраните данные в файле CSV.)
16-2. Сравнение Ситки с Долиной Смерти: разные масштабы температур отражают разные диапазоны данных. Чтобы точно сравнить температурный диапазон в Ситке с температурным диапазоном Долины Смерти, необходимо установить одинаковый масштаб по оси y. Измените параметры оси y для одной или обеих диаграмм на рис. 16.5 и 16.6 и проведите прямое сравнение температурных диапазонов в этих двух местах (или любых других, которые вас интересуют). Также можно попробовать нанести два набора данных на одну диаграмму.
16-3. Осадки: выберите любое место и постройте диаграмму с уровнем осадков. Для начала ограничьтесь данными за один месяц, а когда ваш код заработает, выполните программу для данных за полный год.
16-4. Исследования: постройте еще несколько визуализаций, отражающих любые другие аспекты погоды для интересующих вас мест.
Формат JSON
В этом разделе мы загрузим данные о странах в формате JSON и будем работать с ними при помощи модуля json. Используя удобные средства Pygal для работы с географическими данными, мы построим визуализации, отражающие распределение населения по странам.
Загрузка демографических данных
Скопируйте файл population_data.json, содержащий данные о численности населения большинства стран мира с 1960 по 2010 год, в каталог с программами этой главы. Информация взята из многочисленных наборов данных, бесплатно публикуемых фондом Open Knowledge Foundation (http://data.okfn.org/).
Извлечение необходимых данных
Взглянем на файл population_data.json и попробуем понять, как взяться за обработку данных файла:
population_data.json
[
{
. ."Country Name": "Arab World",
. ."Country Code": "ARB",
. ."Year": "1960",
. ."Value": "96388069"
},
{
. ."Country Name": "Arab World",
. ."Country Code": "ARB",
. ."Year": "1961",
. ."Value": "98882541.4"
},
...
]
Фактически перед нами один длинный список Python. Каждый элемент списка представляет собой словарь с четырьмя ключами: название страны (Country Name), код страны (Country Code), год (Year) и значение (Value), представляющее численность населения. В нашей программе будут использоваться названия стран и численность населения только за 2010 год, поэтому для начала напишем программу, которая выводит только эту информацию:
world_population.py
import json
# Список заполняется данными.
filename = 'population_data.json'
with open(filename) as f:
(1) . .pop_data = json.load(f)
# Вывод населения каждой страны за 2010 год.
(2)for pop_dict in pop_data:
(3) . .if pop_dict['Year'] == '2010':
(4) . . . .country_name = pop_dict['Country Name']
. . . .population = pop_dict['Value']
. . . .print(country_name + ": " + population)
Сначала программа импортирует модуль json, чтобы иметь возможность загружать данные из файла. Загруженные данные сохраняются в списке pop_data (1) . Функция json.load() преобразует данные в формат, с которым может работать Python: в данном случае это список. В точке (2) создается цикл, перебирающий все элементы pop_data. Каждый элемент представляет собой словарь с четырьмя парами «ключ—значение», который сохраняется в переменной pop_dict.
В точке (3) ключ 'Year' каждого словаря проверяется на значение 2010. (Так как все значения population_data.json заключены в кавычки, выполняется сравнение строк.) Если словарь относится к 2010 году, то значение, связанное с ключом 'Country Name', сохраняется в переменной country_name, а значение, связанное с ключом 'Value', сохраняется в переменной population (4). Затем программа выводит название каждой страны и ее население.
Программа выводит последовательность названий стран и численности их населения:
Arab World: 357868000
Caribbean small states: 6880000
East Asia & Pacific (all income levels): 2201536674
...
Zimbabwe: 12571000
Не все данные включают точные названия стран, но это неплохое начало для дальнейшей работы. Теперь данные необходимо преобразовать в формат, с которым может работать Pygal.
Преобразование строк в числовые значения
Все ключи и значения в population_data.json хранятся в строковом формате. Чтобы работать с данными численности населения, необходимо преобразовать строковые значения в числа. Для этого в программе используется функция int():
world_population.py
...
for pop_dict in pop_data:
if pop_dict['Year'] == '2010':
country_name = pop_dict['Country Name']
(1) . . . .population = int(pop_dict['Value'])
(2) . . . .print(country_name + ": " + str(population))
После преобразования (1) все данные численности населения хранятся в числовом формате. При выводе численность населения должна быть преобразована в строку (2). Впрочем, для некоторых значений это изменение приводит к ошибке:
Arab World: 357868000
Caribbean small states: 6880000
East Asia & Pacific (all income levels): 2201536674
...
Traceback (most recent call last):
File "print_populations.py", line 12, in
. .population = int(pop_dict['Value'])
(1) ValueError: invalid literal for int() with base 10: '1127437398.85751'
Необработанные данные часто форматируются непоследовательно, поэтому ошибки в них встречаются достаточно часто. В данном случае ошибка происходит из-за того, что Python не может преобразовать строку с дробным значением '1127437398.85751' в целое число (1) . (Вероятно, дробное значение было получено в результате интерполяции в те годы, в которые перепись населения не производилась.) Чтобы решить эту проблему, мы сначала преобразуем строку в вещественное число, а затем преобразуем вещественное число в целое:
world_population.py
...
for pop_dict in pop_data:
if pop_dict['Year'] == '2010':
country = pop_dict['Country Name']
. . . .population = int(float(pop_dict['Value']))
print(country + ": " + str(population))
Функция float() преобразует строку в целое число, а функция int() отсекает дробную часть и возвращает целое число. Теперь можно вывести полный набор данных численности населения за 2010 год без ошибок:
Arab World: 357868000
Caribbean small states: 6880000
East Asia & Pacific (all income levels): 2201536674
...
Zimbabwe: 12571000
Каждая строка успешно преобразуется сначала в вещественное, а затем в целое число. Обратите внимание: данные хранятся в числовом формате, чтобы их можно было использовать для построения карты распределения населения.
Получение кодов стран
Прежде чем переходить к построению карты, необходимо разобраться еще с одним аспектом данных. Инструментарий Pygal для работы с географическими картами ожидает получить данные в четко определенном формате: страны должны задаваться кодами стран, а численность населения — значениями. Существует несколько стандартных наборов кодов стран, часто применяемых при работе с геополитическими данными; коды, включенные в population_data.json, состоят из трех букв, но Pygal использует систему с двухбуквенными кодами. Нужно найти способ получения двухбуквенных кодов стран по их названиям.
Коды стран Pygal хранятся в модуле i18n (сокращение от «internationalization»). В словаре COUNTRIES двухбуквенные коды стран являются ключами, а названия стран — значениями. Чтобы просмотреть коды, импортируйте словарь из модуля i18n и выведите его ключи и значения:
countries.py
from pygal.i18n import COUNTRIES
(1) for country_code in sorted(COUNTRIES.keys()):
. .print(country_code, COUNTRIES[country_code])
В цикле for ключи сортируются в алфавитном порядке (1) . Затем программа выводит каждый код страны и страну, с которой этот код связан:
ad Andorra
ae United Arab Emirates
af Afghanistan
...
zw Zimbabwe
Напишем функцию, которая перебирает COUNTRIES и возвращает коды стран. Функция будет размещаться в отдельном модуле с именем country_codes, чтобы ее можно было позднее импортировать в программу визуализации:
country_codes.py
from pygal.i18n import COUNTRIES
(1) def get_country_code(country_name):
. ."""Возвращает для заданной страны ее код Pygal, состоящий из 2 букв."""
(2) . .for code, name in COUNTRIES.items():
(3) . . . .if name == country_name:
. . . . . .return code
. .# Если страна не найдена, вернуть None.
(4) . .return None
. . . . . .
print(get_country_code('Andorra'))
print(get_country_code('United Arab Emirates'))
print(get_country_code('Afghanistan'))
Название страны передается функции get_country_code() и сохраняется в параметре country_name (1) . Затем программа перебирает пары «код—название» в COUNTRIES (2). Если название страны будет найдено, функция возвращает код страны (3), а если нет — после цикла добавляется строка, возвращающая None (4). Наконец, программа передает названия трех стран для проверки функции. Как и ожидалось, программа выводит три двухбуквенных кода:
ad
ae
af
Прежде чем переходить к использованию функции, удалите три команды print из country_codes.py.
Затем функция get_country_code() импортируется в world_population.py:
world_population.py
import json
from country_codes import get_country_code
...
# Вывод населения каждой страны за 2010 год.
for pop_dict in pop_data:
if pop_dict['Year'] == '2010':
country_name = pop_dict['Country Name']
population = int(float(pop_dict['Value']))
(1) . . . .code = get_country_code(country_name)
. . . .if code:
(2) . . . . . .print(code + ": "+ str(population))
(3) . . . .else:
. . . . . .print('ERROR - ' + country_name)
После извлечения названия и населения в code сохраняется код страны — или None, если код недоступен (1) . Если код получен, то код и население страны выводятся командой print (2). Если код недоступен, выводится сообщение об ошибке с названием страны, для которого не удалось найти код (3). Запустите программу, и вы увидите коды стран с населением и несколько сообщений об ошибках:
ERROR - Arab World
ERROR - Caribbean small states
ERROR - East Asia & Pacific (all income levels)
...
af: 34385000
al: 3205000
dz: 35468000
...
ERROR - Yemen, Rep.
zm: 12927000
zw: 12571000
Ошибки происходят по двум причинам. Во-первых, классификация в наборе данных не всегда осуществляется по странам; часть статистики относится к регионам или экономическим группам. Во-вторых, в части статистики используется другая запись полных названий стран (Yemen, Rep. вместо Yemen). Пока опустим данные стран, вызывающие ошибки, и посмотрим, как будет выглядеть карта с успешно прочитанными данными.
Построение карты мира
С имеющимися кодами стран карта мира строится легко и просто. В Pygal поддерживается тип диаграммы Worldmap, упрощающий работу с географическими наборами данных. В качестве примера использования Worldmap мы создадим простую карту с данными по Северной, Центральной и Южной Америке:
americas.py
import pygal
(1) wm = pygal.Worldmap()
wm.title = 'North, Central, and South America'
(2)wm.add('North America', ['ca', 'mx', 'us'])
wm.add('Central America', ['bz', 'cr', 'gt', 'hn', 'ni', 'pa', 'sv'])
wm.add('South America', ['ar', 'bo', 'br', 'cl', 'co', 'ec', 'gf',
. .'gy', 'pe', 'py', 'sr', 'uy', 've'])
. .
(3)wm.render_to_file('americas.svg')
В точке (1) мы создаем экземпляр класса Worldmap и задаем атрибут title объекта карты. В точке (2) используется метод add(), который получает метку и список кодов стран, на которых вы хотите сосредоточиться. Каждый вызов add() создает новый цвет для набора стран и добавляет этот цвет в список условных обозначений в левой части диаграммы с заданным текстом. Весь регион Северной Америки будет представлен одним цветом, поэтому мы включаем коды 'ca', 'mx' и 'us' в список, передаваемый первому вызову add(), для единого представления на карте Канады, Мексики и Соединенных Штатов. Затем то же самое делается для стран Центральной и Южной Америки.
Метод render_to_file() в точке (3) создает файл .svg с диаграммой; вы можете открыть этот файл в своем браузере. На полученной карте Северная, Центральная и Южная Америка выделены другими цветами (рис. 16.7).

Рис. 16.7. Простой экземпляр диаграммы Worldmap
Теперь вы знаете, как создать карту с цветными областями, условные обозначения и аккуратные метки. Добавим на карту данные для вывода информации о стране.
Нанесение числовых данных на карту мира
Чтобы потренироваться с нанесением числовых данных на карту, создайте карту с населением трех стран Северной Америки:
na_populations.py
import pygal
wm = pygal.Worldmap()
wm.title = 'Populations of Countries in North America'
(1) wm.add('North America', {'ca': 34126000, 'us': 309349000, 'mx': 113423000})
. .
wm.render_to_file('na_populations.svg')

Рис. 16.8. Численность населения стран Северной Америки
Сначала мы создаем экземпляр Worldmap и назначаем заголовок. Далее снова следует вызов add(), но на этот раз во втором аргументе передается словарь вместо списка (1) . Словарь содержит двухбуквенные коды стран Pygal (ключи) и численность населения (значения). Pygal автоматически использует числа для окраски стран от светлых (менее населенные) до темных (наиболее населенные). На рис. 16.8 показана полученная карта.
Эта карта интерактивна: если вы наведете указатель мыши на каждую страну, то увидите ее население. Добавим на карту побольше данных.
Построение полной карты населения
Чтобы нанести на карту данные численности населения для других стран, обработанные ранее данные необходимо преобразовать в формат словаря Pygal: с двухбуквенными кодами стран и численностью населения, образующими пары «ключ—значение». Добавьте следующий код в world_population.py:
world_population.py
import json
import pygal
from country_codes import get_country_code
# Список заполняется данными.
...
# Построение словаря с данными численности населения.
(1) cc_populations = {}
for pop_dict in pop_data:
if pop_dict['Year'] == '2010':
country = pop_dict['Country Name']
population = int(float(pop_dict['Value']))
code = get_country_code(country)
if code:
(2) . . . . . .cc_populations[code] = population
(3)wm = pygal.Worldmap()
wm.title = 'World Population in 2010, by Country'
(4)wm.add('2010', cc_populations)
. .
wm.render_to_file('world_population.svg')
Сначала импортируется модуль pygal. В точке (1) создается пустой словарь для хранения кодов стран и численности населения в формате, принятом Pygal. В точке (2) для полученных кодов строится очередной элемент словаря cc_populations; ключом пары становится код страны, а значением — численность населения. Также из программы удаляются все команды print.
Мы создаем экземпляр Worldmap и задаем его атрибут title (3). При вызове add() передается словарь с кодами стран и значениями численности населения (4).
На рис. 16.9 изображена полученная карта.
Несколько стран, для которых данные отсутствуют, окрашены в черный цвет, но большинство стран раскрашено в соответствии с размером населения. Проблемой отсутствующих данных мы займемся позднее в этой главе, а сначала приведем тон закраски в соответствие с населением стран. В настоящее время на карте слишком

Рис. 16.9. Численность мирового населения в 2010 году
много стран окрашено в светлые тона, а стран с темной окраской всего две. Контраст между большинством стран попросту недостаточен для того, чтобы зритель мог понять, в какой стране больше или меньше население. Чтобы решить эту проблему, мы сгруппируем страны по уровням населения и окрасим каждую группу по отдельности.
Группировка стран по населению
Китай и Индия по численности населения опережают все остальные страны, поэтому нашей карте не хватает контраста. И в Китае, и в Индии проживает свыше миллиарда человек, тогда как в следующей по численности населения стране — Соединенных Штатах — население составляет около 300 миллионов. Вместо того чтобы наносить на диаграмму все страны в одной группе, разделим страны на три уровня населения: менее 10 миллионов, от 10 миллионов до 1 миллиарда и более 1 миллиарда:
world_population.py
...
# Построение словаря с данными численности населения.
cc_populations = {}
for pop_dict in pop_data:
if pop_dict['Year'] == '2010':
--snip--
if code:
cc_populations[code] = population
# Группировка стран по 3 уровням населения.
(1) cc_pops_1, cc_pops_2, cc_pops_3 = {}, {}, {}
(2)for cc, pop in cc_populations.items():
. .if pop < 10000000:
. . . .cc_pops_1[cc] = pop
. .elif pop < 1000000000:
. . . .cc_pops_2[cc] = pop
. .else:
. . . .cc_pops_3[cc] = pop
# Проверка количества стран на каждом уровне.
(3)print(len(cc_pops_1), len(cc_pops_2), len(cc_pops_3))
wm = pygal.Worldmap()
wm.title = 'World Population in 2010, by Country'
x wm.add('0-10m', cc_pops_1)
wm.add('10m-1bn', cc_pops_2)
wm.add('>1bn', cc_pops_3)
. .
wm.render_to_file('world_population.svg')
Чтобы сгруппировать страны, мы создаем пустой словарь для каждой категории (1) . Затем программа перебирает cc_populations и проверяет население каждой страны (2). Блок if-elif-else добавляет элемент в соответствующий словарь (cc_pops_1, cc_pops_2 или cc_pops_3) для каждой пары «код страны—население».

Рис. 16.10. Численность мирового населения в 2010 году
В точке (3) выводится длина каждого словаря для определения размеров групп. При нанесении данных на диаграмму (4) все три группы добавляются на диаграмму Worldmap. При запуске программы сначала выводятся размеры всех групп:
85 69 2
Вывод показывает, что существуют 85 стран с населением менее 10 миллионов, 69 стран с населением от 10 миллионов до 1 миллиарда и две особые страны с населением свыше 1 миллиарда. Разбиение получается достаточно равномерным для получения содержательной карты. Полученная карта изображена на рис. 16.10.
Три разных цвета помогают подчеркнуть различия между уровнями населения. В каждом из трех уровней страны окрашиваются от светлого к темному оттенку в соответствии с ростом численности населения.
Оформление карты мира в Pygal
Группировка стран на карте работает эффективно, но цвета по умолчанию выбираются довольно странно: например, в нашем примере Pygal выбирает схему с ярко-розовым и зеленым цветом. Директивы оформления Pygal помогут решить проблему с цветами.
В новой версии мы снова прикажем Pygal использовать один базовый цвет, но на этот раз выберем цвет и применим более выразительные оттенки для трех групп численности населения:
world_population.py
import json
import pygal
(1) from pygal.style import RotateStyle
...
# Группировка стран по 3 уровням населения.
cc_pops_1, cc_pops_2, cc_pops_3 = {}, {}, {}
for cc, pop in cc_populations.items():
. .if pop < 10000000:
. . . ....
(2)wm_style = RotateStyle('#336699')
(3)wm = pygal.Worldmap(style=wm_style)
wm.title = 'World Population in 2010, by Country'
...
Стили Pygal хранятся в модуле style, из которого программа импортирует стиль RotateStyle (1) . Этот класс получает один аргумент — цвет RGB в шестнадцатеричном формате (2). Затем Pygal выбирает цвета каждой группы на основании переданного цвета. Цвет в шестнадцатеричном формате представляет собой строку из символа решетки (#), за которым следуют шесть символов: первые два представляют красную составляющую цвета, следующие два — зеленую и последние два — синюю. Значения составляющих лежат в диапазоне от 00 (нулевая интенсивность) до FF (максимальная интенсивность). В Интернете можно легко найти приложение для экспериментов с цветами и получения соответствующих значений RGB. Цвет, используемый в данном случае (#336699), содержит немного красного (33), чуть больше зеленого (66) и еще больше синего (99). В результате RotateStyle назначается светло-синий базовый цвет для выполнения дальнейших операций.
RotateStyle возвращает объект стиля, который сохраняется в переменной wm_style. Чтобы использовать объект стиля, передайте его в именованном аргументе при создании экземпляра Worldmap (3). На рис. 16.11 изображена обновленная диаграмма.

Рис. 16.11. Три уровня численности населения в общей цветовой теме
Стилевое оформление придает карте целостный внешний вид с хорошо различимыми группами.
Осветление темы
По умолчанию Pygal использует темные темы оформления. Для печати я осветлил стиль своих диаграмм при помощи класса LightColorizedStyle. Этот класс изменяет общую тему оформления диаграммы, включая фон и метки, а также цвета отдельных стран. Чтобы использовать его, сначала необходимо импортировать стиль:
from pygal.style import LightColorizedStyle
Затем вы сможете использовать LightColorizedStyle в программе:
wm_style = LightColorizedStyle
Однако этот класс не позволяет напрямую управлять используемым цветом, поэтому Pygal выбирает базовый цвет по умолчанию. Чтобы назначить цвет, используйте LightColorizedStyle в качестве базового стиля для RotateStyle. Импортируйте LightColorizedStyle и RotateStyle:
from pygal.style import LightColorizedStyle, RotateStyle
Создайте стиль с использованием RotateStyle, но передайте дополнительный аргумент base_style:
wm_style = RotateStyle('#336699', base_style=LightColorizedStyle)
В результате для карты используется светлая общая тема, но цвета стран выбираются на основе цвета, переданного в аргументе. При использовании этого стиля ваши диаграммы будут больше похожи на снимки экрана на иллюстрациях.
Пока вы экспериментируете с поиском стилевых директив, хорошо подходящих для тех или иных визуализаций, попробуйте использовать псевдонимы в командах import:
from pygal.style import LightColorizedStyle as LCS, RotateStyle as RS
Определения стилей с псевдонимами получаются более короткими:
wm_style = RS('#336699', base_style=LCS)
Как видите, даже небольшой набор стилевых директив открывает широкие возможности для управления внешним видом диаграмм и карт в Pygal.
Упражнения
16-5. Все страны: на картах, построенных в этом разделе, наша программа не смогла автоматически найти двухбуквенные коды примерно для 12 стран. Определите, что это за страны, и найдите коды в словаре COUNTRIES. Добавьте блок if-elif в get_country_code(), чтобы функция возвращала правильные коды для этих конкретных стран:
if country_name == 'Yemen, Rep.'
return 'ye'
elif ...
Разместите этот код после цикла COUNTRIES, но перед командой return None. Когда это будет сделано, карта станет более полной.
16-6. Валовый внутренний продукт: Фонд Open Knowledge Foundation предоставляет набор данных с величиной валового внутреннего продукта (ВВП) по каждой стране мира; его можно загрузить по адресу http://data.okfn.org/data/core/gdp/. Загрузите версию этого набора данных в формате JSON и нанесите на карту ВВП каждой страны мира за самый последний год в наборе данных.
16-7. Выберите данные самостоятельно: Всемирный банк предоставляет различные наборы данных, разбитые по странам. Откройте страницу http://data.worldbank.org/indicator/ и найдите набор данных, который покажется вам интересным. Щелкните на наборе данных, щелкните по ссылке Download Data и выберите формат CSV. Вы получите три файла CSV, два из которых снабжены пометкой Metadata; используйте третий файл CSV. Напишите программу для генерирования словаря; ключами словаря являются двухбуквенные коды стран Pygal, а значениями — выбранные вами данные из файла. Нанесите данные на диаграмму Worldmap и оформите карту на свое усмотрение.
16-8. Тестирование модуля country_codes: во время разработки модуля country_codes мы использовали команды print для проверки работоспособности функции get_country_code(). Напишите нормальный тест для этой функции, используя информацию из главы 11.
Итоги
В этой главе вы научились работать с сетевыми наборами данных. Вы узнали, как обрабатывать файлы CSV и JSON и как извлечь данные, на которых вы хотите сосредоточиться. Используя реальные погодные данные, вы освоили новые возможности работы с библиотекой matplotlib, включая использование модуля datetime и возможность нанесения нескольких наборов данных на одну диаграмму. Вы узнали, как нанести данные на карту мира с использованием Pygal и как изменить оформление карт и диаграмм Pygal.
С накоплением опыта работы с файлами CSV и JSON вы сможете обрабатывать практически любые данные, которые вам потребуется проанализировать. Многие сетевые наборы данных могут загружаться хотя бы в одном из этих форматов. После работы с этими форматами вам также будет проще усвоить другие форматы данных.
В следующей главе вы напишете программы для автоматического сбора данных из сетевых источников, а затем создадите визуализации этих данных. Это занятие весьма интересное, если вы рассматриваете программирование как увлечение, и абсолютно необходимое, если вы занимаетесь программированием профессионально.
Канал с обзорами, анонсами новинок и книжными подборками
 Книжный Вестник
Книжный Вестник
Бот для удобного поиска книг (если не нашлось на сайте)
 Поиск книг
Поиск книг
Свежие любовные романы в удобных форматах
 Любовные романы
Любовные романы
О психологии, саморазвитии и личностном росте
 Саморазвитие
Саморазвитие
Детективы и триллеры, все новинки
 Детективы
Детективы
Фантастика и фэнтези, все новинки
 Фантастика
Фантастика
Отборные классические книги
 Классика
Классика
 ВКОНТАКТЕ
ВКОНТАКТЕБиблиотека с любовными романами, которая наверняка придётся по вкусу женской части аудитории
Любовные романы
Библиотека с фантастикой и фэнтези, а также смежных жанров
Фантастика
Самые популярные книги в формате фб2
Топ фб2
книги