Разработка приложений баз данных InterBase на Borland Delphi/C++ Builder/Kylix
Что такое InterBase Express?
Пользователи Borland Delphi 5-7 и Borland C++ Builder 5-6 редакций Professional и Enteiprise наверняка уже обратили внимание на закладку InterBase в палитре компонентов. Именно эта закладка и представляет собой набор компонент под общим названием InterBase Express или IBX. Это компоненты для работы с базами данных InterBase, которые используют прямое InterBase API, т. е. обращаются к серверу непосредственно, без каких-то промежуточных (middle-ware) средств.
Фактически если разрабатывать приложения баз данных с использованием IBX, то для работы таких приложений нужно лишь наличие GDS32.DLL на диске в доступном месте.
Официально разработка IBX ведется в рамках IPL - InterBase Public License, т. е. компоненты доступны в полных исходных текстах и вы можете использовать их совершенно бесплатно. Однако фактически данные компоненты разрабатываются только сотрудниками корпорации Borland, совместимы только с определенными версиями и редакциями Delphi и C++ Builder и недоступны для публичной разработки, как это принято в обычных Open Source-проектах.
Компоненты IBX позволяют разрабатывать приложения, ориентированные на идеологию и архитектуру InterBase. К особенностям IBX можно отнести:
* явное управление транзакциями;
* поддержке расширений InterBase 6.0-7.0;
* поддержку event-alerters;
* использование генераторов для значений ключевых полей;
* управление сервером через Services API;
* поддержку стандартных и сторонних визуальных компонентов отображения данных;
* поддержку встроенных и сторонних генераторов отчета;
* совместимость с Delphi 5-7, C++ Builder 5-6 и Kylix
Основой кода IBХ является библиотека FreelBComponents, написанная Грегори Дилтцом в 1998 году. Основные изменения, сделанные в Borland, касались поддержки нового стандарта идентификаторов в SQLDialect 3, а также приведение компонентов к виду, аналогичному существовавшим компонентам (мы поясним суть этой аналогии позднее). Теперь с выходом каждой очередной версии Delphi или C++ Builder IBX включается в поставку, однако все равно желательно проверять наличие исправлений или дополнительных сборок на сайте http://codecentral.borland.com.
Общее описание основных компонентов, включенных в состав IBX

TIBDatabase - предназначен для подключения к базе данных. Основные методы: Open, Close.

TIBTransaction - предназначен для явного управления транзакцией. Основные методы: StartTransaction, Commit, Rollback, CommitRetaining, RollbackRetaining.

TIBTable - аналог стандартного TTable. Компонент предназначен для получения данных из одной таблицы или представления базы данных. Основное свойство - TableName. Основные методы: Open, Close. Набор данных, полученных при помощи TIBTable, является редактируемым, если речь идет о таблице базы данных или обновляемом представлении. Компонент совместим с визуальными компонентами.

TIBQuery - аналог стандартного TQuery. Компонент предназначен для получения данных на основе SQL-запроса. Этот набор данных не всегда будет редактируемым, зачастую необходимо использовать дополнительный компонент TIBUpdateSQL, чтобы иметь возможность редактировать полученные сведения. Основное свойство - SQL. Основные методы: Open, Close, ExecSQL. Компонент совместим с визуальными компонентами.

TIBDataSet - предназначен для получения и редактирования данных, является потомком стандартного класса TDataSet и полностью совместим со всеми визуальными компонентами. Основные методы: Prepare, Open, Close, Insert, Append, Edit, Delete, Refresh.

TIBStoredProc - предназначен для выполнения хранимых процедур и получения набора данных на основе результатов выполнения процедуры. Получаемый набор данных является нередактируемым. Компонент совместим с визуальными компонентами. Основное свойство - StoredProcName. Основной метод - ЕхесРгос.

TIBUpdateSQL - аналог TUpdateSQL. Используется в паре с TIBQuery и предназначен для создания модифицируемых наборов данных. Основные свойства: DeleteSQL, InsertSQL, ModifySQL и RefreshSQL.

TIBSQL - предназначен для выполнения SQL-запросов. В отличие от TIBQuery или TIBDataSet, TIBSQL не имеет локального буфера для набора данных и несовместим с визуальными компонентами.

TIBDatabaselnfo - позволяет получить системную информацию о некоторых свойствах базы данных, соединения и сервера. Например, UserNames - список пользователей, подключенных к базе данных, PageSize - размер страницы базы данных.

TIBSQLMonitor - предназначен для перехвата и отслеживания всех запросов, которые выполняют приложения, использующие ШХ.

TIBEvents - предназначен для получения пользовательских событий InterBase. Основное свойство - Events. Основные методы: RegisterEvents, UnresisterEvents.
Компоненты-оболочки для Services API

TIBConfigService - предназначен для настройки параметров базы данных.

TIBBackupService предназначен для создания резервных копий (backup) баз данных.

TIBRestoreService - предназначен для восстановления базы данных из резервной копии.

TIBValidationService - предназначен для проверки целостности базы данных и согласования внутренних данных о транзакциях.

TIBStatisticalService - предназначен для получения статистики о базе данных.

TIBLogService - предназначен для создания и просмотра лог-файла работы сервера.

TIBSecurityService - предназначен для редактирования списка пользователей на сервере.

TIBLicensingService - предназначен для добавления и удаления сертификатов, регулирующих количество и свойства клиентских подключений к серверу InterBase.

TIBServerProperties - предназначен для получения информации о сервере, параметров конфигурации и т. д.

ТIBInstall - предназначен для установки InterBase installation-компонента.

TIBUnlnstall - предназначен для установки InterBase un-installation компонента.
Использование основных компонентов InterBase eXpress (IBX)
Исторически сложилось так, что первое издание книги не содержало материалов по IBX. То есть данная глава написана специально для второго издания. После выхода книги мы получили ряд отзывов, которые наглядно показали нам, что многие разработчики (особенно те, кто впервые работает с ЮХ или FffiPlus) не представляют, как в целом взаимодействуют компоненты ЮХ между собой. В итоге, несмотря на аккуратное воспроизведение всех примеров из главы по FffiPlus, некоторые программисты не могут ни на шаг отойти от описанных ситуаций, поскольку спотыкаются буквально на совершенно очевидных вопросах. Чтобы осветить технологию несколько с других позиций, мы решили спланировать материал этой главы немного иначе, чем это было сделано с материалами по FffiPlus
Иерархия компонентов в IBX
Поскольку вы работаете с Delphi (или с C++ Builder), то предполагается, что вы знакомы с объектно-ориентированным программированием Таким образом, разобравшись, как именно и от кого унаследованы различные компоненты IBX, можно будет более полно представить себе, как именно их нужно использовать. Рассмотрим рис. 2.1.

Рис 2.1. Иерархия компонентов IBX
Внимательно рассмотрев эту схему, можно сделать сразу несколько выводов.
Во-первых, очевидна несовместимость IBX с версиями Delphi меньше 5, поскольку класс TCustomConnection появился лишь в Delphi 5.
Во-вторых, становится ясно, почему компонент TIBSQL невозможно использовать вместе с визуальными db-aware-компонентами вроде TDBGrid или TDBEdit. Все стандартные визуальные db-aware-компоненты работают только с потомками класса TDataSet. Поэтому для db-aware компонентов невозможна связка с TIBSQL, который не унаследован от TDataSet.
Из той же схемы видно, что в IBX есть компоненты, совместимые с db-aware-компонентами (TDBGrid и т. д.). Это потомки внутреннего класса TIBCustomDataSet - TIBDataSet, TIBTable, TIBQuery и TIBStoredProc Вообще говоря, почти вся данная "ветка" классов по своему назначению близка к аналогичной ветке компонентов для работы с BDE - TTable, TQuery и TstoredProc - и предназначена для "быстрой" миграции старых приложений с BDE на IBX.
Также следует обратить внимание на компонент TIBUpdateSQL, который является аналогом компонента TUpdateSQL, предназначенного для работы с BDE
Судя по отзывам пользователей, переходящих с BDE на IBX, в действительности такое сопоставление компонентов IBX и BDE не всегда приносит желаемый результат, так как взаимозаменяемость старых BDE-компонентов на новые аналоги из IBX зачастую противоречит рекомендациям специалистов в силу различий в идеологии
Прежде всего это связано с управлением транзакциями и обработкой большого котичества записей Ниже мы остановимся на этом вопросе подробнее, а теперь перейдем к рассмотрению особенностей компонентов TIBTable, TIBQuery и TIBStoredProc
Особенности TIBTable, TIBQuery и TIBStoredProc
Фактически, компонент TIBCustomDataSet имеет всю необходимую функциональность для получения базы данных InterBase и поддерживает возможность редактирования этой информациии с помощью визуальных db-aware- компонентов
Для выборки данных, их изменения, удаления и вставки в TIBCustomDataSet используется набор свойств, представляющих собой SQL-запросы для манипулирования данными, - это SelectSQL, DeleteSQL, InsertSQL и ModifySQL.
Отдечьно следует сказать о RefieshSQL Этот запрос не используется для модификации записи, но является очень полезным для получения значений полей, которые были изменены триггерами базы данных и конкурирующими транзакциями
В свойстве SelectSQL указывается запрос на выборку данных (SELECT... FROM ..), которые будут доступны для просмотра и, в зависимости от содержимого остальных запросов, для редактирования, удаления и т д.
В свойствах DeleteSQL, InsertSQL и ModifySQL указываются соответствующие запросы, которые будут вызываться автоматически самим компонентом при вызове операций Delete, Insert и Edit для удаления, вставки и редактирования записей.
Фактически все, что нужно сделать программисту, - это написать нужные запросы, выполняющие нужные операции над записями. Далее мы более подробно рассмотрим потомков TIBCustomDataSet.
TIBTable
Компонент ТШТаЫе прячет все указанные выше свойства, а вместо этого пользователю предоставляется свойство TableName. Пользователь указывает имя таблицы в свойстве TableName, а компонент автоматически формирует набор "спрятанных" запросов.
Например, для таблицы с именем Tablel запрос в SelectSQL будет иметь вид:
SELECT * FROM Tablel
Легко представить, что в нашей таблице несколько миллионов записей и этот запрос попытается получить их их в полном объеме на клиента. Например, при вызове Locate, который так любят пользователи BDE, если запись, соответствующая условиям поиска, не найдена в загруженном наборе записей, то TIBTable будет запрашивать оставшиеся записи, пока не найдется подходящая запись или пока не закончатся записи в таблице.
Очевидно, что это вызовет колоссальную нагрузку на SQL-сервер и клиента, особенно в многопользовательской среде. Ни один специалист не рекомендует использование компонента TIBTable в реальных программных проектах, предназначенных для управления серьезными базами данных в многопользовательской среде.
TIBQuery
Аналогично ТГВТаЫе-компонент TIBQuery скрывает запросы для получения и редактирования данных. Вместо скрытого в этом компоненте свойства SelectSQL разработчику предлагается использовать свойство SQL. На самом деле после присвоения свойства SQL компонент присваивает его значение свойству SelectSQL.
Но самое примечательное с точки зрения проектирования классов начинается тогда, когда мы хотим сделать наш запрос редактируемым (live-query).
Поскольку свойства DeleteSQL, InsertSQL и ModifySQL спрятаны, то TIBQuery сам по себе не может предоставить разработчику редактируемые запросы.
Однако, как уже было сказано, TIBQuery был сделан как аналог TQuery и для полной аналогии в ГВХ введен компонент TIBUpdateSQL. Он содержит собственные свойства DeleteSQL, InsertSQL и ModifySQL и может подключаться к TIBQuery. После чего TIBQuery начинает использовать свойства компонента TIBUpdateSQL для редактирования собственных данных! Получается, что готовую функциональность TIBCustomDataSet, уже заложенную в него с самого на- чача, приходится дублировать в отдельном компоненте.
Отметим, тем не менее, что в данной связке имеется несомненный смысл, если речь идет о миграции готовых BDE-приложений на IBX. В общем-то, вероятно, только ради этого данные классы и были введены
Мы можем принять это как выгоду с точки зрения замены старых BDE-компонентов на нечто похожее из IBX, однако, если вы пишете новое приложение, которое с самого начала базируется на IBХ, мы бы рекомендовали вам использовать TDBDataSet как вместо ТIBTable, так и вместо TffiQuery.
Некоторые разработчики используют TIBQuery для выполнения только модифицирующих запросов, т. е. тех, которые не возвращают результата. Например, это может быть запрос с предложением INSERT или DELETE.
Для выполнения запросов, не возвращающих результирующий набор данных. в TIBQuery предусмотрен метод ExecSQL. Но фактически, как видно из исходных текстов компонента, вызов данного метода не отличается от вызова метода Open, который унаследован от TIBCustomDataSet.
Поэтому для выполнения запросов, которые не возвращают результатов (в том смысле, что не возвращают набор результирующих строк), не имеет смысла использовать компоненты, предназначенные для взаимодействия с визуальными db-aware- компонентами. Вместо этого лучше использовать компонент TIBSQL, который не буферизует получаемые данные и предназначен именно для простого и быстрого выполнения SQL-запросов, в частности не возвращающих набор строк.
TIBStoredProc
Данный компонент предназначен для выполнения исполняемых (executed) хранимых процедур. Он также является потомком TffiCustomDataSet и полностью совместим с визуальными компонентами.
Являясь прямым наследником TffiCustomDataSet, компонент TffiStoredProc прячет все основные свойства предка и добавляет такое свойство, как ProcedureName.
Следует понимать, что в данном случае слово "прячет" относится больше к идеологии проектирования классов, нежели к технической стороне дела. Очевидно, что спрятать свойства предка в Object Pascal нельзя. TIBCustomDataSet уже имеет все необходимые свойства, которые уже готовы для публикации, их просто не вынесли в секцию published. И хотя мы согласимся, что в данном случае нельзя однозначно сказав, насколько правильным является данное проектирование классов, однако считать его красивым довольно трудно.
В результате указания названия процедуры (например, procl) компонент сформирует SQL-запрос следующего вида:
EXECUTE PROCEDURE Proс1
В целом возможно, что проще вызвать хранимую процедуру с помощью соответствующего SQL-запроса, используя TIBDataSet, если мы хотим показать результат в db-aware-компонентах, или TIBSQL, если мы хотим вызывать хранимую процедуру вида executable (т. е. не возвращающую набор данных).
Единственным преимуществом использования TIBStoredProc по сравнению с TIBDataSet является тот факт, что TIBStoredProc самостоятельно формирует список параметров процедуры по ее имени, обращаясь к системным таблицам.
Подключение к базе данных
Очевидно, что прежде чем начать работать с базой данных, надо к ней подключиться. Специально для этого в состав IBX включен компонент TIBDatabase.
Для наших примеров в этой главе мы будем использовать базу данных Employee.gdb, которая поставляtnся вместе с InterBase.
Поместите TIBDatabase на форму и вызовите контекстное меню (рис. 2.2).

Рис. 2.2. Вызов редактора IBDatabase
Из рисунка видно, что у TIBDatabase существует специальный редактор, который позволяет вам настраивать определенные параметры компонента во время разработки приложения (рис. 2.3).

Рис. 2.3. Редактор TIB Database
В частности, необходимо указать путь к базе данных в разделе Connection. Путь включает в себя имя сервера и локальный путь к файлу базы данных на сервере. В случае, если сервер локальный, то достаточно указать только путь к файлу базы данных.
Немного подробнее относительно использования удаленного сервера. Предположим, что InterBase установлен у вас в сети на компьютере с сетевым именем SERV_IB и доступен по протоколу TCP/IP. Пусть база данных находится на сервере на диске Е: в файле MY_DB.GDB. В данной ситуации в редакторе компонента вам надо будет указать тип подключения Remote, имя сервера SERV_1B, а путь к базе данных оставить локальным относительно сервера, т. е. , ЕЛ MY_DB.GDB. Это важный момент! Вы указываете серверу путь к локальному файлу базы на сервере, а не указываете вашей программе сетевой путь к базе данных. В сущности, именно об этом говорится в главе "Создаем базу данных" в разделе "Строка соединения", а здесь мы лишь хотим еще раз подчеркнуть, что данный редактор создает точно такую же строку соединения, которую вы вводите вручную, например, при использовании инструментов администратора и разработчика InterBase.
Вы можете протестировать параметры подключения не выходя из диалога при помощи кнопки Test. Если все указано правильно, то вы увидите сообщение Successful connection.
Управление транзакциями
Необходимо помнить, что любое действие с базой данных происходит в рамках той или иной транзакции. Работа с InterBase основана на явном управлении транзакциями, а поскольку библиотека IBX - это обертка вокруг соответствующих функций InterBase API, то использование этих компонентов также предполагает, что программист явным образом будет управлять транзакциями из своего приложения. Для контроля транзакций в IBX существует специальный компонент TIBTransaction (рис. 2.4):

Рис 2.4. Свойства TIBTransaction
Как видно из рисунка, компонент не слишком перегружен свойствами. Фактически основным является свойство Params, в котором можно указать уровень Изоляции транзакции. Для этого необходимо знать соответствующие системные •константы из InterBase API. Однако для большинства ситуаций вам вполне хватит использования одного из четырех заранее заданных уровней изоляции. Для того чтобы выбрать один из них, можно вызвать редактор компонента (рис. 2.5).

Рис. 2.5. Вызов редактора TIBTransaction
В появившемся диалоге вы сможете указать нужный уровень изоляции, а заодно и увидеть сразу, какими константами он задается (рис. 2.6.).
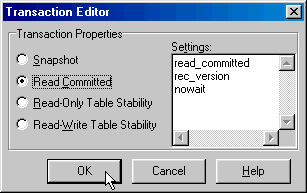
Рис 2.6. Редактор TIBTransaction
Для большинства случаев рекомендуется использовать режим Read Committed, который позволит запросам в одной транзакции "видеть" изменения, сделанные и подтвержденные в контексте других транзакций.
TIBTransaction ссылается на компонент базы данных при помощи свойства DetaultDatabase. Если также указать свойство DefaultTransaction у TIBDatabase, то в дальнейшем любые компоненты (TIBDataSet, TffiSQL и т. д.), которые ссылаются на TIBDatabase, будут автоматически "подхватывать" и указанную транзакцию.
Теперь рассмотрим свойства AllowAutoStart и AutoStopAction. Как вам уже известно, любой запрос к базе данных должен выполняться в контексте транзакции. То есть, прежде чем выполнить даже простейший запрос вида SELECT * FROM TABLE 1, необходимо предварительно запустить транзакцию при помощи вызова IBTransaction.StartTransaction.
Такой "ручной" вызов не всегда удобен. Более того, каждый раз совершенно определенно известно: если мы хотим выполнить запрос, то мы должны запустить транзакцию. Чтобы избежать лишнего кода, связанного с запуском транзакций, можно установить значение свойства AllowAutoStart равным True. В этом случае если мы попробуем, например, открыть TIBDataSet, то он сам автоматически запустит соответствующую транзакцию.
Аналогичный смысл имеет свойство AutoStop Action. Когда мы закрываем все запросы, выполнявшиеся в контексте автоматически запущенной транзакции, то TIBTransaction выполняет действие, указанное в AutoStopAction. Например, автоматически подтверждает всю транзакцию при помощи метода Commit, если свойство AutoStopAction равно saCommit. Таким образом, разработчику предоставляется возможность указать, как компоненты должны автоматически взаимодействовать друг с другом!
Выполнение запросов при помощи TIBDataSet
В данной главе сознательно не рассматривается работа с TIBTable или TIBQuery, так как авторы книги не считают их использование целесообразным. Если вы все же желаете использовать эти компоненты (например, для облегчения миграции приложения с BDE), то для из>че- ния их функций можно обратиться к документации по аналогичным BDE-компонентам, а также к документации по IBX.
Итак, поместите на форму следующие компоненты:
IBDataSetl: TIBDataSet;
DataSourcel: TdataSource
DBGridl: TDBGrid
Необходимо указать свойства Database и Transaction у IBDataSetl, задать DataSourcel.DataSet равным IBDataSetl, а также указать DBGridl.DataSource равным DataSourcel.
Теперь необходимо указать тот запрос, который мы хотим выполнить, в свойстве SelectSQL у IBDataSetl (рис. 2.7).

Рис 2.7. Редактор свойства SelectSQL
Теперь мы можем открыть запрос прямо в design-time, задав свойство Active в True. Результат наших действий приведен на рис. 2.8.
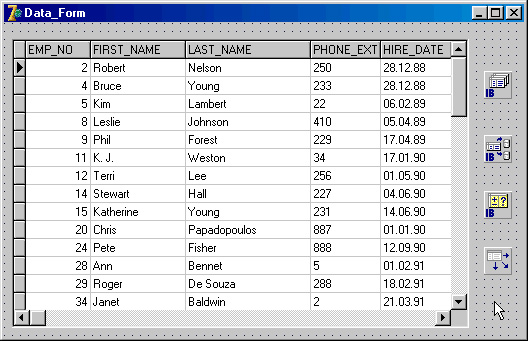
Рис 2.8. Открытие запроса в IBDataSet1
Чтобы получить то же самое во время выполнения программы, напишите следующий обработчик события OnFormCreate у основной формы приложения'
procedure TForml.FormCreate(Sender: TObject);
begin
IBDatabasel.Open;
IBDataSetl.Open;
end;
He забудьте закрыть подключение к базе данных перед сохранением проекта, иначе попытка IBDatabase I .Open вызовет ошибку. Вы также можете написать этот код иначе: IBDatabasel Connected := True; IBDataSetl.Active := True. Он не вызовет сообщения об ошибке, если IBDatabasel и IBDataSetl были активны в design-time.
Редактируемые запросы
Редактирование данных при помощи визуальных компонентов
Если вы уже запустили пример, представленный выше, и попробовали исправить хотя бы одну запись в таблице, то наверняка получили сообщение, что сделать это невозможно. Причины этого сообщения очевидны, поскольку компонент IBDataSetl имеет только свойство SelectSQL. Это свойство содержит запрос на выборку записей, его выполнение позволяет получить список тех записей из таблицы EMPLOYEE с сервера, которые удовлетворяют условию в WHERE.
А для того чтобы, к примеру, исправить какую-либо запись, необходимо выполнить команду UPDATE. В общем случае выполнение этой команды может вообще не зависеть от нашего запроса в SelectSQL.
Но поскольку TIBDataSet был спроектирован в первую очередь для того, чтобы использоваться совместно со стандартными визуальными компонентами, то он предоставляет нам средства для автоматического выполнения тех модифицирующих запросов, которые необходимы для изменения данных, полученных при помощи SelectSQL. Чтобы окончательно не запутаться, давайте подробнее рассмотрим этот вопрос.
Итак, мы открыли запрос в SelectSQL. Как видно из рисунка, первая полученная запись содержит имя сотрудника Robert. Предположим, мы хотим исправить это имя на John.
В момент изменения произойдет следующее: в локальном буфере IBDataSetl у текущей записи значение поля FIRST_NAME будет изменено с Robert на John. В базе данных данное изменение пока никак не отражается. Чтобы произвести фактическое изменение данных на сервере, необходимо выполнить соответствующий запрос с UPDATE. Этот запрос необходимо заранее указать у компонента IBDataSetl в свойстве ModifySQL:
UPDATE EMPLOYEE
SET
EMP_NO = :EMP_NO,
FIRST_NAME = :FIRST_NAME,
LAST_NAME = :LAST_NAME,
PHONE_EXT = :PHONE_EXT,
HIRE_DATE = :HIRE_DATE,
DEPT__NO = :DEPT_NO,
JOB_CODE = :JOB_CODE,
JOB_GRADE = :JOB_GRADE,
JOB_COUNTRY = :JOB_COUNTRY,
SALARY = :SALARY WHERE
EMP_NO = :OLD_EMP_NO
Как видно из примера, вместо реальных значений в этом запросе указаны параметры, названия которых совпадают с названием реальных полей. Таким образом, когда пользователь изменит значения полей конкретной записи, ю jtBDataSetl сам задаст значения всех параметров, взяв их из соответствующих |полей. В частности, значение параметра :FIRST_NAME будет равно John. Запрос шз ModifySQL выполнится, и только после этого изменения, сделанные пользователем, окажутся в базе данных.
Аналогичная последовательность действий связана с запросами в свойствах HnsertSQL и DeleteSQL - они выполняются при вставке новой записи и удалении записи пользователем.
Обратите внимание на префикс OLD_ в названии параметра :OLD_EMP_NO. Данный префикс означает, что IBDataSet должен подставить в параметр значение поля до изменения пользователем.
Итак, если мы сформируем все модифицирующие запросы, то наш IBDataSet позволит пользователям редактировать данные, т. е. мы фактически получим запрос, который разработчики на Delphi/C-H-Buildei обычно называют "живым"(live query).
Существует еще одна важная особенность при создании "живых" запросов После выполнения любого модифицирующего действия IBDataSet 1 выполнит запрос, указанный в свойстве RefreshSQL. Этот запрос должен возвращать только одну запись - текущую и нужен для обновления значений полей текущей записи после сделанных исправлений.
SELECT
EMP_NO,
FIRST_NAME,
LAST_NAME,
PHONE_EXT,
HIRE_DATE,
DEPTMTO,
JOB_CODE,
JOB_GRADE,
JOB_COUNTRY,
SALARY,
FULL_NAME
FROM EMPLOYEE
WHERE
EMP_NO = :EMP_NO
Смысл данного запроса становится очевидным, если допустить существование в базе данных триггеров для таблицы EMPLOYEE, которые модифицируют значения полей. Поскольку изменения происходят в самой базе данных сразу после вставки или после изменения записей, то без повторного перечитывания записи (т. е. без Select только что вставленной или измененной записи), мы не узнаем о тех изменениях, которые были сделаны в триггерах. Можно, конечно, вообще переоткрыть весь запрос, заданный в SelectSQL.
Именно такой механизм и реализуется в BDE, когда мы вынуждены целиком переоткрывать все запросы. В IBX без этого легко можно обойтись, используя RefieshSQL, значительно сэкономив при этом сетевой трафик и снизив нагрузку на сервер, поскольку получение всего лишь одной измененной записи гораздо более эффективно, чем переоткрытие запроса целиком.
IBX предоставляет нам возможность быстро сгенерировать необходимые модифицирующие запросы при помощи редактора IBDataSet (рис 2.9.)
Выбрав из списка Table Name нашу таблицу и нажав кнопку Get Table Fields мы сформируем списки Key Fields и Update Fields. В списке Key Fields нужно выделить те поля, которые будут формировать условие WHERE в наших запросах. Очевидно, что это должны быть поля, которые определяют первичный ключ у таблицы. Если такой ключ существует для выбранной таблицы, то вы можете просто нажать на кнопку Select Primary Keys, чтобы автоматически выделить нужные поля.

Рис 2.9. Генератор модифицирующих запросов
В списке Update Fields необходимо выделить те поля, которые потом пользователь сможет редактировать. На рисунке видно, что поле FULL_NAME не включено в список, поскольку это CALCULATED-поле и его значение нельзя менять
К сожалению, надо самому точно знать, какие поля необходимо исключать из модифицирующих запросов поскольку компоненты не дадут ни одной подсказки. Даже при подготовке данного раздела пришлось потратив впустую некоторое время, чтобы понять, почему IBDataSetl никак не "хотел" становиться модифицируемым. Только выяснив, что поле FULL_NAME является вычислимым, стало понятно, почему возникает ошибка IBDataSetl пытался выполнить команду Prepare для каждого из запросов и сервер каждый раз сообщал, что не может изменить read-only-поле! Хочется отметить, что этой проблемы нет в генераторе запросов, реализованном в FIBPlus.
Остается нажать кнопку Generate SQL, чтобы получить все запросы flnsertSQL, ModifySQL, DeleteSQL и RefreshSQL.
Программное редактирование данных
Как показал некоторый опыт в поддержке пользователей, программисты, впервые применяющие IBX и аналогичные компоненты, не совсем понимают каким образом можно использовать TIBDataSet для того, чтобы управлять данными программно, а не просто давать пользователю возможность вносить какието исправления.
Например, периодически возникает вопрос: "А как мне автоматически вставить новую запись в IBDataSet? Может быть, стоит разместить рядом отдельный компонент IBSQL, в котором написать запрос INSERT, выполнить его, а потом переоткрыть IBDataSet? Или, может быть, можно синхронизировать новую запись в IBSQL и существующие записи в IBDataSet? Существуют ли методы для прямого редактирования локального буфера записей в IBDataSet?"
Подобные "технологические" решения можно придумывать очень долго: поскольку фантазия разработчиков практически неистощима, мы можем найти выход из любой ситуации и обойти любое ограничение существующей технологии. Однако в данном случае решения "проблемы" проистекают от простого непонимания принципов работы IBDataSet. Поверьте, все гораздо проще.
В самом начале главы сказано, что TIBDataSet порожден классом TDataSet, а значит, наследует основные принципы его работы. У TIBDataSet как наследника TDataSet существует три основных метода для изменения данных: Delete, Insert (Append) и Edit.
Предположим, что мы хотим вставить новую запись в наш IBDataSetl по нажатии кнопки:
procedure TForml.ButtonlClick(Sender: TObject);
begin
with IBDataSetl do begin
Insert;
FieldByName('EMP_NO').Aslnteger := 147;
FieldByName('DEPT_NO').Aslnteger := 600;
FieldByName('JOB_CODE').AsString := 'VP';
FieldByName('JOB_GRADE') .Aslnteger : = 2 ;
FieldByName('SALARY').Aslnteger := 105900;
FieldByName('HIRE_DATE').AsDateTime := Now;
FieldByName('JOB_COUNTRY').AsString := 'USA';
FieldByName('FIRST_NAME').AsString := 'Иван';
FieldByName('LAST_NAME').AsString := 'Иванов';
Post;
end;
end;
Теперь поясним, как это работает. После того как мы вызываем метод Insert, IBDataSetl формирует пустой буфер для нашей (пока еще не введенной) записи. Далее мы задаем значения нужных полей при помощи вызовов метода FieldByName и заканчиваем (точнее, подтверждаем) редактирование вызовом метода Post. В этот момент IBDataSetl выполняет запрос, прописанный в свойстве InsertSQL, подставив вместо параметров те значения полей, которые мы задали.
Если запрос выполнился успешно, то IBDataSetl автоматически выполняет RefreshSQL для обновления только что вставленной записи - для проверки изменений, внесенных на стороне базы данных.
Аналогичным образом мы можем редактировать записи. Например, мы можем модифицировать все записи в нашем запросе:
procedure TForml.ButtonlClick(Sender: TObject);
begin
with IBDataSetl do begin
First;
while not Eof do begin
Edit;
FieldByName('LAST_NAME').AsString :=
trim(FieldByName('LAST_NAME').AsString) + ', esquire;
Post;
Next ;
end;
end;
end;
Принцип тот же самый, что и при вставке записей. Мы вызываем метод Edit, подготавливая буфер текущей записи для редактирования, потом меняем значения поля при помощи FieldByName, а потом заканчиваем редактирование, вызвав метод Post. В результате IBDataSetl подставляет значения полей записи в ModifySQL и выполняет запрос.
Оговоримся, что в реальной практике подобная обработка большого множества записей не является хорошим решением. Гораздо легче было бы выполнить одну команду UPDATE, которая добавила бы строку ', esquire' ко всем записям таблицы. Пример выше дан только для демонстрации метода Edit.
Как видно из примеров выше, нет никакой нужды ни в каких дополнительных компонентах, синхронизации о прочих непонятных "телодвижениях", если мы хотим редактировать данные в IBDataSet программно.
И снова про транзакции
Новичков иногда пугает "особенность" IBX закрывать все запросы при подтверждении или "откате" транзакции. Разместим на нашей форме две кнопки, как показано на рис. 2.10: Button 1 (свойство Caption равно Commit) и Button2 (Rollback).

Рис 2.10. Кнопки управления транзакцией
Далее напишем следующие обработчики событий нажатия на эти кнопки:
procedure TForml.ButtonlClick(Sender: TObject);
begin
IBTransactionl.Commit;
end;
procedure TForml.Button2Click(Sender: TObject);
begin
IBTransactionl.Rollback;
end;
Теперь если мы запустим приложение и нажмем любую из этих кнопок, то увидим, что после завершения транзакции наш запрос также будет закрыт.
Это действие совершенно очевидно, поскольку, как уже было сказано, любой запрос должен выполнятся только в рамках определенной транзакции и, таким образом, если транзакция уже закрыта, то запрос не может быть активным.
Однако для тех разработчиков, которые до сих пор пользовались BDE, такое поведение компонентов непривычно. Существует два метода. Первый: запоминать активные записи во всех открытых запросах перед закрытием транзакции, потом заново открывать все запросы и перемещать указатели текущих записей на "старое место". Именно так и работает механизм неявного переоткрытия, реализованный в BDE. Второй - это использовать методы CommitRetaining и RollbackRetaining, впервые появившиеся в InterBase 5.x. Эти методы в целом аналогичны методам Commit и Rollback, однако они реализованы таким образом, что сервер автоматически перезапускает транзакцию и не закрывает открытых запросов. Использование CommitRetaining и RollbackRetaining позволит вам избегать массовых операций переоткрытия ваших запросов.
Однако тут есть одна особенность, которая сразу не бросается в глаза. Предположим, что вы делали какие-то изменения, после чего решили отменить их и вызвали RollbackRetaining. Все модифицирующие запросы, которые были отправлены на сервер в контексте данной транзакции, будут отменены, однако локальный буфер TIBDataSet останется неизмененным.
Таким образом, содержимое, например, TDBGrid в вашем приложении будет отличаться от реального состояния таблицы на сервере. Поэтому мы рекомендуем вам все-таки заново открывать запросы, изменения которых были отменены при помощи RollbackRetaining.
Использование генераторов для автоинкрементных полей
Чаще всего автоинкрементные поля используются для поддержки суррогатных первичных ключей. В таблице заводится поле, значения для которого генерируются при помощи доступных технических средств, гарантирующих уникальность получаемых значений.
Существует несколько способов получения таких значений, мы же остановимся на том, который рекомендуется для большинства баз данных в InterBase. Как вы знаете, в InterBase существуют специальные объекты - генераторы, которые гарантируют получение уникальных возрастающих значений, независимых от контекста транзакций.
В IBDataSet существует специальное свойство, которое позволяет нам удобно использовать генераторы для создания уникальных значений первичного ключа, а именно GeneratorField. У этого свойства существует специальный редактор, доступный в design-time (рис. 2.11).
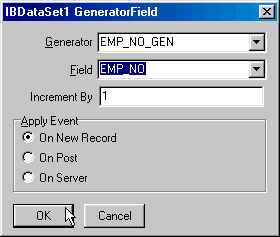
Рис 2.11. Настройка автоинкрементного поля
Укажите название генератора, имя поля в таблице, значения для которого будут генерироваться, шаг увеличения счетчика (в большинстве случаев это 1), а также опцию, указывающую, когда будет генерироваться значение поля: сразу при вставке новой записи (On New Record), при завершении вставки (On Post) или при помощи триггера (On Server). В последнем случае вы не увидите значения сгенерированного поля, пока не переоткроете весь запрос, однако данная опция все равно может оказаться полезной. Поскольку наше поле EMP_NO входит в первичный ключ, то его значение не может формально быть незаданным (NULL). Если не указывать свойство GeneratorField, то DBDataSetl будет требовать от нас указывать значение поля EMP_NO в обязательном порядке и мы не сможем "переложить ответственность" на триггер.
Указав же явным образом, что значение поля будет получено именно в триггере, мы обойдем это ограничение. Тем не менее мы рекомендуем вам использовать опции On New Record или On Post, поскольку они лучше укладываются в общую идеологию применения IBX.
Если мы получаем значение первичного ключа до отправки на сервер, то IBDataSetl сумеет корректно выполнить RefreshSQL. Если же мы будем использовать для генерации триггер, то IBDataSetl не сможет подставить правильное значение в RefreshSQL, поскольку значения полей в условии WHERE еще неизвестны.
Механизм master-detail
Механизм мастер-деталь часто используется в приложениях для работы с базами данных, поскольку именно он позволяет нам легко связывать данные из разных таблиц, полученных в результате нормализации базы.
Добавим на нашу форму новые компоненты (рис. 2.12).
IBDataSet2: TIBDataSet;
DataSource2: TdataSource;
DBGrid2: TDBGrid;

Рис 2.12. Разработка связи мастер-деталь
Свяжем DataSource2 с IBDataSet2, a DBGrid2 с DataSource2. Укажем следующие запросы для IBDataSet2:
SelectSQL:
SELECT BUDGET, DEPARTMENT, DEPT_NO, HEAD_DEPT, LOCATION,
MNGR_NO, PHONE_NO
FROM DEPARTMENT
InsertSQL:
INSERT INTO DEPARTMENT
(BUDGET, DEPARTMENT, DEPT_NO, HEAD_DEPT, LOCATION, MNGR_NO,
PHONE_NO)
VALUES
(:BUDGET, :DEPARTMENT, :DEPT_NO, :HEAD_DEPT, :LOCATION,
:MNGR_NO, :PHONE_NO)
DeleteSQL:
DELETE FROM DEPARTMENT
WHERE DEPT_NO = :OLD_DEPT_NO
ModifySQL:
UPDATE DEPARTMENT SET
BUDGET = :BUDGET,
DEPARTMENT = :DEPARTMENT,
DEPT_NO = :DEPT_NO,
HEAD_DEPT = :HEAD_DEPT,
LOCATION = :LOCATION,
MNGR_NO = :MNGR_NO,
PHONE_NO = :PHONE_NO WHERE
DEPT_NO = :OLD_DEPT_NO
RefreshSQL:
SELECT
DEPT_NO,
DEPARTMENT,
HEAD_DEPT,
MNGR_NO,
BUDGET,
LOCATION,
PHONE_NO,
DEPT_NO1 FROM DEPARTMENT WHERE
DEPT_NO = :DEPT_NO
Очевидно, что их можно сгенерировать при помощи DataSet Editor, как это было описано выше
Теперь необходимо внести изменения в IBDataSetl. Во-первых, нужно задать свойство IBDataSetl.DataSource равным DataSource2. Во-вторых, надо изменить IBDataSetl. SelectSQL:
SELECT DEPT_NO, EMP_NO, FIRST_NAME, FULL_NAME, HIRE_DATE,
JOB_CODE, JOB_COUNTRY, JOB_GRADE, LAST_NAME, PHONE_EXT, SALARY
FROM EMPLOYEE
WHERE DEPT_NO = :DEPT_NO
Значение параметра :DEPT_NO будет автоматически браться из одноименного поля IBDataSet2: DEPT_NO.
Запустите приложение, и вы увидите, что при перемещении по верхней таблице в нижней будут отображаться только сотрудники текущего отдела (рис. 2.13).
Еще одна особенность заключается в том, чтобы настроить IBDataSetl таким образом, что при добавлении новой записи о работнике автоматически подставлялся номер текущего отдела из IBDataSet2. Для этого напишем обработчик OnNewRecord у IBDataSetl:
procedure TForml.IBDataSetlNewRecord(DataSet: TDataSet);
begin
DataSetl.FieldByName('DEPT_NO').Aslnteger :=
IBDataSet2.FieldByName('DEPT_NO').Aslnteger;
end;

Puc 2.13. Запущенное приложение со связью мастер—деталь
Теперь мы можем смело запускать приложение и редактировать записи в обеих таблицах.
Хочется отметить, что в соответствующей главе, посвященной механизму мастер-деталь в FlBPlus, описаны дополнительные возможности компонентов, связанные с оптимизацией и "тонкой" настройкой связей мастер-деталь, которые отсутствуют в IBX Возможно, что, ознакомившись с этим описанием, вы реализуете в своем приложении нечто подобное и при помощи IBX
Также хочется отметить, что компоненты IBX предоставляют все необходимые базовые возможности для создания приложений практически любого уровня сложности.
Важно лишь понимать, какой компонент желательно применять в конкретной ситуации. Например, для массовых вставок записей в базу данных, если нет нужды отображать вставляемые записи в пользовательских компонентах, желательно использовать IBSQL, которые не буферизуют записи в отличие от TIBDataSet и его потомков.
При использовании для этой же операции TIBDataSet при большом количестве записей (порядка нескольких миллионов) приложение может начать работать на порядки медленнее.
Важно отметить, что работа с большим количеством записей для пользователя редко бывает удобной. Согласитесь, не так часто можно найти человека, который смог бы удержать в памяти информацию из нескольких сотен записей.
Обычно пользователи все-таки применяют поиск, чтобы найти нужные данные, и задача разработчика, помимо прочего, состоит в том, чтобы формулировать условия в SQL-запросах максимально точно и иметь в итоге лишь небольшой набор данных. Во-первых, это резко снизит лишний сетевой трафик, а во- вторых, снизит размер памяти, занимаемой данными в буфере TIBDataSet, за счет чего также увеличится скорость работы TIBDataSet.
Управление транзакциями тоже зависит только от вас и требований вашей задачи. Не существует единственно правильного способа распределения компонентов TIBTransaction. Некоторые предпочитают все делать в контексте одной общей транзакции, вовремя вызывая Commit или Rollback; другие предпочитают для каждого TIBDataSet иметь отдельную транзакцию, следя за правильным уровнем изоляции. Только вы можете решить, какие транзакции нужны для правильной работы ваших запросов.
Заключение
Данная глава не претендует на звание учебника по IBX, поскольку дает лишь самые основные факты и описывает только наиболее важные, как нам кажется, особенности компонентов. Однако мы надеемся, что этот материал даст вам необходимый оазис для дальнейшего самосостоятельного изучения.
Также заметим, что в главе по FTBPlus вы сможете найти многие вещи, которые окажутся полезными и при работе с ШХ. Например, вы вполне сможете использовать материалы, описывающие работу с генератором отчетов FastReport, работу с BLOB-полями, локальную фильтрацию и обработку событий (event alerts).
Что такое FIBPIus?
Предыдущие главы книги содержали описание самого сервера InterBase, но для практического его использования необходимо разрабатывать клиентские программы. Само название технологии Client/Server говорит о наличие двух сторон: сервера, который в нашем случае обслуживает базу данных, и клиента, который является специализированной программой, взаимодействующей с сервером InterBase.
Для написания клиента, или клиентской части, вы в принципе можете использовать практически любые среды разработки, которые позволяют вызывать функции из внешней DLL-библиотеки. Суть взаимодействия с InterBase состоит в том, что ваша программа вызывает некоторые функции InterBase API для выполнения тех или иных запросов к базе данных. InterBase API заключено в специальной библиотеке gds32.dll. Таким образом, вы имеете возможность писать свои программы на чем угодно, обращаясь к функциям gds32.dll. Тем не менее, такой низкоуровневый подход неудобен для создания прикладных программ, в которых основное внимание уделяется обработке данных на достаточно абстрактном уровне. Если разработчик вынужден каждый раз заботиться, прежде всего, о том, чтобы правильно сформировать внутренние структуры для вызова функций gds32.dll, то процесс разработки значительно усложняется и затягивается.
Этого можно избежать, если вы используете для разработки клиентской части Borland Delphi, Borland C++ Builder или Borland Kylix. Идеология этих продуктов поощряет создание специализированных наборов компонент для решения определенных системных задач, облегчая, таким образом, жизнь прикладного разработчика.
Devrace FIBPIus - это библиотека компонент для Delphi, C++ Builder и Kylix, предназначенных для работы с InterBase и его клонами (Firebird и Yaffil). Компоненты используют прямой InterBase API для взаимодействия с сервером, поэтому для нормальной работы программ, написанных с использованием FIBPIus, не нужно ничего, кроме наличия gds32.dll. Кроме того, использование прямого API дает клиентским приложениям максимальную производительность, гибкость и возможность использования "специальных" уникальных вещей, реализованных в InterBase. В частности, можно упомянуть array-поля, которые невозможно использовать при работе со стандартными Delphi компонентами ТТаЫе, TQuery, взаимодействующими с InterBase через Borland Database Engine (BDE).
Попробуем кратко перечислить основные возможности и преимущества FIBPIus:
* Полная совместимость со Borland Delphi 3-7, C++ Builder 3-6 и Kylix 3.
* Полная совместимость с существующими версиями InterBase 4.X-7.0, Firebird, Yaffil в настоящий момент, а также поддержка всех версий InterBase и его основных клонов в будущем.
* Поддержка всех особенностей и специальных возможностей InterBase: event alerters, array-полей, blob-полей.
* Встроенные макросы в SQL-выражениях, позволяющие использовать параметры-подстановки даже в там, где это не позволяет сам InterBase.
* Удивительно гибкий механизм работы с master-detail запросами, позволяющий свести "ручное" кодирование практически к нулю и при этом иметь возможность гибко настраивать любые связки master-detail без написания обработчиков событий, улучшая общую производительность приложения за счет снижения лишнего сетевого трафика.
* Улучшенная производительность при выполнении запросов со средним и небольшим количеством результирующих записей (т. е , для 90-95% всех запросов в обычных приложениях!).
* Гибкое управление транзакциями. FIBPlus, которое позволяет, с одной стороны, явно управлять каждой транзакцией, а с другой стороны автоматизирует большинство операций, автоматически запуская транзакции, и подтверждая их в режиме AutoCommit. Кроме этого, FIBPlus реализует уникальный механизм работы одного компонента в контексте двух транзакций: читающей и пишущей, что позволяет совершенно избегать DEADLOCK при работе приложения.
* Реализация и поддержка дополнительных возможностей, например, эмуляция Boolean-полей, отсутствующих в явном виде в InterBase. Качественная поддержка режима CachedUpdates позволяет использовать FIBPlus в приложениях с нестабильными удаленными подключениями к базе данных (например, посредством dial-up). Используя CachedUpdates, вы можете подключиться к базе данных, выбрать данные, отключиться, изменить данные и после повторного подключения (или восстановления подключения), вернуть изменения на сервер. Данная возможность реализована только в FIBPlus, поскольку, например, в IBX даже при режиме CachedUpdates необходимо, тем не менее, иметь активные транзакции и подключение к серверу.
* Поддержка локальной сортировки и локальной фильтрации данных (без дополнительных запросов на сервер).
* Автоматическая генерация модифицирующих запросов в run-time и design- time. Уникальная возможность автоматически генерировать модифицирующие запросы, в которых участвуют не все поля записи, а только те, значения которых реально были изменены, что позволяет снизить сетевой траффик приложения.
* Аккуратная поддержка auto-increment полей, не требующая переоткрытия запроса после вставки новой записи, чтобы получить значения полей, измененных триггерами.
* Возможность централизованной обработки ошибок и исключений при помощи компонента TpFIBErrorHandler.
* Уникальная возможность создания цепочек модифицирующих запросов при помощи компонента TpFIBUpdateObject. Компонент позволяет реализовывать без ручного кодирования выполнение нескольких автоматических модифицирующих действий. Причем, эти модифицирующие запросы автоматически получают параметры от TpFIBDataSet и могут работать в рамках разных транзакций и даже разных подключений к базам данных. Управляя только свойствами TpFIBUpdateObject, разработчик может активировать или деактивировать нужные ему цепочки запросов. Все это превращает TpFEBUpdateObject в некое подобие триггера, реализованного в клиентской части приложения.
* Полная поддержка Services API, что позволяет включать в приложения функции удаленного администрирования баз данных и самого сервера.
Компоненты FffiPlus построены таким образом, чтобы их можно было использовать со всеми стандартными визуальными db-компонентами и сторонними продуктами, поддерживающими стандарт TDataSet-TDataSource. Таким образом, разработчик, выбравший FffiPlus для доступа к InterBase, не ограничен в выборе сторонних компонент для отображения данных, или печати отчетов (мы покажем, в частности, как использовать FffiPlus в связке с FastReport).
Для любознательного читателя, возможно, будет также интересно узнать некоторые факты из истории появления и развития FffiPlus. В 1998 году независимый разработчик Грегори Дилтц создал минимальный набор компонентов для работы с InterBase API, назвав его FreeffiComponents (FffiC). Уже с 1999 года одесский программист Сергей Бузаджи стал дописывать эту бесплатную библиотеку своими более функциональными компонентами, назвав эти дополнения FffiPlus. Тогда же корпорация Borland выпустила Delphi 5, включив в нее компоненты InterBase Express (ffiX), полностью основанные на коде FIBC. Сам Грегори Дилтц отказался от продолжения развития своей библиотеки. К этому времени изменения в FffiC, сделанные Сергеем Бузаджи, были столь значительны и затрагивали практически весь первоначальный код Грегори Дилтца, что было решено развивать FIBPIus как отдельный проект, в рамках условий лицензионного соглашения Грегори Дилтца. С этого времени поддержкой и развитием библиотеки занимается компания Devrace, Сергей Бузаджи является ведущим разработчиком и идеологическим руководителем данного продукта. На текущий момент библиотека полностью совместима с Borland Delphi 3-7, Borland C++ Builder 3-5, Borland Kylix 3 и поддерживает Borland InterBase 4-7.0, а также все версии Firebird и Yaffil.
FIBPIus является коммерческим продуктом, однако компания Devrace ввела специальную цену для стран бывшего Союза, которая в десятки раз меньше цены для "западных" пользователей.Вы можете найти всю информацию о FIBPIus на сайтах: http://www.devrace.com, http://www.fibplus.net.
Общее описание компонент, включенных в состав FIBPIus

TpFIBDatabase - предназначен для подключения к базе данных, позволяет получать статистическую информацию о базе, свойствах базы данных и так далее. Основные методы: Open, Close.

TpFIBTransaction - предназначен для явного управления транзакцией. Основные методы: StartTransaction, Commit, Rollback, CommitRetaining, RollbackRbtainine.

TpFIBDataSet - предназначен для получения и редактирования данных, является потомком стандартного класса TDataSet и полностью совместим со всеми визуальными компонентами. Основные методы: Prepare, Open, Close, Insert, Append, Edit, Delete, Refresh.

TpFIBQuery - предназначен для простого выполнения запросов, позволяет также получать данные из базы данных. В отличие от TpFIBDataSet , компонент не содержит локального буфера для хранения всех полученных записей, и не совместим с визуальными компонентами. Основные методы: Prepare, ExecOuery, Close

TpFIBStoredProc - потомок TpFIBQuery, предназначен для выполнения хранимых процедур. Не рекомендуется для вызова процедур, возвращающих данные. Фактически, компонент является удобной "оберткой" вокруг команды EXECUTE PROCEDURE.

TpFIBUpdateObject - предназначен для автоматического выполнения дополнительных модифицирующих действий совместно с TpFIBDataSet.

TDataSetContainer - предназначен для централизации обработки типичных обработчиков событий TpFIBDataSet и внутренней нотификации, что иногда позволяет сильно упростить код.

TpFIBSQLMonitor - предназачен для отслеживания всех запросов, которые выполняются при помощи компонентов FIBPIus. Позволяет также отслеживать запросы из параллельных приложений, также написанных на основе FIBPIus.

TpFIBErrorHandler - предназначен для централизованной обработки исключительных ситуаций, возникших при работе с функциями InterBase API. Позволяет обрабатывать потерю подключения к базе данных, инициализацию пользовательских исключений в самой базе данных.

SuperlBAlerter - предназначен для регистрации и получения событий (event alerters) InterBase.

TIBConfigService - предназначен для настройки параметров базы данных.

TIBBackupService предназначен для создания резервных копий (backup) баз данных.

TpFIBRestoreService - предназначен для восстановления базы данных из резервной копии.

TpFIBValidationService - предназначен для проверки целостности базы данных и согласования внутренних данных о транзакциях.

TpFIB Statistical Service - предназначен для получения статистики о базе данных.

TpFIBLogService - предназначен для создания и просмотра лог-файла работы сервера.

TpFIBSecurityService - предназначен для редактирования списка пользователей на сервере.

TpFIBLicensingService - предназначен для добавления и удаления сертификатов, регулирующих количество и свойства клиентских подключений к серверу InterBase.

TpFIBServerProperties - предназначен для получения информации о сервере, параметров конфигурации и так далее.

TpFIBInstall предназначен для установки компонента InterBase installation.

TpFIBUnlnstall - предназначен для установки компонента InterBase un- installation.
Использование основных компонентов FIBPIus
В процессе более подробного рассмотрения вопросов использования компонентов FIBPIus мы постараемся создать очень простое приложение, которое будет предназначено для редактирования некоторого достаточно абстрактного прайс-листа. Этот пример позволит рассмотреть все основные аспекты работы с FIBPIus, с которыми так или иначе сталкивается практически каждый прикладной разработчик.
Наше приложение должно позволять редактировать категории товаров, список товаров для каждой категории и печатать прайс-лист. Нам понадобятся две таблицы: для категорий товаров и для списка товаров:
CREATE TABLE "Categories" (
"Id" INTEGER NOT NULL,
"Name" VARCHAR (50) character set WIN1251 collate PXW_CYRL,
"GoodsCount" INTEGER);
/* Unique keys definition */
ALTER TABLE "Categories" ADD CONSTRAINT "PK_Categories" PRIMARY
KEY ("Id");
SET TERM ^ ;
/* Trigger: "AI_Categories_Id" */
CREATE TRIGGER "AI_Categories_Id" FOR "Categories" ACTIVE
BEFORE INSERT POSITION 0
AS
BEGIN
IF (NEW."Id" IS NULL) THEN
NEW."Id" = GEN_ID("Categories_Id_GEN", 1);
END
^
SET TERM ; ^
CREATE TABLE "Goods" (
"Id" INTEGER NOT NULL,
"Name" VARCHAR (150) character set WIN1251 collate
PXW_CYRL,
"Price" DOUBLE PRECISION,
"IdCategory" INTEGER NOT NULL);
/* Unique keys definition */
ALTER TABLE "Goods" ADD CONSTRAINT "PK_Goods" PRIMARY KEY
("Id");
/* Foreign keys definition */
ALTER TABLE "Goods" ADD CONSTRAINT FK_GOODS FOREIGN KEY
("IdCategory") REFERENCES "Categories" ("Id") ON DELETE CASCADE
ON UPDATE CASCADE;
SET TERM ^ ;
/* Trigger: "AI_Goods_Id" */
CREATE TRIGGER "AI_Goods_Id" FOR "Goods" ACTIVE
BEFORE INSERT POSITION 0
AS
BEGIN
IF (NEW."Id" IS NULL) THEN
NEW."Id" = GEN_ID("Goods_Id_GEN", 1);
END
^
Очевидна связь master-detail между таблицами "Categories" и "Goods".
Обратите внимание, что мы с самого начала и в дальнейшем будем использовать особенности SQLDialect 3, который доступен в InterBase начиная с версии 6.0
Для печати прайс-листа мы будем использовать генератор отчетов FastReport f (http://www.fastreport.ru).
Подключение к базе данных, выполнение простых запросов
Рассмотрим с самого начала создание приложения, при помощи которого мы сможем редактировать прайс-лист. Необходимо поместить на форме основной компонент, который позволяет подключаться к базе данных InterBase (TpFIBDatabase) и вызвать редактор этого компонента (рис. 2.14 и 2.15).

Рис 2.14. Вызов редактора TpFIBDataBase

Рис 2.15. Bug редактора компонента TpFIBDataBase
Для подключения к базе как минимум необходимо указать путь (в данном примере это путь к локальному файлу), имя пользователя и пароль. Вы можете проверить правильность заданных параметров, нажав на кнопку Test. Мы также можем задать параметры подключения к базе в run-time, получив путь к базе данных из ini-файла:
procedure TMainForm.FormCreate(Sender: TObject);
begin
with TiniFile.Create('ib_price.ini') do begin
pFIBDatabasel.DBName := ReadString('Options', 'DBPath',
'C:\IBPRICE.GDB');
Free ;
end;
pFIBDatabasel.Open;
end;
Компонент TpFIBDatabase можно также использовать для выполнения запросов к базе данных, которые не возвращают в результате набора данных. Для этого существуют такие методы:
function Execute(const SQL: string): boolean;
function QueryValue(const aSQL: string;
FieldNo:integer):Variant;
function QueryValueAsStr (const aSQL: string,-
FieldNo:integer): String;
Например, мы можем выяснить количество категорий товаров, выполнив простой запрос:
SnowMessage(pFIBDatabasel.QueryValueAsStr('select count("Id")
from "Categories"', 0));
Управление транзакциями
Фактически любые действия с данными должны происходить в контексте той или иной транзакции. Управление транзакциями в FIBPlus осуществляется при помощи компонентов класса TpFIBTransacdon. Все транзакции в FIBPlus являются "явными" (explicit) и запускаются при помощи метода StartTransaction. Тем не менее, чтобы вы могли избежать лишнего кодирования, TpFIBDataSet и TpFIBQuery самостоятельно запускают транзакции, если установлен ключ poStartTrasaction в свойстве Options. Завершать транзакцию в любом случае необходимо явным образом при помощи вызова соответствующих методов: Commit, Rollback, CommitRetaining и RollbackRetaining
Метод CommilRetammg появится в InteiBase только начиная с версии 5.1, а метод RollbaekRetammg - только в версии 6.0.
Планируя внутреннюю организацию транзакций в приложении, необходимо помнить про уровень изоляции транзакций Можно указывать уровень изоляции транзакции явным образом при помощи соответствующих констант InterBase в свойстве TRPaiams или используя заранее заданные уровни изоляции при помощи свойства TPBMode. По умолчанию любой компонент TpTransaction, помещенный на форму, имеет уровень изоляции "Read Committed".
FIBPlus также позволяет создавать и запоминать в системном реестре пользовательские уровни изоляции (свойство UserKmdTransaction) Необходимо вызвать редактор компонента, нажав на нем правой кнопкой мыши, и выбрать пункт "Edit transaction params" (рис. 2.16).

Рис 2.16. Редактор компанента TpFIBTransaction
После нажатия на кнопку New Kind нужно указать название для набора констант и перечислить необходимые константы в поле Settings. Теперь нужно сохранить константы нажатием кнопки Save kind Описания всех констант вы можете узнать в документации к InterBase В дальнейшем, вы можете использовать собственные созданные наборы констант, выбирая названия из списка в свойстве UserKmdTiansaction
Закрытие транзакции также имеет ряд особенностей, которые необходимо иметь в виду разработчикам Если вы закрываете транзакцию вызовом методов Commit или Rollback, то все активные запросы, которые работают в контексте этой транзакции, будут также закрыты. Такое поведение непривычно для разработчиков, ранее использовавших в своих приложениях BDE, где подтверждение транзакции оставляло курсоры открытыми. Нужно подчеркнуть, что механизм, реализованный в BDE, является лишь эмуляцией. То есть фактически завершение транзакции просто вызывало невидимое автоматическое "переоткрытие" всех активных запросов. Кроме того, важно иметь в виду, что все запросы при использовании BDE работают в контексте одной и той же транзакции, в отличие от FDBPlus, где каждый запрос может работать в рамках своей отдельно взятой транзакции.
Тем не менее если вы не хотите, чтобы подтверждение транзакции вызывало закрытие всех активных TpFIBDataSet, то вы можете использовать метод CommitRetaining. Этот метод подтверждает транзакцию и автоматически запускает новую с теми же самыми параметрами, не закрывая при этом пользовательских курсоров (запросов, выбирающих данные)
Данный метод содержал ошибку реализации, поэтому не рекомендуется слишком часто вызывать CommitRetaining для версий Intel Base меньше чем 6.5.
То же самое касается и метода RollbackRetaining, который отменяет изменения, сделанные в контексте транзакции и запускает новую.
Данный метод появился в InteiBase версии 6.0.
Использование стандартных визуальных db-компонентов совместно с FIBPIus
Следующий этап - получение данных из базы данных и отображение этих данных при помощи визуальных компонентов (рис. 2.17).

Рис 2.17. Подключение визуальных компонентов к TpFIBDataSet
Для этого нам необходимы два компонента. TpFIBDataSet HTpFTBTiansdction. TpFIBDataSet является потомком класса TDataSet и полностью совместим со всеми стандартными визуальными компонентами. Для связки TpFIBDataSet с визуальным компонентом CategoriesGrid (TDBGrid) компонент CategoriesDataSource подключен к CategoriesDataSet. TpFIBTransaction, как уже было сказано, предназначен для управления транзакцией.
Необходимо указать уровень изоляции транзакции при помощи свойства TPBMode, а также "подключить" CategoriesTransaction к pFIBDatabasel (2.18).

Рис 2.18. Подключение транзакции к компоненту pFIBDataBasel
Аналогично необходимо указать свойства Database и Transaction для компонента CategoriesDataSet (рис. 2.19).

Рис 2.19. Подключение компонента CategoriesDataSet к pFIBDataBasel и транзакции CategoriesTransaction
Теперь мы можем указать необходимые запросы к базе данных для получения и изменения данных в таблице Нужно написать запрос для получения данных, используя свойство SelectSQL. В нашем случае это будет очень простой запрос:
SELECT * FROM "Categories"
Теперь изменим немного код в процедуре:
procedure TMainForm.FormCreate(Sender: TObject);
begin
with TiniFile.Create('ib_price.ini') do begin
pFIBDatabasel.DBName := ReadString('Options', 'DBPath',
'C:\IBPRICE.GDB');
Free ;
end;
pFIBDatabasel.Open;
CategoriesDataSet.Open;
end;
В свойстве DataSet у компонента CategoriesSource (TDataSource) мы укажем CategoriesDataSet, а в свойстве DataSource у компонента CategoriesGrid (TDBGrid) укажем CategoriesSource. Теперь все данные, полученные в результате запроса, будут отображены в CategoriesGrid. Нам не нужно явным образом запускать транзакцию перед открытием запроса, поскольку по умолчанию свойство CategoriesDataSet.Options содержит ключ poStartTransaction и компонент сам запускает транзакцию После запуска приложения и открытия базы данных мы увидим следующий результат (рис. 2.20):

Рис 2.20. Вид запущенного приложения
Вместо CategoriesGrid мы могли использовать любой визуальный db-компонент, который используется в связке с TDataSource. Это мог быть TDBEdit, TDBLabel, TDBMemo и т. д., а также любые сторонние компоненты, которые придерживаются данного стандарта (TDBGridEh, например).
Как сделать запрос редактируемым? Автоматическая генерация модифицирующих запросов в design-time и run-time
Если вы попробуете исправить какие-то значения в CategoriesGrid, то увидите, что в текущем состоянии мы имеем iead-only-запрос Для того чтобы наш запрос стал редактируемым, или "живым", нам надо написать несколько дополнительных запросов, которые будут автоматически выполнятся компонентом CategonesDataSet при редактировании данных в CategoriesGrid. Необходимо заполнить свойства (рис. 2.21).

Рис 2.21. Свойства CategonesDataSet с запросами для чтения и модификации данных
FIBPlus включает специальный design-time-редактор для редактирования и генерации модифицирующих запросов. Вы можете вызвать "Generator SQLs" из контекстного меню, если нажмете правой кнопкой мыши на компоненте CategonesDataSet (рис. 2.22)
Для генерации модифицирующих запросов необходимо сначала указать основную таблицу в списке Если в запросе участвует только одна таблица, то она будет выбрана в списке автоматически После этого необходимо нажать кнопку Get Table Fields для заполнения списков "Key Fields" и "Update Fields '. В первом списке нужно выделить те поля, которые будут вставлены в условие WHERE во всех модифицирующих запросах. В списке "Update Fields" необходимо выделить те поля, которые мы хотим редактировать. По умолчанию выделены все поля таблицы "Categories" Теперь достаточно нажать кнопку Generate SQLs и получить автоматически все модифицирующие запросы, которые вы можете увидеть на закладке SQLs Например, мы получим следующий запрос для свойства InsertSQL
INSERT INTO "Categories"(
"Id" ,
" Name" ,
"GoodsCount"
)
VALUES(
:"Id",
:"Name",
:"GoodsCount"
)

Puc 2.22. Редактор компонента TpFIBDataSet, предназначенный для генерации модифицирующих запросов
Обратите внимание также на запрос для свойства RefreshSQL:
select * from "Categories"
WHERE
(
"Categories"."Id" = :"OLD_Id"
)
Это такой же выбирающий запрос, как и запрос в свойстве SelectSQL, но возвращать он должен только одну запись - текущую Теперь, после создания всех запросов, когда пользователь будет редактировать запись в CategoriesGrid, CategonesDataSet автоматически заполнит значения параметров : "Id", . "Name" и т д., теми значениями полей, которые наберет пользователь. После выполнения метода Post (который, в частности, вызывается при нажатии клавиши Enter в CategonesGnd) CategoriesDataSet выполнит соответствующий модифицирующий запрос После редактирования записи будет выполнен запрос из свойства UpdateSQL, при вставке новой записи - из InsertSQL, а при удалении записи - из DeleteSQL После выполнения любого модифицирующего запроса (кроме удаления) CategoriesDataSet автоматически выполняет запрос из RefreshSQL, подставляя в качестве условия текущие значения параметров. Это позволяет "узнать" значения всех полей текущей записи, если они были изменены при помощи триггеров базы данных.
Несколько слов о специальных префиксах для параметров, которые используются в FIBPlus.
Префикс "OLD_" фактически означает текущее значение одноименного поля или же предыдущее значение поля Термин "предыдущее значение" имеет смысл в запросе на удаление. Во всех остальных случаях, когда нужны актуальные значения полей, можно обходиться без данного префикса.
Префикс "NEW_" означает новое значение поля и фактически имеет смысл только в запросах на изменение и вставку. Однако новые значения полей в этих ситуациях также являются и текущими, а значит, префикс "NEW_" можно опускать
Существует также специальный префикс "MAS_", но мы доберемся до него несколько позже.
Поскольку мы сгенерировали все необходимые модифицирующие запросы, то уже можем запустить наше приложение, добавить пару категорий, изменить их названия и даже целиком удалить их.
Тем не менее генерация модифицирующих запросов в design-time не всегда удобна FIBPIus позволяет разработчику автоматически генерировать нужные запросы во время работы приложения, основываясь на запросе из свойства SelectSQL Для этого нужно использовать свойство AutoUpdateOptions (рис 223).
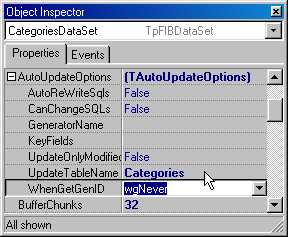
Рис 2.23. Комплексное свойство AutoUpdateOptions
Необходимо "включить" ключ "AutoReWriteSqls", указать ключевое поле, которое будет использовано в условиях WHERE (в нашем случае, это поле "Id") и указать название модифицируемой таблицы ("Categories"), поскольку в реальности запросы могут быть многотабличными. Теперь свойства InsertSQL, DeleteSQL, UpdateSQL и RefreshSQL будут генерироваться автоматически при открытии CategonesDataSet. To есть фактически мы имеем генератор запросов в run-time, что бывает очень удобно.
Есть еще один момент, связанный с генерацией модифицирующих запросов Например, если мы редактируем только название категории, то после нажатия на Entei на сервер будет отправлен запрос, в котором изменены два поля и Name и GoodsCount Фактически же мы изменяли только одно поле - "Name".В итоге если запись таблицы содержит значительный объем данных (например, длинные строковые поля), то при малейшем исправлении даже одного поля на сервер будут "уходить" все данные. При многопользовательской работе это создаст дополнительный лишний трафик Данной ситуации можно избежать но для этого необходимо, чтобы приложение выполняло 6oлee эффективные изменяющие запросы, например запрос:
UPDATE "Categories" SET
"Name" = ."Name"
WHERE
"Id" = :"OLD_Id"
в котором, как вы видите, участвует только то поле, значение которого действительно было изменено. Такая возможность существует, если мы включим ключ UpdateOnlyModifiedFields (разумеется, этот ключ действует, только если мы используем режим генерации запросов в run-time). В случае редактирования только поля "Name" компонент CategoriesDataSet автоматически сгенерирует запрос, приведенный выше, и будет генерировать каждый раз новые запросы в зависимости от того, какие поля изменялись.
Поскольку теперь наш CategoriesDataSet стал модифицируемым, то мы можем написать обработчики событий OnClick у трех кнопок справа от CategoriesGrid:
procedure TMainForm AddCatButtonClick(Sender TObject);
begin
CategoriesDataSet Append;
end;
procedure TMainForm.EditCatButtonClick(Sender: TObject);
begin
CategoriesDataSet Edit;
end;
procedure TMainForm.DeleteCatButtonClick(Sender: TObject);
begin
if MessageDlg('Вы уверены, что хотите удалить категорию "' +
CategoriesDataSet.FieldByName('Name').AsString + '"?',
mtConfirmation,
[mbYes, mbNo], 0) = mrYes then
CategoriesDataSet.Delete;
end;
Правильный способ использования auto-increment полей в FIBPIus
В текущем состоянии наш запрос уже является редактируемым, мы можем вставлять новые записи, удалять записи существующие, а также редактировать значения полей Тем не менее пользователь должен самостоятельно указывать значение ключевого поля "Id", чтобы каждая запись была уникальной. Разумеется, мы можем переложить заботу о генерации уникальных значений на базу данных, написав соответствующий триггер, который при вставке новой записи будет автоматически получать новое уникальное значение из некоторого 1енерагора. Такой способ гарантирует уникальность значений, но не гарантирует правильность работы клиентского приложения.
Особенность использования генераторов при написании корректно работающих приложений на FIBPlus состоит в том, что мы должны получать новое значение генератора в приложении до того, как выполним запрос на вставку записи. Зачем это нужно? Дело в том, что, как уже было сказано, после выполнения любого модифицирующего запроса (кроме удаления) CategoriesDataSet автоматически выполняет запрос из RefreshSQL, подставляя в качестве условия текущие значения параметров. В нашем случае для подстановки надо использовать значение первичного ключа (поле "Id"). Если мы не получим его заранее, а будем генерировать его, используя триггер, то мы не сможем подставить значение параметра : "OLD_Id" в запрос RefreshSQL, а значит, не сможем перечитать измененную запись. Таким образом, если какие-то поля записи были изменены триггерами базы данных, то мы не увидим этих изменений, пока не переоткроем весь запрос целиком Если же мы сначала получим новое значение генератора, а потом вставим это значение наравне с остальными параметрами, то затем мы сможем использовать это же значение, чтобы "перечитать" текущую запись, и будем "в курсе" актуальных значений полей без излишних переоткрываний!
TpFIBDataSet позволяет автоматически получать и вставлять значения первичного ключа, используя генератор. Для этого нам необходимо заполнить некоторые дополнительные ключи в свойстве AutoUpdateOptions (рис. 2.24).
Нужно указать название генератора Categories_Id_GEN. Свойство WhenGetGenID может принимать три возможных значения:
wgOnNewRecord - получать значение генератора сразу после подготовки буфера для новой записи;
wgBeforePost - получать значение генератора непосредственно перед отправкой новой записи на сервер;
wgNever- не использовать механизм генерации ключевых значений.
В нашем примере мы укажем значение wgOnNewRecord, чтобы сразу видеть в CategoriesGrid те значения поля "Id", которые будут получены с сервера. Теперь мы можем запустить наше приложение и отредактировать какие-либо существующие записи и даже вставить новые записи (рис. 2.25).

Рис 2.24. Использование AutoUpdateOptions для генерации уникальных значений первичного ключа

Рис 2.25. Внешний вид "живого" запроса
Из рисунка видно, что было автоматически получено значение для поля "Id" равное 66
Разделенные транзакции: уникальная возможность избежать Deadlock. Режим AutoCommit
CategoriesDataSet позволяет автоматически подтверждать сделанные изменения, если задать свойство AutoCommit в True. Теперь после вызова метода Post компонент CategoriesDataSet будет автоматически вызывать CategonesTransaction CommitRetainmg, сохраняя сделанные пользователем изменения и не закрывая при этом сам запрос. Такой подход уже снижает вероятность Deadlock, который возможен при наличии длинных незакрытых транзакций, в контекст которых производились изменения данных.
Тем не менее, FIBPlus предлагает другую возможность, которая сводит вероятность возникновения Deadlock практически к нулю. TpFIBDataSet может работать одновременно в контексте двух транзакций. Одна длинная транзакция, в контексте которой данные только читаются, и другая короткая транзакция, в контексте которой выполняются все модифицирующие запросы.
Переименуем CategoriesTransaction в CategoriesReadTransaction и добавим еще один компонент CategoriesWriteTransaction. После этого зададим свойство UpdateTransaction у CategoriesDataSet в CategoriesWriteTransaction. Таким образом, теперь CategoriesDataSet подключен сразу к двум компонентам TpFTBTransaction (рис. 2.26).

Рис 2.26. Разделение читающей и пишущей транзакций
После вызова метода Post компонент CategoriesDataSet будет вызывать метод Commit у компонента CategoriesWriteTransaction. Однако, учитывая, что данные читаются в контексте совсем другой транзакции (CategoriesReadTransaction), это не вызовет закрытия всего CategoriesDataSet. To есть, используя FIBPlus, мы имеем настоящий режим AutoCommit, который уменьшает вероятность Deadlock и не мешает "видеть" нам актуальные значения всех записей. При использовании BDE в режиме AutoCommit вы не могли бы узнать реальные значения записей, пока не переоткроете запрос.
Кроме того, как уже упоминалось, для InterBase до версии 6.5 слишком частый вызов CommitRetaining мог привести к значительному "захвату" ресурсов сервером. При использовании механизма разделенных транзакций вы можете использовать режим AutoCommit без потерь производительности сервера для любых версий InterBase.
Механизм master-detail. Специальные опции TpFIBDatabase и TpFIBDataSet
Мы имеем возможность редактировать данные о категориях товаров и можем переходить к вопросам, связанным с построением связки master-detail. Для этого мы положим на форму дополнительные компоненты:
GoodsSource: TDataSource;
GoodsGrid: TDBGrid;
GoodsDataSet: TpFIBDataSet;
GoodsReadTransaction: TpFIBTransaction;
GoodsWriteTransaction: TpFIBTransaction;
AddGoodsButton: TButton;
EditGoodsButton: TButton;
DeleteGoodsButton: TButton;
"Свяжем" их так же, как и предыдущую группу компонентов, и напишем SelectSQL для GoodsDataSet:
SELECT * FROM "Goods"
WHERE "IdCategory" = :"Id"
Очевидно, что мы хотим выбрать при помощи detail-запроса только те товары, которые относятся к текущей категории. Значение параметра : "Id" должно браться из поля "Id" таблицы "Categories". Чтобы это происходило автоматически, необходимо задать свойство GoodsDataSet.DataSource равным CategoriesSource. Теперь сгенерируем модифицирующие запросы для GoodsDataSet так же, как мы делали это раньше для CategoriesDataSet.
После автоматической генерации мы должны внести некоторые изменения в полученные запросы. Рассмотрим, в частности, запрос для InsertSQL:
INSERT INTO "Goods"(
"Id",
"Name",
"Price",
"IdCategory" )
VALUES(
:"Id",
:"Name",
:"Price",
:"IdCategory"
)
Очевидно, что при добавлении нового товара, мы должны задать параметр : "IdCategory" текущим значением поля "Id" из таблицы "Categories". FIBPlus позволяет делать это автоматически при помощи префикса "MAS_", о котором мы уже упоминали выше:
INSERT INTO "Goods"(
"Id" ,
"Name",
"Price",
"IdCategory" )
VALUES(
:"Id",
:"Name",
:"Price",
:"MAS_Id"
)
Теперь мы указали явным образом, что значение для поля "Goods"."IdCategory" нужно брать из поля "Id" таблицы "Categories", которая является master- таблицей для таблицы "Goods". To же изменение необходимо внести в запрос UpdateSQL
UPDATE "Goods" SET
"Id" = :"Id",
"Name" = :"Name",
"Price" = :"Price",
"IdCategory" = :"MAS_Id"
WHERE
"Id" = 'OLD_Id"
Теперь изменим немного код в процедуре FormCreate:
procedure TMainForm.FormCreate(Sender: TObject);
begin
with TimFile. Create (' ib_price. mi ') do begin
pFIBDatabasel.DBName := ReadStringt'Options', 'DBPath',
'C:\IBPRICE.GDB');
Free;
end;
pFIBDatabasel.Open;
CategoriesDataSet.Open;
GoodsDataSet.Open;
end;
He забудем заполнить свойства AutoUpdateOptions, чтобы GoodsDataSet автоматически генерировал значения первичного ключа (рис 2 27)
Можно запустить приложение Двигаясь вверх и вниз по CategoriesGrid, вы можете наблюдать, как автоматически изменяется содержимое в GoodsGrid Связка master-detail уже работает.
FIBPlus позволяет также настраивать некоторые особенности работы механизма master-detail. В частности, как вы уже обратили внимание, в нашем примере мы открывали detail-dataset (GoodsDataSet) "вручную", при помощи явного вызова метода Open В случае с простой связкой это нетрудно, однако если мы используем несколько цепочек master-detail или более длинные цепочки - master-detail-subdetail, то ручное открытие всех запросов может даже привести к ошибке. Вы всегда должны открывать подчиненный запрос после основного.
Чтобы избежать ненужного и совершенно очевидного кодирования, TpFEBDataSet содержит специальное свойство DetailConditions (рис. 2.28).

Рис 2.27. Использование AutoUpdateOptions длл генерации значений первичного ключа GoodsDdtabet

Рис 2.28. Свойаво DetailConditions
Задав ключ dcForceOpen. мы можем быть совершенно уверены, что detail- запрос будет автоматически открыт после открытия master-запроса. Теперь мы можем удалить строку GoodsDataSet.Open из метода CreateForm. Какова бы ни была глубина связок master-detail, все запросы будут открыты в нужном порядке.
Вторая важная опция - это ключ dcWaitEndMastei Scroll Представьте, что пользователь передвигается по CategonesGrid, пытаясь найти нужную категорию товаров. При каждом движении, когда меняется текущая запись в CategoriesGrid, GoodsDataSet автоматически открывает запрос заново. Очевидно, движение по mastei-таблице может вызвать серию довольно "тяжелых" запросов, которые значительно увеличат совершенно бесполезный сетевой трафик. На практике было нужно переоткрыть detail-запрос только один раз, когда пользователь все-таки нашел нужную ему категорию в CategoriesGrid. FIBPlus позволяет избежать ненужных запросов. Если ключ dcWaitEndMasterScroll добавлен в DetailConditions, то detail-запрос переоткрывается только после некоторой паузы (величину паузы можно регулировать, задавая значение свойства WaitEndMasterlnterval).
Таким образом, когда пользователь просто передвигается по CategoriesGrid, изменение текущей записи "включает" таймер detail-запроса. Если за время паузы пользователь успевает перейти на другую запись, то таймер сбрасывается. И так до тех пор, пока пользователь не остановится на нужной записи. Только после этого detail-запрос переоткрывается, а значит, GoodsDataSet выполняет только один запрос вместо целой серии.
Третий важный ключ в DetailConditions управляет поведением master- таблицы при изменении detail-таблицы. В нашем примере в таблице "Categories" существует поле "GoodsCount", в котором содержится количество наименований товаров для текущей категории. Когда мы добавляем или удаляем наименование товара из категории, то это значение должно меняться. Очевидно, что данный механизм легко реализуется парой триггеров для таблицы "Goods":
CREATE TRIGGER "Goods_AI" FOR "Goods" ACTIVE
AFTER INSERT POSITION 0
AS
BEGIN
update "Categories" set
"GoodsCount" = (select count("Id") from "Goods" where
"IdCategory" = New."IdCategory")
where "Id" = New."IdCategory";
END^
CREATE TRIGGER "Goods_BD" FOR "Goods" ACTIVE
BEFORE DELETE POSITION 0
AS
BEGIN
update "Categories" set
"GoodsCount" = (select count("Id") from "Goods" where
"IdCategory" = Old."IdCategory")
where "Id" = Old."IdCategory";
END^
Давайте рассмотрим последовательность происходящих действий, например при добавлении нового наименования товара для какой-то категории.
В GoodsDataSet формируется значение ключевого поля "Id" при помощи генератора.
Значения полей заполняются пользователем.
После нажатия пользователем клавиши Enter GoodsData подготавливает запрос из свойства InsertSQL к выполнению и заполняет значения параметров соответствующими значениями полей.
Параметр :"IdCategory" заполняется текущим значением поля "Id" из CategoriesDataSet.
Запрос выполняется и выполняется триггер "Goods_AI".
Транзакция GoodsWriteTransaction автоматически подтверждает сделанные изменения при помощи метода Commit.
Выполняется запрос из свойства RefreshSQL, который перечитывает значения полей вставленной в таблицу "Goods" записи, основываясь на известном значении ключевого поля "Id".
В этот момент значение поля "GoodsCount" уже изменилось, но это изменение никак не отражается в CategoriesGrid. Мы должны обновить текущую запись в CategoriesDataSet, чтобы увидеть актуальное значение всех полей. Это можно сделать при помощи явного вызова метода CategoriesDataSet.Refresh. Однако этот же метод нам надо будет вызывать и в случае удаления записи из GoodsDataSet. А если бы нам нужно было создать более сложный механизм взаимодействия между master и detail-таблицами, то, скорее всего, метод Refresh нужно было бы вызывать также и после многих других операций.
Вместо всего этого мы можем просто добавить ключ dcForceMasterRetresh. Этот ключ автоматически вызывает метод Refresh у master, если detail была изменена. Если вы запустите приложение, то сами увидите, что значение поля "GoodsCount" автоматически изменяется при добавлении и удалении записей в GoodsDataSet.
Специальные опции в компонентах FIBPIus
Опции и настройки TpFIBDatabase
TpFIBDatabase содержит ряд специальных свойств, которые управляют режимами работы компонента. Мы уже описывали основные вещи, связанные с подключением к базе данных, однако некоторые особенности TpFIBDatabase остались "за кадром".
Хочется начать с описания механизма поддержки Alias в FIBPIus. Те из вас, кто уже работал с Interbase через Borland Database Engine, наверняка знают про существование такого понятия, как Database Alias, т. е. псевдоним базы данных. С точки зрения BDE Database Alias - это не что иное, как ряд параметров подключения к базе данных, которые хранятся в системном реестре Windows. Программист, который разрабатывает пользовательскую программу, подключающуюся к базе данных, может не указывать реальные параметры подключения, а просто "сослаться" на существующий алиас. Таким образом, если потом, например, хотелось поменять путь к базе данных, то достаточно было изменить информацию в алиасе и перезапустить программу.
Аналогичный механизм реализован и в FIBPIus. Вы можете задать свойство TpFIBDatabase.AliasName и забыть про такие параметры, как путь к базе данных, имя пользователя, character set, SQL Role и SQL Dialect. При запуске программы, если значение свойства AliasName не пустое, TpFIBDatabase будет пытаться получить значения соответствующих свойств из системного реестра. Встает вопрос: а как записать туда первоначальные значения? Для этого существует два способа.
Первый заключается в том, что вы устанавливаете свойство SaveDBParams в True, после чего все необходимые свойства автоматически сохраняются в системном реестре, как только вы подключитесь к базе данных. Фактически это одноразовая операция: установили свойства и имя алиаса, установили SaveDBParams в True, подключились к базе данных - параметры алиаса сохранены. Отключились от базы данных, выставили SaveDBParams в False. Теперь при последующих подключениях значения для свойств буду) брался из системного реестра.
Второй способ - использование утилиты AliasManager, которая написана специально для того, чтобы можно было настраивать значения алиасов на любом клиентском месте без сред Delphi и C++ Builder. Иными словами, вы можете использовать эту утилиту на тех компьютерах, на которые установите свою программу. Мы не будем приводить здесь описание утилиты, поскольку ее использование достаточно очевидно само по себе (рис. 2.29).

Рис 2.29. Внешний вид Alias Manager
Достаточно удобным и полезным также является свойство DesignDBOptions. Если выставить ключ ddoIsDefaultDatabase в True, то у всех компонент (TpFIBDataSet, TpFIBQuery, TpFIBTransaction), которые вы потом положите на форму, автоматически будет заполняться свойство Defaul(Database (или Database). Ключ ddoStoreConnected указывает - сохранять ли значение свойства TpFIBDatabase.Active при сохранении формы или проекта. Дело в том, что активное состояние базы данных зачастую бывает полезно в процессе разработки, когда мы используем визуальные средства FIBPlus: Database Editor, Transaction Editor, SQL Generator и различные свойства. Тем не менее, сохраняя активное подключение (а значит, и автоматически восстанавливая его при загрузке программы!), мы можем получить ошибку в работе приложения, которое может попытаться открыть уже активное подключение. Чтобы избежать подобной накладки, вы можете выставить свойство ddoStoreConnected в False.
Свойство SynchronizeTime предназначено для правильного вычисления default-значений полей. Вы знаете, что в Interbase существуют специальные функции для работы с датами и временем: NOW и CURRENT_TIME (в Firebird). Эти функции часто ИСПОЛЬЗУЮТ при описании полей:
CREATE TABLE NODES_LIST (
ID INTEGER NOT NULL,
INSERTED TIME NOT NULL DEFAULT 'NOW'
);
При вставке записи с пустым значением поля INSERTED сервер автоматически подставит текущее время. Однако существует некоторая особенность при работе клиентской части программы. Как вы понимаете, чтобы работать с таблицей NODES_LIST, нам придется заполнять значения свойств SelectSQL, InsertSQL, DeleteSQL, UpdateSQL и RefreshSQL у некоторого компонента TpFIBDataSet. При вставке TpFIBDataSet проверяет свойства полей таблицы и пытается автоматически заполнить поля новой записи значениями по умолчанию. В нашем случае он должен присвоить полю INSERTED текущее время. Однако поскольку мы можем иметь дело с сетевой системой, то время на сервере может отличаться от времени на клиентской машине. В нашем гипотетическом примере это, возможно, и не играет никакой роли, однако могут быть случаи, когда необходимо подставлять точное "серверное" время. Для этого и используется свойство SynchronizeTime. Если оно выставлено в True, то при подключении к базе данных TpFIBDatabase выясняет "разницу во времени" между сервером и клиентским компьютером, чтобы впоследствии подставлять правильные значения.
Свойство UpperOldNames было введено в FIBPlus на этапе перехода с Interbase 5.x на Interbase 6.x. Как вы знаете, в 3-м SQL Dialect Interbase 6.x позволяет использовать "регистро-чувствительные" имена объектов. В старых версиях Interbase имена INSERTED и inserted являлись одинаковыми, поэтому программисты в своих программах не придерживались точного написания. В частности, можно было писать и следующее:
MainDS.FieldByName('COST').AsFloat :=
ainDS.FieldByNamet'cost').AsFloat * 0,3;
И это работало без ошибок. Однако если просто перенести базу на Interbase 6.x и запустить то же самое приложение, то оно начинало работать с ошибками, поскольку поле COST действительно существовало, а вот поле cost - уже нет. Фактически подобная миграция означала, что нужно было проверять все приложение, чтобы найти подобные подводные камни. FIBPlus позволяет обойтись без подобных мероприятий. Если выставить UpperOldNames в True, то любые идентификаторы, в которых явным образом не используются двойные кавычки, приводятся "внутри" к верхнему регистру, а значит, запись
MainDS.FieldByName('COST').AsFloat :=
ainDS.FieldByName('cost').AsFloat * 0,3;
снова начинает работать без проблем.
Опции и настройки TpFIBDataSet
TpFIBDataSet содержит гораздо больше настроек, которые регулируют его работу. Будет трудно, пожалуй, выбрать наиболее важные, поскольку все они предназначены для совсем разных задач, а поэтому начнем по порядку.
AllowedUpdateKinds. Свойство представляет собой множество из трех элементов: [okModity. uklnsert, ukDelete]. Достаточно очевидно, что, используя это свойство, мы можем разрешать и запрещать выполнение определенных модифицирующих операций TpFTBDataSet. не изменяя при этом свойства InsertSQL. DeleteSQL и UpdateSQL. To есть мы можем получить TpFIBDataSet, который будет считаться "живым", но не будет позволять, например, вставлять новые записи! Это, кстати, одна из стандартных проблем при работе с компонентом TDBGrid, который не позволяет ограничивать изменение данных, — он либо "совсем" редактируемый (а значит, пользователь может изменять поля, удалять записи и вставлять новые), либо "совсем" нередактируемый. При работе с FIBPlus мы можем регулировать это поведение без необходимости писать какие-то специальные обработчики событий. Есть и еще одна особенность в свойстве AllowedUpdateKinds. Как вы уже в курсе, Interbase позволяет регулировать права доступа к объектам базы данных. Таким образом, может возникнуть ситуация, когда конкретный пользователь, работающий с вашей программой, не имеет прав на удаление записей из конкретной таблицы. Писать для каждого пользователя отдельную программу, очевидно, слишком накладно. Однако TpFIBDataSet легко справляется с проблемой, поскольку если при попытке "скомпилировать" конкретный модифицирующий запрос компонент получает от сервера сообщение об ошибке из-за отсутствия прав, то TpFIBDataSet просто запрещает данное действие, убрав соответствующий элемент из свойства AllowedUpdateKinds. Дальнейшие попытки просто, таким образом, пресекаются, а пользователь работает с программой, даже не подозревая об ошибках или отсутствии прав.
Свойство DefaultFormats используется при заполнении свойства DisplayFormat у объектов TField при открытии запроса. Поэтому, если вы хотите автоматически задавать какой-то нужный вам формат представления, например, числовых полей, то вам достаточно указать его в DefaultFormats.NumericDisplayFormat. Правила заполнения масок можно прочитать в описании свойства DisplayFormat у стандартного класса TField.
Свойство Options тоже управляет режимами работы TpFIBDataSet, причем надо иметь в виду, что эти опции управляют поведением TpFIBDataSet уже после открытия запроса или в момент редактирования данных:
poTrimCharFields - среди разработчиков идут постоянные споры, должны ли компоненты для работы с Interbase "обрезать" конечные пробелы у строковых полей или нет. С одной стороны, дополнение пробелами - это описанная техническая особенность Interbase, а с другой стороны - это не всегда удобно для пользователя. Нет нужды спорить, если можно отрегулировать этот процесс в отдельно взятом приложении (и даже в отдельно взятом запросе) Включив ключ PoTrimCharFields, вы можете быть уверены, что пробелов в конце строковых полей не будет.
poRep-eshAperPost позволяет вам отключить выполнение "обновляющего" запроса после редактирования записи. Как уже было сказано, после операции Post TpFIBDataSet автоматически выполняет запрос из свойства RefreshSQL, чтобы получить актуальные значения всех полей измененной записи, поскольку они могли быть изменены при помощи триггеров. Это дополнительный запрос, и если вы считаете, что в нем нет никакой нужды (например, вы точно уверены, что никакие триггеры не изменяют записи в таблице), то вы можете отключить этот режим.
При включенной опции poRefreshDeletedRecord если в результате выполнения RefreshSQL запрос ничего не вернул (в частности, это может произойти, если запись была удалена другим пользователем), то TpFIBDataSet также удалит ее из внутреннего буфера.
poStartTransaction отвечает за автоматический запуск транзакции перед открытием запроса, если транзакция еще не была активна. Если вы предпочитаете вызывать метод StartTransaction вручную, то можете отключить данную опцию.
poAutoFormatFields разрешает или запрещает автоматическое форматирование полей на основе форматов, заданных в свойстве DefaultFormats.
poProtectEdit руководит режимом "защищенного" редактирования. Этот режим иногда полезен, если вы хотите избежать коллизий при редактировании одной и той же записи разными пользователями. Если активизировать режим, то, как только вы начинаете редактировать запись (но до вызова метода Post), на сервер отправляется так называемый "холостой" update вида:
UPDATE TABLE
SET FIELD1 = FIELD1,
FIELD2= FIELD2, ...
To есть запрос, который формально является редактированием записи, а фактически не изменяет значения полей. Тем не менее сервер считает, что изменения произошли, а значит, пользователь, который первым начал редактирование, имеет преимущество перед всеми последующими. Фактически это эмуляция режима блокировок на уровне записей. Проблема, однако, состоит в том, что в Interbase не существует возможности отменить UPDATE, не отменив транзакции целиком. Поэтому даже если пользователь начал редактирование записи, а потом отказался и метод Post так и не был вызван, то запись все равно будет считаться измененной до конца транзакции. Кроме того, данный режим практически совершенно бесполезен, если вы используете режим работы в контексте двух транзакций, как это было описано выше, поскольку "блокировка" действует только до конца изменяющей транзакции.
Опция poKeepSorting нужна, если вы используете методы локальной сортировки DoSort и DoSortEx. Эти методы выполняют сортировку записей внутри локального буфера (без запроса на сервер). При изменении значений полей возможна ситуация, что измененная запись должна быть помещена в другое место (если изменилось, например, значение поля, по которому записи отсортированы). При активной опции poKeepSorting, после изменения записи, весь буфер автоматически сортируется и запись "встает" на нужное место.
poPersistentSorting - при активной опции, если вы вызывали методы DoSort или DoSortEx, то после переоткрытия запроса результат будет автоматически отсортирован вызовом DoSort с теми же параметрами.
Опция poAllowChangeSQLs блокирует или разрешает изменение свойств InsertSQL, DeleteSQL, UpdateSQL и RefreshSQL при открытом запросе.
Свойство PrepareOptions, в отличие от Options, позволяет задать некоторые особенности поведения TpFEBDataSet до открытия запроса:
pfSetRequiredFields - если опция активна, то для полей, которые в базе данных были описаны как NOT NULL, свойство TField.Required будет выставлено в True Если пользователь попробует не задать значение для таких полей, например, в TDBGnd, то на экран будет выведено стандартное предупреждение
При включенной опции pfSetReadOnlyFielcls для полей, которые описаны в базе как вычислимые (а значит, не изменяемые пользователем), свойство TField ReadOnly будет выставлено в True Это позволит избежать попыток изменения значений таких полей пользователем.
pflmportDefaultValues - данная опция включает и выключает режим, при котором TpFIBDataSet будет автоматически заполнять поля их значениями по умолчанию при вставке новой записи.
Опция psUseBooleanFields включает или выключает режим эмуляции Boolean-полей Вы знаете, что Interbase не поддерживает специальный тип для логических значений и разработчики вынуждены так или иначе заменять его своим пользовательским типом. Однако даже пользовательские типы не дают равноценной замены Boolean-типу, поскольку визуальные компоненты все равно видят такие поля либо как числовые, либо как строковые в зависимости от описания Таким образом, пропадает возможность использования каких-то специальных возможностей отображения логических полей визуальными компонентами (например, многие сторонние компоненты наподобие TDBGrid отображают логические поля галочками). FIBPlus позволяет эмулировать Boolean-поля гораздо более эффективно. Необходимо описать в базе данных домен вида:
CREATE DOMAIN T_BOOLEAN
AS INTEGER DEFAULT 0
NOT NULL CHECK (VALUE IN (0,1))
Поле должно быть целочисленным и содержать в названии слово "boolean". После этого все поля, которые вы создадите с использованием данного домена, будут "распознаваться" в FIBPlus как Boolean-поля, т. е. для них будут создаваться экземпляры класса TFIBBooleanField, который является прямым потомком стандартного TBooIeanField, значит, любой визуальный компонент будет работать с такими полями как с настоящими Boolean!
psSQL!NT64ToBCD - опция заставляет TpFIBDataSet создавать экземпляры TBCDField для полей INT64 с любым масштабом (в SQL Dialect 3), что гарантирует точность вычислений для любых полей INT64.
psApplyRepositary - опция включает или выключает режим использования FIBPlus Repository. Эта особенность FIBPlus требует отдельного разговора, и мы вернемся к ее рассмотрению позже в отдельном параграфе.
psGetOrderlnfo - при включенном режиме, FIBPlus анализирует запрос перед выполнением и автоматически заполняет структуру SortFields данными о полях, по которым происходит сортировка в запросе. Впоследствии это может быть использовано в методах локальной сортировки DoSort и DoSortEx
Опция psAskRecordCount предназначена для получения информации о количестве записей, которые должен вернуть запрос, до выполнения, собственно, запроса Дело в том, что фактически, значение свойства TpFIBDataSet RecoidCount показывает лишь количество записей, которые мы уже получили с сервера Это число может отличаться от полного количества записей, поскольку если мы не вызывали метод FetchAll, то сервер "отдает" нам записи по мере необходимости (при вызове метода Next). Иногда бывает полезно узнать точное количество заранее В этом случае нужно включить опцию psAskRecordCount. Однако необходимо учитывать, что данная опция имеет ряд ограничений. Поскольку единственным способом узнать количество записей в запросе заранее является выполнение другого запроса вида SELECT COUNT (*) с теми же условиями, что и в основном запросе, то для некоторых запросов мы выполнить такую операцию не можем Например, если мы имеем запрос
SELECT ID FROM TABLE1
UNION
SELECT ID FROM TABLE2
то запрос SELECT COUNT(*) .. попросту теряет смысл, поскольку результат будет ложным по определению В общем случае опция psAskRecordCount не работает с запросами, которые содержат команды UNION, ORDER и DISTINCT.
Использование FIBPIus совместно с генератором отчетов FastReport
Фактически компоненты FIBPIus совместимы с любыми генераторами отчетов, которые работают с потомками стандартного класса TDataSet. Таким образом, вы сможете использовать FIBPIus вместе с QuickReport, ReportBuilder, FastReport и даже со специализированными генераторами отчетов, такими, как, например, Afalina XLReport.
Все эти генераторы будут получать данные из TpFIBDataSet напрямую или через компонент TDataSource. Мы не будем останавливаться на рассмотрении всех особенностей всех генераторов, а просто продемонстрируем как быстро и просто можно получить отчет при помощи FastReport от FastReport Software. Отметим, что, как и FIBPIus, этот генератор отчетов можно использовать не только при разработке приложений в Borland® Delphi® для Microsoft® Windows®, но и в Borland® Kylix® для Linux®. Для этого предназначена специальная CLX-версия пакета.
Простой отчет
Не претендуя на демонстрацию всех возможностей FastReport, поскольку этот пакет предоставляет очень мощные и гибкие возможности для построения отчетов, мы создадим отчет, который распечатает наш price-лист.
Идеология FastReport позволяет включать "внутрь" отчетов совершенно независимые источники данных (и даже отдельные независимые подключения к базе данных), чтобы получить, таким образом, отчеты, которые можно было бы создавать отдельно от приложения (например, если первоначальная постановка задачи не предусматривала каких-то специальных отчетов). Это потребует установки дополнительных компонентов для "привязки" к конкретному источнику данных. Вместе со стандартным пакетом FastReport поставляются, в частности, компоненты для использования FasrtReport с IBX, ADO, BDE и FIBPIus. Автором компонентов FastReport для FIBPIus является Виталий Бармин (barmin@udm.ru).
Итак, если вы хотите использовать и дополнительные возможности FastReport вместе с FIBPIus (этот вопрос будет рассмотрен в разделе "Генератор отчетов FastReport. Создание отчетов в run-time"), то вам необходимо установить соответствующий пакет (FrFib3.dpk, FrFib4.dpk, FrFib5.dpk или FrFib6.dpk, в зависимости от версии Delphi) входящий в поставку FastReport.
Вы также можете всегда найти эти компоненты Виталия Бармина на caйте FIBPlus http://www.fibplus.net/.
Напомним, что сам FastReport вы всегда сможете найти на сайте http://www.fastrepoit.ru
После установки вы увидите в палитре на странице FastReport дополнительный компонент: TfrFIBComponents. Теперь можно перейти к созданию отчета.
Поместим на нашу форму следующие компоненты: frReport: TfrReport; frFIBComponents: TfrFIB Components и frDBDataSetl: TfrDBDataSet (рис. 2.30).

Рис 2.30. Компоненты FastReport
Откроем дизайнер отчетов, дважды нажав на frReport (рис. 2.31).

Рис 2.31. Внешний вид дизайнера отчетов
Как видно из рисунка, оба компонента TpFIBDataSet уже доступны нам в дизайнере. Для начала рассмотрим самый простой вариант отчета, который распечатает нам список категорий товаров в прайс-листе (рис. 2.32).

Рис 2.32. Шаблон отчета о категориях товаров
Для этого мы поместим на страницу четыре полосы (band): Report Title, Page Header, Master Data и Page Footer. Объекты, помещенные на Report Title, будут распечатаны только один раз в самом начале отчета Объекты, размещенные на Page Header, будут выводиться на печать в начале каждой новой страницы. В нашем случае мы просто добавили туда переменную PAGE#, которая будет выводить номер страницы. Master Data нужен нам для вывода данных из компонента CategonesDataSet. Эта полоса (band) будет выведена на печать столько раз, сколько записей в нашем наборе данных. И наконец, Page Footer будет выводиться в конце каждой страницы отчета.
Укажем FastReport, откуда необходимо брать данные для отчета Для этого зададим свойство DataSource у компонента frDBDataSetl (рис. 2 33).

Рис 2.33. Свойства TfrDBDataSet
Теперь необходимо задать источник данных для Master Data Band в самом отчете Нажмите дважды на Master Data в дизайнере отчета и укажите источник данных в появившемся диалоге (рис. 2.34).

Рис 2.34. Источник данных для Master Data
Остается обратить внимание на объект TfrMemoView, в котором и будут выводится названия категорий в отчете (рис 2.35.)

Рис 2.35. Объект шаблона отчета TfrMemoView, необходимый для печати значений поля таблицы
Это выражение вы можете ввести вручную, а можете использовать специальный диалог редактирования объекта и нажать кнопку Insert data field, изображенную на рис 2 36.
На этом этапе фактически отчет готов. Вы можете нажать кнопку Preview и увидеть уже готовый список категорий, который можно распечатать Тем не менее добавим в наше приложение кнопку, которая будет вызывать отчет по названиям категорий товаров
Необходимо написать очень простую обработку нажатия на эту кнопку (предположим, что мы сохранили шаблон для отчета в файле 'price_categories.frf):
procedure TMainForm.PrintBClick(Sender: TObject);
begin
frReport LoadFromFile('price_categories.frf');
frReport PrepareReport;
frReport.ShowPreparedReport,
end;

Рис 2.36. Внешний вид диалога редактирования объекта TfrMemoView
После запуска приложения и нажатия на кнопку Печать мы увидим следующий отчет (рис. 2.37).

Рис 2.37. Вид отчета о категориях товаров в прайс-листе
Отчеты вида master-detail
Теперь мы можем приступить к построению отчета более сложной структуры, хотя фактически это реализуется так же просто, как и предыдущий вид отчета. Сначала добавим на нашу форму еще один компонент frDBDataSet2: TfrDBDataSet - и зададим его свойство DataSource равным GoodsSource. Теперь необходимо добавить две полосы (bands): Detail Header (заголовки детализованных данных) и Detail Data (сами данные). На Detail Data мы разместим два объекта типа TfrMemoView. В первом мы будем выводить названия товаров, а во втором - цену каждого товара (рис. 2.38):

Рис 2.38. Шаблон отчета для связи мастер-деталь
Очевидно, что мы должны указать источником данных для Detail Data компонент frDBDataSet2. Отчет готов. Сохраним его в файл 'price_list.frf и изменим немного обработчик клавиши "Печать":
procedure
TMainForm.PrintBClick(Sender: TObiect);
begin
GoodsDataSet.DetailConditions :=
GoodsDataSet.DetailConditions [dcWaitEndMasterScroll];
frReport.LoadFromFile('price.f rf');
frReport.PrepareReport ;
frReport.ShowPreparedReport;
GoodsDataSet.DetailConditions :=
GoodsDataSet DetailConditions + [dcWaitEndMasterScroll];
end,
Важный момент касается изменения DetailConditions. Как уже было сказано, ключ dcWaitEndMasteiScioll позволяет избегать лишних запросов при навигации по master-запросу. Однако в ел) чае с распечаткой полного отчета это может привести к тому, что для каждой категории товара мы будем иметь одни и те же наименования, поскольку GoodsDataSet не будет переоткрывать запрос, пока FastReport будет получать данные из CategonesDataSet Чтобы избежать такой ошибки, мы отключаем оптимизацию master-detail на период подготовки отчета и включаем ее вновь после того, как отчет уже готов
Теперь при запуске приложения мы можем легко распечатать весь наш прайс-лист (рис 2.39.)

Рис 2.39. Внешний вид отчета вида мастер-деталь
При желании мы можем выделить цветом или курсивом "горячие" (к примеру, самые дешевые) позиции прайса. Для этого в дизайнере выберем TfrMemoView, затем воспользуемся Objectlnspector и установим свойство Highlight. Для этого в поле "Condition" появившегося окна введем условие Value<0 и выберем способ выделения. В нашем примере все позиции прайса с ценой менее 1000 будут выделены ярко-зеленым цветом (рис. 2.40).

Рис 2.40. Диалог параметров условного форматирования
Создание отчетов в run-time
Одной из самых замечательных особенностей FastReport является возможность создавать отчеты прямо в run-time, т. е. во время работы приложения. Это позволяет добавлять в ваше приложение отчеты, которые не были предусмотрены заранее, и использовать в этих отчетах как существующие запросы, так и совершенно новые. Более того, фактически вы можете создавать в таких отчетах даже самостоятельные подключения к базам данных не меняя код вашей программы!
Все это возможно благодаря архитектуре FastReport и компонентам, написанным Виталием Барминым, о которых мы уже упоминали выше.
Для этого добавим в наше приложение компоненты TfrDesigner, TfrDialogControls (как видно из названия, этот компонент предназначен для построения и использования самостоятельных диалоговых окон в составе отчета), а также кнопку для вызова диалога редактирования шаблона отчета (рис. 2.41).
Обработчик для этой кнопки будет исключительно простым:
procedure TMainForm.DesignPClick(Sender: TObject);
begin
frReport.DesignReport;
end;
Теперь при запуске приложения мы можем нажать на кнопку "Дизайн отчетов" и создать отчет прямо в run-time, сохранить его в отдельном файле и потом использовать в приложении. Все эти шаги, в сущности, являются тем же самым, что мы уже делали в предыдущих разделах. Теперь же мы хотим сосредоточиться на дополнительных возможностях FastReport, а именно на создании независимых отчетов.

Рис 2.41. Компоненты для встраивания дизайнера отчетов в программу
Если вы обратите внимание, то шаблон для отчета по умолчанию имеет одну страницу, на которой мы и располагаем полосы для печати. Добавим к отчету специальную страницу - диалоговую, на которой расположим компоненты доступа к данным (рис. 2.42).

Рис 2.42. Добавление диалоговой страницы к шаблону отчета
После добавления диалога и перехода на страницу 2 нашего шаблона на панели инструментов с объектами, доступными для отчета, вы увидите ряд визуальных компонентов, которые можно располагать на диалоге (рис. 2.43).

Рис 2.43. Компоненты для доступа к базе данных из шаблона отчета
Положим на диалог компонент Query: TfrFIBQuery, укажем ему существующее подключение к базе данных в свойстве Database и напишем следующий запрос в свойстве SQL:
SELECT "Categories"."Name", "Categories"."GoodsCount"
FROM "Categories"
WHERE "Categories"."GoodsCount" > 0
Очевидно, что мы хотим вывести на печать только те категории товаров, количество наименований по которым больше нуля. Остается только создать сам шаблон печати, привязав соответствующие полосы (bands) к Query как к источнику данных (рис. 2.44).

Рис 2.44. Шаблон встроенного отчета
Укажем источник данных для Master Data (рис. 2.45).

Рис 2.45. Подключение полосы (band) к встроенному в шаблон запросу
И сохраним наш новый отчет, например, под именем "pricel.frf". Теперь можно несколько изменить реакцию нашего приложения на нажатие кнопки печати. Положим на форму компонент OpenDialog: TopenDialog - и напишем следующий обработчик нажатия на кнопку "Печать":
procedure TMainForm.PrintBClick(Sender: TObject);
begin
if not OpenDialog.Execute then exit;
GoodsDataSet.DetailConditions :=
GoodsDataSet.DetailConditions [dcWaitEndMasterScroll];
frReport.LoadFromFile(OpenDialog.FileName);
frReport.PrepareReport;
frReport.ShowPreparedReport;
GoodsDataSet.DetailConditions :=
GoodsDataSet.DetailConditions + [dcWaitEndMasterScroll] ;
end;
Таким образом, когда пользователь нажмет на кнопку "Печать", он сможет выбрать любой шаблон отчета и вывести его на печать. Учитывая, что при помощи дизайнера отчетов тот же самый пользователь (или вы, как разработчик) может подготовить неограниченное количество самых разных отчетов без необходимости изменения основного кода приложения, становится очевидным преимущество использования FIBPlus совместно с FastReport. Конечно, возможность создавать отчеты в run-time доступна в FastReport и для других пакетов работы с данными, в частности с IBX, однако FIBPlus делает эту возможность значительно более гибкой за счет использования макросов. Более подробно механизм макросов мы рассмотрим чуть позже, а сейчас лишь продемонстрируем, как, используя макросы, мы можем создавать более функциональные диалоговые отчеты.
Скопируем "pricel.frf" в "price2.frf", откроем "price2.frf" для редактирования в дизайнере отчетов и перейдем на диалоговую страницу. Там мы поместим дополнительные компоненты: ComboBoxl, Editl, Labell и Buttonl (рис. 2.46).

Рис 2.46. Внешний вид диалога, встроенного в шаблон отчета
Изменим запрос в Query.SQL:
SELECT "Categories"."Name", "Categories"."GoodsCount"
FROM "Categories"
WHERE "Categories"."GoodsCount" @COND
COND в данном случае является макросом FIBPlus, и вместо него мы можем поставить любой текст. Удобство же заключается прежде всего в том, что макросы в FIBPlus рассматриваются как полноценные параметры, а значит, FastReport тоже будет считать, что в данном случае имеет дело с параметром. В данном примере мы можем позволить пользователю самому указать условия для выборки категорий прайс-листа. Заполним ComboBoxl.Items символами сравнения:
>
<
>=
< =
<>
=
Теперь нам достаточно только указать FastReport, какое значение необходимо "подставить" вместо нашего макроса-параметра. Для этого надо изменить свойство Params у компонента Query (рис. 2.47).

Рис 2.47. Выражение для получения значение макроса COND
Параметр у нас один: COND. Его значение мы должны сформировать из двух частей: знака сравнения и значения, с которым будет сравниваться поле "GoodsCount". Что и было сделано, как видно из рисунка выше. Теперь при запуске отчета мы увидим диалог, в котором необходимо указать условие для выборки (рис. 2.48).

Рис 2.48. Полученный диалог во время получения отчета
А на рис. 2.49 изображен получившийся отчет о категориях товаров, в которых более семи наименований товаров.
Теперь мы можем определить реакцию на щелчок по любой категории товаров в подобном отчете таким образом, чтобы по нему выводился полный отчет о товарах из этой категории. Для этого у всех объектов FastReport есть свойство Tag: String. В окне preview пользователь может нажать на объект и при этом выполнится какое-либо действие (например, построится другой отчет). Цель свойства - облегчить распознавание нажатого объекта. Например, объект может содержать текст "12.25р", по которому идентификация невозможна. Но в свойство Tag можно поместить более развернутую информацию, например значение ключа таблицы, из которой был получен текст "12.25р", номер строки или колонки в отчете и пр. При этом необходимо использовать событие TfrReport.OnObjectClick.

Рис 2.49. Внешний вид получившегося динамического отчета
Логично использовать для вывода детализованного отчета тот же самый объект frReport, который уже лежит у нас на диалоговой форме приложения. Однако саму форму этого отчета надо будет разработать отдельно и сохранить на диске. Форма отчета будет выглядеть так же, как и в нашем отчете master-detail (рис. 2.50).
Кроме того, нам будет необходимо наложить фильтр на категории товаров:
SELECT "Categories"."Name", "Categories"."GoodsCount"
FROM "Categories"
WHERE "Categories"." Name " @NAME
Теперь укажем FastReport, какое значение следует подставить вместо макроса "@NAME" в компоненте Query. Здесь нам придется немного "схитрить" и присвоить этому макросу значение переменной FastReport. Назовем эту переменную Va .
К самой переменной мы присвоим значение в коде программы.
Сохраним эту форму отчета из дизайнера на диске в текущем каталоге под именем "detailed.frf".

Рис 2.50. Шаблон дополнительного отчета
Определим в коде программы для TfrReport событие OnObjectClick следующим образом:
procedure Tforml.frReportObjectClick(View: TfrView);
var str: string;
begin
str .= View.Memo.Text;
frReport.LoadFromFile('detailed.frf')
frReportl.Dictionary.Variables['Varl'] := str;
if frReport.PrepareReport then begin
frReport.OnObjectClick := nil; { чтобы при щелчке на детализованном отчете не показывался детализованный отчет }
frReport.ShowPreparedReport;
frReport.OnObjectClick := frReportObjectClick; { возвращаем событие для вывода детализованного отчета }
frReport.ShowReport;
end;
end;
Наиболее полную документацию, описание всех возможностей, а также последние версии FastReport можно найти на официальном Web-сайте http://www.fastreport.ru.
Использование специальных инструментов в design-time: FIBPIus Tools
Кроме компонентов библиотека FIBPIus также включает ряд дополнительных инструментов - FIBPIus Tools, которые расширяют возможности среды разработки специально для более удобного и эффективного использования FIBPIus.
Установка FIBPIus Tools
FIBPIus Tools - это эксперты для Delphi и C++ Builder, поставляющиеся в готовом, скомпилированном виде, поэтому для их установки в среде необходимо установить соответствующий пакет.
На момент создания книги опубликованы FIBPIus Tools для Borland Delphi 3-7 и Borland C++ Builder 5-6. Если вы используете другие версии продуктов Borland, мы рекомендуем вам проверить более новые версии FIBPIus Tools на сайте http://www.tlbplus.net/.
Рассмотрим установку в среде Delphi (рис. 2.51). Необходимо выбрать пункт основного меню Components -> Install Packages.
Рис 2.51. Установка FIBPIusTools в среду Delphi
Нажмите на кнопку Add и найдите соответствующий вашей версии Delphi пакет (табл. 2.1).
Табл 2.1. FIBPlusTools: Поддерживаемые версии Delphi/C++ Builder
|
Версия Delphi/C++ Builder |
Название пакета FIBPIus Tools |
|
Delphi 3 |
PFIBPIusTools3.dpl |
|
Delphi 4 |
pFIBPIusTools4.bpl |
|
Delphi 5 |
pFIBPIusToolsS.bpl |
|
Delphi 6 |
PFIBPIusTools6.bpl |
|
Delphi 7 |
PFIBPIusTools7.bpl |
|
C++ Builder 5 |
PFIBPIusTools_CB5.bpl |
|
C++ Builder 6 |
pFIBPIusTools_CB6.bpl |
После установки вы обнаружите пункт FIBPIus в основном меню Delphi (рис. 2.52).

Рис 2.52. Меню FIBPIus Tools
Последний пункт в меню FIBPIus фактически ничего не делает, но показывает номер установленной версии.
Preferences
Пункт Preferences позволяет настроить параметры основных компонентов по умолчанию (рис. 2.53).
На первой странице диалога вы можете задать значения по умолчанию для свойств Options, PrepareOptions и DetailsConditions для всех компонентов класса TpFIBDataSet. Вы можете задать определенные ключи для этих свойств. Например, если вы включите флажок SetRequiredFields то, когда вы положите новый компонент TpFIBDataSet на вашу форму, ее свойство PrepareOptions будет содержать ключ pfSetRequiredFields. Наиболее важным является тот факт, что умолчания, заданные в FIBPIus Tools Preferences, действуют во всех приложениях, которые вы будете создавать. Однако необходимо иметь в виду, что это только первоначальные умолчания. То есть если после помещения компонента на форму вы измените свойства, то это никак не коснется Preferences. Также изменение Preferences не коснется тех компонент значения свойств которых уже были заданы.

Рис. 2.53. Диалог настройки опций TpFIBDataSet в design-time.
Обратите внимание на поля "Prefix Generator name" и "Suffix Generator name". Задав их значения, вы сможете регулировать формирование имен для названий генераторов в свойстве AutoUpdateOptions у TpFIBDataSet. Имя генератора в AutoUpdateOptions генерируется из названия таблицы (UpdateTable), префикса и суффикса.
Следующие страницы диалога позволяют настраивать ключевые свойства компонентов TpFIBDataBase, TpFIBTransaction и TpFIBQuery.
В частности, если вы всегда работаете с новыми версиями InterBase, т. е. С версиями 6 и более (а также Firebird), то мы рекомендуем вам задать значение SQL Dialect на закладке TpFIBDatabase равным 3, чтобы каждый раз не переключать это свойство вручную.
SQL Navigator
Это наиболее интересная часть FIBPlus Tools, не имеющая аналогов в других продуктах. Фактически это инструмент централизованной обработки SQL в рамках целого приложения (рис. 2.54):

Рис 2.54. Внешний вид SQL Navigator
SQLNavigator позволяет разработчику сосредоточиться на написании и анализе SQL-кода в приложении. Нажмите кнопку Scan all forms of active project. SQLNavigator переберет все формы приложения и выделит из них те, которые содержат компоненты FIBPlus для работы с SQL: TpFIBDataSet, TpFIBQuery, TpFIBUpdateObject и TpFffiStoredProc. Нажмите в списке на любую из обнаруженных форм. Список справа будет заполнен компонентами, обнаруженными на этой форме. Нажатие на любой из компонентов позволит нам посмотреть соответствующие свойства, в которых содержится SQL-код. Для компонентов класса TpFIBDataSet будут выведены свойства: SelectSQL, InsertSQL, UpdateSQL, DeleteSQL и RefreshSQL Для компонентов TpFIBQuery, TpFIBUpdateObject и TpFIBStoiedPioc будет выведено значение свойства SQL
Вы можете изменить любое свойство напрямую из SQLNavigator, и новое значение будет сохранено SQLNavigator позволяет делать операции с группами компонентов Для этого достаточно пометить соответствующие компоненты или даже формы (рис. 2.55).

Рис 2.55. Выделение группы компонентов при помощи SQL Navigator
Теперь мы можем сохранить значения выделенных свойств во внешнем файле при помощи кнопки Save selected SQLs или проверить их корректность прямо в SQLNavigator при помощи кнопки Check selected SQLs Записанный файл с выделенными запросами можно использовать для дальнейшего анализа при помощи специализированных инструментов
Вы можете использовать SQLNavigator для поиска текста в SQL в рамках всего проекта Например, на рис. 2 56 вы можете видеть все свойства в проекте, которые содержат строку "ID"
При помощи двойного нажатия на каждом найденном элементе SQLNavigator выберет компонент и свойство, чтобы разработчик мог редактировать SQL.
Таким образом, SQLNavigator представляется очень эффективным инструментом для работы с SQL-кодом в клиентской части приложения базы данных, пожалуй, единственным в своем роде

Рис 2.56. Результат поиска текста в запросах FIBPIus
Специальные возможности FIBPIus
Обработка потери подключения к базе данных
Корректная обработка потери подключения к базе данных является одной из проблем при разработке устойчивых приложений вообще и, пожалуй, самым важным вопросом при разработке приложения, которое будет работать в условиях нестабильного канала связи (в частности, при использовании dial-up).
FIBPIus предоставляет разработчику полный набор средств для обработки потери подключения: возможность аккуратно закрыть все приложение, "закрыть" (т. е. деактивировать все соответствующие компоненты) само подключение на уровне приложения или попробовать восстановить подключение без закрытия запросов.
Ключевым компонентом для обработки ситуации является TpFTBErrorHandler. Формально, потерю подключения мы будем обрабатывать при помощи компонента TpFIBDatabase в обработчике события OnLostConnect, однако без "глубокого" перехвата в TpFIBErrorHandler мы не сможем избавиться от лишних сообщений о потере подсоединения.
Итак, попробуем создать простое приложение, позволяющее редактировать данные в TDBGrid и обрабатывать потерю подключения к базе данных тремя способами, про которые уже было упомянуто (рис. 2.57).

Рис 2.57. Внешний вид главной формы примера Connection Lost
Заполним SelectSQL для CompaniesDataSet: select * from "Companies" и предоставим CompaniesDataSet самостоятельно генерировать модифицирующие запросы (рис. 2.58).

Рис 2.58. Свойства AutoUpdateOptions компонента CompaniesDataSet
Включим также режим CachedUpdates (CompaniesDataSet.CachedUpdates := True), чтобы корректно обрабатывать восстановление подключения без потери данных.
Компонент cmbKindOnLost: TComboBox будет содержать список возможных реакций на потерю подключения, чтобы мы могли во время выполнения приложения попробовать все возможности:
Close pFIBDataBase
Terminate application
Restore connect
Теперь обратим внимание на компонент pFIBErrorHandlerl (рис. 2.59).
TpFIBErrorHandler обрабатывает "особым" образом два типа ошибок: пользовательские исключения и потерю подключения к базе данных. В компонент заложена также возможность обработки ошибок, связанных с нарушением ссылочной целостности, однако в существующих версиях FIBPlus данная функция еще не реализована.
TpFIBErrorHandler имеет только одно событие - OnFIBErrorEvent, обработка которого позволит нам обработать, в частности, потерю подключения к базе данных:
procedure TForml.pFibErrorHandlerlFIBErrorEvent(Sender:
TObject;
ErrorValue: EFIBError; KindlBError: TKindlBError; var
DoRaise: Boolean);
begin
if KindlBError = keLostConnect then begin
DoRaise := false;
Abort;
end;
end;

Puc 2.59. Свойства компонента pFIBErrorHandlerl
Вот в общем-то и весь обработчик - мы просто запрещаем вывод стандартного сообщения о потере подключения. На практике вы сможете использовать OnFIBEnorEvent для более сложной обработки разного рода исключительных ситуаций, используя значение параметра ErrorValue. Для нашего случая важно также знать что, кроме срабатывания QnFIBErrorEvent, TpFIBErrorHandler инициирует возникновение OnLostConnection у компонентов TpFIBDatabase Именно здесь мы и сосредоточим основную обработку потери подсоединения.
procedure TForml.DatabaseLostConnect(Database: TFIBDatabase; E:
EFIBError;
var Actions: TOnLostConnectActions);
begin
AttemptRest := 0;
case cmbKindOnLost.Itemlndex of 0: begin
Actions := laCloseConnect;
MessageDlg('Connection lost. TpFIBDatabase will be closed'',
mtlnformamon, [mbOk] , 0
);
end;
1: begin
Actions := laTerminateApp;
MessageDlg('Connection lost. Application will be closed',
mtlnformation, [mbOk], 0
);
end;
2: Actions := laWaitRestore;
end;
end;
Смысл обработчика очевиден - в зависимости от выбранного пользователем значения компонента cmbKindOnLost наше приложение либо "закрывает" активное подключение и все соответствующие компоненты, либо закрывает все приложение, либо включает режим восстановления подсоединения. Первые два случая очевидны и в общем-то не требуют никаких дополнительных шагов, кроме установления значения параметра Actions. Более подробно мы остановимся на восстановлении подключения.
Поскольку CompaniesDataSet находится в режиме CachedUpdates, то потеря подключения не влияет на возможность редактирования данных пользователем, поскольку все изменения будут сохраняться в локальном буфере компонента CompaniesDataSet Таким образом, в задачу TpFIBDataBase входит только одно: периодически пытаться восстано'вить подключение и сообщать об удачных и неудачных попытках. Когда подсоединение будет восстановлено, мы просто применим "отложенные" изменения к данным в базе данных Конечно, никто не гарантирует, что отложенные команды смогут быть выполнены сервером, поскольку на момент восстановления подключения наши локальные данные могут совершенно потерять актуальность.
Итак, напишем два простых обработчика Первый для события Database OnErrorRestoreConnect
procedure TForml.DatabaseErrorRestoreConnect(Database:
TFIBDatabase;
E: EFIBError; var Actions: TOnLostConnectActions);
begin
Inc(AttemptRest);
Label4.Caption := IntToStr(AttemptRest);
Label4.Refresh;
end;
Компонент Label4 будет показывать счетчик попыток восстановления подсоединения. Второе событие, которое нас интересует, - AfterRestoreConnect:
procedure TForml DatabaseAfterRestoreConnect;
begin
MessageDlg('Connection restored. You can apply cached updates',
mtlnformation, [mbOk], 0
) ;
end;
Как только подключение к базе восстановлено, мы получим сообщение и сможем применить все сделанные изменения.
procedure TForml.ButtonlClick(Sender: TObject);
begin
with CompaniesDataSet do
try
if not DataBase.Connected then begin
try
DataBase.Connected . = True;
except
MessageDlg('Can''t restore connect',
mtlnformation, [mbOk], 0
);
Exit;
end
end;
if not Transaction.Active then Transaction StartTransaction;
ApplyUpdToBase;
Transaction.CoimutRetaining;
CommitUpdToCach;
except
if Transaction.Active then Transaction.RollBack;
end;
end;
На практике вы можете автоматически вызывать процедуру применения данных сразу из обработчика AfterRestoreConnect. В самой процедуре следует обратить внимание на методы ApplyUpdToBase и CommitUpdToCach. В отличие от стандартного метода ApplyUpdates, наследованного от TDataSet, который "не замечает" скрытые в результате локальной фильтрации записи (более подробно этот вопрос будет рассмотрен в разделе "Локальная фильтрация"), методы ApplyUpdToBase и CommitUpdToCach позволяют обойти эту ошибку VCL
Эмуляция Boolean-полей
Вы уже знаете, что InterBase не поддерживает логического типа данных. Чем бы это ни было вызвано, нам остается только огорчиться этим фактом, поскольку на практике логический тип очень удобен. Разработчики, использующие InterBase, вынуждены заменять его другими типами, вводя ограничение на множество допустимых значений. Как правило, в базе данных создается соответствующий домен одного из двух видов.
CREATE DOMAIN TBOOLEAN_CHAR AS CHAR(1)
DEFAULT 'F' NOT NULL
CHECK (VALUE IN ('F', 'T'))
CREATE DOMAIN TBOOLEAN_INT AS INTEGER
DEFAULT 0 NOT NULL
CHECK (VALUE IN (0, 1))
При использовании любой библиотеки компонент для доступа к InterBase оба способа совершенно равноценны, поскольку для полей, созданных с такими доменами, в приложении все равно не создаются Boolean-поля. То есть если мы добавим некоторое логическое поле к нашей таблице:
ALTER TABLE "Categories" ADD IS_ACTIVE TBOOLEAN_INT
NOT NULL
А потом, используя, например, компоненты IBX, сделаем выборку при помощи компонента TIBDataSet:
SELECT "Categories"."Name", "Categories".IS_ACTIVE
FROM "Categories"
то в результате компонент создаст два внутренних компонента для полей:
* TIBStringField для поля "Name" и
* TmtergerField для поля "IS_ACTIVE"
Последнее совершенно верно, поскольку формально поле "IS_ACTIVE" не является логическим. Таким образом, все визуальные компоненты типа TDBGnd и его расширенные аналоги от сторонних производителей не будут обрабатывать данное поле так, как нам бы хотелось. Например, если даже компонент умеет рисовать "галочки" для Boolean-полей, значения которых равно True, то поскольку он будет "видеть" всего лишь целочисленное поле, то и выводить он будет "0" и "1" Разумеется, если мы напишем соответствующие обработчики событий, то сможем добиться более или менее сносного отображения логических величин для поля TIntergerField, однако FIBPlus предоставляет гораздо более простое и качественное решение
Фактически оно состоит только в том, что нам необходимо добавить ключ poUseBooleanField в свойстве PrepareOptions (рис. 2.60).
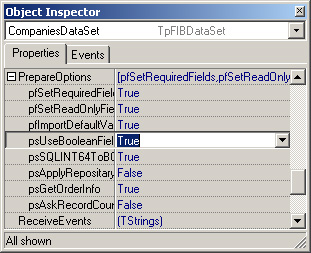
Рис 2.60. Использование PrepareOptions для эмуляции Boolean—полей
После этого поля, созданные на основе целочисленного домена, в названии которого присутствует слово "boolean", будут считать логическими, и для них будут создаваться экземпляры TFIBBooleanField. Данный класс является прямым потомком класса TBooleanField и является полноценным логическим полем Любые визуальные компоненты для отображения данных будут работать с такими полями как с логическими, т. е. используя свойство AsBoolean. Вам же не придется писать для этого никакой дополнительный код.
Поддержка array-полей. Пример использования TpFIBUpdateObject и TDataSetContainer
InterBase с самых ранних версий позволял описывать в таблицах многомерные поля-массивы, делая хранение специализированных данных максимально удобным. Вы наверняка согласитесь, что матриц) проще всего хранить и обрабатывать в виде матрицы, а не раскладывать ее по отдельным полям и даже таблицам из-за ограничений реляционной модели Тем не менее поскольку array- поля не поддерживаются стандартом SQL, то и работа с такими полями на уровне SQL-запросов крайне затруднена. Фактически вы можете использовать массивы только поэлементно и только в операциях чтения Чтобы изменить значения array-поля, необходимо использовать специальные команды InterBase API. FIBPlus позволяет обойтись без подобных сложностей, взяв на себя всю рутину, связанную с array-полями
Мы продемонстрируем, как работать с array-полями при помощи FIBPlus на примере DemoArray5, входящем в стандартную поставку FIBPlus. Пример демонстрирует два варианта использования array-полей Первый способ позволяет редактировать array-поле при помощи специальных методов ArrayFieldValue и SetAiiayValue и работать с таким полем как с единой структурой (рис 2 6П
Рис 2.61. Внешний вид формы примера DemoArrayS Первый вариант использования array—полей
Рассмотрим запросы, заданные в соответствующих свойствах ArrayDataSet:
SeleetSQL
SELECT
JOB JOB_CODE,
JOB.JOB_GRADE,
JOB.JOB_COUNTRY,
JOB.JOB_TITLE,
JOB MIN_SALARY,
JOB.MAX_SALARY,
JOB.JOB_REQUIREMENT,
JOB.LANGUAGE_REQ
FROM
JOB JOB
ORDER BY 1,2,3
UpdateSQL:
UPDATE JOB SET
JOB_CODE = ?JOB_CODE,
JOB_GRADE = ?JOB_GRADE,
JOB_COUNTRY = ?JOB_COUNTRY,
JOB_TITLE = ?JOB_TITLE,
MIN_SALARY = ?MIN_SALARY,
MAX_SALARY = ?MAX_SALARY,
JOB_REQUIREMENT = ?JOB_REQUIREMENT,
JOB.LANGUAGE_REQ= ?LANGUAGE_REQ WHERE
JOB_CODE = ?OLD_JOB_CODE
and JOB_GRADE = ?OLD_JOB_GRADE
and JOB_COUNTRY = ?OLD_JOB_COUNTRY
InsertSQL
INSERT INTO JOB(
JOB_CODE,
JOB_GRADE,
JOB_COUNTRY,
JOB_TITLE,
MIN_SALARY,
MAX_SALARY,
JOB_REQUIREMENT,
JOB.LANGUAGE_REQ
)
VALUES(
?JOB_CODE,
?JOB_GRADE,
?JOB_COUNTRY,
?JOB_TITLE,
?MIN_SALARY,
?MAX_SALARY,
?JOB_REQUIREMENT,
?LANGUAGE_REQ
)
DeleteSQL:
DELETE FROM JOB
WHERE
J03_CODE = ? OLD_JOB_CODE
and JOB_GRADE = ?OLD_JOB_GRADE
and JOB_COUNTRY = ?OLD_JOB_COUNTRY
RefreshSQL:
SELECT
JOB.JOB_CODE,
JOB.JOB_GRADE,
JOB.JOB_COUNTRY,
JOB.JOB_TITLE,
JOB.MIN_SALARY,
JOB.MAX_SALARY,
JOB.JOB_REQUIREMENT,
JOB.LANGUAGE_REQ
FROM
JOB JOB
WHERE
(
JOB.JOB_CODE = ?OLD_JOB_CODE
and JOB.JOB_GRADE = ?OLD_JOB_GRADE
and JOB.JOB_COUNTRY = ?OLD_JOB_COUNTRY
)
Поле LANGUAGE_REQ является массивом (LANGUAGE_REQ VARCHAR(15) [1:5]) и, как видно из запросов, обрабатывается целиком, а не поэлементно. С одной стороны это удобно, но не позволяет использовать для редактирования таких полей специализированные визуальные компоненты типа TDBGrid. Если мы используем array-поля для хранения значительных массивов данных, мы в любом случае будем использовать "ручную" обработку данных, не прибегая к помощи визуальных компонент. Однако для наглядности примера мы позволим редактировать элементы массива в компонентах TEdit.
Фактически нам понадобится написать только два основных обработчика для событий: BeforePost и OnPostError
procedure TForml.ArrayDataSetBeforePost(DataSet: TDataSet);
begin
with ArrayDataSet do begin
SetArrayValue(FieldByName('LANGUAGE_REQ'),
VarArrayOf([
Editl.Text,
Edit2.Text,
Edit3.Text,
Edit4.Text,
Edits.Text
]) ) ;
end;
end;
procedure TForml.ArrayDataSetPostError(DataSet: TDataSet;
E: EDatabaseError; var Action: TDataAction);
begin
Action := daAbort;
MessageDlg('Error!', mtError, [mbOk], 0);
ArrayDataSet.Refresh;
end;
Метод SetArrayValue позволяет задать все элементы поля в виде массива. Важным моментом является обработчик ошибки ArrayDataSetPostError В случае неудачной операции Update или Insert необходимо восстанавливать внутренний идентификатор массива у редактируемой записи. Это правило диктуется функциями InterBase API, и мы должны их придерживаться. Для восстановления идентификатора необходимо получить значения полей текущей записи заново, что и делается при помощи явного вызова метода Refresh.
Для автоматического заполнения визуальных компонентов значениями элементов массива мы можем написать обработчик события AfterScroll:
procedure TForml.ArrayDataSetAfterScroll(DataSet: TDataSet);
var v: Variant;
begin
with ArrayDataSet do try
FInShowArrays := true;
v := ArrayFieldValue(FieldByName('LANGUAGE_REQ'));
Editl.Text := VarToStr(v[l]);
Edit2.Text := VarToStr(v[2]);
Edit3.Text := VarToStr(v[3]);
Edit4.Text := VarToStr(v[4]);
EditS.Text := VarToStr(v[5]);
finally
FInShowArrays:=false;
end;
end;
Флаг FInShowArrays используется в примере для того, чтобы не включать режим редактирования записи при обычной навигации.
Рекомендуется иметь под руками полный текст примера, который доступен на сайте http://www.fibplus.net. В книге мы указываем только те части примера, которые имеют непосредственное и наибольшее значение для работ с array-полями. Однако без полного текста некоторые части исходного текста могут показаться не до конца наглядными.
Данный способ работы с array-полями нельзя применять в режиме CachedUpdates.
Второй способ работы с array-полями позволяет использовать их в "живых" запросах и редактировать при помощи стандартных визуальных компонентов (рис. 2.62).
Рассмотрим запросы, указанные в свойствах ArrayDataSet:
SelectSQL:
SELECT
JOB.JOB_CODE,
JOB.JOB_GRADE,
JOB.JOB_COUNTRY,
JOB.JOB_TITLE,
JOB.LANGUAGE_REQ[1] LQ1,
JOB.LANGUAGE_REQ[2] LQ2
FROM
JOB JOB
ORDER BY 1,2,3

Рис 2.62. Внешний вид формы примера DemoArrayS. Второй вариант использования array-полей
UpdateSQL:
UPDATE JOB SET
JOB_TITLE = -?JOB_TITLE,
JOB JOB_GRADE=?JOB_GRADE,
JOB.JOB_COUNTRY=?JOB_COUNTRY,
LANGUAGE_REQ = ''LQ
WHERE
JOB_CODE = ?OLD_JOB_CODE
and JOB_GRADE = ?OLD_JOB_GRADE
and JOB_COUNTRY = ?OLD_JOB_COUNTRY
InsertSQL:
INSERT INTO JOB(
JOB_CODE,
JOB_GRADE,
JOB_COUNTRY,
JOB_TITLE,
LANGUAGE_REQ
)
VALUES(
?JOB_CODE,
?JOB_GRADE,
?JOB_COUNTRY,
?JOB_TITLE,
?LQ
)
DeleteSQL:
DELETE FROM JOB
WHERE
JOB_CODE = ?OLD_JOB_CODE
and JOB_GRADE = ?OLD_JOB_GRADE
and JOB_COUNTRY = ?OLD_JOB_COUNTRY
RefieshSQL:
SELECT
JOB.JOB_CODE,
JOB.JOB_GRADE,
JOB.JOB_COUNTRY,
JOB.JOB_TITLE,
JOB.LANGUAGE_REQ[1] LQ1,
JOB.LANGUAGE_REQ[2] LQ2
FROM
JOB JOB
WHERE
(
JOB.JOB_CODE = ?OLD_JOB_CODE
and JOB. JOB_GRADE = ?OLD_JOB_GRADE
and JOB.JOB_COUNTRY = ?OLD_JOB_COUNTRY
)
На этот раз мы выбираем только два элемента из нашего поля-массива. Обратите внимание' несмотря на то что в выбирающем запросе мы явным образом выделяем два элемента массива, а в модифицирующих запросах мы обновляем поле целиком На самом деле, это, конечно, не совсем так, однако данный синтаксис наиболее удобен и близок к естественному SQL-запросу несмотря на то что во внутренней реализации FIBPlus использует специальные функции работы с массивами Обратим внимание на компонент QryAirField TpFIBUpdateObject. Именно он позволит нам правильно сформировать значение параметра "LQ" в модифицирующих запросах Разумеется, для этой цели вполне бы подошел и простой TpFIBQuery, однако удобство TpFIBUpdateObject заключается в первую очередь в том, что он выполняет запрос автоматически и сам подставляет туда нужные значения параметров в зависимости от значений TpFIBDataSet. Вот запрос, который выполняет QryArrField SELECT
JOB LANGUAGE_REQ,
JOB JOB_CODE
FROM
JOB JOB
WHERE
JOB JOB_CODE=?OLD_JOB_CODE and
JOB.JOB_GRADE=?OLD_JOB_GRADE and
JOB.JOB_COUNTRY=?OLD_JOB_COUNTRY
Обратим внимание на свойства QryArrField (рис 2 63)

Рис 2.63. Свойство компонента QryArrField
Обработчик QiyAnField AtteiExecute
procedure TForm2 QryArrFieldAfterExecute(Sender: TObject);
var v Variant,
begin
v = QryArrField Fields[0] GetArrayValues,
with ArrayDataSet do begin
v[l] = FieldByName('LQ1') AsString,
v[2] = FieldByName( LQ2 ) AsString,
QryArrField Fields[0] SetArrayValue(v);
QUpdate Params ByName[ LQ ] AsQuad :=
QryArrField.Fields[0] AsQuad;
end;
QryArrField Close;
end;
Теперь все становится совершенно очевидным Поскотьку свойство QiyAnField KindUpdate равно ukModify, то QiyArrField выполняет запрос при изменении записи в AnayDataSet а поскольку свойство QiyArrField ExecuteOider равно eoBeforeDefault, то запрос (QiyArrField SQL) выполняется до того, как AirayDataSet выполнит свой собственный UpdateSQL В обработчике QryArrField AfterExecute мы всего лишь получаем заново все текущие элементы массива из базы данных, подменяем два из них новыми значениями, которые указал пользователь, и задаем значение параметра для ArrayDataSet.UpdateSQL Это означает что при выполнении ArrayDataSet.UpdateSQL формально будут обновлены все пять элементов массива но фактически изменены значения тотько двух элементов, которые изменил пользователь в TDBGrid.
Как видите работа с массивами достаточно проста поскотьку все основные сложности решают компоненты FIBPlus Хотелось бы также рассмотреть еще один специализированный компонент, входящий в FIBPlus Пример DemoArray демонстрирует работу с TDataSetContamei, использованным для синхронизации значений двух TpFIBDataSet, редактирующих наше апау-поле (рис 2 64)

Рис 2.64. Использование TDatabetContamer
Компонент DataSetContamerl помещен вместе с Database и Transaction на DataModule в нашем приложении Оба компонента AnayDataSet из разных форм нашего приложения ссылаются на DataSetContamerl при помощи свойства Contamei (рис 2 65)

Рис 2.65. Подключение компонентов TpFIBDataSet к DataSetContamerl
Компонент TDataSetContamei позволяет централизованно обрабатывать события от разных компонентов TpFIBDataSet, а также (расширяя, таким образом, список стандартных событий) посылать им сообщения, при получении которых они могут производить какие-то дополнительные действия. В нашем примере DataSetContainerl имеет обработчики двух событий OnDataSetEvent и OnUserEvent
procedure TDataModule2.DataSetsContainerlDataSetEvent(DataSet:
TDataSet;
Event: TKindDataSetEvent);
var Info: string;
begin
if Event = deAfterPost then
if DataSet.Owner.Name = 'Forml' then
DataSetsContainerl.NotifyDataSets(DataSet,
'Form2.ArrayDataSet', 'JOB_TABLE_CHANGED', Info)
else
if DataSet.Owner.Name = 'Form2' then
DataSetsContainerl.NotifyDataSets(DataSet,
'Form1.ArrayDataSet', 'JOB_TABLE_CHANGED', Info);
end;
procedure TDataModule2.DataSetsContainerlUserEvent(Sender:
TObject;
Receiver: TDataSet; const EventName: String; var Info:
String) ;
begin
if EventName = 'JOB_TABLE_CHANGED' then begin
with TpFIBDataSet(Sender) do
if (not CachedUpdates) and
(not TpFIBDataSet(Receiver).CachedUpdates) then
if
TpFIBDataSet(Receiver).Locate('JOB_CODE;JOB_GRADE;JOB_COUNTRY', varArrayOf([
FieldByNamet'JOB_CODE').AsString,
FieldByName('JOB_GRADE').AsString,
FieldByName('JOB_COUNTRY').AsString
]), []) then TpFIBDataSet(Receiver) Refresh
end;
end;
Смысл действий сводится к следующему: после изменения записи в одном из наших компонентов ArrayDataSet происходит событие AfterPost. Поскольку DataSetContainerl перехватывает все события у подчиненных компонентов, то срабатывает обработчик OnDataSetEvent. Параметр Event равен deAfterPost, а параметр DataSet ссылается на тот компонент, в котором произошло изменение записи. При помощи вызова метода NotifyDataSets DataSetContainerl посылает сообщение оставшемуся компоненту ArrayDataSet о том, что произошло изменение записи. Поскольку оба компонента на самом деле редактируют одну и ту же таблицу, то желательно синхронизировать изменения. Синхронизация происходит в обработчике события OnUserEvent, то есть при получении "извещения" об изменении какого-либо из ArrayDataSet.
Если получено сообщение "JOB_TABLE_CHANGED" и ни в одном из наших двух ArrayDataSet не включен режим CachedUpdates (в этом случае Refresh просто ничего не даст), то мы позиционируемся на соответствующую запись и вызываем для нее метод Refresh, обновив, таким образом, запись в одном ArrayDataSet после того, как она была изменена в другом ArrayDataSet.
Данная технология является совершенно уникальной: использование DataSetContainer позволяет делать чрезвычайно гибкие и в то же время прозрачные схемы обработки и синхронизации данных в нескольких компонентах TpFIBDataSet.
Работа с BLOB-полями
Достаточно часто желательно хранить в базе данных разнообразные неструктурированные данные: изображения, OLE-объекты, звук и т. д. Специально для этих целей существует специальный тип данных - BLOB Продемонстрируем использование BLOB-полей на примере простого приложения (см. рис. 2.66), использующего следующую таблицу:
CREATE TABLE BIOLIFE (
ID INTEGER NOT NULL,
CATEGORY VARCKAR (15) character set WIN1251 collate
WIN1251,
COMMON_NAME VARCHAR (30) character set WIN1251 collate
WIN1251,
SPECIES_NAME VARCHAR (40) character set WIN1251 collate
WIN1251,
LENGTH_CM_ DOUBLE PRECISION,
LENGTH_IN DOUBLE PRECISION,
NOTES BLOB sub_type 1 segment size 80,
GRAPHIC BLOB sub_type 0 segment size 80);
Для вывода изображений, сохраненных в поле GRAPHIC, мы будем использовать стандартный компонент DBIMagel: TDBImage. Очевидно также, что запросы при работе с BLOB-полями ничем не отличаются от запросов со стандартными типами полей:
SelectSQL:
SELECT * FROM BIOLIFE
UpdateSQL:
UPDATE BIOLIFE Set
ID=?NEW_ID,
CATEGORY=?NEW_CATEGORY,
COMMON_NAME=?NEW_COMMON_NAME,
SPECIES_NAME=?NEW_SPECIES_NAME,
LENGTH__CM_=?NEW_LENGTH_CM_,
LENGTH_IN=?NEW_LENGTH_IN,
NOTES=?NEW_NOTES,
GRAPHIC=?NEW_GRAPHIC
WHERE ID=?OLD_ID

Рис 2.66. Внешний вид формы приложения для работы с BLOB-полями
InsertSQL:
INSERT INTO BIOLIFE(
ID,
CATEGORY,
COMMON_NAME,
SPECIES_NAME,
LENGTH__CM_,
LENGTH_IN,
NOTES,
GRAPHIC
)
VALUES (
?NEW_ID,
?NEW_CATEGORY,
?NEW_COMMON_NAME,
?NEW_SPECIES_NAME,
?NEW_LENGTH_CM_,
?NEW_LENGTH_IN,
?NEW_NOTES ,
?NEW_GRAPHIC
)
DeleteSQL:
DELETE FROM BIOLIFE
WHERE ID=?OLD_ID
RefreshSQL:
SELECT * FROM BIOLIFE
WHERE
ID=?OLD_ID
Единственным отличием от обычных типов данных является то, что для присвоения значения BLOB-параметру необходимо использовать потоки (специализированные потомки стандартного класса TStream). Например, если мы хотим сохранить в нашем поле изображение из внешнего файла, то мы можем написать следующий обработчик нажатия на кнопку:
procedure TMainForm.OpenBClick(Sender: ТОbjесt);
var S. TStream;
FileS: TFileStream;
begin
if not OpenD.Execute then exit;
pFIBDataSetl.Edit;
S : =
pFIBDataSetl.CreateBlobStream(pFIBDataSetl.FieldByName('GRAPHIC') , bmReadWrite);
try
FileS := TFiIeStream.Create(OpenD.FileName, fmOpenRead);
S.CopyFrom(FileS, FileS.Size);
finally
FileS.Free;
S.Free;
pFIBDataSetl.Post;
end;
end;
Обратите внимание на важный момент - перед тем как присваивать значение BLOB-параметру, необходимо перевести pFIBDataSet в состояние редактирования данных. В данном случае это делается безусловным вызовом метода Edit. Вызов метода CreateBlobStream создает экземпляр специального внутреннего класса TFIBDSBlobStream. Скорее всего, вам не придется использовать этот класс напрямую. В нашем примере он нужен только для обмена данными между BLOB-параметром и потоком, который читает данные из файла с изображением. Параметр bmReadWrite означает, что мы собираемся изменять содержимое параметра. Поток S напрямую связан с BLOB-параметром, поэтому, копируя данные из файла (FileS) в поток S, мы фактически присваиваем значение параметру. Остается только сохранить изменения вызовом метода Post Аналогичным образом мы можем сохранить значение BLOB-поля в некоторый внешний файл:
procedure TMainForm.SaveBClick(Sender: TObject);
var S: TStream;
FileS: TFiIeStream;
begin
if not SaveD.Execute then exit;
if not pFIBDatasetl.FieldByName('GRAPHIC').IsNull then begin
S : =
pFIBDatasetl.CreaceBlobStream(pFIBDatasetl.FieldByName('GRAPHIC '), bmRead);
try
if FileExists(SaveD.FileName) then
FileS := TFileStream.Create(SaveD.FileName, fmOpenWrite)
else
FileS := TFileStream.Create(SaveD.FileName, fmCreate);
FileS.CopyFrom(S, S.Size);
finally
S.Free;
FileS.Free;
end;
end;
end;
Обратите внимание, что в этой процедуре мы используем параметр bmRead при создании потока S. Очевидно, что для сохранения содержимого BLOB-поля в файл нам не нужно изменять само поле, поэтому мы создаем поток только для чтения. Еще более простым способом мы можем очистить содержимое BLOB-поля:
procedure TMainForm.ButtonlClick(Sender: TObject);
begin
pFIBDataSetl .Edit;
pFIBDataSetl.FieldByName('GRAPHIC').Clear;
pFIBDataSetl.Post;
end;
В этом случае даже не требуется создавать какие-либо потоки. Иногда также нужно знать, является ли BLOB-поле пустым или нет. При использовании визуальных компонентов типа TDBImage мы не можем быть в этом уверены. Согласитесь, что никто не мешает нам "нарисовать" пустую картинку и сохранить ее в BLOB-поле В этом случае мы не сможем отличить "на глаз": есть ли какое-то изображение в BLOB-поле или нет. Однако мы можем написать обработчик события OnDataChange компонента DataSourcel: TDataSource:
procedure TMainForm.DataSourcelDataChange(Sender: TObject;
Field: TField) ;
begin
CheckBoxl.Checked :=
pFIBDataSetl.FieldByName('GRAPHIC').IsNull;
end;
Это событие вызывается, в частности, при навигации по DBGridl; таким образом, мы всегда можем узнать, является ли текущее поле пустым или нет.
Если вы используете TpFIBQuery для работы с BLOB-полями, то общий принцип остается тем же - необходимо использовать потоки, однако, в отличие от TpFIBDataSet, вам не потребуется создавать какие-то специальные потоки. Например, мы можем написать следующую процедуру, которая сохранит в файлы все изображения из нашей таблицы:
pFIBQuery.SQL: SELECT * FROM BIOLIFE
procedure TMainForm.Button2Click(Sender: TObject);
var SaveFile: TFileStream;
Index: Integer;
begin
with pFIBQueryl do begin ExecQuery;
Index := 1;
while not Eof do begin
SaveFile := TFileStream.Create(IntToStr(Index) + '.bmp',
fmCreate);
FN('GRAPHIC').SaveToStream(SaveFile);
Next;
inc(Index);
SaveFile.Free;
end;
Close;
end;
end;
Метод FN является аналогом FieldByName.
Смысл кода, приведенного выше, совершенно очевиден: мы получаем все записи из таблицы BIOLIFE, в цикле получаем от сервера очередную запись из запроса, создаем файл при помощи потока SaveFile, сохраняем в него значение поля GRAPHIC и запрашиваем следующую запись при помощи метода Next. Аналогичным образом мы могли бы присваивать значение BLOB-параметру: pFIBQuery.SQL: INSERT INTO BIOLIFE (GRAPHIC) VALUES (7GRAPHIC)
procedure TMainForm.Button2Click(Sender: TObject);
var SaveFile: TFileStream;
Index: Integer;
begin
with pFIBQueryl do begin
Prepare;
for Index := 1 to 3 do begin
SaveFile := TFileStream.Create(IntToStr(Index) + '.bmp', fmOpenRead);
Params[0].LoadFromStream(SaveFile);
SaveFile.Free;
ExecQuery;
end;
Transaction.Commit;
end;
end;
Данный пример вставляет три новые записи в таблицу BIOLIFE и сохраняет в них изображения из некоторых файлов "l.bmp", "2.bmp" и "3.bmp".
Поскольку в данном примере для сохранения изменений использовался метод Commit, то необходимо перезапустить приложение, чтобы увидеть вставленные записи в DBGridl.
Локальная сортировка и локальная фильтрация
TpFIBDataSet позволяет разработчику оптимизировать работу с базой данных, используя в случае необходимости локальную сортировку данных и локальную фильтрацию. Термин "локальный" в данном случае означает, что в этих механизмах не используются дополнительные запросы к серверу. Таким образом, в определенных случаях вы можете значительно снизить сетевой трафик вашего приложения, а также увеличить скорость поиска или сортировки данных.
Локальная сортировка
Рассмотрим локальную сортировку на примере Sorting, который входит в поставку FIBPlus.
Как и все остальные примеры, приложение Sorting вы можете наши на сайте http://www.fibplus.net
Пример использует таблицу EMPLOYEE из базы данных Employee.gdb (рис. 2.67)

Рис 2.67. Внешний вид формы приложения, демонстрирующего локальную сортировку в TpFIBDataSet
MainDS.SelectSQL: SELECT * FROM EMPLOYEE
Все записи, полученные от сервера в результате запроса, сохраняются в локальном буфере компонента TpFIBDataSet.
Это одна из причин, из-за которой не рекомендуется использовать TpFIBDataSet для слишком больших выборок, - вам просто может не хватить оперативной памяти и работа приложения замедлится.
Предположим, что пользователь хочет отсортировать записи по полю FIRST_NAME. Очевидно, что мы можем сформировать новый запрос:
SELECT * FROM EMPLOYEE
ORDER BY FIRST_NAME
Чтобы получить новый порядок записей, необходимо переоткрыть наш запрос. Это работает, но означает, что мы будем повторно получать от сервера все •записи, несмотря на то что нам нужно было всего лишь поменять их визуальный порядок. Если предполагать, что нашим приложением могут пользоваться одновременно несколько пользователей, то затраты на подобные "сортировки" могут оказаться довольно значительными. Тем не менее выход существует, поскольку TpFIBDataSet позволяет сортировать данные внутри своего локального буфера, т. е. без необходимости получения всех записей заново.
Для этого мы должны воспользоваться одним из возможных вариантов метода DoSort или DoSortEx:
procedure DoSort(Fields: array of const; Ordering: array of Boolean); virtual;
procedure DoSortEx(Fields: array of integer; Ordering: array of Boolean); overload;
procedure DoSortEx(Fields: TStrings; Ordering: array of Boolean); overload;
Метод DoSortEx доступен в FIBPlus начиная с версии Delphi 4.
Первый параметр всех трех процедур - это список полей, по которым мы хотим отсортировать данные. В случае DoSort это могут быть названия полей или номера полей. Первый вариант DoSortEx позволяет нам использовать только список с номерами полей, а второй вариант DoSortEx предполагает, что мы заполнили список Fields названиями полей. Параметр Ordering во всех трех случаях указывает направление сортировки по каждому из полей. Таким образом, мы можем отсортировать наш запрос по полю FIRST_NAME следующим образом:
DoSort(['FIRSN_NAME'], [True]);
Или: DoSortEx([1], [True]);
[True] означает, что поле сортируется по возрастанию (ASCENDING).
В сущности, использование этих методов очевидно, однако иногда возникает вопрос, связанный с динамическим формированием списков полей. Рассмотрим подробнее наш пример, который демонстрирует, как создавать параметры для DoSortEx динамически. Предполагается, что пользователь сможет нажимать на заголовки DBGridl, указывая, таким образом, поле, которое будет участвовать в сортировке. Повторное нажатие на колонку, которая уже участвует в сортировке, будет изменять порядок сортировки по этой колонке на противоположный. Сначала мы опишем вспомогательный класс для хранения информации о молях, которые будут участвовать в сортировках.
type
TOrderStringList = class(TStringList)
protected
function GetAscending(Index: Integer): boolean;
procedure SetAscending (Index: Integer; Value: boolean);
public
property Ascending[Index: Integer]: boolean read
GetAscending write SetAscending;
end;
...
{ TOrderStringList }
function TOrderStringList.GetAscending(Index: Integer):
boolean;
begin
Result := boolean(integer(Objects[Index]));
end;
procedure TOrderStringList.SetAscending(Index: Integer; Value:
boolean);
begin
Objects [ Index] := pointer (integer (Value));
end;
Очевидно, что данный класс является списком строк - названия полей, а также хранит для каждого поля, включенного в список, порядок сортировки в виде свойства Ascending. Ниже вы видите описание класса формы, а также два основных обработчика событий (OnCreate, OnDestroy). При создании формы мы создаем экземпляр класса TOrderStringList, а при ее уничтожении - удаляем.
TMainForm = class(TForm)
MainDB: TpFIBDatabase;
MainDS: TpFIBDataSet;
MainTr: TpFIBTransaction;
DataSourcel: TDataSource;
DBGridl: TDBGrid;
Buttonl: TButton;
Label2: TLabel;
procedure DBGridlTitleClick(Column: TColumn);
procedure FormCreate(Sender: TObject);
procedure FormDestroy(Sender: TObject);
procedure ButtonlClick(Sender: TObject);
private
{ Private declarations }
public
{ Public declarations }
SortFields: TOrderStringList;
procedure ReSort;
end;
procedure TMainForm.FormCreate(Sender: TObject);
begin
SortFields := TOrderStringList.Create;
end;
procedure TMainForm.FormDestroy(Sender: TObject);
begin
SortFields.Free;
end;
Теперь напишем обработчик события OnTitleClick у компонента DBGridl:
procedure TMainForm. DBGndlTitleCiiCK (Column: TColumn);
const OrderScr: array [boolean] of string = ('(DESC)',
'(ASC) ') ;
var aField: string;
aFieldlndex: integer;
begin
aField := Column.FieldName;
aFieldlndex := SortFields.IndexOf(aField) ;
if aFieldlndex = -1 then begin
SortFields.Add(aField);
SortFields.Ascending[SortFields.Count - 1] := true;
Column.Field.Display-Label := Column. Field.FieldName + OrderStr[true];
end
else begin
SortFields.Ascending[aFieldlndex] := not
SortFields.Ascending[aFieldlndex];
Column.Field.Display-Label := Column.Field.FieldName +
OrderStr[SortFields.Ascending[aFieldlndex]];
end;
ReSort;
end;
Смысл обработчика состоит в следующем: при нажатии пользователем на заголовок мы проверяем, есть ли данное поле в нашем списке сортировки. Если нет, то мы добавляем его и формируем новый заголовок для колонки, который теперь будет состоять из названия поля и порядка сортировки (ASC) или (DESC). Если же поле уже было включено в сортировку, то мы лишь меняем порядок сортировки. В обоих случаях мы должны вызвать процедуру ReSort, описанную ниже:
procedure TMainForm.ReSort;
var Orders: array of boolean;
Index: Integer;
begin
if SortFields.Count = 0 then begin MainDS.CloseOpen(false);
exit;
end;
SetLength(Orders, SortFields.Count);
for Index := 0 to pred(SortFields.Count) do
Orders[Index] := SortFields.Ascending[Index];
MainDS.DoSortEx(SortFields, Orders);
end;
Данная процедура формирует списки для метода DoSortEx на основе списка SortFields и пересортировывает записи. В случае, если наш список сортировки пустой, мы должны вернуться к "стандартному" порядку записей. Для этого вызывается метод CloseOpen.
Параметр False означает, что мы не хотим автоматически получать сразу все записи от сервера.
Если наш список полей не пустой, то мы должны сформировать массив Orders. Это делается, как видно, достаточно легко. Используя динамические массивы, мы сначала задаем длину Orders равной количеству полей в списке SortFields, а потом последовательно заполняем Orders значениями свойства Ascending списка SortFields. Остается только вызвать метод DoSortEx - и сортировка б\дет выполнена.
Чтобы закрыть вопрос целиком, нам остается только предоставить пользователю возможность исключать поля из сортировки. Для этого мы положим на форму кнопку Button 1 (см. рис. 46, заголовок "Delete column from Sorting"):
procedure TMainForm.ButtonlClick(Sender: TObject);
var aField: string;
aFieldlndex: integer;
begin
aField := DBGridl.SelectedField.FieldName;
aFieldlndex := SortFields.IndexOf(aField);
if aFieldlndex <> -1 then begin
SortFields.Delete(aFieldlndex);
DBGridl.SelectedField.DisplayLabel := aField;
ReSort;
end;
end;
Пользователь выделяет поле, которое хочет удалить из сортировки, и нажимает на кнопку "Delete column from Sorting", после чего это поле удаляется из списка SortFields и производится пересортировка записей.
Локальная фильтрация
Аналогично локальной сортировке, которая оперирует только с данными в локальном буфере, мы можем также выбирать записи из уже полученных по какому-либо критерию, скрывая от пользователя "лишние" записи.
Рассмотрим локальную фильтрацию на примере приложения Filtering. Этот пример включен в стандартную поставку FIBPlus. В примере используется база данных FIBPlus_Example.gdb (рис. 2.68).
Эта база данных в виде backup-файла доступна на сайте http://www.fibplus.net/
Рис 2.68. Использование локальной фильтрации TpFIBDataSet
Совершенно очевиден код для подключения к базе данных. Список элементов компонента FieldsC: TComboBox заполняется названиями полей из таблицы BIOLIFE.
FilteringDS.SelectSQL: SELECT * FROM BIOLIFE
procedure TMainForm.btnConnectClickfSender: TObject);
var Index: Integer;
begin
with MainDB do begin
ConnectParams.UserName := edtUserName.Text;
ConnectParams.Password := edtPassword.Text;
DBName := edtDataBase.Text;
try
Open;
FilteredDS.Open;
FieldsC.Items.Clear;
for Index := 0 to pred(FilteredDS.FieldCount) do
FieldsC.Items.Add(FilteredDS.Fields[Index].FieldName);
except
MessageDlgt'Error of connection to a database!', mtError, [mbOk], 0) ;
Close;
end;
end;
end;
Пользователь может выбрать поле из списка FieldsC, указать в поле FilterE: TEdit строку для поиска и после нажатия на кнопку Button I ("Activate Filter"):
procedure TMainForm.ButtonlClick(Sender: T0b3ect);
begin
FilteredDS.Filtered := false;
FilteredDS.Filtered := true;
end;
в DBGrid 1 останутся видны только те записи, которые содержат в заданном поле искомую строку Для этого нам необходимо написать обработчик события OnFilterRecord у FilteringDS:
procedure TMainForm.FilteredDSFilterRecord(DataSet: TDataSet;
var Accept: Boolean); begin
Accept := DOS(FilterE.Text,
FilteredDS.FieldByName(FieldsC.Text).AsString) <> 0
end;
После включения FilteredDS.Filtered := true OnFilterRecord вызывается для каждой записи в локальном буфере. Если мы хотим, чтобы конкретная запись оставалась видимой, мы должны задать для нее параметр Accept равным True. Из примера кода видно, что мы оставляем видными только те записи, которые содержат в искомом поле (FieldsC.Text) заданную строку (FilterE.Text). Если мы, например, выберем поле COMMON_NAME и укажем строку для поиска "А", то в результате получим только две видимые записи (рис. 2.69).

Рис 2.69. Пример двух "отфильтрованных" записей
Поскольку наше условие для фильтра сформулировано таким образом, что мы выбираем записи по точному включению искомой подстроки - в нашем случае это только те записи, которые содержат большую букву "А". Мы можем немного усложнить условие поиска. Положим на форму CaseC: TcheckBox (см. рис. 2.69, "Case sensitive") и перепишем обработчик OnFilterRecord следующим образом:
procedure TMainForm.FilteredDSFilterRecord(DataSet: TDataSet;
var Accept: Boolean);
begin
if CaseC.Checked then
Accept := pos(FilterE.Text,
FilteredDS.FieldByName(FieldsC.Text).AsString) <> 0
else
Accept := pos(AnsiUpperCase(FilterE.Text),
AnsiUpperCase(FilteredDS.FieldByName(FieldsC.Text).AsString))
<> 0;
end;
Очевидно, что теперь если пользователь отключит "флажок" "Case sensitive", то фильтр по строке "А" будет содержать гораздо большее количество записей - все записи, которые содержат хотя бы одну букву "А", неважно маленькую или большую (рис. 2.70).

Рис 2.70. Записи, содержащие букву "А"
Очевидно, что использование локальной фильтрации дает разработчику в руки очень гибкое средство построения условий, поскольку этот механизм не столько ограничен, как SQL в условиях WHERE. На основе локальной фильтрации, например, очень легко создается механизм быстрого поиска записи по первым буквам, которые пользователь набирает в поле редактирования.
Обработка событий InterBase при помощи FIBPIus
InterBase дает разработчику некоторый механизм для синхронизации приложений в многопользовательской среде Event Alerts. Суть данного механизма состоит в том. что вы можете вызывать пользовательские события из триггеров или хранимых процедур при помощи функции POST_EVENT:
CREATE PROCEDURE SHOW_EVENT(
EVENT_ID INTEGER)
AS
BEGIN
IF (:EVENT_ID = 1) THEN POST_EVENT 'TEST_EVENT1';
IF (.EVENT_ID = 2) THEN POST_EVENT 'TEST_EVENT2';
IF (.EVENT_ID = 3) THEN POST_EVENT 'TEST_EVENT3';
EXIT;
END
Создадим приложение (рис 2.71), которое будет вызывать данную процедуру и получать соответствующие события Если вы впоследствии попробуете запустить это приложение на двух компьютерах, то оба приложения будут получать сообщения вне зависимости оттого, кто их инициировал

Рис 2.71. Использование InterBase events, при помощи компонента TSIBfibEventAlerter
Для вызова хранимой процедуры мы будем использовать специальный компонент pFIBStoiedPioc TpFIBStoredPioc, задав свойство StoiedProcName (рис 2.72)

Рис 2.72. Вызов хранимой процедуры при помощи компонента TpFIBStoredPioc
Компонент TpFIBStoredProc является прямым потомком TpFIBQuery и сам формирует свойство SQL в виде ' EXECUTE PROCEDURE ...' Название процедуры задается свойством StoiedProcName
Компонент SffifibEventAlerterl: TSffifibEventAlerterlпредназначен для получения приложением событий InterBase Компонент ссылается на конкретное подключение к базе данных, т.е. на компонент типа TpFIBDatabase (рис 2.73)

Рис 2.73. Свойства SIBfibEventAlerterl
Установим свойство AutoRegister в False, чтобы собственноручно зарегистрировать нужные нам события, а в свойстве Events перечислим те события, которые нас интересуют (рис. 2.74).
Рис 2.74. Список зарегистрированных событий
Чтобы компонент SIBfibEventAlerterl "получал" события, мы должны зарегистрировать их после подключения к базе данных. Для этого напишем обработчик события OnConnect у компонента pFIBDatabasel:
procedure TForml.pFIBDatabaselConnect(Sender: TObject);
begin
if not SIBfibEventAlerterl.Registered then
SIBfibEventAlerterl.RegisterEvents;
end;
Соответственно перед закрытием подключения желательно "отключить" SIBfibEventAlerterl. Для этого создадим обработчик события BeforeDisconnect компонента pFIBDatabasel:
procedure TForml.pFIBDatabaselBeforeDisconnect(Sender:
TObject);
begin
if SIBfibEventAlerterl.Registered then
SIBfibEventAlerterl.UnRegisterEvents;
end;
Зададим свойство Tag у кнопок равным соответственно 1, 2 и 3, и напишем общий обработчик события OnClick для них:
procedure TForml.ButtonsClick(Sender: TObject);
begin
if not pFIBTransactionl.InTransaction then
pFIBTransactionl.StartTransaction;
pFIBStoredProcl.Params[0].Aslnteger := TButton(Sender).Tag;
try
pFIBStoredProcl.ExecProc;
pFIBTransactionl.Commit;
except
pFIBTransactionl.Rollback;
end;
end;
Смысл кода очевиден - мы задаем значение параметра процедуры, используя свойство Tag у кнопки, на которую нажал пользователь, выполняем процедуру при помощи метода ExecProc и либо подтверждаем транзакцию, либо отменяем ее в случае ошибки. Нам остается только написать обработчик события OnEventAlert компонента SIBfibEventAlerterl:
procedure TForml . SIBf ibEvent Alerter 1 Event Alert (Sender : TObject ;
EventName: String, EventCount: Integer);
begin
ShowMessage(EventName + ' : ' + IntToStr(EventCount));
end;
Параметр EventName возвращает название произошедшего события, a EventCount возвращает количество событий EventName. Значение параметра EventCount требует некоторых разъяснений. Итак, при работе с событиями важно помнить, что реально они вызываются только в случае подтверждения транзакции. Иными словами, если вы вызываете некоторое событие 'NEW_CUSTOMER' при вставке записей в таблицу, и вызываете Commit только после вставки 1000 записей, то обработчик OnEventAlert будет вызван только один раз, сразу после Commit, и значение параметра EventCount будет равно 1000. Очевидно, что событие произошло 1000 раз, но приложение получает нотификацию обо всех событиях только после подтверждения транзакции, в контексте которой они происходили.
Мы можем запустить наше приложение. При нажатии на любую из кнопок мы будем получать сообщение о произошедшем событии, причем, как уже было сказано, если наше приложение запущено несколько раз и даже на разных компьютерах, все копии приложения будут получать нотификацию о событиях.
"Низкоуровневая" работа с внутренним буфером TpFIBDataSet
TpFIBDataSet включает несколько специальных методов для работы с внутренним буфером, в котором хранятся записи. В общем-то, данные методы превращают TpFIBDataSet в аналог TClientDataSet, ориентированный на InterBase. Наиболее интересным примером использования данных методов будет, пожалуй, построение диалога выбора, состоящего из двух списков (рис. 2.75).

Рис 2.75. Использование локального кеша TpFIBDataSet для организации двойного списка выбора
В данном примере мы будем использовать базу данных EMPLOYEE.GDB, входящую в стандартную поставку InterBase и FIBPlus. Покажем запросы для SourceDS:
SelectSQL:
SELECT
CUS.CUST_NO,
CUS.CUSTOMER
FROM
CUSTOMER CUS
ORDER BY CUS.CUSTOMER
UpdateSQL:
UPDATE CUSTOMER SET
CUSTOMER = ?CUSTOMER
WHERE
CUST_NO = ?OLD_CUST_NO
InsertSQL:
INSERT INTO CUSTOMER(
CUST_NO,
CUSTOMER
)
VALUES(
?CUST_NO,
?CUSTOMER
)
DeleteSQL:
DELETE FROM CUSTOMER
WHERE
CUST_NO = ?OLD_CUST_NO
RefreshSQL:
SELECT
CUS.CUST_NO,
CUS.CUSTOMER
FROM
CUSTOMER CUS
WHERE
(
CUS.CUST_NO = ?OLD_CUST_NO
)
Те же самые запросы мы будем использовать в TargetDS, поскольку оба компонента должны обладать совместимой структурой полей. Откроем оба запроса сразу после создания формы:
procedure TDualListForm.FormCreate(Sender: TObject);
begin
SourceDS.Open;
TargetDS.CacheOpen;
end;
Если мы не указываем в коде явного открытия базы данных, то это означает, что свойство Connected > компонета TpFlBDatabase было задано в True в design-time.
Обратите внимание на то, что TargetDS мы активируем при помощи специального метода CacheOpen. Этот метод не выполняет запрос из SelectSQL, а только подготавливает внутренний буфер компонента в зависимости от запроса в SelectSQL. Очевидно, что после запуска приложения мы увидим записи в левом списке и пустую таблицу в правом. Теперь мы можем написать процедуру, которая позволит переносить записи из одного списка в другой:
procedure TDualListForm.MoveRec(Select: Boolean);
begin
if Select then begin
if (SourceDS.Active) and (not SourceDS.IsEmpty) then begin
TargetDS.CacheRefreshByArrMap(SourceDS, frklnsert,
['CUST_NO'], ['CUST_NO']);
SourceDS.CacheDelete;
end;
end
else begin
if (TargetDS.Active) and (not TargetDS.IsEmpty) then begin
SourceDS.CacheRefresh(TargetDS, frklnsert, nil);
TargetDS.CacheDelete;
end;
end;
end;
Если параметр Select равен True, то мы будем переносить текущую запись из левого списка в правый, т. е. из SourceDS в TargetDS. Рассмотрим подробнее метод CacheRefreshByArrMap.
procedure CacheRefreshByArrMap(FromDataSet: TDataSet; Kind:
TCachRefreshKind; const SourceFields, DestFields: array of
String);
Метод позволяет вставлять или модифицировать текущую запись в локальный буфер компонента, т. е. без выполнения соответствующих модифицирующих запросов. Параметр FromDataSet указывает, из какого TpFIBDataSet мы хотим получить запись. Параметр Kind может принимать два значения: frkEdit или frklnsert. Frklnsert указывает, что мы хотим вставить новую запись, a frkEdit - что мы хотим изменить существующую. Параметр SourceFields описывает список полей из компонента источника, а список DestFields - список полей в TpFIBDataSet-приемнике. Формально названия полей в списках могут не совпадать, но необходимо, чтобы совпадали типы данных, иначе обмен данными будет невозможен. В нашем примере, как вы можете видеть, мы вставляем в TargetDS текущую запись из SourceDS. Данный метод использован здесь только для демонстрации, поскольку мы вполне могли бы обойтись методом CacheRefresh, который копирует соответствующие поля автоматически. После вставки записи необходимо удалить ее из компонента источника. Это делается при помощи метода CacheDelete, который также не выполняет соответствующий запрос (DeleteSQL), а удаляет запись только из локального буфера в памяти. Теперь, когда мы знаем, что делают процедуры CacheRefreshByArrMap, CacheRefresh и CacheDelete, код процедуры достаточно очевиден: мы копируем запись из компонента-источника в компонент-приемник и удаляем ее из компонента-источника.
То же самое можно сделать в цикле, если мы хотим перенести все записи сразу:
procedure TDualListForm.MoveAll(Select: Boolean);
var TmpDataSet: TpFIBDataSet;
begin
if Select then TmpDataSet := SourceDS else
TmpDataSet := TargetDS;
with TmpDataSet do begin
try
DisableControls;
First;
while not Eof do MoveRec(Select);
finally
EnableControls;
end;
end;
end;
Остается написать обработчики события OnClick для кнопок:
procedure TDualListForm.ButtonlClick(Sender: TObject);
begin
MoveRec(True); // SourceDS -> TargetDS
end;
procedure TDualListForm.Button2Click(Sender: TObject);
begin
MoveRec(False); // TargetDS -> SourceDS
end;
procedure TDualListForm.Button3Click(Sender: TObnect);
begin
MoveAll(True), // SourceDS -> TargetDS
end;
procedure TDualListForm. Button4Click (Sender : TObject) ;
begin
MoveAll(False); // TargetDS -> SourceDS
end;
Мы можем запустить наше приложение (рис 2.76)
Если мы будем нажимать на кнопку Button 1, то записи будут переноситься из левого списка в правый (рис. 2 77).
Все операции осуществляются только с данными внутри локальных буферов, не затражвают сервер и реальные данные в базе Наряду с описанными выше методами вы также можете использовать.
OpenAsCIone - открыть DataSet и скопировать данные из другого DataSet
CacheAppend - добавить запись в конец локального буфера.
SwapRecords - обменять записи в локальном буфере.
CacheEdit - задать значения полей у записи в локальном буфере.
Cachelnsert - вставить запись в локальный буфер
CacheModify - общий метод для вставки и изменения записи в локальным буфере
LoadFromFile - заполнить локальный буфер записями из файла.
LoadFromStream - заполнить локальный буфер записями из потока.
SaveToFile - сохранить локальный буфер в файл.
SaveToStream - сохранить локальный буфер в потоке
Функции работы с локальным буфером предоставляют разработчику чрезвычайно гибкое средство манипуляции данными в клиентских приложениях, позволяя улучшать наглядность пользовательского интерфейса без выполнения дополнительных запросов к базе данных

Рис 2.76. Внешний вид запущенного приложения

Рис 2.77. Внешний вид приложения при выборе пользователем трех записей
Обработка потери подключения к базе данных
Корректная обработка потери подключения к базе данных является одной из проблем при разработке устойчивых приложений вообще и, пожалуй, самым важным вопросом при разработке приложения, которое будет работать в условиях нестабильного канала связи (в частности, при использовании dial-up).
FIBPIus предоставляет разработчику полный набор средств для обработки потери подключения: возможность аккуратно закрыть все приложение, "закрыть" (т. е. деактивировать все соответствующие компоненты) само подключение на уровне приложения или попробовать восстановить подключение без закрытия запросов.
Ключевым компонентом для обработки ситуации является TpFTBErrorHandler. Формально, потерю подключения мы будем обрабатывать при помощи компонента TpFIBDatabase в обработчике события OnLostConnect, однако без "глубокого" перехвата в TpFIBErrorHandler мы не сможем избавиться от лишних сообщений о потере подсоединения.
Итак, попробуем создать простое приложение, позволяющее редактировать данные в TDBGrid и обрабатывать потерю подключения к базе данных тремя способами, про которые уже было упомянуто (рис. 2.57).
Рис 2.57. Внешний вид главной формы примера Connection Lost
Заполним SelectSQL для CompaniesDataSet: select * from "Companies" и предоставим CompaniesDataSet самостоятельно генерировать модифицирующие запросы (рис. 2.58).
Рис 2.58. Свойства AutoUpdateOptions компонента CompaniesDataSet
Включим также режим CachedUpdates (CompaniesDataSet.CachedUpdates := True), чтобы корректно обрабатывать восстановление подключения без потери данных.
Компонент cmbKindOnLost: TComboBox будет содержать список возможных реакций на потерю подключения, чтобы мы могли во время выполнения приложения попробовать все возможности:
Close pFIBDataBase
Terminate application
Restore connect
Теперь обратим внимание на компонент pFIBErrorHandlerl (рис. 2.59).
TpFIBErrorHandler обрабатывает "особым" образом два типа ошибок: пользовательские исключения и потерю подключения к базе данных. В компонент заложена также возможность обработки ошибок, связанных с нарушением ссылочной целостности, однако в существующих версиях FIBPlus данная функция еще не реализована.
TpFIBErrorHandler имеет только одно событие - OnFIBErrorEvent, обработка которого позволит нам обработать, в частности, потерю подключения к базе данных:
procedure TForml.pFibErrorHandlerlFIBErrorEvent(Sender:
TObject;
ErrorValue: EFIBError; KindlBError: TKindlBError; var
DoRaise: Boolean);
begin
if KindlBError = keLostConnect then begin
DoRaise := false;
Abort;
end;
end;
Puc 2.59. Свойства компонента pFIBErrorHandlerl
Вот в общем-то и весь обработчик - мы просто запрещаем вывод стандартного сообщения о потере подключения. На практике вы сможете использовать OnFIBEnorEvent для более сложной обработки разного рода исключительных ситуаций, используя значение параметра ErrorValue. Для нашего случая важно также знать что, кроме срабатывания QnFIBErrorEvent, TpFIBErrorHandler инициирует возникновение OnLostConnection у компонентов TpFIBDatabase Именно здесь мы и сосредоточим основную обработку потери подсоединения.
procedure TForml.DatabaseLostConnect(Database: TFIBDatabase; E:
EFIBError;
var Actions: TOnLostConnectActions);
begin
AttemptRest := 0;
case cmbKindOnLost.Itemlndex of 0: begin
Actions := laCloseConnect;
MessageDlg('Connection lost. TpFIBDatabase will be closed'',
mtlnformamon, [mbOk] , 0
);
end;
1: begin
Actions := laTerminateApp;
MessageDlg('Connection lost. Application will be closed',
mtlnformation, [mbOk], 0
);
end;
2: Actions := laWaitRestore;
end;
end;
Смысл обработчика очевиден - в зависимости от выбранного пользователем значения компонента cmbKindOnLost наше приложение либо "закрывает" активное подключение и все соответствующие компоненты, либо закрывает все приложение, либо включает режим восстановления подсоединения. Первые два случая очевидны и в общем-то не требуют никаких дополнительных шагов, кроме установления значения параметра Actions. Более подробно мы остановимся на восстановлении подключения.
Поскольку CompaniesDataSet находится в режиме CachedUpdates, то потеря подключения не влияет на возможность редактирования данных пользователем, поскольку все изменения будут сохраняться в локальном буфере компонента CompaniesDataSet Таким образом, в задачу TpFIBDataBase входит только одно: периодически пытаться восстано'вить подключение и сообщать об удачных и неудачных попытках. Когда подсоединение будет восстановлено, мы просто применим "отложенные" изменения к данным в базе данных Конечно, никто не гарантирует, что отложенные команды смогут быть выполнены сервером, поскольку на момент восстановления подключения наши локальные данные могут совершенно потерять актуальность.
Итак, напишем два простых обработчика Первый для события Database OnErrorRestoreConnect
procedure TForml.DatabaseErrorRestoreConnect(Database:
TFIBDatabase;
E: EFIBError; var Actions: TOnLostConnectActions);
begin
Inc(AttemptRest);
Label4.Caption := IntToStr(AttemptRest);
Label4.Refresh;
end;
Компонент Label4 будет показывать счетчик попыток восстановления подсоединения. Второе событие, которое нас интересует, - AfterRestoreConnect:
procedure TForml DatabaseAfterRestoreConnect;
begin
MessageDlg('Connection restored. You can apply cached updates',
mtlnformation, [mbOk], 0
) ;
end;
Как только подключение к базе восстановлено, мы получим сообщение и сможем применить все сделанные изменения.
procedure TForml.ButtonlClick(Sender: TObject);
begin
with CompaniesDataSet do
try
if not DataBase.Connected then begin
try
DataBase.Connected . = True;
except
MessageDlg('Can''t restore connect',
mtlnformation, [mbOk], 0
);
Exit;
end
end;
if not Transaction.Active then Transaction StartTransaction;
ApplyUpdToBase;
Transaction.CoimutRetaining;
CommitUpdToCach;
except
if Transaction.Active then Transaction.RollBack;
end;
end;
На практике вы можете автоматически вызывать процедуру применения данных сразу из обработчика AfterRestoreConnect. В самой процедуре следует обратить внимание на методы ApplyUpdToBase и CommitUpdToCach. В отличие от стандартного метода ApplyUpdates, наследованного от TDataSet, который "не замечает" скрытые в результате локальной фильтрации записи (более подробно этот вопрос будет рассмотрен в разделе "Локальная фильтрация"), методы ApplyUpdToBase и CommitUpdToCach позволяют обойти эту ошибку VCL
Эмуляция Boolean-полей
Вы уже знаете, что InterBase не поддерживает логического типа данных. Чем бы это ни было вызвано, нам остается только огорчиться этим фактом, поскольку на практике логический тип очень удобен. Разработчики, использующие InterBase, вынуждены заменять его другими типами, вводя ограничение на множество допустимых значений. Как правило, в базе данных создается соответствующий домен одного из двух видов.
CREATE DOMAIN TBOOLEAN_CHAR AS CHAR(1)
DEFAULT 'F' NOT NULL
CHECK (VALUE IN ('F', 'T'))
CREATE DOMAIN TBOOLEAN_INT AS INTEGER
DEFAULT 0 NOT NULL
CHECK (VALUE IN (0, 1))
При использовании любой библиотеки компонент для доступа к InterBase оба способа совершенно равноценны, поскольку для полей, созданных с такими доменами, в приложении все равно не создаются Boolean-поля. То есть если мы добавим некоторое логическое поле к нашей таблице:
ALTER TABLE "Categories" ADD IS_ACTIVE TBOOLEAN_INT
NOT NULL
А потом, используя, например, компоненты IBX, сделаем выборку при помощи компонента TIBDataSet:
SELECT "Categories"."Name", "Categories".IS_ACTIVE
FROM "Categories"
то в результате компонент создаст два внутренних компонента для полей:
* TIBStringField для поля "Name" и
* TmtergerField для поля "IS_ACTIVE"
Последнее совершенно верно, поскольку формально поле "IS_ACTIVE" не является логическим. Таким образом, все визуальные компоненты типа TDBGnd и его расширенные аналоги от сторонних производителей не будут обрабатывать данное поле так, как нам бы хотелось. Например, если даже компонент умеет рисовать "галочки" для Boolean-полей, значения которых равно True, то поскольку он будет "видеть" всего лишь целочисленное поле, то и выводить он будет "0" и "1" Разумеется, если мы напишем соответствующие обработчики событий, то сможем добиться более или менее сносного отображения логических величин для поля TIntergerField, однако FIBPlus предоставляет гораздо более простое и качественное решение
Фактически оно состоит только в том, что нам необходимо добавить ключ poUseBooleanField в свойстве PrepareOptions (рис. 2.60).
Рис 2.60. Использование PrepareOptions для эмуляции Boolean—полей
После этого поля, созданные на основе целочисленного домена, в названии которого присутствует слово "boolean", будут считать логическими, и для них будут создаваться экземпляры TFIBBooleanField. Данный класс является прямым потомком класса TBooleanField и является полноценным логическим полем Любые визуальные компоненты для отображения данных будут работать с такими полями как с логическими, т. е. используя свойство AsBoolean. Вам же не придется писать для этого никакой дополнительный код.
Поддержка array-полей. Пример использования TpFIBUpdateObject и TDataSetContainer
InterBase с самых ранних версий позволял описывать в таблицах многомерные поля-массивы, делая хранение специализированных данных максимально удобным. Вы наверняка согласитесь, что матриц) проще всего хранить и обрабатывать в виде матрицы, а не раскладывать ее по отдельным полям и даже таблицам из-за ограничений реляционной модели Тем не менее поскольку array- поля не поддерживаются стандартом SQL, то и работа с такими полями на уровне SQL-запросов крайне затруднена. Фактически вы можете использовать массивы только поэлементно и только в операциях чтения Чтобы изменить значения array-поля, необходимо использовать специальные команды InterBase API. FIBPlus позволяет обойтись без подобных сложностей, взяв на себя всю рутину, связанную с array-полями
Мы продемонстрируем, как работать с array-полями при помощи FIBPlus на примере DemoArray5, входящем в стандартную поставку FIBPlus. Пример демонстрирует два варианта использования array-полей Первый способ позволяет редактировать array-поле при помощи специальных методов ArrayFieldValue и SetAiiayValue и работать с таким полем как с единой структурой (рис 2 6П
Рис 2.61. Внешний вид формы примера DemoArrayS Первый вариант использования array—полей
Рассмотрим запросы, заданные в соответствующих свойствах ArrayDataSet:
SeleetSQL
SELECT
JOB JOB_CODE,
JOB.JOB_GRADE,
JOB.JOB_COUNTRY,
JOB.JOB_TITLE,
JOB MIN_SALARY,
JOB.MAX_SALARY,
JOB.JOB_REQUIREMENT,
JOB.LANGUAGE_REQ
FROM
JOB JOB
ORDER BY 1,2,3
UpdateSQL:
UPDATE JOB SET
JOB_CODE = ?JOB_CODE,
JOB_GRADE = ?JOB_GRADE,
JOB_COUNTRY = ?JOB_COUNTRY,
JOB_TITLE = ?JOB_TITLE,
MIN_SALARY = ?MIN_SALARY,
MAX_SALARY = ?MAX_SALARY,
JOB_REQUIREMENT = ?JOB_REQUIREMENT,
JOB.LANGUAGE_REQ= ?LANGUAGE_REQ WHERE
JOB_CODE = ?OLD_JOB_CODE
and JOB_GRADE = ?OLD_JOB_GRADE
and JOB_COUNTRY = ?OLD_JOB_COUNTRY
InsertSQL
INSERT INTO JOB(
JOB_CODE,
JOB_GRADE,
JOB_COUNTRY,
JOB_TITLE,
MIN_SALARY,
MAX_SALARY,
JOB_REQUIREMENT,
JOB.LANGUAGE_REQ
)
VALUES(
?JOB_CODE,
?JOB_GRADE,
?JOB_COUNTRY,
?JOB_TITLE,
?MIN_SALARY,
?MAX_SALARY,
?JOB_REQUIREMENT,
?LANGUAGE_REQ
)
DeleteSQL:
DELETE FROM JOB
WHERE
J03_CODE = ? OLD_JOB_CODE
and JOB_GRADE = ?OLD_JOB_GRADE
and JOB_COUNTRY = ?OLD_JOB_COUNTRY
RefreshSQL:
SELECT
JOB.JOB_CODE,
JOB.JOB_GRADE,
JOB.JOB_COUNTRY,
JOB.JOB_TITLE,
JOB.MIN_SALARY,
JOB.MAX_SALARY,
JOB.JOB_REQUIREMENT,
JOB.LANGUAGE_REQ
FROM
JOB JOB
WHERE
(
JOB.JOB_CODE = ?OLD_JOB_CODE
and JOB.JOB_GRADE = ?OLD_JOB_GRADE
and JOB.JOB_COUNTRY = ?OLD_JOB_COUNTRY
)
Поле LANGUAGE_REQ является массивом (LANGUAGE_REQ VARCHAR(15) [1:5]) и, как видно из запросов, обрабатывается целиком, а не поэлементно. С одной стороны это удобно, но не позволяет использовать для редактирования таких полей специализированные визуальные компоненты типа TDBGrid. Если мы используем array-поля для хранения значительных массивов данных, мы в любом случае будем использовать "ручную" обработку данных, не прибегая к помощи визуальных компонент. Однако для наглядности примера мы позволим редактировать элементы массива в компонентах TEdit.
Фактически нам понадобится написать только два основных обработчика для событий: BeforePost и OnPostError
procedure TForml.ArrayDataSetBeforePost(DataSet: TDataSet);
begin
with ArrayDataSet do begin
SetArrayValue(FieldByName('LANGUAGE_REQ'),
VarArrayOf([
Editl.Text,
Edit2.Text,
Edit3.Text,
Edit4.Text,
Edits.Text
]) ) ;
end;
end;
procedure TForml.ArrayDataSetPostError(DataSet: TDataSet;
E: EDatabaseError; var Action: TDataAction);
begin
Action := daAbort;
MessageDlg('Error!', mtError, [mbOk], 0);
ArrayDataSet.Refresh;
end;
Метод SetArrayValue позволяет задать все элементы поля в виде массива. Важным моментом является обработчик ошибки ArrayDataSetPostError В случае неудачной операции Update или Insert необходимо восстанавливать внутренний идентификатор массива у редактируемой записи. Это правило диктуется функциями InterBase API, и мы должны их придерживаться. Для восстановления идентификатора необходимо получить значения полей текущей записи заново, что и делается при помощи явного вызова метода Refresh.
Для автоматического заполнения визуальных компонентов значениями элементов массива мы можем написать обработчик события AfterScroll:
procedure TForml.ArrayDataSetAfterScroll(DataSet: TDataSet);
var v: Variant;
begin
with ArrayDataSet do try
FInShowArrays := true;
v := ArrayFieldValue(FieldByName('LANGUAGE_REQ'));
Editl.Text := VarToStr(v[l]);
Edit2.Text := VarToStr(v[2]);
Edit3.Text := VarToStr(v[3]);
Edit4.Text := VarToStr(v[4]);
EditS.Text := VarToStr(v[5]);
finally
FInShowArrays:=false;
end;
end;
Флаг FInShowArrays используется в примере для того, чтобы не включать режим редактирования записи при обычной навигации.
Рекомендуется иметь под руками полный текст примера, который доступен на сайте http://www.fibplus.net. В книге мы указываем только те части примера, которые имеют непосредственное и наибольшее значение для работ с array-полями. Однако без полного текста некоторые части исходного текста могут показаться не до конца наглядными.
Данный способ работы с array-полями нельзя применять в режиме CachedUpdates.
Второй способ работы с array-полями позволяет использовать их в "живых" запросах и редактировать при помощи стандартных визуальных компонентов (рис. 2.62).
Рассмотрим запросы, указанные в свойствах ArrayDataSet:
SelectSQL:
SELECT
JOB.JOB_CODE,
JOB.JOB_GRADE,
JOB.JOB_COUNTRY,
JOB.JOB_TITLE,
JOB.LANGUAGE_REQ[1] LQ1,
JOB.LANGUAGE_REQ[2] LQ2
FROM
JOB JOB
ORDER BY 1,2,3
Рис 2.62. Внешний вид формы примера DemoArrayS. Второй вариант использования array-полей
UpdateSQL:
UPDATE JOB SET
JOB_TITLE = -?JOB_TITLE,
JOB JOB_GRADE=?JOB_GRADE,
JOB.JOB_COUNTRY=?JOB_COUNTRY,
LANGUAGE_REQ = ''LQ
WHERE
JOB_CODE = ?OLD_JOB_CODE
and JOB_GRADE = ?OLD_JOB_GRADE
and JOB_COUNTRY = ?OLD_JOB_COUNTRY
InsertSQL:
INSERT INTO JOB(
JOB_CODE,
JOB_GRADE,
JOB_COUNTRY,
JOB_TITLE,
LANGUAGE_REQ
)
VALUES(
?JOB_CODE,
?JOB_GRADE,
?JOB_COUNTRY,
?JOB_TITLE,
?LQ
)
DeleteSQL:
DELETE FROM JOB
WHERE
JOB_CODE = ?OLD_JOB_CODE
and JOB_GRADE = ?OLD_JOB_GRADE
and JOB_COUNTRY = ?OLD_JOB_COUNTRY
RefieshSQL:
SELECT
JOB.JOB_CODE,
JOB.JOB_GRADE,
JOB.JOB_COUNTRY,
JOB.JOB_TITLE,
JOB.LANGUAGE_REQ[1] LQ1,
JOB.LANGUAGE_REQ[2] LQ2
FROM
JOB JOB
WHERE
(
JOB.JOB_CODE = ?OLD_JOB_CODE
and JOB. JOB_GRADE = ?OLD_JOB_GRADE
and JOB.JOB_COUNTRY = ?OLD_JOB_COUNTRY
)
На этот раз мы выбираем только два элемента из нашего поля-массива. Обратите внимание' несмотря на то что в выбирающем запросе мы явным образом выделяем два элемента массива, а в модифицирующих запросах мы обновляем поле целиком На самом деле, это, конечно, не совсем так, однако данный синтаксис наиболее удобен и близок к естественному SQL-запросу несмотря на то что во внутренней реализации FIBPlus использует специальные функции работы с массивами Обратим внимание на компонент QryAirField TpFIBUpdateObject. Именно он позволит нам правильно сформировать значение параметра "LQ" в модифицирующих запросах Разумеется, для этой цели вполне бы подошел и простой TpFIBQuery, однако удобство TpFIBUpdateObject заключается в первую очередь в том, что он выполняет запрос автоматически и сам подставляет туда нужные значения параметров в зависимости от значений TpFIBDataSet. Вот запрос, который выполняет QryArrField SELECT
JOB LANGUAGE_REQ,
JOB JOB_CODE
FROM
JOB JOB
WHERE
JOB JOB_CODE=?OLD_JOB_CODE and
JOB.JOB_GRADE=?OLD_JOB_GRADE and
JOB.JOB_COUNTRY=?OLD_JOB_COUNTRY
Обратим внимание на свойства QryArrField (рис 2 63)
Рис 2.63. Свойство компонента QryArrField
Обработчик QiyAnField AtteiExecute
procedure TForm2 QryArrFieldAfterExecute(Sender: TObject);
var v Variant,
begin
v = QryArrField Fields[0] GetArrayValues,
with ArrayDataSet do begin
v[l] = FieldByName('LQ1') AsString,
v[2] = FieldByName( LQ2 ) AsString,
QryArrField Fields[0] SetArrayValue(v);
QUpdate Params ByName[ LQ ] AsQuad :=
QryArrField.Fields[0] AsQuad;
end;
QryArrField Close;
end;
Теперь все становится совершенно очевидным Поскотьку свойство QiyAnField KindUpdate равно ukModify, то QiyArrField выполняет запрос при изменении записи в AnayDataSet а поскольку свойство QiyArrField ExecuteOider равно eoBeforeDefault, то запрос (QiyArrField SQL) выполняется до того, как AirayDataSet выполнит свой собственный UpdateSQL В обработчике QryArrField AfterExecute мы всего лишь получаем заново все текущие элементы массива из базы данных, подменяем два из них новыми значениями, которые указал пользователь, и задаем значение параметра для ArrayDataSet.UpdateSQL Это означает что при выполнении ArrayDataSet.UpdateSQL формально будут обновлены все пять элементов массива но фактически изменены значения тотько двух элементов, которые изменил пользователь в TDBGrid.
Как видите работа с массивами достаточно проста поскотьку все основные сложности решают компоненты FIBPlus Хотелось бы также рассмотреть еще один специализированный компонент, входящий в FIBPlus Пример DemoArray демонстрирует работу с TDataSetContamei, использованным для синхронизации значений двух TpFIBDataSet, редактирующих наше апау-поле (рис 2 64)
Рис 2.64. Использование TDatabetContamer
Компонент DataSetContamerl помещен вместе с Database и Transaction на DataModule в нашем приложении Оба компонента AnayDataSet из разных форм нашего приложения ссылаются на DataSetContamerl при помощи свойства Contamei (рис 2 65)
Рис 2.65. Подключение компонентов TpFIBDataSet к DataSetContamerl
Компонент TDataSetContamei позволяет централизованно обрабатывать события от разных компонентов TpFIBDataSet, а также (расширяя, таким образом, список стандартных событий) посылать им сообщения, при получении которых они могут производить какие-то дополнительные действия. В нашем примере DataSetContainerl имеет обработчики двух событий OnDataSetEvent и OnUserEvent
procedure TDataModule2.DataSetsContainerlDataSetEvent(DataSet:
TDataSet;
Event: TKindDataSetEvent);
var Info: string;
begin
if Event = deAfterPost then
if DataSet.Owner.Name = 'Forml' then
DataSetsContainerl.NotifyDataSets(DataSet,
'Form2.ArrayDataSet', 'JOB_TABLE_CHANGED', Info)
else
if DataSet.Owner.Name = 'Form2' then
DataSetsContainerl.NotifyDataSets(DataSet,
'Form1.ArrayDataSet', 'JOB_TABLE_CHANGED', Info);
end;
procedure TDataModule2.DataSetsContainerlUserEvent(Sender:
TObject;
Receiver: TDataSet; const EventName: String; var Info:
String) ;
begin
if EventName = 'JOB_TABLE_CHANGED' then begin
with TpFIBDataSet(Sender) do
if (not CachedUpdates) and
(not TpFIBDataSet(Receiver).CachedUpdates) then
if
TpFIBDataSet(Receiver).Locate('JOB_CODE;JOB_GRADE;JOB_COUNTRY', varArrayOf([
FieldByNamet'JOB_CODE').AsString,
FieldByName('JOB_GRADE').AsString,
FieldByName('JOB_COUNTRY').AsString
]), []) then TpFIBDataSet(Receiver) Refresh
end;
end;
Смысл действий сводится к следующему: после изменения записи в одном из наших компонентов ArrayDataSet происходит событие AfterPost. Поскольку DataSetContainerl перехватывает все события у подчиненных компонентов, то срабатывает обработчик OnDataSetEvent. Параметр Event равен deAfterPost, а параметр DataSet ссылается на тот компонент, в котором произошло изменение записи. При помощи вызова метода NotifyDataSets DataSetContainerl посылает сообщение оставшемуся компоненту ArrayDataSet о том, что произошло изменение записи. Поскольку оба компонента на самом деле редактируют одну и ту же таблицу, то желательно синхронизировать изменения. Синхронизация происходит в обработчике события OnUserEvent, то есть при получении "извещения" об изменении какого-либо из ArrayDataSet.
Если получено сообщение "JOB_TABLE_CHANGED" и ни в одном из наших двух ArrayDataSet не включен режим CachedUpdates (в этом случае Refresh просто ничего не даст), то мы позиционируемся на соответствующую запись и вызываем для нее метод Refresh, обновив, таким образом, запись в одном ArrayDataSet после того, как она была изменена в другом ArrayDataSet.
Данная технология является совершенно уникальной: использование DataSetContainer позволяет делать чрезвычайно гибкие и в то же время прозрачные схемы обработки и синхронизации данных в нескольких компонентах TpFIBDataSet.
Работа с BLOB-полями
Достаточно часто желательно хранить в базе данных разнообразные неструктурированные данные: изображения, OLE-объекты, звук и т. д. Специально для этих целей существует специальный тип данных - BLOB Продемонстрируем использование BLOB-полей на примере простого приложения (см. рис. 2.66), использующего следующую таблицу:
CREATE TABLE BIOLIFE (
ID INTEGER NOT NULL,
CATEGORY VARCKAR (15) character set WIN1251 collate
WIN1251,
COMMON_NAME VARCHAR (30) character set WIN1251 collate
WIN1251,
SPECIES_NAME VARCHAR (40) character set WIN1251 collate
WIN1251,
LENGTH_CM_ DOUBLE PRECISION,
LENGTH_IN DOUBLE PRECISION,
NOTES BLOB sub_type 1 segment size 80,
GRAPHIC BLOB sub_type 0 segment size 80);
Для вывода изображений, сохраненных в поле GRAPHIC, мы будем использовать стандартный компонент DBIMagel: TDBImage. Очевидно также, что запросы при работе с BLOB-полями ничем не отличаются от запросов со стандартными типами полей:
SelectSQL:
SELECT * FROM BIOLIFE
UpdateSQL:
UPDATE BIOLIFE Set
ID=?NEW_ID,
CATEGORY=?NEW_CATEGORY,
COMMON_NAME=?NEW_COMMON_NAME,
SPECIES_NAME=?NEW_SPECIES_NAME,
LENGTH__CM_=?NEW_LENGTH_CM_,
LENGTH_IN=?NEW_LENGTH_IN,
NOTES=?NEW_NOTES,
GRAPHIC=?NEW_GRAPHIC
WHERE ID=?OLD_ID
Рис 2.66. Внешний вид формы приложения для работы с BLOB-полями
InsertSQL:
INSERT INTO BIOLIFE(
ID,
CATEGORY,
COMMON_NAME,
SPECIES_NAME,
LENGTH__CM_,
LENGTH_IN,
NOTES,
GRAPHIC
)
VALUES (
?NEW_ID,
?NEW_CATEGORY,
?NEW_COMMON_NAME,
?NEW_SPECIES_NAME,
?NEW_LENGTH_CM_,
?NEW_LENGTH_IN,
?NEW_NOTES ,
?NEW_GRAPHIC
)
DeleteSQL:
DELETE FROM BIOLIFE
WHERE ID=?OLD_ID
RefreshSQL:
SELECT * FROM BIOLIFE
WHERE
ID=?OLD_ID
Единственным отличием от обычных типов данных является то, что для присвоения значения BLOB-параметру необходимо использовать потоки (специализированные потомки стандартного класса TStream). Например, если мы хотим сохранить в нашем поле изображение из внешнего файла, то мы можем написать следующий обработчик нажатия на кнопку:
procedure TMainForm.OpenBClick(Sender: ТОbjесt);
var S. TStream;
FileS: TFileStream;
begin
if not OpenD.Execute then exit;
pFIBDataSetl.Edit;
S : =
pFIBDataSetl.CreateBlobStream(pFIBDataSetl.FieldByName('GRAPHIC') , bmReadWrite);
try
FileS := TFiIeStream.Create(OpenD.FileName, fmOpenRead);
S.CopyFrom(FileS, FileS.Size);
finally
FileS.Free;
S.Free;
pFIBDataSetl.Post;
end;
end;
Обратите внимание на важный момент - перед тем как присваивать значение BLOB-параметру, необходимо перевести pFIBDataSet в состояние редактирования данных. В данном случае это делается безусловным вызовом метода Edit. Вызов метода CreateBlobStream создает экземпляр специального внутреннего класса TFIBDSBlobStream. Скорее всего, вам не придется использовать этот класс напрямую. В нашем примере он нужен только для обмена данными между BLOB-параметром и потоком, который читает данные из файла с изображением. Параметр bmReadWrite означает, что мы собираемся изменять содержимое параметра. Поток S напрямую связан с BLOB-параметром, поэтому, копируя данные из файла (FileS) в поток S, мы фактически присваиваем значение параметру. Остается только сохранить изменения вызовом метода Post Аналогичным образом мы можем сохранить значение BLOB-поля в некоторый внешний файл:
procedure TMainForm.SaveBClick(Sender: TObject);
var S: TStream;
FileS: TFiIeStream;
begin
if not SaveD.Execute then exit;
if not pFIBDatasetl.FieldByName('GRAPHIC').IsNull then begin
S : =
pFIBDatasetl.CreaceBlobStream(pFIBDatasetl.FieldByName('GRAPHIC '), bmRead);
try
if FileExists(SaveD.FileName) then
FileS := TFileStream.Create(SaveD.FileName, fmOpenWrite)
else
FileS := TFileStream.Create(SaveD.FileName, fmCreate);
FileS.CopyFrom(S, S.Size);
finally
S.Free;
FileS.Free;
end;
end;
end;
Обратите внимание, что в этой процедуре мы используем параметр bmRead при создании потока S. Очевидно, что для сохранения содержимого BLOB-поля в файл нам не нужно изменять само поле, поэтому мы создаем поток только для чтения. Еще более простым способом мы можем очистить содержимое BLOB-поля:
procedure TMainForm.ButtonlClick(Sender: TObject);
begin
pFIBDataSetl .Edit;
pFIBDataSetl.FieldByName('GRAPHIC').Clear;
pFIBDataSetl.Post;
end;
В этом случае даже не требуется создавать какие-либо потоки. Иногда также нужно знать, является ли BLOB-поле пустым или нет. При использовании визуальных компонентов типа TDBImage мы не можем быть в этом уверены. Согласитесь, что никто не мешает нам "нарисовать" пустую картинку и сохранить ее в BLOB-поле В этом случае мы не сможем отличить "на глаз": есть ли какое-то изображение в BLOB-поле или нет. Однако мы можем написать обработчик события OnDataChange компонента DataSourcel: TDataSource:
procedure TMainForm.DataSourcelDataChange(Sender: TObject;
Field: TField) ;
begin
CheckBoxl.Checked :=
pFIBDataSetl.FieldByName('GRAPHIC').IsNull;
end;
Это событие вызывается, в частности, при навигации по DBGridl; таким образом, мы всегда можем узнать, является ли текущее поле пустым или нет.
Если вы используете TpFIBQuery для работы с BLOB-полями, то общий принцип остается тем же - необходимо использовать потоки, однако, в отличие от TpFIBDataSet, вам не потребуется создавать какие-то специальные потоки. Например, мы можем написать следующую процедуру, которая сохранит в файлы все изображения из нашей таблицы:
pFIBQuery.SQL: SELECT * FROM BIOLIFE
procedure TMainForm.Button2Click(Sender: TObject);
var SaveFile: TFileStream;
Index: Integer;
begin
with pFIBQueryl do begin ExecQuery;
Index := 1;
while not Eof do begin
SaveFile := TFileStream.Create(IntToStr(Index) + '.bmp',
fmCreate);
FN('GRAPHIC').SaveToStream(SaveFile);
Next;
inc(Index);
SaveFile.Free;
end;
Close;
end;
end;
Метод FN является аналогом FieldByName.
Смысл кода, приведенного выше, совершенно очевиден: мы получаем все записи из таблицы BIOLIFE, в цикле получаем от сервера очередную запись из запроса, создаем файл при помощи потока SaveFile, сохраняем в него значение поля GRAPHIC и запрашиваем следующую запись при помощи метода Next. Аналогичным образом мы могли бы присваивать значение BLOB-параметру: pFIBQuery.SQL: INSERT INTO BIOLIFE (GRAPHIC) VALUES (7GRAPHIC)
procedure TMainForm.Button2Click(Sender: TObject);
var SaveFile: TFileStream;
Index: Integer;
begin
with pFIBQueryl do begin
Prepare;
for Index := 1 to 3 do begin
SaveFile := TFileStream.Create(IntToStr(Index) + '.bmp', fmOpenRead);
Params[0].LoadFromStream(SaveFile);
SaveFile.Free;
ExecQuery;
end;
Transaction.Commit;
end;
end;
Данный пример вставляет три новые записи в таблицу BIOLIFE и сохраняет в них изображения из некоторых файлов "l.bmp", "2.bmp" и "3.bmp".
Поскольку в данном примере для сохранения изменений использовался метод Commit, то необходимо перезапустить приложение, чтобы увидеть вставленные записи в DBGridl.
Локальная сортировка и локальная фильтрация
TpFIBDataSet позволяет разработчику оптимизировать работу с базой данных, используя в случае необходимости локальную сортировку данных и локальную фильтрацию. Термин "локальный" в данном случае означает, что в этих механизмах не используются дополнительные запросы к серверу. Таким образом, в определенных случаях вы можете значительно снизить сетевой трафик вашего приложения, а также увеличить скорость поиска или сортировки данных.
Локальная сортировка
Рассмотрим локальную сортировку на примере Sorting, который входит в поставку FIBPlus.
Как и все остальные примеры, приложение Sorting вы можете наши на сайте http://www.fibplus.net
Пример использует таблицу EMPLOYEE из базы данных Employee.gdb (рис. 2.67)
Рис 2.67. Внешний вид формы приложения, демонстрирующего локальную сортировку в TpFIBDataSet
MainDS.SelectSQL: SELECT * FROM EMPLOYEE
Все записи, полученные от сервера в результате запроса, сохраняются в локальном буфере компонента TpFIBDataSet.
Это одна из причин, из-за которой не рекомендуется использовать TpFIBDataSet для слишком больших выборок, - вам просто может не хватить оперативной памяти и работа приложения замедлится.
Предположим, что пользователь хочет отсортировать записи по полю FIRST_NAME. Очевидно, что мы можем сформировать новый запрос:
SELECT * FROM EMPLOYEE
ORDER BY FIRST_NAME
Чтобы получить новый порядок записей, необходимо переоткрыть наш запрос. Это работает, но означает, что мы будем повторно получать от сервера все •записи, несмотря на то что нам нужно было всего лишь поменять их визуальный порядок. Если предполагать, что нашим приложением могут пользоваться одновременно несколько пользователей, то затраты на подобные "сортировки" могут оказаться довольно значительными. Тем не менее выход существует, поскольку TpFIBDataSet позволяет сортировать данные внутри своего локального буфера, т. е. без необходимости получения всех записей заново.
Для этого мы должны воспользоваться одним из возможных вариантов метода DoSort или DoSortEx:
procedure DoSort(Fields: array of const; Ordering: array of Boolean); virtual;
procedure DoSortEx(Fields: array of integer; Ordering: array of Boolean); overload;
procedure DoSortEx(Fields: TStrings; Ordering: array of Boolean); overload;
Метод DoSortEx доступен в FIBPlus начиная с версии Delphi 4.
Первый параметр всех трех процедур - это список полей, по которым мы хотим отсортировать данные. В случае DoSort это могут быть названия полей или номера полей. Первый вариант DoSortEx позволяет нам использовать только список с номерами полей, а второй вариант DoSortEx предполагает, что мы заполнили список Fields названиями полей. Параметр Ordering во всех трех случаях указывает направление сортировки по каждому из полей. Таким образом, мы можем отсортировать наш запрос по полю FIRST_NAME следующим образом:
DoSort(['FIRSN_NAME'], [True]);
Или: DoSortEx([1], [True]);
[True] означает, что поле сортируется по возрастанию (ASCENDING).
В сущности, использование этих методов очевидно, однако иногда возникает вопрос, связанный с динамическим формированием списков полей. Рассмотрим подробнее наш пример, который демонстрирует, как создавать параметры для DoSortEx динамически. Предполагается, что пользователь сможет нажимать на заголовки DBGridl, указывая, таким образом, поле, которое будет участвовать в сортировке. Повторное нажатие на колонку, которая уже участвует в сортировке, будет изменять порядок сортировки по этой колонке на противоположный. Сначала мы опишем вспомогательный класс для хранения информации о молях, которые будут участвовать в сортировках.
type
TOrderStringList = class(TStringList)
protected
function GetAscending(Index: Integer): boolean;
procedure SetAscending (Index: Integer; Value: boolean);
public
property Ascending[Index: Integer]: boolean read
GetAscending write SetAscending;
end;
...
{ TOrderStringList }
function TOrderStringList.GetAscending(Index: Integer):
boolean;
begin
Result := boolean(integer(Objects[Index]));
end;
procedure TOrderStringList.SetAscending(Index: Integer; Value:
boolean);
begin
Objects [ Index] := pointer (integer (Value));
end;
Очевидно, что данный класс является списком строк - названия полей, а также хранит для каждого поля, включенного в список, порядок сортировки в виде свойства Ascending. Ниже вы видите описание класса формы, а также два основных обработчика событий (OnCreate, OnDestroy). При создании формы мы создаем экземпляр класса TOrderStringList, а при ее уничтожении - удаляем.
TMainForm = class(TForm)
MainDB: TpFIBDatabase;
MainDS: TpFIBDataSet;
MainTr: TpFIBTransaction;
DataSourcel: TDataSource;
DBGridl: TDBGrid;
Buttonl: TButton;
Label2: TLabel;
procedure DBGridlTitleClick(Column: TColumn);
procedure FormCreate(Sender: TObject);
procedure FormDestroy(Sender: TObject);
procedure ButtonlClick(Sender: TObject);
private
{ Private declarations }
public
{ Public declarations }
SortFields: TOrderStringList;
procedure ReSort;
end;
procedure TMainForm.FormCreate(Sender: TObject);
begin
SortFields := TOrderStringList.Create;
end;
procedure TMainForm.FormDestroy(Sender: TObject);
begin
SortFields.Free;
end;
Теперь напишем обработчик события OnTitleClick у компонента DBGridl:
procedure TMainForm. DBGndlTitleCiiCK (Column: TColumn);
const OrderScr: array [boolean] of string = ('(DESC)',
'(ASC) ') ;
var aField: string;
aFieldlndex: integer;
begin
aField := Column.FieldName;
aFieldlndex := SortFields.IndexOf(aField) ;
if aFieldlndex = -1 then begin
SortFields.Add(aField);
SortFields.Ascending[SortFields.Count - 1] := true;
Column.Field.Display-Label := Column. Field.FieldName + OrderStr[true];
end
else begin
SortFields.Ascending[aFieldlndex] := not
SortFields.Ascending[aFieldlndex];
Column.Field.Display-Label := Column.Field.FieldName +
OrderStr[SortFields.Ascending[aFieldlndex]];
end;
ReSort;
end;
Смысл обработчика состоит в следующем: при нажатии пользователем на заголовок мы проверяем, есть ли данное поле в нашем списке сортировки. Если нет, то мы добавляем его и формируем новый заголовок для колонки, который теперь будет состоять из названия поля и порядка сортировки (ASC) или (DESC). Если же поле уже было включено в сортировку, то мы лишь меняем порядок сортировки. В обоих случаях мы должны вызвать процедуру ReSort, описанную ниже:
procedure TMainForm.ReSort;
var Orders: array of boolean;
Index: Integer;
begin
if SortFields.Count = 0 then begin MainDS.CloseOpen(false);
exit;
end;
SetLength(Orders, SortFields.Count);
for Index := 0 to pred(SortFields.Count) do
Orders[Index] := SortFields.Ascending[Index];
MainDS.DoSortEx(SortFields, Orders);
end;
Данная процедура формирует списки для метода DoSortEx на основе списка SortFields и пересортировывает записи. В случае, если наш список сортировки пустой, мы должны вернуться к "стандартному" порядку записей. Для этого вызывается метод CloseOpen.
Параметр False означает, что мы не хотим автоматически получать сразу все записи от сервера.
Если наш список полей не пустой, то мы должны сформировать массив Orders. Это делается, как видно, достаточно легко. Используя динамические массивы, мы сначала задаем длину Orders равной количеству полей в списке SortFields, а потом последовательно заполняем Orders значениями свойства Ascending списка SortFields. Остается только вызвать метод DoSortEx - и сортировка б\дет выполнена.
Чтобы закрыть вопрос целиком, нам остается только предоставить пользователю возможность исключать поля из сортировки. Для этого мы положим на форму кнопку Button 1 (см. рис. 46, заголовок "Delete column from Sorting"):
procedure TMainForm.ButtonlClick(Sender: TObject);
var aField: string;
aFieldlndex: integer;
begin
aField := DBGridl.SelectedField.FieldName;
aFieldlndex := SortFields.IndexOf(aField);
if aFieldlndex <> -1 then begin
SortFields.Delete(aFieldlndex);
DBGridl.SelectedField.DisplayLabel := aField;
ReSort;
end;
end;
Пользователь выделяет поле, которое хочет удалить из сортировки, и нажимает на кнопку "Delete column from Sorting", после чего это поле удаляется из списка SortFields и производится пересортировка записей.
Локальная фильтрация
Аналогично локальной сортировке, которая оперирует только с данными в локальном буфере, мы можем также выбирать записи из уже полученных по какому-либо критерию, скрывая от пользователя "лишние" записи.
Рассмотрим локальную фильтрацию на примере приложения Filtering. Этот пример включен в стандартную поставку FIBPlus. В примере используется база данных FIBPlus_Example.gdb (рис. 2.68).
Эта база данных в виде backup-файла доступна на сайте http://www.fibplus.net/
Рис 2.68. Использование локальной фильтрации TpFIBDataSet
Совершенно очевиден код для подключения к базе данных. Список элементов компонента FieldsC: TComboBox заполняется названиями полей из таблицы BIOLIFE.
FilteringDS.SelectSQL: SELECT * FROM BIOLIFE
procedure TMainForm.btnConnectClickfSender: TObject);
var Index: Integer;
begin
with MainDB do begin
ConnectParams.UserName := edtUserName.Text;
ConnectParams.Password := edtPassword.Text;
DBName := edtDataBase.Text;
try
Open;
FilteredDS.Open;
FieldsC.Items.Clear;
for Index := 0 to pred(FilteredDS.FieldCount) do
FieldsC.Items.Add(FilteredDS.Fields[Index].FieldName);
except
MessageDlgt'Error of connection to a database!', mtError, [mbOk], 0) ;
Close;
end;
end;
end;
Пользователь может выбрать поле из списка FieldsC, указать в поле FilterE: TEdit строку для поиска и после нажатия на кнопку Button I ("Activate Filter"):
procedure TMainForm.ButtonlClick(Sender: T0b3ect);
begin
FilteredDS.Filtered := false;
FilteredDS.Filtered := true;
end;
в DBGrid 1 останутся видны только те записи, которые содержат в заданном поле искомую строку Для этого нам необходимо написать обработчик события OnFilterRecord у FilteringDS:
procedure TMainForm.FilteredDSFilterRecord(DataSet: TDataSet;
var Accept: Boolean); begin
Accept := DOS(FilterE.Text,
FilteredDS.FieldByName(FieldsC.Text).AsString) <> 0
end;
После включения FilteredDS.Filtered := true OnFilterRecord вызывается для каждой записи в локальном буфере. Если мы хотим, чтобы конкретная запись оставалась видимой, мы должны задать для нее параметр Accept равным True. Из примера кода видно, что мы оставляем видными только те записи, которые содержат в искомом поле (FieldsC.Text) заданную строку (FilterE.Text). Если мы, например, выберем поле COMMON_NAME и укажем строку для поиска "А", то в результате получим только две видимые записи (рис. 2.69).
Рис 2.69. Пример двух "отфильтрованных" записей
Поскольку наше условие для фильтра сформулировано таким образом, что мы выбираем записи по точному включению искомой подстроки - в нашем случае это только те записи, которые содержат большую букву "А". Мы можем немного усложнить условие поиска. Положим на форму CaseC: TcheckBox (см. рис. 2.69, "Case sensitive") и перепишем обработчик OnFilterRecord следующим образом:
procedure TMainForm.FilteredDSFilterRecord(DataSet: TDataSet;
var Accept: Boolean);
begin
if CaseC.Checked then
Accept := pos(FilterE.Text,
FilteredDS.FieldByName(FieldsC.Text).AsString) <> 0
else
Accept := pos(AnsiUpperCase(FilterE.Text),
AnsiUpperCase(FilteredDS.FieldByName(FieldsC.Text).AsString))
<> 0;
end;
Очевидно, что теперь если пользователь отключит "флажок" "Case sensitive", то фильтр по строке "А" будет содержать гораздо большее количество записей - все записи, которые содержат хотя бы одну букву "А", неважно маленькую или большую (рис. 2.70).
Рис 2.70. Записи, содержащие букву "А"
Очевидно, что использование локальной фильтрации дает разработчику в руки очень гибкое средство построения условий, поскольку этот механизм не столько ограничен, как SQL в условиях WHERE. На основе локальной фильтрации, например, очень легко создается механизм быстрого поиска записи по первым буквам, которые пользователь набирает в поле редактирования.
Обработка событий InterBase при помощи FIBPIus
InterBase дает разработчику некоторый механизм для синхронизации приложений в многопользовательской среде Event Alerts. Суть данного механизма состоит в том. что вы можете вызывать пользовательские события из триггеров или хранимых процедур при помощи функции POST_EVENT:
CREATE PROCEDURE SHOW_EVENT(
EVENT_ID INTEGER)
AS
BEGIN
IF (:EVENT_ID = 1) THEN POST_EVENT 'TEST_EVENT1';
IF (.EVENT_ID = 2) THEN POST_EVENT 'TEST_EVENT2';
IF (.EVENT_ID = 3) THEN POST_EVENT 'TEST_EVENT3';
EXIT;
END
Создадим приложение (рис 2.71), которое будет вызывать данную процедуру и получать соответствующие события Если вы впоследствии попробуете запустить это приложение на двух компьютерах, то оба приложения будут получать сообщения вне зависимости оттого, кто их инициировал
Рис 2.71. Использование InterBase events, при помощи компонента TSIBfibEventAlerter
Для вызова хранимой процедуры мы будем использовать специальный компонент pFIBStoiedPioc TpFIBStoredPioc, задав свойство StoiedProcName (рис 2.72)
Рис 2.72. Вызов хранимой процедуры при помощи компонента TpFIBStoredPioc
Компонент TpFIBStoredProc является прямым потомком TpFIBQuery и сам формирует свойство SQL в виде ' EXECUTE PROCEDURE ...' Название процедуры задается свойством StoiedProcName
Компонент SffifibEventAlerterl: TSffifibEventAlerterlпредназначен для получения приложением событий InterBase Компонент ссылается на конкретное подключение к базе данных, т.е. на компонент типа TpFIBDatabase (рис 2.73)
Рис 2.73. Свойства SIBfibEventAlerterl
Установим свойство AutoRegister в False, чтобы собственноручно зарегистрировать нужные нам события, а в свойстве Events перечислим те события, которые нас интересуют (рис. 2.74).
Рис 2.74. Список зарегистрированных событий
Чтобы компонент SIBfibEventAlerterl "получал" события, мы должны зарегистрировать их после подключения к базе данных. Для этого напишем обработчик события OnConnect у компонента pFIBDatabasel:
procedure TForml.pFIBDatabaselConnect(Sender: TObject);
begin
if not SIBfibEventAlerterl.Registered then
SIBfibEventAlerterl.RegisterEvents;
end;
Соответственно перед закрытием подключения желательно "отключить" SIBfibEventAlerterl. Для этого создадим обработчик события BeforeDisconnect компонента pFIBDatabasel:
procedure TForml.pFIBDatabaselBeforeDisconnect(Sender:
TObject);
begin
if SIBfibEventAlerterl.Registered then
SIBfibEventAlerterl.UnRegisterEvents;
end;
Зададим свойство Tag у кнопок равным соответственно 1, 2 и 3, и напишем общий обработчик события OnClick для них:
procedure TForml.ButtonsClick(Sender: TObject);
begin
if not pFIBTransactionl.InTransaction then
pFIBTransactionl.StartTransaction;
pFIBStoredProcl.Params[0].Aslnteger := TButton(Sender).Tag;
try
pFIBStoredProcl.ExecProc;
pFIBTransactionl.Commit;
except
pFIBTransactionl.Rollback;
end;
end;
Смысл кода очевиден - мы задаем значение параметра процедуры, используя свойство Tag у кнопки, на которую нажал пользователь, выполняем процедуру при помощи метода ExecProc и либо подтверждаем транзакцию, либо отменяем ее в случае ошибки. Нам остается только написать обработчик события OnEventAlert компонента SIBfibEventAlerterl:
procedure TForml . SIBf ibEvent Alerter 1 Event Alert (Sender : TObject ;
EventName: String, EventCount: Integer);
begin
ShowMessage(EventName + ' : ' + IntToStr(EventCount));
end;
Параметр EventName возвращает название произошедшего события, a EventCount возвращает количество событий EventName. Значение параметра EventCount требует некоторых разъяснений. Итак, при работе с событиями важно помнить, что реально они вызываются только в случае подтверждения транзакции. Иными словами, если вы вызываете некоторое событие 'NEW_CUSTOMER' при вставке записей в таблицу, и вызываете Commit только после вставки 1000 записей, то обработчик OnEventAlert будет вызван только один раз, сразу после Commit, и значение параметра EventCount будет равно 1000. Очевидно, что событие произошло 1000 раз, но приложение получает нотификацию обо всех событиях только после подтверждения транзакции, в контексте которой они происходили.
Мы можем запустить наше приложение. При нажатии на любую из кнопок мы будем получать сообщение о произошедшем событии, причем, как уже было сказано, если наше приложение запущено несколько раз и даже на разных компьютерах, все копии приложения будут получать нотификацию о событиях.
"Низкоуровневая" работа с внутренним буфером TpFIBDataSet
TpFIBDataSet включает несколько специальных методов для работы с внутренним буфером, в котором хранятся записи. В общем-то, данные методы превращают TpFIBDataSet в аналог TClientDataSet, ориентированный на InterBase. Наиболее интересным примером использования данных методов будет, пожалуй, построение диалога выбора, состоящего из двух списков (рис. 2.75).
Рис 2.75. Использование локального кеша TpFIBDataSet для организации двойного списка выбора
В данном примере мы будем использовать базу данных EMPLOYEE.GDB, входящую в стандартную поставку InterBase и FIBPlus. Покажем запросы для SourceDS:
SelectSQL:
SELECT
CUS.CUST_NO,
CUS.CUSTOMER
FROM
CUSTOMER CUS
ORDER BY CUS.CUSTOMER
UpdateSQL:
UPDATE CUSTOMER SET
CUSTOMER = ?CUSTOMER
WHERE
CUST_NO = ?OLD_CUST_NO
InsertSQL:
INSERT INTO CUSTOMER(
CUST_NO,
CUSTOMER
)
VALUES(
?CUST_NO,
?CUSTOMER
)
DeleteSQL:
DELETE FROM CUSTOMER
WHERE
CUST_NO = ?OLD_CUST_NO
RefreshSQL:
SELECT
CUS.CUST_NO,
CUS.CUSTOMER
FROM
CUSTOMER CUS
WHERE
(
CUS.CUST_NO = ?OLD_CUST_NO
)
Те же самые запросы мы будем использовать в TargetDS, поскольку оба компонента должны обладать совместимой структурой полей. Откроем оба запроса сразу после создания формы:
procedure TDualListForm.FormCreate(Sender: TObject);
begin
SourceDS.Open;
TargetDS.CacheOpen;
end;
Если мы не указываем в коде явного открытия базы данных, то это означает, что свойство Connected > компонета TpFlBDatabase было задано в True в design-time.
Обратите внимание на то, что TargetDS мы активируем при помощи специального метода CacheOpen. Этот метод не выполняет запрос из SelectSQL, а только подготавливает внутренний буфер компонента в зависимости от запроса в SelectSQL. Очевидно, что после запуска приложения мы увидим записи в левом списке и пустую таблицу в правом. Теперь мы можем написать процедуру, которая позволит переносить записи из одного списка в другой:
procedure TDualListForm.MoveRec(Select: Boolean);
begin
if Select then begin
if (SourceDS.Active) and (not SourceDS.IsEmpty) then begin
TargetDS.CacheRefreshByArrMap(SourceDS, frklnsert,
['CUST_NO'], ['CUST_NO']);
SourceDS.CacheDelete;
end;
end
else begin
if (TargetDS.Active) and (not TargetDS.IsEmpty) then begin
SourceDS.CacheRefresh(TargetDS, frklnsert, nil);
TargetDS.CacheDelete;
end;
end;
end;
Если параметр Select равен True, то мы будем переносить текущую запись из левого списка в правый, т. е. из SourceDS в TargetDS. Рассмотрим подробнее метод CacheRefreshByArrMap.
procedure CacheRefreshByArrMap(FromDataSet: TDataSet; Kind:
TCachRefreshKind; const SourceFields, DestFields: array of
String);
Метод позволяет вставлять или модифицировать текущую запись в локальный буфер компонента, т. е. без выполнения соответствующих модифицирующих запросов. Параметр FromDataSet указывает, из какого TpFIBDataSet мы хотим получить запись. Параметр Kind может принимать два значения: frkEdit или frklnsert. Frklnsert указывает, что мы хотим вставить новую запись, a frkEdit - что мы хотим изменить существующую. Параметр SourceFields описывает список полей из компонента источника, а список DestFields - список полей в TpFIBDataSet-приемнике. Формально названия полей в списках могут не совпадать, но необходимо, чтобы совпадали типы данных, иначе обмен данными будет невозможен. В нашем примере, как вы можете видеть, мы вставляем в TargetDS текущую запись из SourceDS. Данный метод использован здесь только для демонстрации, поскольку мы вполне могли бы обойтись методом CacheRefresh, который копирует соответствующие поля автоматически. После вставки записи необходимо удалить ее из компонента источника. Это делается при помощи метода CacheDelete, который также не выполняет соответствующий запрос (DeleteSQL), а удаляет запись только из локального буфера в памяти. Теперь, когда мы знаем, что делают процедуры CacheRefreshByArrMap, CacheRefresh и CacheDelete, код процедуры достаточно очевиден: мы копируем запись из компонента-источника в компонент-приемник и удаляем ее из компонента-источника.
То же самое можно сделать в цикле, если мы хотим перенести все записи сразу:
procedure TDualListForm.MoveAll(Select: Boolean);
var TmpDataSet: TpFIBDataSet;
begin
if Select then TmpDataSet := SourceDS else
TmpDataSet := TargetDS;
with TmpDataSet do begin
try
DisableControls;
First;
while not Eof do MoveRec(Select);
finally
EnableControls;
end;
end;
end;
Остается написать обработчики события OnClick для кнопок:
procedure TDualListForm.ButtonlClick(Sender: TObject);
begin
MoveRec(True); // SourceDS -> TargetDS
end;
procedure TDualListForm.Button2Click(Sender: TObject);
begin
MoveRec(False); // TargetDS -> SourceDS
end;
procedure TDualListForm.Button3Click(Sender: TObnect);
begin
MoveAll(True), // SourceDS -> TargetDS
end;
procedure TDualListForm. Button4Click (Sender : TObject) ;
begin
MoveAll(False); // TargetDS -> SourceDS
end;
Мы можем запустить наше приложение (рис 2.76)
Если мы будем нажимать на кнопку Button 1, то записи будут переноситься из левого списка в правый (рис. 2 77).
Все операции осуществляются только с данными внутри локальных буферов, не затражвают сервер и реальные данные в базе Наряду с описанными выше методами вы также можете использовать.
OpenAsCIone - открыть DataSet и скопировать данные из другого DataSet
CacheAppend - добавить запись в конец локального буфера.
SwapRecords - обменять записи в локальном буфере.
CacheEdit - задать значения полей у записи в локальном буфере.
Cachelnsert - вставить запись в локальный буфер
CacheModify - общий метод для вставки и изменения записи в локальным буфере
LoadFromFile - заполнить локальный буфер записями из файла.
LoadFromStream - заполнить локальный буфер записями из потока.
SaveToFile - сохранить локальный буфер в файл.
SaveToStream - сохранить локальный буфер в потоке
Функции работы с локальным буфером предоставляют разработчику чрезвычайно гибкое средство манипуляции данными в клиентских приложениях, позволяя улучшать наглядность пользовательского интерфейса без выполнения дополнительных запросов к базе данных
Рис 2.76. Внешний вид запущенного приложения
Рис 2.77. Внешний вид приложения при выборе пользователем трех записей
Разработка клиентских приложений СУБД InterBase с использованием технологии Microsoft OLE DB
Немного истории
Одним из распространенных заблуждений разработчиков баз данных является мысль, что СУБД InterBase ориентирована исключительно на работу с продуктами компании Borland. И этому способствовало то, что до последнего времени все качественные библиотеки доступа к этому серверу баз данных существовали только для создания приложений на Delphi, C++ Builder или Kylix. Для остальных систем программирования приходилось использовать InterBase API или ODBC. И хотя первое позволяет создавать высокопроизводительные приложения, а второе обладает значительными претензиями на универсальность, оба подхода не в полной мере удовлетворяют требованиям современных программных систем, базирующихся на компонентных технологиях. Поэтому потребность в использовании компонентов доступа к InterBase, универсальных с точки зрения языка программирования, была. И вопрос их реализации заключался только в одном: что именно должны предоставлять эти компоненты и кто решится начать их разработку.
Ответ на первый вопрос дают принципы современной организации масштабируемой архитектуры программного обеспечения, подразумевающие использование компонентов и их группировку в раздельно компилируемые модули. Поэтому компоненты доступа должны обеспечить прозрачную интеграцию компонентов в пределах как одного модуля, так и нескольких. И технология Component Object Model (COM) позволяет без проблем применять эти принципы на практике. Но полноценное использование этой технологии для создания крупных проектов с использованием InterBase осложнялось отсутствием готовой стандартизованной реализации СОМ-объектов доступа к этой СУБД. В результате разработчики программного обеспечения под InterBase вынуждены либо продолжав создавать монолитные приложения, либо самостоятельно решать проблемы совместного использования ресурсов СУБД малосвязанными между собой модулями программы. В первом случае осознанное ограничение возможностей программы экономит время. Во втором, опуская дополнительные трудозатраты на создание компонентов доступа, можно попасть в ловушку, которая в лучшем случае не позволяет сменить сервер базы данных, в худшем приводит к краху всего проекта. Как правило, разработчики это осознают, когда поздно что-либо менять.
Тем не менее попытки создания СОМ-объектов для доступа к InterBase были Наиболее успешной попыткой можно считать библиотеку Visual Database Tools от компании Borland (VDBT). Это VCL-подобные компоненты для Visual Basic, работающие с InterBase через Borland Database Engine. Но библиотека VDBT была готовой реализацией СОМ-объектов доступа к InterBase, а не открытой спецификацией. Поэтому расширению и усовершенствованию не подлежала.
Спецификацию под названием OLE Database (OLE DB), предназначенную для создания компонентов доступа к базам данных, выпустила компания Microsoft, которая курирует и саму СОМ-технологию. Но Open Source InterBase 6 не имел собственного OLE DB-провайдера, поэтому ничего не оставалось, как начать самостоятельную разработку OLE DB for InterBase, известную ныне как IBProvider.
Обзор возможностей IBProvider
* Возможность работы со всей линейкой СУБД InterBase, начиная с версии 4 х и заканчивая клонами InieiBase 6 - Firebird и Yattil Минимальным условием работы IBProvider является наличие на компьютере клиента динамической библиотеки GDS32.dll от InterBase 4 (см. главу "Состав модулей InterBase" (ч. 4)). IBProvider самостоятельно определяет уровень возможностей сервера (так называемый base level) и клиентской части (т е. возможности GDS32.dll). а также диалект базы данных и автоматически подстраивается под эти параметры.
* Поддержка всех типов данных InterBase. Есть поддержка BLOB-полей (бинарных и текстовых), массивов и типов DECIMAL/NUMERIC (см. главу " Типы данных" (ч. 1)).
* Поддержка storage-объектов для работы с BLOB-полями. Эти объекты могут возвращаться клиенту и приниматься в качестве входящих параметров.
* Практически весь спектр OLE DB-типов. Помимо типов, непосредственно поддерживаемых InterBase, IBProvider способен принимать и возвращать беззнаковые целые числа, булевы значения, строки UNICODE и т. д.
* Встроенная поддержка конвертирования данных из одного типа в другой, преобразования массивов, бинарного и текстового представления BLOB-полей. Для преобразования типа данных NUMERIC используется библиотека для работы с большими целыми числами, что обеспечивает естественную поддержку 64-битовых целых.
* Поддержка многопоточной работы. Компоненты провайдера самостоятельно обеспечивают синхронизацию доступа к своим ресурсам, поэтому клиент может не беспокоиться о проблемах параллельной работы с одним подключением к базе данных из нескольких потоков одного приложения.
* Отказоустойчивость. Для компонентов, работающих в составе серверных приложений, исключительно важна надежность. При разработке провайдера повсеместно используются мощные возможности языка Си++ для автоматического освобождения ресурсов и обработки исключительных ситуаций.
* Оптимизация работы с результирующим множеством SQL-запросов. В зависимости от требований клиента используется механизм либо однонаправленного доступа к выборке, либо произвольного. Для поддержки обработки большого количества данных автоматически применяются временные файлы, причем для доступа к ним используется 64-битовая адресация
* Тридцатидвухбитовый кеш выбранных строк результирующего множества. Применение динамической системы приоритетов позволяет удерживать в заданном объеме памяти только наиболее часто используемые строки, а хеш- таблица обеспечивает эффективную навигацию по содержимому кеша. Таким образом, LBProvider способен с одинаковой производительностью обрабатывать как небольшие по размеру результирующие множества, так и очень большие, даже превышающие объем доступной оперативной памяти.
* Оптимизация работы с оперативной памятью. Во-первых, IBProvider использует две собственные "кучи" (heap) для динамического выделения памяти. Это снижает нагрузку на системную кучу. Во-вторых, IBProvider интенсивно запускает совместно используемые объекты, хранящие информацию только для чтения. Во время работы IBProvider создает глобальный пул (pool) объектов, что приводит к экономии памяти и позволяет уменьшить время создания и инициализации объектов и, таким образом, улучшить общую производительность приложения баз данных.
* Полная поддержка синтаксиса SQL. Также поддерживаются команды для создания/удаления базы данных и явного управления транзакциями.
* Работа с базой данных в режиме автоматического запуск и подтверждения транзакций (autocommit). По умолчанию этот режим выключен, так как он не является оптимальным для работы с InterBase, но при необходимости его можно включить.
* Полная поддержка параметризованных запросов. Можно использовать именованные и неименованные параметры, самостоятельно или автоматически формировать описания параметров и передавать их значения в обоих направлениях (in-out-параметры).
* Поддержка вызова хранимых процедур (сокращенно - ХП; подробнее о них см главу "Хранимые процедуры" (ч. 1)). Провайдер распознает запросы вида "ехес proc_name", "execute proc_name", "execute procedure proc_name" и возвращает результат работы хранимой процедуры через выходные (out) параметры.
Возможность получения метаданных из базы данных InterBase. Это списки таблиц, колонок, хранимых процедур, индексов, ограничений и т. д. (всего 26 видов метаданных). Помимо CASE-средств и систем построения отчетов, эта информация использ>ется в Microsoft Distributed Query для выполнения гетерогенных запросов к нескольким базам данных под управлением различных (!) SQL-серверов (например, MS SQL) посредством OLE DB-провайдеров.
* Тщательное следование парадигмам объектно-ориентированного проектирования, а также двухлетнее тестирование в реальных системах СУБД гарантируют высокий уровень надежности и стабильности IBProvider, который идеально подходит для использования в составе программного обеспечения с круглосуточным режимом работы.
В настоящий момент, оставив позади большой объем работ по созданию OLE DB для InterBase, можно пересмотреть роль и назначение этого драйвера. Вытеснив оригинальную клиентскую часть GDS32.DLL на второй план, IBProvider предоставляет мощный объектно-ориентированный низкоуровневый клиентский API для работы с InterBase. Встраиваясь в приложения баз данных, OLE DB-провайдер способен взять на себя всю работу по организации взаимодействия с сервером базы данных. Предоставление ресурсов для работы с базой данных в виде СОМ-объектов снимает традиционные ограничения, накладываемые на клиентские приложения баз данных. Приложение можно дробить на модули, которые можно создавать с помощью разных систем программирования. Используя сценарии, написанные на VBScript/JScript, в программы можно добавлять логику, которую невозможно реализовать на уровне базы данных. OLE DB является общепризнанным промышленным стандартом доступа к данным, что позволяет легко разворачивать и управлять приложениями, разработанными с использованием IBProvider.
Таким образом, разработка крупных масштабируемых клиентских приложений для InterBase с помощью средств разработки компании Microsoft, а также любых других систем, поддерживающих OLE DB, становится более реальной и доступной, чем можно было себе представить ранее.
Использование IBProvider в клиентских приложениях
Низкоуровневые прикладные интерфейсы для работы с СУБД (API) обычно не используются в клиентских приложениях из-за большого объема кода, необходимого для подготовки и выполнения SQL-запросов. Это относится и к OLE DB-интерфейсам. Поэтому примеры, демонстрирующие взаимодействие с различными OLE DB-провайдерами непосредственно через их СОМ-интерфейсы, носят исключительно демонстрационный характер и имеют мало общего с реальным программированием приложений баз данных Для решения повседневных задач обычно используют надстройки в виде других СОМ-объектов или библиотек классов, которые существенно упрощают работу с OLE DB. Работать с IBProvider можно двумя основными способами - через стандартные ADODB компоненты и с помощью собственной библиотеки классов для поддержки IBProvider. написанной для компилятора Borland C++ Builder.
Компоненты ADODB
В настоящее время этот набор компонентов стал промышленным стандартом взаимодействия с OLE DB-провайдерами. ADODB (www.microsoft.com/data) - это весьма удобный высокоуровневый интерфейс, реализующий классическую иерархию объектов для работы с базами данных в виде СОМ-объектов, поддерживающих технолог ию OLE Automation.
Реализация OLE DB-интерфейсов большинства провайдеров не является взаимозаменяемой и больше ориентирована на использование из программ, написанных на C++, что приводит к проблемам совместимости и переносимости приложений между различными OLE DB-провайдерами. Поэтому ADODB-компонеты, сглаживающие различия между разными OLE DB-провайдерами и доступные для использования практически везде - начиная от VisualBasic и заканчивая тем же C++, - лучше подходят для использования в качестве универсальной платформонезависимой основы для приложений баз данных.
Но у ADODB-компонентов имеется ряд недостатков, которые являются обратной стороной достоинств:
* Ограничения на типы данных, накладываемые структурой VARIANT.
* Некоторое снижение производительности за счет того, что создание объектов ADODB производится через инфраструктуру СОМ.
* Отсутствие встроенной поддержки использования нескольких независимых транзакций в рамках одного подключения, чем InterBase выгодно отличается от других SQL-серверов базы данных.
* Появляется дополнительный уровень взаимодействия с OLE DB.
Для того, чтобы избежать недостатков ADODB-компонентов, была разработана специализированная библиотека классов C++, которая реализует доступ к OLE DB провайдерам (в том числе и к IBProvider) с максимально возможной эффективностью. Эта библиотека поставляется в составе дистрибутива IBProvider.
Библиотека классов C++ для работы с OLE DB
Созданная как дополнительный слой ("обертка") над СОМ-объектами, эта библиотека классов обеспечивает более тесную интеграцию с OLE DB-провайдерами. В ней нет всего списка возможностей, который предлагает ADODB, но предоставляемый сервис делает ее более приспособленной для построения независимых и эффективных компонентов, работающих с базами данных через OLE DB.
К основным достоинствам данной библиотеки классов относится:
* автоматическое создание и разрушение объектов;
* изоляция классов для работы с базами данных друг от друга, что обеспечивает исключительную модульность и гибкость приложений на основе данной библиотеки;
* возможность подключения объекта C++ к уже существующему OLE DB компоненту;
* удобная работа с наборами полей и параметров, значительно более гибкая по сравнению с компонентами ADODB и VCL;
* возможность выбора способа обработки ошибок - через исключения или через код возврата.
Поскольку данная библиотека доступа создавалась специально для использования в больших проектах, её классы значительно уменьшают сложность взаимодействия с OLE DB-провайдером В случае необходимости использовать ADODB (например, для совместной работы модулей проекта, написанных на C++ и на VBScript, в рамках одной транзакции) в библиотеке реализованы механизмы "шлюзования".
Разумеется, существуют еще несколько других библиотек, упрощающих работу с OLE DB-провайдерами. Однако в нижеследующих примерах будут использоваться только компоненты ADODB и библиотека классов C++ для работы с OLE DB. Поэтому, прежде чем приступить к работе над описанными примерами, убедитесь в наличии всех необходимых программных продуктов. Помните, что вы можете скачать все примеры и нужные для их работы программы на сайте поддержки данной книги www.InterBase-world com.
Инсталляция IBProvider
Перед установкой OLE DB-провайдера убедитесь, что на вашей машине инсталлирована клиентская часть InterBase Для этого на компьютере как минимум, должна находиться GDS32.DLL. Обычно она находится в системном каталоге Windows (System - для 95/98/МЕ, System32 - для NT4/Win2000) Подробнее обустановке клиентской части InterBase см. главу "Установка InterBase - взгляд изнутри" (ч. 4)
В минимальный набор дистрибутива IBProvider входят два модуля: _IBProvider.dll и cw3250mt.dll. Скопируйте оба файла в системный каталог Windows и выполните команду regsvr32 _B3Provider.dll для регистрации провайдера в системе.
Если вы обладаете готовым дистрибутивом IBProvider, то программа инсталляции выполнит все необходимые операции самостоятельно.
Обратите внимание, что при инсталляции провайдера в Windows NT4/Windows 2000 у вас должны быть права на запись в реестр Поэтому операцию регистрации лучше всего выполнять, обладая правами администратора.
После установки провайдера перезагрузка ОС не требуется
Инсталляция ADODB-компонентов
Компоненты ADO входят в состав свободно распространяемого дистрибутива Microsoft Data Access Components и доступны для скачивания на сайте компании Microsoft - www microsoft com/data. Для написания примеров использовались ADODB-компоненты из дистрибутива версии 2.6.
Примеры использования ADODB
Для создания примеров работы с IBProvider через ADODB был применен Visual Basic for Application (VBA) из Microsoft Excel 97. Для использования ADODB-компонентов нужно их добавить в список библиотек, употребляемых Visual Basic Для этого:
* Откройте редактор кода Visual Basic (Alt+Fl 1).
* Выберите пункт меню Сервис\Ссылки.
* Найдите в списке строку Microsoft ActiveX Data Objects 2.6 Library и поставьте рядом с ней галочку.
* Закройте окно, нажав кнопку "ОК".
Использование библиотеки классов
Библиотека классов поставляется в виде исходных текстов. Поэтому для ее использования нужно выполнять следующие требования:
* Явно добавить в проект файлы из каталога Lib:
ole_lib\oledb\oledb_client_lib.cpp Основные классы для работы с OLE DB
ole_lib\oledb\oledb_client_base.cpp
ole_lib\oledb\oledb_common.cpp
ole_lib\oledb\oledb_variant.cpp
ole_lib\oledb\oledb_ado_lib.cpp Утилиты стыковки с ADODB
ole_lib\ole_base.cpp
ole_lib\ole_auto.cpp
Win32Lib\win321ib.cpp
structure\util_classes.cpp
util_func.cpp
* Начало каждого срр-файла, включенного в проект, должно выглядеть следующим образом:
ttinclude <_pch_.h> #pragma hdrstop
* Добавить в параметры проекта (опция Conditional defines) макрос INCLUDE_OLEDB_HEADER.
* При использовании в проекте VCL компонент, нужно добавить в параметры проекта макрос _USE_VCL_. В этом случае файл будет добавлен в проектный csm-файл (файл прекомпилированного заголовка) косвенно из <_pch_ h>.
* Основной каталог include, используемый компилятором C++ Builder, должен содержать заголовочные файлы OLE DB SDK. BCB5 и Free Borland C++ Compiler уже содержат все необходимое. В ВСВЗ нужно добавить эти файлы самостоятельно, используя OLE DB SDK версии не выше 2.1.
Представленная в составе дистрибутива IBProvider библиотека классов является основой для проектов, её использующих. Поэтому предполагается, чго заголовочный файл <_pch_.h> прямо или косвенно включен в каждый срр-файл проекта. Возможность параллельного использования с другими библиотеками осуществляется за счет определения пространств имен. Поддержка библиотеки VCL добавлена изначально. Для поддержки других библиотек потребуется модифицировать <_pch_.h>.
Перенос на другие компиляторы C++ полностью зависит от степени их совместимости с последним стандартом C++ и от сложности перехода на другую реализацию STL.
Примеры использования библиотеки классов
Для написания и тестирования примеров использовался Borland C++ Builder 3-й версии (с установленным пакетом исправлений, который доступен для скачивания на сайте компании Borland). Библиотека классов самостоятельно конфигурируется под использование компилятора и STL из ВСВ5, поэтому примеры переносятся на Borland C++ Builder 5-й версии без проблем.
В примерах, включенных в текст этого раздела, опускаются этап инициализации СОМ и обработка исключений. Все это, естественно, присутствует в оригинале примеров, доступных для скачивания с сайта поддержки этой книги www.lnterBase-world.com.
Также для изучения технологии использования библиотеки классов для работы с OLE DB из C++ рекомендуется посмотреть примеры из дистрибутива IBProvider.
Тестовая база данных
Для тестирования использовался Firebird 1.0 и база данных employee.gdb, входящая в дистрибутив этого сервера баз данных. На этом сервере был создан пользователь "gamer" с паролем "vermin"
Для сокращения объема кода, проводящего подключение к базе данных, использовался текстовый файл employee.ibp, содержащий следующую информацию:
data source=c266:d:\database\employee.gdb;
user=gamer;
password=vermut;
auto_cornmit = true ;
ctype=win!251;
Операционная система
Все перечисленные компоненты для написания примеров были установлены на одном компьютере, работающем под управлением Windows NT4 Service Pack 5, Internet Explorer 5.
Состав компонентов IBProvider
Давайте рассмотрим составные части IBProvider. Компоненты, входящие в состав OLE DB-провайдера, делятся на 4 основные группы:
Источник Оанны\ (Data Source). Компоненты этой группы отвечают за инициализацию и управление подключением к базе данных. Здесь же предоставляется интерфейс для создания сессии.
Сессия (Session). Компонент управления транзакцией. У одного источника данных может быть несколько сессий. Кроме управления транзакциями, сессия обеспечивает создание команд, открытие таблиц и получение информации о метаданных базы данных.
Команда (Command). Компонент для подготовки и выполнения SQL-запросов к базе данных Команда выполняется в рамках конкретной сессии, однако в случае работы в режиме автоматического запуска и подтверждения транзакций (autocommit) выполняется в рамках собственной транзакции. Внутри одной сессии может существовать множество команд.
Набор строк (Ronset). Компонент, реализующий интерфейсы навигации по результатам SQL-запроса (результирующему множеству) и доступа к его содержимому.
Для описания взаимодействующих сторон, будет использоваться следующая терминология:
Клиент - это любой фрагмент системного или прикладного кода, использующий интерфейс OLE DB. Сюда могут входить и сами компоненты доступа. Так же, для обозначения этой стороны взаимодействия, будут использоваться термины пользователь и потребитель. Компонентов доступа - это любой программный компонент, предоставляющий интерфейс OLE DB. Параллельно будут использоваться OLE DB- поставщик, OLE DB-провайдер, провайдер и IBProvider. Настройка и определение функциональности компонентов осуществляется через их свойства. Свойства - это атрибуты объекта. Например, свойства набора строк определяют верхний предел объема оперативной памяти для хранения данных, поддержку закладок и потоковую модель. Клиенты устанавливают значения свойств, чтобы потребовать от соответствующего объекта некоторого заданного поведения, и читают свойства, чтобы определить возможности объекта Каждое свойство характеризуется значением, типом, описанием, атрибутом чтения/записи
Свойство идентифицируется GUID (глобальный уникальный идентификатор, представляющий собой структуру длиной 128 бит) и целым числом, представляющим идентификатор свойства. Набор свойств - это совокупность свойств с одним и тем же GUID.
Источник данных
Создание компонента Data Source является отправной точкой для работы с базой данных через IBProvider. Существует несколько сценариев создания и инициализации компонента доступа. Они отличаются объемом работы, выполняемой в клиентском приложении, библиотекой доступа к OLE DB и самим IBProvider.
Вариант 1. Клиент самостоятельно осуществляет все этапы:
ADODB
Dim en As New ADODB.Connection
cn.Provider = "LCPI.IBProvider.1"
cn.Properties("data source") =
"localhost:d:\database\employee.gdb"
en.Properties("user id") = "gamer"
en.Properties("password") = "vermut"
cn.Open
C++
t_db_data_source cn;
_THROW_OLEDB_FAILED(cn,create("LCPI.IBProvider.1"))
t_db_ob]_props cn_props(/*refresh=*/false);
_THROW_OLEDB_FAILED(cn_props,attach_data_source(en.m_obj, DBPROPSET_DBINITALL))
_THROW_OLEDB_FAILED(cn_props,set("data source" "iocalhost:d:\\database\\employee. gdo")) ;
_THROW_OLEDB_FAILED(cn_props,set("user id","gamer"));
_THROW_OLEDB_FAILED(cn_props,set("password","vermut"));
_THROW_OLEDB_FAILED(en,attach(""));
Вариант 2. Создание и инициализацию выполняет клиентская библиотека:
ADODB
Dim en As New ADODB.Connection
Call en.Open("provider=LCPI.IBProvider.1; data
source=Iocalhost:d:\database\employee.gdb", "gamer", "vermut")
C++
t_db_data_source cn;
_THROW_OLEDB_FAILED(en,attach("provider=LCPI.IBProvider.1;"
"data source=localhost:d:\\database\\employee.gdb;"
"user id=gamer;password=vermut"));
Вариант 3. Провайдер создает клиентская библиотека, инициализацию выполняет сам провайдер:
ADODB
Dim en As New ADODB.Connection
Call en.Open("file name=d:\database\employee.ibp")
C++
t_do_data_source cn;
_THROW_OLEDB_FAILED(cn,
attach!"file name=d:\\database\\employee.ibp"));
//или явно указываем провайдер и файл с параметрами
_THROW_OLEDB_FAILED(en,
attach("provider=LCPI.IBProvider.1;"
"file name=d:\\database\\employee.ibp"));
где "employee.ibp" - обычный текстовый файл, в котором хранится строка подключения вида
data souгсе=Iocalhost:d:\\database\\employee.gdb;
user id=gamer;
password=vermut
Пока OLE DB-провайдер не подключен к базе данных, параметры инициализации будут единственно доступным набором свойств. В IBProvider определены стандартные свойства инициализации и собственные, предназначенные для специанализированной настройки дальнейшей работы с базой данных. (За подробностями обращайтесь к документации по IBProvider.)
После успешного подключения к базе данных становятся доступными свойства информационного набора, с помощью которых компонент источника данных предоставляет сведения о сервере базы данных. Часть этих свойств стандартизовано спецификацией OLE DB. Остальные свойства предоставляют информацию, специфичную для IBProvider, содержащую расширенные сведения о сервере и базе данных.
Пример получения значений информационных свойств:
ADODB
'подключение к базе данных
....
'стандартные свойства
Debug.Print en.Properties("provider version")
Debug.Print en.Properties("provider friendly name")
'специфические свойства
Debug.Print en.Properties("IB Base Level")
Debug.Print en.Properties("IB GDS32 Version")
Debug.Print en Properties("IB Version")
C++
//Подключение к базе данных
//...
t_db_obj_props cn_props(false);
_THROW_OLEDB_FAILED(cn_props,
attach_data_source(cn.m_obi, DBPROPSET_DATASOURCEINFOALL));
..печать всех информационных свойств
for(UINT i = 0; i! =cn_props .GetltemsInContainer () ;+ + i)
{
cout<
;
}
Компонент Data Source имеет еще несколько возможностей: например, сохранение параметров подключения к базе данных в файле и перечисление до- пус!имы\ символов для названий объектов базы данных. Однако в основном он используется для создания объектов сессий.
Сессия
Основная функция сессии - установить рамки транзакции с заданными параметрами (подробнее о транзакциях см. главу "Транзакции. Параметры транзакций" (ч 1))
Хотя в ADODB понятие сессии совмещено с понятием источника данных, в OLE DB это два различных объекта. Надо полагать, что основная причина такой иерархии объектов ADODB заключается в архитектуре пула подключений, используемого в серверных приложениях Microsoft. Гораздо проще и эффективнее осуществлять балансировку загрузки на уровне отдельных подключений к базе данных, чем на уровне сессий. Как правило, в SQL-серверах через два раздельных подключения можно осуществлять параллельные запросы к базе данных, а через разные сессии одного подключения такая работа будет осуществляться последовательно. Тем не менее InterBase может одновременно обслуживать несколько транзакций в рамках одного подключения и в данном случае выгодно отличается от большинства других SQL-серверов. Поэтому IBProvider поддерживает возможность создания нескольких объектов сессий, принадлежащих одному источнику данных.
Уровни изоляции транзакции
В IBProvider реализована поддержка трех уровней изоляции транзакций: READ COMMITTED, REPEATABLE READ (SNAPSHOT), SERIALIZABLE (SNAPSHOT TABLE STABILITY). При работе через ADODB след>ет обратить внимание на значение свойства ADODB.Connection.IsolationLevel. Библиотека классов C++ по умолчанию использует режим REPEATABLE READ. Подробнее об у ровнях изоляции транзакций вы можете узнать в главе "Транзакции. Параметры транзакций" (ч. 1).
Управление транзакциями
Поскольку корректное использование транзакций является важным условием разработки эффективных приложений баз данных, то IBProvider по умолчанию требует явного участия пользователя в процессе управления транзакциями.
Причинами отказа от автоматического запуска и завершения транзакции являются относительно высокие затраты ресурсов на эту операцию и желание контролировать все действия с базой данных.
Надо сказать, что последнее обстоятельство является наиболее важным, поскольку при разработке большой программной системы, состоящей и множества независимых модулей, явный контроль операций с базой данных позволяет избегать многих ошибок.
В то же время иногда автоматический запуски завершение транзакции могут оказаться очень удобными для решения небольших и несложных задач.
Помимо автоматических транзакций для работы с данными в IBProvider определена еще одна категория внутренних транзакций (inner transaction), используемых для чтения метаданных базы данных По умолчанию внутренних транзакций разрешены, поскольку CASE-дизайнеры и системы построения отчетов для получения метаданных явно не управляют транзакциями.
Автоматические транзакции
Для разрешения провайдеру самостоятельно управлять транзакциями нужно указать в строке инициализации параметр "auto_commit=true":
Call сn.Open(
"data source=localhost:d:\database\employee.gdb;auto_commit=true",
"gamer", "vermut")
В этом случае все создаваемые объекты сессий для данного источника данных будут способны самостоятельно запускаться и завершать транзакции без явного участия пользователя. Для выборочного разрешения такого режима можно воспользоваться свойством сессии "Session AutoCommit". Если это свойство равно true, то сессия может обслуживать запросы к базе данных без необходимости явного запуска и подтверждения.
По умолчанию автоматические транзакции используют уровень изоляции SNAPSHOT. Если требуется установить другой уровень изоляции, то нужно либо установить параметр инициализации источника данных "auto_commit_level", либо изменить свойство сессии "Autocommit Isolation Levels" в одно из следующих значений:
* 0 х 1000 - READ COMMITED;
* 0 x 10000 - REPEAT ABLE READ. Это режим по умолчанию;
* 0 x 100000 - SERIALIZABLE.
О принципе функционирования автоматических транзакций следует сказать следующее. Автоматическая транзакция не управляется через интерфейс сессии. За её завершение и откат отвечает команда или набор строк внутри этой сессии. Если команда не возвращает набор строк (rowset), то транзакция фиксируется сразу. Если внутри автоматической транзакции появляется набор строк, то транзакция завершается при освобождении этого набора То есть внутри одной сессии. у которой свойство "Session AutoCommit" равно true, может существовать несколько активных транзакций. Естественно, что в этом случае пользователь также может явно управлять запуском и завершением транзакции, принадлежащей сессии. В случае явного запуска транзакции, для дальнейших запросов и операций в рамках этой сессии будет использоваться контекст именно этой транзакции.
Несмотря на то, что ffiProvider старается выполнить как можно больше операций в рамках одной автоматической транзакции, все равно производительность приложения, не осуществляющего самостоятельного контроля над транзакциями, не может сравниться с приложениями, явно управляющими транзакциями.
Управление транзакциями через SQL
Помимо управления транзакцией через OLE DB-интерфейсы сессии, IBProvider осуществляет специальную поддержку SQL-запросов вида: "SET TRANSACTION...", "COMMIT" и "ROLLBACK". В этом случае будет использоваться транзакция, принадлежащая сессии. Управление транзакциями через SQL-запросы позволяет указывать специфические параметры контекста транзакции, которые не стандартизированы в OLE DB и которые возможно использовать благодаря особенностям InterBase API.
Примеры работы с транзакциями
Ниже приведены примеры, демонстрирующие способы запуска и завершения транзакций, поддерживаемые OLE DB-провайдером.
ADODB:
явное управление транзакцией:
Dim en As New ADODB.Connection
сn.Provider = "LCPI.IBProvider.1"
Call en.Open(
"data source=localhost:d:\database\employee.gdb",
"gamer","vermut")
'стандартный способ
сn IsolationLevel = adXactRepeatableRead
сn.BeginTrans
'...
'можно указать использование commit retaining
'cn.Attributes = adXactAbortRetaining + adXactCommitRetaining
cn.CoimutTrans
'управление транзакцией через SQL (можно использовать специфику
InterBase)
Dim cmd As New ADODB.Command
cmd.ActiveConnection = en
cmd.CommandText = "set transaction"
cmd.Execute
'...
cmd CommandText = "rollback"
cmd Execute
автоматический запуск транзакций - разрешение и запрещение:
Dim en As New ADODB.Connection
en Provider = "LCPI.IBProvider.1"
'auco_commit=true включение автоматических транзакций
'для всех сессий
Call cn.Open(
"data source=localhost:d:\database\employee.gdb;auto_commit=true",
"gamer", "vermut")
Dim cmd As New ADODB.Command
Dim rs As ADODB Recordset
cmd ActiveConnection = cn
cmd.CommandText = "select * from rdb$database"
Sec rs = cmd.Execute 'транзакция запускается неявно
'...
'и Судет завершена при закрытии результирующего множества
rs Close
'альтернативой auto_commit=true является установка
'(после успешного подключения к база данных)
'свойства сессии Session AutoCommit=true.
'В ADODB это одно и то же,
'поскольку на одно подключение - одна сессия
'через это же свойство можно "выключить" глобальное
'разрешение на автоматический
'запуск транзакции, что дальше и демонстрируется
cn Properties("Session AutoCommit") = False
cmd.CommandText = "select * from rdb$database"
Set rs = cmd Execute
'выдаст олибку "Automatic transaction is disabled"
При программировании на C++ принципы взаимодействия с сессией точно такие же. Но в C++ сессия будет отдельным объектом.
В нижеследующем примере на C++ демонстрируется трюк, который часто используется для моделирования принудительного завершения транзакций. Дело в том, что InterBase реализует многоверсионную архитектуру данных (подробнее о многоверсионности данных см. главу "Транзакции Параметры транзакций" (ч 1)) Одной из особенностей такой архитектуры является то, что любые транзакции желательно завершать подтверждением (commit), а не откатом (lollback).
Однако, как правило, транзакцию, в рамках которой выполняется операция чтения данных, не подтверждают, а откатывают. Особенно в случае достаточно длинного участка кода, который генерирует исключения в случае непредвиденных ошибок загрузки информации Поэтому и нужно принудительно завершать транзакции так. как это показано в нижеследующем примере.
try
{
t_db_data_source cn;
_THROto_OLEDB_FAILED(en,attacn("provider=LCPI.IBProvxCter.1,"
"data source=localhost:d:\\database\\employee.gdb;"
"user id=gamer;"
"password=vermut"));
t_db_session session;
// метод create перегружен для разных типов аргумента, поэтому
// можно передавать
// как C++ объект (t_db_data_source), так и IUnknown источника
// данных
_THROW_OLEDB_FAILED(session,create(en)) ,
// запуск транзакции
_THROW_OLEDB_FAILED(session,start_transaction() ) ;
// создаем объект для принудительного завершения транзакции
t_auto_mem_fun_l
_auto_commit_(session, /*commit_retaining=*/false, &t_db_session::commit);
//... теперь, что бы ни произошло, транзакция
// будет "закоммичена"
throw runtime_error("This is my test error");
}
catcn(const exception& exc)
{
cout<< "error:"<
}
По умолчанию библиотека не генерирует исключений, поэтому даже если сбой произошел из-за проблем с самой базой данных, то принудительное завершение транзакции, выполняемое в деструкторе _auto_commit_, не возбудит исключения.
Распределенные транзакции
Еще одним способом инициирования транзакции является подключение сессии к координатору распределенных транзакций. В общих чертах, координатор представляет собой сессию, транслирующую вызовы собственных интерфейсов управления транзакциией в идентичные групповые вызовы интерфейсов списка дочерних сессий. Как правило, от пользователя не требуется никакого участия для подключения к координатору. За это отвечает окружение, у которого пользовательский код запрашивает подключение к базе данных.
На практике распределенные транзакции обычно используются в СОМ+ (MTS) и Microsoft Distributed Query. В первом случае существует следующая особенность. Когда компоненты просят у своего окружения предоставить им подключение к базе данных, то на каждый такой запрос создается отдельная пара источник данных - сессия. Связано это с описанным выше принципом работы пула подключений. Если компонентов, обрабатывающих пользовательский запрос, очень много и они работают с одной и той же базой данных с идентичными параметрами подключения, то имеет смысл один раз получить подключение и потом предоставлять его компонентам. Иначе в распределенной транзакции будет использовано множество сессий, каждая из которых соответствует процессу или потоку на сервере базы данных, что может привести к резкому снижению производительности сервера СУБД.
Использование нескольких сессий в ADODB
Несмотря на то что модель объектов ADODB не предоставляет прямой возможности одновременного использования нескольких сессий с одним источником данных, это ограничение можно обойти. Решение основывается на применение внутреннего интерфейса ADOConnectionConstruction компоненты ADODB.Connection.
void clone_adodb_connection(IDispatch* pCurrentConnection,
IDispatchPtr& spNewConnection)//throw
{
//объявляем типы смарт-указателей для интерфейсов
//конструирования ADODB-подключения
DECLARE_IPTR_TYPE(ADOConnectionConstruction);
DECLARE_IPTR_TYPE(ADOConnectionConstructionl5);
//1 получаем источник данных, привязанный к pCurrentConnection
ADOConnectionConstructionPtr
spConstruct(pCurrentConnection);
ADOConnectionConstruetionl5Ptr
spConstructlS(pCurrentConnection);
if(!spConstruct && !spConstruct15)
t_ole_error::throw_error("Объект - не ADODB.Connection",
E_INVALIDARG);
IUnknownPtr spDataSource;
//берем указатель на OLE DB-источник данных
if((bool)spConstruct15)
spConstruct15->get_DSO(&spDataSource.ref_ptr());
if(!spDataSource && (bool)spConstruct)
spConstruct->get_DSO(&spDataSource.ref_ptr());
if(!spDataSource)
t_ole_error::throw_error(
"ADODB.Connection не инициализирован",E_FAIL);
//2 создаем новую сессию для spDataSource ------------------
IUnknownPtr spNewSession;
IDBCreateSessionPtr spDBCreateSession(spDataSource);
assert((bool) spDBCreateSession);
if(FAILED(spDBCreateSession->CreateSession
(NULL,IID_IUnknown,kspNewSession.ref_ptr())))
{
t_ole_error::throw_error(
"Ошибка создания новой сессии",E_FAIL);
}
assert((bool)spNewSession);
//3 создаем новый экземпляр ADODB.Connection ----------------
IUnknownPtr spUnkNewConnection;
HRESULT hr=SafeCreateInstance("ADODB.Connection",
NULL,CLSCTX_INPROC,IID_IUnknown,
(void**)&spUnkNewConnection.ref_ptr());
if(FAILED(hr))
t_ole_error::throw_error(
"Ошибка создания \"ADODB.Connection\"",hr);
spConstruet = spUnkNewConnection;
spConstruct15=spUnkNewConnection;
if(!spConstructlS && !spConstruct)
throw t_ole_error(
"Ошибка подключения к \"ADODB.Connection\"",E_FAIL);
spDataSource->AddRef(); //ADO не вызывает для них AddRef spNewSession->AddRef();
//при конструировании ADODB.Connection
//пытается установить свои свойства,
//в результате чего, если IBProvider уже подключен
//к базе данных, может произойти ошибка
//тем не менее подключение уже сконструировано
//и вполне работоспособно.
if((bool)spConstructlS) //IID_Connect-on15
{
spConstruct15->WrapDSOandSession(spDataSource,spNewSession);
hr = spUnkNewConnection ->
Querylnterface(IID_ConnectionlS,spNewConnection);
}
else //IID_Connection
{
spConstruct->WrapDSOandSession(spDataSource,spNewSession);
hr = spUnkNewConnection ->
Querylnterface(IID_Connection,spNewConnection);
}
if (FAILED(hr))
t_ole_error::throw_error(
"Ошибка получения IDispatch из ADODB.Connection",hr);
assert((bool)spNewConnection);
//всё — spNewConnection подключен к тому же
//источнику данных, но обладает
//собственной сессией.
}//cione_adodb_connection
Чтение метаданных
Помимо управления транзакциями, сессия предоставляет еще одну полезную возможность - получение метаданных для базы данных (о метаданных см. главу "Структура базы данных InterBase" (ч. 4)). Поскольку в некоторых системах, например в Microsoft Distributed Query, операция получения метаданных выполняется очень часто, то IBProvider хранит информацию о них в оперативной памяти (т. е. кеширует). Кэширование метаданных можно настраивать для обеспечения оптимального быстродействия. Определить режим кеширования можно через свойство инициализации источника данных "schema_cache" и свойство сессии - "Session Schema Cache". Этим свойствам можно присваивать следующие значения:
* Кэширование запрещено. Данные будут всегда перечитываться.
* Глобальное кеширование на уровне Data Source. Это режим по умолчанию.
* Кеширование на уровне Session.
Если при запросе метаданных сессия содержит явно запущенную транзакцию, то провайдер не будет использовать дополнительную внутреннюю транзакцию для получения данных, а воспользуется уже существующей. Если явно запущенной транзакции нет, то IBProvider автоматически запустит внутреннюю транзакцию с уровнем изоляции, указанной в свойстве сессии "Autocommit Isolation Levels". Для запрещения автоматического запуска провайдером внутренних транзакций для извлечения метаданные необходимо определить в строке инициализации источника данных "inner_trans=false" или установить свойство сессии "Session InnerTrans=false".
Получение и вывод списка таблиц базы данных:
ADODB
Dim cn As New ADODB.Connection
Call cn.Open("file name=d:\database\employee.ibp")
Dim rs As ADODB.Recordset
Set rs = cn.OpenSchema(adSchemaTables)
Cells.Clear
Dim col As Long, row As Long
row = 1
'печать названия колоник
For col = 0 To rs.Fields.Count - 1
Cells(row, col + 1) = rs(col).Name
Next col
'печать содержимого
While Not rs.EOF
row = row + 1
For col = 0 To rs.Fields.Count - 1
Cellsfrow, col + 1) = rs(col).Value
Next col
rs.MoveNext
Wend
Здесь следует обратить внимание на одну особенность. Спецификация OLE DB для некоторых полей таблиц метаданных определяет типы, несовместимые с VARIANT, например UI8. Поэтому при попытке получения значения из этих полей через ADODB может возникнуть ошибка;
C++
try
{
t_db_data_source сn;
_THROW_OLEDB_FAILED(cn,attach("file
name=d:\\database\\employee.ibp"));
t_db_session session;
_THROW_OLEDB_FAILED(session,create(сn));
//библиотека напрямую не поддерживает
//работу с интерфейсом получения
//наборов информационной схемы,
//поэтому напишем необходимый код "в лоб".
IDBSchemaRowsetPtr spSR(session.session_obj());
if(!spSR)
t_ole_error::throw_error(
"query interface [IDBSchemaRowset]",spSR.m_hr);
IUnknownPtr spUnk;
HRESULT hr=spSR->GetRowset(NULL,DBSCHEMA_TABLES,0,NULL,
IID_IUnknown,0,NULL,&spUnk.ref_ptr());
if(FAILED(hr))
t_ole_error::throw_disp_error(hr,"get tables list");
//подключаем полученный набор к курсору
t_db_cursor cursor;
_THROW_OLEDB_FAILED(cursor,attach(spUnk))
//получаем описание полей результирующего
//множества (набора данных)
t_db_row row;
_THROW_OLEDB_FAILED(cursor,describe(row))
//печатаем содержимое набора
while(cursor.fetch(row)==S_OK)
{
for(t_db_row::size_type i=0;i!=row.count;++i)
cout<
cout<
}//while
//проверяем причину выхода из цикла
_THROW_OLEDB_FAILED(cursor,m_last_result)
}
catch(const exception& exc){
cout<<"error:"<
}
Команда
Команда используется для выполнения SQL-запросов к базе данных Важно не путать команду, которая является СОМ-объектом, с текстом команды, который представляет собой строку. Обычно команды используют для описания данных, например для создания таблицы и предоставления привилегий, и манипуляции данными, например для обновления и удаления строк Особый случай манитчя- ции данными - создание набора строк (примером служит оператор SQL SELECT).
Спецификация OLE DB определяет гибкий набор интерфейсов для выполнения и обработки результатов SQL-запросов. Определяется так последовательность шагов:
* Создание команды.
* Установка текста запроса.
* Подготовка запроса.
* Подготовка параметров запроса.
* Установка свойств результирующего множества (набора данных).
* Выполнение запроса.
Создание команды
Как уже было отмечено ранее, объект команды создается объектом сессии.
С помощью отдельной сессии можно создать много команд
По умолчанию команда пользуется транзакцией породившей ее сессии Если же сессия не содержит активной транзакции и разрешен режим автоматического подтверждения/отката, то команда будет выполняться в своей собственной автоматической транзакции, не зависящей от сессии.
Примеры создания команд.
ADODB
Dim сn As New ADODB.Connection
сn.Open "file name=d:\database\employee.ibp"
Dim cmd As New ADODB.Command cmd.ActiveConnection = сn
C++
t_db_data_source сn;
_THROW_OLEDB_FAILED(cn, attach(
"file name=d:\\database\\employee.ibp"));
t_db_session session;
_THROW_OLEDB_FAILED(session,create(en));
t_db_command cmdl,cmd2;
//Создаем команду традиционным способом,
//используя объект C++ сессии
_THROW_OLEDB_FAILED(cmdl,create(session));
//Команду также можно создать, обладая
//только указателем на lUnknown OLE DB-сессии.
//Это более подходящий способ для СОМ-объектов
IUnknownPtr spSession(session session_obj());
_THTOW_OLEDB_FAILED(cmd2,create(spSession));
Установка текста команды
Если команда только что создана, она еще не содержит текста. Поэтому текст SQL-запроса нужно установить
Пример установки текста запроса:
ADODB
cmd.Command.Text = "select x from job"
При этом IBPrivider сбрасывает флаг подготовленности команды и очищает список параметров Как это ни странно, здесь могут происходить ошибки:
* Команда обнаружит смешанное использование параметров - именованных " param" и неименованных, обозначаемых вопросительным знаком ('"?")
* Сбой преобразования SQL-запросов из ODBC-диалекта в вид, пригодный для передачи на сервер
Все действия, связанные с установкой текста команды, осуществляются локально, т. е. обращение к серверу базы данных не производится.
Подготовка команды
Если пользователю нужна информация о наборе рядов, который она создаст, то команду нужно подготовить:
C++
t_db_row row;
_THROW_OLEDB_FAILED (cmd, prepare("select * from iob",&row))
Поскольку с точки зрения взаимодействия с InterBase подготовка представляет собой передачу текста SQL-запроса серверу базы данных, то этот этап будет выполнен всегда - либо явным указанием пользователя, либо самой командой. При этом повторный вызов операции подготовки для одного и того же текста запроса игнорируется. Реализация команды провайдера для InterBase не осуществляет переподготовку запроса при повторном выполнении команды, поэтому явная подготовка с целью оптимизации многократного использования команды не имеет смысла
ADODB способно самостоятельно определять необходимость явной подготовки команды, поэтому об этом можно не заботиться Библиотека классов всегда проводит явную подготовку команды, выполняя ее сразу же после установки текста запроса.
Подготовка параметров SQL-запроса
Многократно выполняемые SQL-запросы, как правило, содержат параметры, представляющие собой переменные в тексте SQL-запроса. IBProvider поддерживает два вида параметров: именованные и неименованные. Перед выполнением параметризованного SQL-запроса команда должна обладать описаниями параметров. Описание параметра — это его тип, имя, направление передачи значения (in-out). Пользователь может самостоятельно сформировать описания параметров или поручить формирование параметров команде.
Явное определение параметров SQL-запроса, несмотря на свою громоздкость при работе через ADODB. обеспечивает более эффективную работу с приложениями, поскольку исключается лишнее обращение к серверу для получения их описаний.
Пример явного определения параметров SQL-запроса:
ADODB
cmd.CommandText="select * from job where job_code=?"
cmd.Parameters.Append cmd.CreateParameter(,adBSTR,adParamlnput)
cmd(0)="Eng"
C++
t_db_row row;
t_db_row param(1);
_THROW_OLEDB_FAILED(cmd2,
prepare("select * from job where job_code=?",&row))
//тип параметра определяется его значением
param[0]="Eng";
param.count=1;
_THROW_OLEDB_FAILED(cmd2,execute(¶m));
//Тип параметра задается отдельно от значения,
//в этом случае провайдер выполнит преобразование значения
//в указанный тип.
set_param(param,0,adBSTR,"Eng");
param.count=1;
_THROW_OLEDB_FAILED(cmd2,execute(¶m));
Автоматическое определение описаний параметров SQL-запроса позволяет клиентскому приложению перепоручить отслеживание типов параметров InterBase и конвертору типов IB Provider.
Пример явного указания команде сгенерировать описания типов:
ADODB
cmd.CommandText = "select * from job where job_code=?"
cmd.Parameters.Refresh
cmd(0) = "Eng"
Явное указание обновления списка параметров (cmd.Parameters.Refresh) обычно можно опустить. Однако иногда это необходимо. Например, для выполнения такого цикла:
ADODB
Dim cmd As New ADODB.Command
Dim is As ADODB.Recordset
cmd.ActiveConnection = сn
cmd.CommandText = "select * from job where job_code=?"
Dirr i AS_ Long For i = 0 To 10
cmd.Parameters.Refresh
cmd(0) = "Eng"
Set rs = cmd,Execute
'...
'rs.Close
Next i
Вся хитрость заключается в том, что ADODB при выполнении второй итерации будет создавать новую OLE DB-команду, поскольку предыдущая занята обслуживанием результирующего множества SQL-запроса, созданного на первом шаге. Без строки cmd.Parameters.Refresh внутренний список описания параметров новой команды не будет сформирован, хотя коллекция ADODB.Command.Parameters будет содержать элементы. В результате при вызове метода cmd.execute в команду передаются значения параметров, описание которых у нее отсутствует. Принудительное обновление решает эту проблему. Понятно, что создание новой команды снижает производительность описанного выше алгоритма. Поэтому для того, чтобы ADODB могло повторно воспользоваться OLE DB-командой, нужно закрывать результирующее множество (rs.Close).
Повторный вызов cmd.Parameters.Refresh для одного и того же запроса не приводит к повторному обращению к серверу, поэтому расходы на такое дублирование ничтожны.
Автоматическая генерация описания параметров:
C++
_THROW_OLEDB_FAILED(cmd2,describe_params(param));
param[0]="Eng";
_THROW_OLEDB_FAILED(cmd2,execute(¶m) ) ;
Существует единственное исключение, когда IBProvider обязательно выполнит дополнительный запрос на сервер для получения описания параметров SQL- запроса. Это касается слуиая, когда в параметре передается массив. Для такого типа параметров необходима дополнительная информация об имени таблицы и поля, в которые будут производить запись данных, а также информация о размерности массива. Подробности см. далее в разделе "Работа с массивами".
В вышеприведенных примерах были использованы неименованные параметры, обозначаемые в тексте запроса символом вопросительного знака. Именно такое обозначение параметров поддерживает и сам InterBase. Однако иногда удобно использовать именованные параметры в SQL-запросах:
* Именованный параметр можно многократно указывать в разных частях одного запроса.
* Порядок описания параметров может не соответствовать порядку использования параметров в тексте запроса. Это недопустимо для неименованных параметров.
В ADODB за удобство именованных параметров приходиться "платить" использованием режима автоматической генерации описания параметров (ADODB.Command.Parameters.Refresh). Причина заключается в том, что имя параметра, указываемое в ADODB.Command.CreateParameter, не передается команде. При использовании классов C++ такого ограничения нет - описание параметров можно формировать обоими способами. Еще одним ограничением, ADODB является невозможность использования именованных параметров для BLOB-полей -только неименованные параметры '?'.
Как уже было сказано выше, команда запрещает одновременное использование в тексте запроса именованных и неименованных параметров.
Сам InterBase поддерживает неименованные параметры. Поэтому команда вынуждена заменять в тексте запроса именованные параметры на неименованные параметры. Окончательный текст запроса, используемый для передачи на сервер, доступен через свойство команды "Prepare Stmt"
Пример многократного выполнения параметризованного запроса, содержащего именованный параметр:
ADODB
Dim cmd As New ADODB.Command
Dim rs As ADODB.Recordset
cmd.ActiveConnection = en
cmd.CommandText = "select * from job where job_code=:job_code"
Dim i As Long
For i = 0 To 10
cmd.Parameters.Refresh
cmd("job_code") = "Eng"
Debug.Print cmd.Properties("prepare stmt")
Set rs = cmd.Execute
'...
rs.Close
Next i
Установка свойств результирующего множества
Перед выполнением команды, создающей набор рядов, можно задать различные свойства этого набора. Например, поддерживаемые интерфейсы, возможности позиционирования и верхняя граница объема оперативной памяти, используемой для хранения данных. Эти свойства задаются на уровне объекта команды и будут скопированы в набор свойств объекта результирующего множества.
Пример настройки свойств набора результирующего множества команды:
ADODB
'разрешить поддержку закладок для
'произвольного позиционирования в наборе
cmd.Properties("Use bookmarks") = True
'Использовать 1 MB памяти для кеширования рядов
cmd.Properties("Memory Usage") = 1024
C++
t_db_obj_props cmd_props(false);
_THROW_OLEDB_FAILED(cmd_props,
attach_command(cmd2.command_obj()));
_THROW_OLEDB_FAILED(cmd_props,set("Use Bookmarks",true));
_THROW_OLEDB_FAILED(cmd_props,set("Memory Usage",1024));
Выполнение команды
Вызов операции execute является последним этапом выполнения SQL-запроса к базе данных, в ко юром )частв)е] объект команды Первоначальное и почти полное описание всех этапов выполнения этой операции заняло больше двух листов, забитых сухой технической информацией, дочитывая которую забываешь, с чего все началось. Шутка. Поэтому ограничимся коротким списком задач, выполняемых командой при вызове операции выполнения SQL-запроса.
* Проверка параметров. Количество разнообразных ошибок, вылавливаемых на этом этапе, превышает полтора десятка.
* Получение транзакции, в рамках которой будет выполняться SQL-запрос. Это может быть собственная активная транзакция родительской сессии или отдельная автоматически завершаемая транзакция (если таковые разрешены).
* Создание нового дескриптора низкоуровневого запроса, если текущий, принадлежащий команде, обслуживает набор строк, сформированных предыдущим вызовом операции execute. Такая ситуация может произойти при многократных вызовах execute для одного и того же SQL-запроса.
* Подготовка команды, если эта операция еще не была выполнена.
* Вызов InterBase API для выполнения запроса.
* Возвращение результата (если таковые создаются) через OUT-параметры или объект набора строк (rowset)
При выполнении SQL-запросов модификации данных (INSERT, UPDATE, DELETE) можно узнать число строк, затронутых запросом:
ADODB
cmd.CommandText =
"insert into project (proj_id,proj_name,proj_desc) " & _
"values(?,?,?)"
cmd(0) = 1001
cmd(l) = "test 1001"
cmd(2) = "test 1001"
Dim RowAffected As Long 'кол-ве вставленных строк
cmd.Execute RowAffected
Debug.Print "insert " & CStr(RowAffected) & " rows"
Набор строк
Наборы строк - это центральные объекты, которые позволяют всем компонентам доступа к данным OLE DB представлять свои данные в табличной форме. Фактически набор строк - это совокупность строк, состоящих из полей данных. Компоненты доступа к базовым таблицам предоставляют свои данные в форме набор строк. Процессоры запросов (команда) представляют в форме набора строк результаты SQL-запросов. Это позволяет создавать слои объектов, поставляющих и потребляющих данные посредством одного и того же объекта.
СУБД InterBase поддерживает только однонаправленное движение курсора по набору строк, возвращаемому SQL-запросами. Под курсором здесь и далее будет подразумеваться текущая позиция в наборе строк. Этого вполне достаточно для очень широкого круга задач. Положительной стороной однонаправленного обхода наборов строк в InterBase является возможность загрузки приложением большого объема данных без хранения в памяти уже обработанной информации. IBProvider по умолчанию обеспечивает именно такой способ "навигации" по множеству строк.
Хотя понятие курсора и присутствует в OLE DB, его основное назначение заключается в получении идентификаторов строк (HROW), а не самих данных полей строки. С помощью этих идентификаторов клиент может получать интересующие его данные в конкретной строке результирующего набора данных. То есть получив идентификатор строки, пользователь может выполнять многократное чтение полей одной и той же строки. Например, при первом чтении определяется размер данных BLOB-поля, а при втором осуществляется загрузка его содержимого.
Клиент обязан освободить идентификатор строки, когда последний ему уже не нужен. Но может это и не сделать, имитируя с помощью массива идентификаторов строк произвольный доступ к результирующему множеству SQL- запроса. При использовании ADODB этого можно добиться с помощью свойства ADODB.Recordset.CacheSize. В этом случае провайдер начнет осуществлять кеширование данных заблокированных рядов.
Помимо последовательного обхода всех строк множества, IBProvider поддерживает пропуск рядов и возможность возвращения курсора на начало множества за счет повторного выполнения запроса.
Пример создания набора строк, способа пропуска строк и возвращения курсора на начало набора:
ADODB
cmd.CommandText = "select * from job where job_code=:job_code"
cmd(";job_code") = "Eng"
Set rs = cmd.Execute
'последовательный обход всех строк множества
While Not rs.EOF
rs.MoveNext
Wend
rs.MoveFirst 'Restart
rs.Move 1 'пропускаем первый ряд
'...
rs.MoveFirst 'Restart
rs.Kove 2 'пропускаем первые два ряда
'...
Произвольный доступ к результирующему множеству SQL-запросов IBProvider имитирует за счет кеширования выбранных данных на стороне клиента. Для работы в этом режиме провайдер использует более совершенный компонент управления множеством, реализующий возможности обратной выборки и произвольного перемещения по набору данных, а также возможность "приблизительного" позиционирования. И кроме того, в режиме произвольного доступа набор строк предоставляет закладки строк, с помощью которых клиент может быстро возвращаться к некоторой строке. В некотором смысле закладки строк эквивалентны идентификатору строки (HROW), но гораздо более эффективны и не требуют никаких ресурсов для хранения. Кроме того, при работе через ADODB значение закладки текущей строки можно получить и сохранить для дальнейшего использования (см. ADODB.Recordset.Bookmark), а идентификатор строки - нет.
Ниже приведен пример создания набора строк, поддерживающего произвольный доступ, "программируя" его характеристики напрямую через свойства команды.
Пример позиционирования курсора набора рядов в случайном порядке.
ADODB
Dim cmd As New ADODB.Command
Dim rs As ADODB.Recordset
cmd.ActiveConnection = cn
cmd.CommandText = "select * from job where job_code=:job_code"
cmd("job_code") = "Eng"
'включаем поддержку закладок
cmd.Properties("Use Bookmarks") = True
Set rs = cmd.Execute
Dim i As Long
For i = 0 To rs.RecordCount
'нумерация с единицы
rs.AbsolutePosition = CLng(Rnd * rs.RecordCount) + 1
'...
Next i
В общем, клиент независимо от режима доступа может заставить провайдер хранить данные выбранных строк. В первом случае это будет осуществлено за счет явного участия пользователя и провайдера, во втором случае - провайдер будет осуществлять это самостоятельно.
Поэтому набор строк OLE DB-провайдера для InterBase всегда использует собственный механизм контроля над объемом расходуемой памяти для хранения результирующего множества. Он заключается в удержании в указанном объеме памяти только наиболее часто используемых строк и вытеснении остальных строк во временный файл. При этом создание файла откладывается до последнего момента. Такой способ хранения данных выгодно отличает IBProvider от других компонентов доступа, которые основываются на поддержке со стороны ОС и использовании ее файла подкачки.
По умолчанию IBProvider удерживает в памяти 32 строки, независимо от их размера. Часто этого может оказаться недостаточно. Поэтому спецификация OLE DB определяет стандартное свойство набора строк "Memory Usage", которое позволяет отрегулировать верхнюю границу используемой памяти.
0
IBProvider удерживает в памяти 32 ряда. По умолчанию.
1...99
Использовать процент от доступной памяти ОС (как физической гак и файла подкачки)
100...
Использование указанного размера памяти в килобайтах.
Естественно, нужно осознавать, что кеш результирующего набора данных в IBProvider является вторичным по отношению к файловому кешу ОС. Поэтому в случае экстремально больших размеров кеша в IBProvider вместо увеличения производительности можно получить прямо противоположный эффект.
Единственным ограничением, которое присутствует в текущей версии IBProvider (1.6.2), является невозможность редактирования выбранного множества строк, т. е. работы с так называемыми "живыми" запросами, которые часто используются в приложениях, создаваемых с помощью средств разработки компании Borland.
Практическое использование IBProvider
Работа с BLOB-полями
IBProvider предоставляет поддержку двум типам BLOB-полей: содержащих текст (SUB_TYPE TEXT) и бинарные данные. При этом доступ к BLOB может быть организован как к данным в памяти, так и к объекту-хранилищу. В любом случае провайдер не хранит сами данные BLOB-поля, а каждый раз загружает их по требованию клиента.
ADODB. Чтение BLOB:
Dim cn As New ADODB.Connection
cn.Open "file name=d:\database\employee.ibp"
cn.BeginTrans
Dim cmd As New ADODB.Command
Dim rs As ADODB.Recordset
cmd.ActiveConnection = cn
'JOB_REQUIREMENT - текстовое BLOB-поле
cmd.CommandTexc = "select nob_requirement from job"
Set rs = cmd.Execute
'доступ к BLOB как к данным в памяти
While Not rs.EOF
'печатаем размер BLOB-поля. обращение к ActualSize
'не производит загрузки самих данных
Debug.Print "size:" & CStr(rs(0).ActualSize)
If IsNull(rs(0)) Then
Debug.Print "NULL"
Else
Debug.Print rs(0)
End If
rs.MoveNext
Wend
Debug.Print "******************"
rs.MoveFirst
'чтение порциями по 40 байт
Dim seg As Variant, str As String
Const seg_size = 40
While Not rs.EOF
'пропускаем пустые BLOB-поля
If (Not IsNulKrs(0))) Then
str = ""
Do
seg = rs(0).GetChunk(seg_size)
'когда данных нет - GetChunk возвращает NULL
If IsNull(seg) Then Exit Do
str = str + seg
Debug.Print "get chunk: " & Len(seg) & " bytes"
Loop While True
Debug.Print ">" & CStr(rs(0).ActualSize) & " - " & Len(str)
Debug.Print ">" & str
End If
rs.MoveNext
Wend
cn.CommitTrans
ADODB. Запись BLOB-поля:
Dim cn As New ADODB.Connection
cn.Open "file name=d:\database\employee.ibp"
cn.BeginTrans
Dim cmd As New ADODB.Command
Dim rs As ADODB.Recordset
cmd.ActiveConnection = cn
'JOB_REQUIREMENT - текстовое BLOB-поле
cmd.CommandText = "select * from job"
Set rs = cmd.Execute
Dim upd_cmd As New ADODB.Command
upd_cmd.ActiveConnection = cn
upd_cmd.CommandText = _
"update job set job_requirement=? " & _
"where job_code=? and job_grade=? and " & _
"job_country=?"
upd_cmd.Parameters.Refresh
Dim RowAffected As Long
While Not rs.EOF
If (Not IsNull(rs("job_requirement"))) Then
upd_cmd(0) = UCase(rs("job_requirement"))
upd_cmd(l) = rs("job_code")
upd_cmd(2) = rs("job_grade")
upd_cmd(3) = rs("job_country")
upd_cmd.Execute RowAffected
Debug.Print "affect:" & CStr(RowAffected)
End If
rs.MoveNext
Wend
'отменяем все изменения в базе данных
cn.RollbackTrans
Работа с BLOB-полями через TBProvider на C++ также прозрачна. Хотя можно написать более интересные алгоритмы, например подстановка объекта-хранилища, полученного из результирующего множества, в качестве параметра в команду, привязанную к другой базе данных. Подробности см. в примерах из дистрибутива IBProvider и спецификации OLEDB - "BLOB's and OLE Objects".
Работа с массивами
Встроенная поддержка массивов является одним из основных пунктов списка достоинств InterBase как SQL сервера баз данных. И одновременно массивы возглавляют список его невостребованных возможностей. В практике сильная потребность в использовании массивов возникала только один раз. Эта работа была связана с анализом накапливаемой информации, касающейся функционирования торговой организации. Тогда основным препятствием оказалось отсутствие готового решения для работы с массивами InterBase из VBA (MS Office).
Поэтому в IBProvider была реализована поддержка массивов с предоставлением высокоуровневого представления этого несомненно полезного типа данных InterBase.
Особенности реализации поддержки массивов
* OLEDB-спецификация для представления типа данных "массив" использует структуру SAFEARRAY. Эта же структура употребления для управления массивами в Visual Basic.
* Элементы массивов не могут содержать NULL. Это ограничение связано с тем, что InterBase не поддерживает тип VARIANT.
* Все типы строк, хранящиеся в массивах, обрабатываются сервером как Си- строки, т. е. заканчивающиеся нулем. IBProvider исходит именно из такого способа хранения и не использует собственных символов типа \п для определения конца строки.
* Провайдер предоставляет полную поддержку для преобразования массивов из одного типа в другой. И пользуется ею по умолчанию, поскольку VB не понимает структуру SAFEARRAY, содержащую данные, несовместимые с VARIANT. Вообще говоря, наверное, можно было бы всегда возвращать массивы, содержащие VARIANT, но удалось обойтись без этой крайности. Отключить конвертирование массивов можно с помощью свойства инициализации источника данных (строка подключения) или набора строк "array_vt_type", установив его значение в false.
* Как и BLOB-поля, провайдер не хранит и не кеширует данные массива. Информация каждый раз загружается с сервера.
* Если при чтении массивов от пользователя не требуется никакой помощи, то для записи массивов провайдеру может потребоваться дополнительная информация. Дело в том, что запись массива, как и BLOB-поля, производиться отдельным обращением к InterBase API. Для этой операции требуется иметь описание, содержащее имя таблицы и имя колонки, в которую производится запись, тип элемента и сведения о размерности. Провайдер способен самостоятельно определить эту информацию только при работе с сервером InterBase 6.x и выше. Для работы с InterBase 4.x и InterBase 5.x IBProvider вводит нестандартное расширение, позволяющее определять в тексте запроса параметры вида "параметр.таблица.колонка". Этот синтаксис может быть использован как для именованных, так и для неименованных параметров:
update job set language_req=?.job.language_req
update job set language_req=:param.job.language_req
Переданные таким образом названия таблицы и колонки используются только для внутренних целей и недоступны вне провайдера. Если IBProvider смог самостоятельно получить эту информацию или значение параметра не является массивом, то пользовательская помощь игнорируется. В противном случае клиент отвечает за корректность переданных дополнительных сведений о параметре. Дополнительно заметим, что во 2-й и 3-й части такого составного имени параметра можно использовать квотированные названия объектов базы данных.
* Клиент не имеет возможности определить интересующее его подмножество массива. Провайдер всегда возвращает массив целиком. Это ограничение OLEDB, а не InterBase.
* При записи массива можно передавать подмножество. Но нужно учитывать, что массив всегда пересоздается. Поэтому в случае выполнения "UPDATE...", можно потерять предыдущую информацию из неуказанных элементов.
Пример чтения массивов.:
ADODB
Dim en As New ADODB.Connection
cn.Open "file name=d:\database\employee.ibp"
Dim cmd As New ADODB.Command, rs As ADODB.Recordset
cmd.ActiveConnection = cn
cmd. CornmandText = "select * from proj_dept_budget"
Set rs = cmd.Execute
Dim qhc As Variant ' QUART_HEAD_CNT
Dim i As Long
While Not rs.EOF
If IsNull(rs("quart_head_cnt")) Then
Debug.Print "NULL"
Else
qhc = rs("quart_head_cnt")
For i = LBound(qhc, 1) To UBound(qhc, 1)
Debug.Print "qhc[" & CStr(i) & "]=" & CStr(qhc(i))
Next i
End If
rs.MoveNext
Debug.Print "-------------------"
Wend
Пример записи массивов (InterBase 5.6):
ADODB
Dim en As New ADODB.Connection
cn.Open "file name=d:\database\employee.ibp"
Debug.Print en.Properties("IB Version")
cn.BeginTrans
Dim cmd As New ADODB.Command, rs As ADODB.Recordset
cmd.ActiveConnection = cn
cmd CommandText = "select * from proj_dept__budget"
Set rs = cmd.Execute
Dim upd_cmd As New ADODB.Command
upd_cmd.ActiveConnection = cn
upd_cmd.CommandText = _
"update proj_dept_budget " & _
"set quart_head_cnt=:a pro]_aept_budget.quart_head_cnt " & _
"where year=:year and proj_id=:proj_id and dept_no=:dept_no"
upd_cmd.Parameters.Refresh
Dim qhc As Variant ' QUAD_HEAD_CNT
Dim i As Long, RowAffected As Long
While Not rs.EOF
If Not IsNull(rs("quart_head_cnt")) Then
qhc = rs("quart_head_cnt")
For i = LBound(qhc, 1) To UBound(qhc, 1)
qhc(i) = 10 * qhc(i)
Next i
upd_cmd("a") = qhc
upd_cmd("year") = rs("year")
upd_cmd ("proj_id" ) = rs ("proj_id")
upd_cmd("dept_no") = rs("dept_no")
upd_cmd.Execute RowAffected ' транзакционные изменения
Debug.Print ">" & CStr(RowAffected)
End If
rs.MoveNext
Debug.Print -------------------
Wend
en.CommitTrans
Работа с хранимыми процедурами
Хранимые процедуры делятся на две категории - селективные (процедуры- выборки) и исполняемые.
Принцип работы с селективной хранимой процедурой, возвращающей ре- з>льтат своей работы в виде набора строк, очень похож на выполнение обычного SQL-запроса "SELECT..." содержащего параметры.
Вызов селективной процедуры "SUB_TOT_BUDGET"
ADODB
'вспомогательная функция конвертирования VARIANT в строку
'с поддержкой NULL
Function my_cstr(s As Variant) As String
If (IsNull(s)) Then
my_cstr = "NULL"
Else
my_cstr = CStr(s)
End If
End Function
Sub sproc_select()
Dim cn As New ADODB.Connection
cn.Open "file name=d:\database\employee.ibp"
cn.BeginTrans
Dim cmd As New ADODB.Command
cmd.ActiveConnection = cn
cmd.CommandText = "select * from SUB_TOT_BUDGET(?)"
cmd(0) = 100
Dim rs As ADODB.Recordset
Set rs = cmd.Execute
Dim col As Long
While Not rs.EOF
Debug.Print "----------------"
For col = 0 To rs.Fields.Count - 1
Debug.Print CStr(col) & ":" & rs.Fields(col).Name & " - " &
my_cstr(rs(col})
Next col
rs.MoveNext
Wend
cn.CommitTrans
End Sub
Вызов исполняемой ХП отличается от использования селективной ХП в том плане, что применяют SQL-запрос EXECUTE PROCEDURE... и получают результат работы через out-параметры. IBProvider различает только вызов исполняемой ХП, анализируя сигнатуру SQL-запроса. Наряду с SQL-выражением EXECUTE PROCEDURE..., непосредственно поддерживаемого InterBase, в тексте команды можно указывать EXECUTE ... и ЕХЕС ... IBProvider распознает в этих командах попытку вызова исполняемой ХП и автоматически приводит текст SQL-запроса к совместимому с InterBase. Для получения результата работы исполняемой ХП нужно либо самостоятельно описать out-параметры, либо попросить команду сформировать эти описания самостоятельно (ADODB Command Paiameters.Refresh). Основными правилами здесь являются:
* В тексте запроса out-параметры не упоминаются
* Описание out-параметров после in-параметров.
* Не обязательно определять все out-параметры. При работе через ADODB. это могут быть первые out-параметры из всего списка (пропуски не допускаются). При прямой работе с OLE DB-командой можно указывать имена интересующих выходящих параметров ХП, тем самым получать out-параметры в любой комбинации.
Тестовая база данных employee.gdb не содержит готовых примеров исполняемых ХП, поэтому для следующего примера будет определена своя собственная простейшая хранимая процедура.
Определение исполнимой хранимой процедуры:
SQL
create procedure sp_calculate_values(x integer,у integer)
returns(valuel integer,value2 varchar(64))
as
begin
valuel=x+y;
value2=x-y;
end
Вызов и обработка результатов исполнимой хранимой процедуры SP_CALCULATE_VALUES:
ADODB
Sub sproc_exec()
Dim en As New ADODB.Connection
cn.Open "file name=d:\database\employee.ibp"
cn.BeginTrans
Dim cmd As New ADODB.Command
cmd.ActiveConnection = cn
'автоматическое определение параметров
cmd.CommandText = "exec sp_calculate_values(:xl,:x2)"
cmd('x1") =200
cmd("x2") = 100
cmd.Execute
Debug.Print "outl=" & CStr(cmd("valuel"))
Debug.Print "out2=" & CStr(cmd("value2"))
' явное определение параметров
cmd.CommandText = "execute sp_calculate_values(?,?)"
cmd.Parameters.Append cmd.CreateParameter(, adlnteger,
adParamlnput, , 200)
cmd.Parameters.Append cmd.CreateParameter(, adlnteger,
adParamlnput, , 300)
cmd.Parameters.Append cmd.CreateParameter("vl", adlnteger,
adParamOutput)
cmd.Parameters.Append cmd.CreateParameter("v2", adBSTR,
adParamOutput)
cmd.Execute
Debug.Print "vl=" & CStr(cmd("vl"))
Debug.Print "v2=" & CStr(cmd("v2"))
сn.CommitTrans
End Sub
При явном определении параметров можно попробовать испытать мрован к'р на "прочность", задав некорректный порядок перечисления параметров. Например, сначала out-параметры, потом in-параметры.
Создание СОМ-объектов для работы с базой данных
Самым эффективным применением технологии OLEDB является создание и использование специализированных компонентов для работы с базой данных. Этот подход изначально начал применяться для серверов приложений (application servers). Однако ничто не мешает реализовывать re же самые принципы при создании обычного приложения базы данных. В этом случае, помимо обычных преимуществ компонентной технологии, исчезают типичные проблемы, связанные с передачей и разделением ресурсов сервера баз данных между несколькими модулями клиентского приложения. Для малосвязанных модулей достаточно разделять одно подключение, в случае использования сервисных компонентов может потребоваться совместная работа в контексте одной транзакции. Поскольку эти ресурсы представлены в виде СОМ-объектов, то для корректной работы требуется только правильно управлять их счетчиком ссылок. Однако для опытного программиста, использующего СОМ-технологии в реальной работе, это не проблема.
Исходя из накопленного опыта создания таких компонентов и их использования из программ, написанных на C++, VBA и VBScript, можно порекомендовать следующую структуру СОМ-объектов:
* Дуальный (dual) интерфейс автоматизации, через который выполняется основное взаимодействие с объектом. Этот же интерфейс предоставляет свойство Connection для того, чтобы устанавливать и получать подключение, используя ADODB-компоненты. Как уже было сказано ранее, ADODB.Connection одновременно является и источником данных и сессией.
* Обычный интерфейс (наследующий ILJnknown) для инициализации компонента посредством указателя на ITJnknown сессии.
* Внутренняя работа с базой данных осуществляется через низкоуровневые интерфейсы OLEDB посредством классов C++. Таким образом, компонент изолируется от ADODB и обеспечивает более производительное функционирование собственных алгоритмов.
Принцип наиболее эффективной работы также не очень сложный - компонент должен свести к минимуму число создающихся и подготавливающихся команд. Так же имеет смысл загрузить в память содержимое таблиц, небольших по размеру и хранящих фиксированные данные. В основном под эту категорию попадают таблицы справочников. Тогда можно исключить из запросов все возможные обращения для выборки этой информации, что в конечном итоге, уменьшает нагрузку на сервер базы данных.
В качестве поддержки совместного использования ADODB и OLEDB в одном проекте инструментальная библиотека представляет две утилиты:
* construct_adodb_connection - создание ADODB подключения на базе существующего источника данных и сессии;
* get_adodb_session - получение OLEDB-сессии, обслуживаемой ADODB-подключением.
Несмотря на открывающиеся в связи с использованием IBProvider перспективы, связанные с дроблением ваших приложений для InterBase на модули, главное не переусердствовать. Не стоит делать компоненты, предназначенные для коллекций, с собственным механизмом чтения и записи. Помните, что любой использующий команды объект делает как минимум 4-5 обращений к серверу:
* Создание
* Подготовка.
* Выполнение.
* Выборка результата.
* Разрушение
Поэтому для групповых операций больше всего приемлем классический подход, когда реализуется групповая загрузка и запись, отделенная от самих данных.
Еще одной хорошей идеей является создание в приложении обычных классов с реализацией той логики, которая скорее всего не потребуется вне границ вашего приложения. Согласитесь, что написание класса и СОМ-компонента требует несравнимых усилий. Кроме того, не забывайте, что создание СОМ-объектов производиться через СОМ-инфраструктуру, поэтому накладные расходы распространяются и на время выполнения приложения. Поэтому обычные классы все равно остаются основным "тактическим средством" больших приложений, разработанных в объектно-ориентированном стиле
Ниже приводиться пример СОМ-объекта, который подключается к сессии и используется для того, чтобы получить значение генератора (см. главу "Таблицы Первичные ключи и генераторы" (ч. 1)). Здесь мы ограничимся лишь IDL-описанием двух интерфейсов и реализацией их методов. Помимо этого, используются возможности инструментальной библиотеки из дистрибутива IBProvider I.6.2. В реальном случае этот код, конечно же, лучше оформить в виде обычного класса. Тогда можно исключить одновременную поддержку ADODB и OLEDB. Кроме того, в данном примере не оптимизирована работа метода GenID для случая повторного использования подготовленной команды, для случая многократного вызова метода с идентичными аргументами.
IDL-описание интерфейсов:
////////////////////////////////////////////////////////////
//interface IDBSessionObject
// уcтановка/получение рабочей OLEDB-сессии объекта
[
object,
uuid(98E5AB40-333E-llD6-AC8F-OOAOC907DB93),
pointer_default(unique)
]
interface IDBSessionObject:IUnknown
{
HRESULT SetDBSession([in] lUnknown* pSession);
HRESULT GetDBSession([out]lUnknown** ppSession);
};//interface IDBSessionObject
/////////////////////////////////////////////
//interface IDBGenID
// интерфейс получения значения генератора
[
object,
uuid(98E5AB41-333E-llD6-AC8F-OOAOC907DB93),
dual,
oleautomation,
pointer_default(unique),
nonextensible
]
interface IDBGenID:IDispatch
{
[propput]
HRESULT Connection([in]IDispatch* pConnection);
[propget]
HRESULT Connection([out,retval]IDispatch** ppConnection);
HRESULT Convert([in]BSTR GenName,
[in]LONG Count,
[out,retval]LONG* pResult);
};//interface IDBGenID
Реализация методов установки сессии:
//m_spADODBConnection - член класса,
// содержащий указатель на ADODB-подключение
//m_spSession - член класса,
// содержащий указатель на используемую OLEDB-сессию
//m_Cmd - команда (t_db_command) получения значения генератора
//IDBSessionObject interface ------------------------------
HRESULT _stdcall TDBGenID::SetDBSession(lUnknown* pSession)
{
::SetErrorlnfo(0,NULL);
HRESULT hr=S_OK;
_OLE_TRY_
{
//освобождаем ADODB connection
m_spADODBConnection.Release();
m_spSession=pSession;
//инициализируем объекты взаимодействия с базой данных
m_Cmd destroy();
}
_OLE_DIS P_CATCHES_
return hr;
}//SetDBSession
HRESULT _stdcall TDBGenID::GetDBSession(lUnknown** ppSession)
{
::SetErrorlnfo(0,NULL);
return m_spSession.CopyTo(ppSession);
}//GetDBSession
//IOC2_ObjectLoader interface -----------
HRESULT _stdcall TDBGenID::put_Connection
(IDispatch* pConnection)
{
::SetErrorInf0(0,NULL);
HRESULT hr=NOERROR;
_OLE_TRY_
{
IDispatchPtr spConnection(pConnection) ; //блокируем в памяти
//освобождаем текущие подключения
SetDBSession(NULL);
if(pConnection) {
IUnknownPtr spDBSession;
get_adodb_session(pConnection,spDBSession); //throw
if(SUCCEEDED(hr=SetDBSession(spDBSession)))
m_spADODBConnection=pConnection;
}//pConnection!=NULL
}
_OLE_DISP_CATCHES_
return hr;
}//put_Connection
HRESULT _stdcall TDBGenID::get_Connection
(IDispatch** ppConnection)
{
::SetErrorlnfо(0,NULL);
if(ppConnection==NULL)
return E_POINTER;
*ppConnection=NULL;
HRESULT hr=S_OK;
_OLE_TRY_
{
if(!m_spADODBConnection && (bool)m_spSession)
{
IGetDataSourcePtr spGetDataSource(m_spSession);
if(i spGetDataSource)
t_ole_error::throw_error
("query IGetDataSource interface",spGetDataSource.m_hr);
IUnknownPtr spDataSource;
if(FAILED(hr=get_data_source(spGetDataSource,spDataSource)))
t_ole_error::throw_error("Получение источника данных",hr);
IDBPropertiesPtr spDBProperties(spDataSource);
if(!spDBProperties)
t_ole_error::throw_error
("query IDBProperties interface",spDBProperties.m_hr);
construct_adodb_connection(spDBProperties,m_spSession,
m_spADODBConnection);//throw
}//if - создание ADODB-объекта
hr=m_spADODBConnection.CopyTo(ppConnection);
}
_OLE_DISP_CATCHES_
return hr;
}//get_Connection
Реализация метода получения значения генератора:
HRESULT _stdcall TDBGenID::GenID(BSTR GenName,LONG Count,
LONG* pResult)
{
::SetErrorlnfо(0,NULL);
if(pResult==NULL)
return E_POINTER;
HRESULT hr=S_OK;
_OLE_TRY_
{
if(!m_spSession)
throw runtime_error("Объект неинициализирован");
if(!m_Cmd.is_created())
_THROW_OLEDB_FAILED(m_Cmd,create(m_spSession));
structure::str_formatter stmt
("select gen_id(%l,%2) from rdb$database");
t_db_row row(1);
_THROW_OLEDB_FAILED (m_Cmd, prepare ( stmt«GenName«Count, &row) )
_THROW_OLEDB_FAILED(m_Cmd,execute(NULL));
if(m_Cmd.fetch(row)==S_OK)
*pResult=row[0].as_integer;
else
{
//проверим причину сбоя получения данных
_THROW_OLEDB_FAILED(m_Cmd,m_last_result)
throw runtime_error("Получено пустое множество");
}
}
_OLE_DIS P_CATCHES_
return hr;
}//GenID
Использование скриптов в клиентских приложениях базы данных InterBase
Время от времени у любого программиста появляется желание вынести часть логики своих приложений на уровень, который можно было бы изменять без перекомпиляции приложения. А для определенного класса задач это требование изначально является первоочередным. Как правило, когда речь заходит о добавлении такой возможности, сразу вспоминают серверы приложений. Однако существуют задачи, для которых то же самое эффективнее реализовывать на уровне отдельного клиента.
Использование такого рода "программ" разгружает основной код приложения от алгоритмов, сильно подверженных переменчивым желаниям пользователей. Например:
* Проверка достоверности данных при сохранении.
* Контроль прав на чтение и изменение данных.
* Правила движения документов.
* Настраиваемый пользовательский интерфейс.
* Печать выходных форм.
* Встроенные отчеты.
При этом не существует больших проблем с выполнением сценариев, поскольку реализовано и доступно достаточно много компонентов для быстрого решения этой задачи. В том числе и бесплатный ActiveX-компонент ScriptControl от Microsoft.
Основные трудности при реализации такого подхода приходятся на осуществление тесной интеграции основного кода приложения и кода сценария. В числе важных вопросов находится и обеспечение доступа сценария к базе данных.
Самым тривиальным решением было бы создание внутри сценария собственного подключения к база данных. Но, как уже было замечено ранее, это медленно и неэффективно. Другим решением является передача готового подключения из основного кода приложения. И вот здесь применение ADODB- и OLEDB- компонентов доступа дает максимальный эффект.
Компоненты ADODB изначально приспособлены для использования в ActiveX-сценариях. Впрочем, для передачи в сценарий соединения с базой данных ADODB.Connection с выделенной сессией могут потребоваться некоторые усилия. Решение этой задачи было приведено в разделе описания сессии.
Компоненты OLEDB нельзя непосредственно использовать в сценариях. Но их можно "обернуть" в ADODB-компоненты и таким образом использовать в коде сценария. Подробности можно посмотреть в примерах, входящих в дистрибутив IBProvider.
Естественно, что для сложных задач проблема связи сценариев с базами данных не является основной. Тем не менее стоимость программного решения может резко возрасти, если приложение будет базироваться на компонентах доступа, которые нельзя ни напрямую, ни через какой-либо адаптер использовать в сценариях.
Использование пула подключений к базе данных
Для многопользовательских серверных приложений, обрабатывающих клиентские запросы с помощью запросов к отдельной базе данных, повторное употребление ресурсов SQL-сервера является одним из основных способов увеличения производительности. Поэтому пул подключений, кеширующий инициализированные источники данных, является важной составляющей такого рода программного обеспечения. Кроме того, важно понимать, что механизм пула подключений не реализуется самим OLE DB-провайдером. От последнего требуется только корректно обрабатывать уведомления о помещении в пул и обеспечивать многопоточный доступ к компонентам. IBProvider реализует оба требования, поэтому клиенту предлагается только провести корректную инициализацию источника данных.
Для включения пула подключений при работе через ADODB нужно указать в строке подключения параметры
"OLE DB Services=-l;free_threading=true"
Параметр "OLE DB Services=-l" указывает ADODB на необходимость использования пула подключений. Параметр "free_threading=true" устанавливает внутренний флаг, объявляющий поддержку многопоточного доступа.
Для демонстрации работы пула ниже приведен простой пример, выполняющий в цикле инициализацию и закрытие источника данных. Для запрещения пула подключений присвойте "OLE DB Services" нулевое значение. Замеры производительности проводятся очень грубо - в секундах, но этого оказалось достаточно, чтобы увидеть преимущества пула подключений. По истечении 60 с с момента добавления в пул неиспользуемые источники данных освобождаются и производиться отключение от сервера базы данных.
Для того чтобы подробно изучить процесс функционирования пула подключений, следует воспользоваться информацией на сайте компании Microsoft или посмотреть в документацию по OLE DB SDK (см. "Resource Pooling").
ADODB:
Dim en As New ADODB.Connection
Dim cnt As Long
Dim start As Date, total As Date
total = Time
For cnt = 1 To 10
start = Time
cn.Provider = "LCPI.IBProvider.1"
cn.Properties("OLE DB Services") = -1
cn.Properties("free_threading") = True
cn.Open "data source=localhost:d:\database\employee.gdb;", _
"gamer", "vermut"
Dim cmd As New ADODB.Command
cmd.ActiveConnection = cn
cmd.CommandText = "select count(*) from job"
cn.BeginTrans
cmd.Execute
cn.CommitTrans
cn.Close
Debug.Print ">" & CStr(CDate(Time - start))
'можно сделать задержку чуть больше 60 с,
'чтобы понаблюдать за освобождением
'инициализированного источника данных и
'потерю подключения к базе данных
'Application.Wait Time + CDate("О:1:05")
'Debug.Print "disconnect"
'Application.Wait Time + CDate("0:0:15")
Next cnt
Debug.Print "total:" & CStr(CDate(Time - total))
'освобождение последнего объекта, использующего
'пул подключений, приводит к уничтожению всех
' инициализированных источников данных
Set cn = Nothing
Распределенные запросы
Помимо определения самой спецификации OLE DB, Microsoft активно применяет ее в своих разработках, связанных с управлением данными. И одной из самых потрясающих разработок этой категории является Microsoft Distributed Query - программный компонент, входящий в состав MS SQL, позволяющий делать SQL-запросы к нескольким источникам данных с использованием OLE DB-провайдеров. И хотя возможность обращения в одном запросе сразу к нескольким источникам данных так же доступна и в BDE, процессор распределенных SQL-запросов, реализованный Microsoft, несомненно, представляет собой более мощный и более совершенный механизм для этих целей. Далее будут перечислены основные моменты и принципы использования IBProvider в распределенных запросах с применением MS SQL 7.
* MS Distributed Query потребовал полной стабильности в описании метаданных. Для этого пришлось реализовать в IBProvider полную поддержку всех типов InterBase и обеспечить совпадение описания метаданных в наборах информационной схемы с описанием колонок результирующих множеств.
* Из-за скрупулезной сверки данных результирующих множеств с описанием их метаданных не допускается усечение хвостовых пробелов полей типа CHAR. По умолчанию усечение производится. Чтобы запретить эту операцию, в строке подключения к базе данных нужно указать свойство инициализации источника данных "truncate_char=false".
* Процессор распределенных запросов не поддерживает массивы, поэтому не стоит их выбирать в результирующее множество.
* Несовпадение диапазона дат MS SQL и InterBase приводит к тому, что нельзя выбирать даты до 1 января 1753 года.
* При работе с 3-м диалектом подключения нужно соблюдать регистр символов имени объекта базы данных, независимо от того, квотировано оно или нет Дело в том, что процессор запросов начинает повсеместно использовать двойные кавычки для имен объектов базы данных независимо от того, хотите вы этого или нет. Для подключения 1-го диалекта квотированные имена не используются, поэтому большие и маленькие символы в названии объектов базы данных не различаются.
Регистрация базы данных к процессору распределенных запросов MS SQL 7:
* Скопируйте и зарегистрируйте IBProvider на компьютер с сервером баз данных MS SQL 7, процессор запросов которого будет использоваться для выполнения распределенных запросов.
* Откройте "SQL Server Enterprise Manager" (консоль управления MS SQL серверами) и подключитесь к интересующему вас серверу.
* Перейдите на "SecurityVLinked Servers" дерева элементов конфигурирования сервера. В контекстном меню этого элемента выберите пункт "New Linked Server..."
* В открывшемся диалоге нужно указать параметры подключения к базе данных InterBase через IBProvider. Для этого:
* В поле "Linked Server" укажите имя, которое будет использоваться в SQL- запросах для идентификации нашей базы данных. Например, "ГВ_ЕМР".
* В выпадающем списке "Provider Name" выберите "LCPI OLE DB Provider for InterBase".
* Нажмите кнопку Options и установите галочку напротив пункта "Allow InProcess". Закройте это окно, нажав кнопку ОК.
* В поле "Data Source" нужно указать путь к базе данных. Например, main:e:\database\employee.gdb.
* В поле "Provider string" указываются остальные параметры подключения:
"use id=gamer, password=vermut; free_threading=true; truncate_char=false".
* Закройте диалог ввода параметров подключения.
Если все параметры были введены правильно, то, перейдя в дереве на элемент "SecurityYLinked Servers\IB_EMP\Tables", можно посмотреть на список таблиц базы данных "employers.gdb". Если при указании параметров подключения была допущена ошибка, связанный сервер нужно удалить (выбрав в его контекстном меню "Удалить") и повторить операцию регистрации с самого начала.
После того как источник данных был подключен в качестве связанного сервера к MS SQL, можно начать эксперименты с SQL-запросами. Для этого нужно открыть SQL Server Query Analyzer. Это можно сделать из меню "Tools" консоли управления MS SQL-серверами или через меню группы программ для работы с MS SQL, которое доступно через кнопку "Пуск" панели задач Windows.
В поле ввода SQL-запросов Query Analyzer можно вводить как одиночный текст запроса, так и группу запросов, используя точку с запятой в качестве разделителя. При наборе запросов нужно использовать синтаксис MS SQL, а не InterBase, поскольку последний переходит в ранг обычного носителя данных взаимодействие с которым осуществляется через OLE DB-интерфейсы и очень простые SQL-запросы.
Как уже было описано ранее, любая операция с данными базы InterBase, требует наличия активной транзакции. Поэтому самым первым SQL-запросом будет команда запуска транзакции:
MS SQL
BEGIN TRANSACTION;
После этого можно вводить SQL-запросы на выборку данных из источника данных IВ_ЕМР:
MS SQL
SELECT EMP.* FROM IB_EMP...EMPLOYEE EMP WHERE
EMP.JOB_CODE='Eng';
где IВ_ЕМР...EMPLOYEE представляет собой составное имя объекта, которое полностью идентифицирует его расположение в пространстве имен сервера баз данных MS SQL.
Теперь можно зарегистрировать любую другую базу данных InterBase, выполнив действия по аналогии с вышеописанными. В том числе никто не запрещает зарегистрировать несколько раз одну и ту же базу данных под разными псевдонимами, например ПЗ_ЕМР и Ю_ЕМР_1. Конечно, в качестве связанного сервера может использоваться любой другой OLE DB-поставщик данных, который поддерживает необходимую для процессора запросов функциональность.
Пример нахождения записей описания служащих источника данных Ш_ЕМР_1, отсутствующих в базе данных Ш_ЕМР:
MS SQL
SELECT EMP1.*
FROM IB_EMP_1...EMPLOYEE EMP1
WHERE NOT EXISTS(SELECT * FROM IB_EMP... EMPLOYEE EMP
WHERE EMP1.FIRST_NAME=EMP.FIRST_NAME AND
EMP1.LAST_NAME=EMP.LAST_NAME)
Если IB_ЕМР и IB_ЕМР_1 являются псевдонимами одной и той же базы, то результирующее множество этого SQL-запроса должно быть пустым.
При первом обращении к связанному источнику данных его сессия подключается к координатору распределенной транзакции, активизированному командой "BEGIN TRANSACTION" и для дальнейшей работы будет использоваться транзакция, принадлежащая сессии. В предыдущем примере для выполнения запроса к координатору транзакций будет подключено две сессии, каждая из которых содержит активную транзакцию. Поэтому, теоретически, если между запусками этих двух транзакций таблица EMPLOYEER будет изменена, результирующее множество может оказаться непустым. На практике, конечно, с одной базой через два различных псевдонима обычно не работают.
Поскольку в настоящий момент IB Provider (версия 1.6.2) не реализует OLE DB-интерфейсы модификации результирующих множеств, использование процессора запросов для выполнения запросов "INSERT ...", "UPDATE ...", "DELETE..." невозможно.
Заключение
В этой главе рассмотрены способы разработки клиентских приложений для InterBase 6.x и его клонов с помощью технологии OLEDB. Показаны основные подходы к разработке приложений баз данных InterBase с использованием таких популярных средств разработки компании Microsoft, как Visual Basic и Visual C++. Мощные и гибкие возможности, предоставляемые IBProvider, опровергают распространенное мнение, что InterBase - это сервер, с которым можно работать только с помощью средств разработки от компании Borland.
Немного истории
Одним из распространенных заблуждений разработчиков баз данных является мысль, что СУБД InterBase ориентирована исключительно на работу с продуктами компании Borland. И этому способствовало то, что до последнего времени все качественные библиотеки доступа к этому серверу баз данных существовали только для создания приложений на Delphi, C++ Builder или Kylix. Для остальных систем программирования приходилось использовать InterBase API или ODBC. И хотя первое позволяет создавать высокопроизводительные приложения, а второе обладает значительными претензиями на универсальность, оба подхода не в полной мере удовлетворяют требованиям современных программных систем, базирующихся на компонентных технологиях. Поэтому потребность в использовании компонентов доступа к InterBase, универсальных с точки зрения языка программирования, была. И вопрос их реализации заключался только в одном: что именно должны предоставлять эти компоненты и кто решится начать их разработку.
Ответ на первый вопрос дают принципы современной организации масштабируемой архитектуры программного обеспечения, подразумевающие использование компонентов и их группировку в раздельно компилируемые модули. Поэтому компоненты доступа должны обеспечить прозрачную интеграцию компонентов в пределах как одного модуля, так и нескольких. И технология Component Object Model (COM) позволяет без проблем применять эти принципы на практике. Но полноценное использование этой технологии для создания крупных проектов с использованием InterBase осложнялось отсутствием готовой стандартизованной реализации СОМ-объектов доступа к этой СУБД. В результате разработчики программного обеспечения под InterBase вынуждены либо продолжав создавать монолитные приложения, либо самостоятельно решать проблемы совместного использования ресурсов СУБД малосвязанными между собой модулями программы. В первом случае осознанное ограничение возможностей программы экономит время. Во втором, опуская дополнительные трудозатраты на создание компонентов доступа, можно попасть в ловушку, которая в лучшем случае не позволяет сменить сервер базы данных, в худшем приводит к краху всего проекта. Как правило, разработчики это осознают, когда поздно что-либо менять.
Тем не менее попытки создания СОМ-объектов для доступа к InterBase были Наиболее успешной попыткой можно считать библиотеку Visual Database Tools от компании Borland (VDBT). Это VCL-подобные компоненты для Visual Basic, работающие с InterBase через Borland Database Engine. Но библиотека VDBT была готовой реализацией СОМ-объектов доступа к InterBase, а не открытой спецификацией. Поэтому расширению и усовершенствованию не подлежала.
Спецификацию под названием OLE Database (OLE DB), предназначенную для создания компонентов доступа к базам данных, выпустила компания Microsoft, которая курирует и саму СОМ-технологию. Но Open Source InterBase 6 не имел собственного OLE DB-провайдера, поэтому ничего не оставалось, как начать самостоятельную разработку OLE DB for InterBase, известную ныне как IBProvider.
Обзор возможностей IBProvider
* Возможность работы со всей линейкой СУБД InterBase, начиная с версии 4 х и заканчивая клонами InieiBase 6 - Firebird и Yattil Минимальным условием работы IBProvider является наличие на компьютере клиента динамической библиотеки GDS32.dll от InterBase 4 (см. главу "Состав модулей InterBase" (ч. 4)). IBProvider самостоятельно определяет уровень возможностей сервера (так называемый base level) и клиентской части (т е. возможности GDS32.dll). а также диалект базы данных и автоматически подстраивается под эти параметры.
* Поддержка всех типов данных InterBase. Есть поддержка BLOB-полей (бинарных и текстовых), массивов и типов DECIMAL/NUMERIC (см. главу " Типы данных" (ч. 1)).
* Поддержка storage-объектов для работы с BLOB-полями. Эти объекты могут возвращаться клиенту и приниматься в качестве входящих параметров.
* Практически весь спектр OLE DB-типов. Помимо типов, непосредственно поддерживаемых InterBase, IBProvider способен принимать и возвращать беззнаковые целые числа, булевы значения, строки UNICODE и т. д.
* Встроенная поддержка конвертирования данных из одного типа в другой, преобразования массивов, бинарного и текстового представления BLOB-полей. Для преобразования типа данных NUMERIC используется библиотека для работы с большими целыми числами, что обеспечивает естественную поддержку 64-битовых целых.
* Поддержка многопоточной работы. Компоненты провайдера самостоятельно обеспечивают синхронизацию доступа к своим ресурсам, поэтому клиент может не беспокоиться о проблемах параллельной работы с одним подключением к базе данных из нескольких потоков одного приложения.
* Отказоустойчивость. Для компонентов, работающих в составе серверных приложений, исключительно важна надежность. При разработке провайдера повсеместно используются мощные возможности языка Си++ для автоматического освобождения ресурсов и обработки исключительных ситуаций.
* Оптимизация работы с результирующим множеством SQL-запросов. В зависимости от требований клиента используется механизм либо однонаправленного доступа к выборке, либо произвольного. Для поддержки обработки большого количества данных автоматически применяются временные файлы, причем для доступа к ним используется 64-битовая адресация
* Тридцатидвухбитовый кеш выбранных строк результирующего множества. Применение динамической системы приоритетов позволяет удерживать в заданном объеме памяти только наиболее часто используемые строки, а хеш- таблица обеспечивает эффективную навигацию по содержимому кеша. Таким образом, LBProvider способен с одинаковой производительностью обрабатывать как небольшие по размеру результирующие множества, так и очень большие, даже превышающие объем доступной оперативной памяти.
* Оптимизация работы с оперативной памятью. Во-первых, IBProvider использует две собственные "кучи" (heap) для динамического выделения памяти. Это снижает нагрузку на системную кучу. Во-вторых, IBProvider интенсивно запускает совместно используемые объекты, хранящие информацию только для чтения. Во время работы IBProvider создает глобальный пул (pool) объектов, что приводит к экономии памяти и позволяет уменьшить время создания и инициализации объектов и, таким образом, улучшить общую производительность приложения баз данных.
* Полная поддержка синтаксиса SQL. Также поддерживаются команды для создания/удаления базы данных и явного управления транзакциями.
* Работа с базой данных в режиме автоматического запуск и подтверждения транзакций (autocommit). По умолчанию этот режим выключен, так как он не является оптимальным для работы с InterBase, но при необходимости его можно включить.
* Полная поддержка параметризованных запросов. Можно использовать именованные и неименованные параметры, самостоятельно или автоматически формировать описания параметров и передавать их значения в обоих направлениях (in-out-параметры).
* Поддержка вызова хранимых процедур (сокращенно - ХП; подробнее о них см главу "Хранимые процедуры" (ч. 1)). Провайдер распознает запросы вида "ехес proc_name", "execute proc_name", "execute procedure proc_name" и возвращает результат работы хранимой процедуры через выходные (out) параметры.
Возможность получения метаданных из базы данных InterBase. Это списки таблиц, колонок, хранимых процедур, индексов, ограничений и т. д. (всего 26 видов метаданных). Помимо CASE-средств и систем построения отчетов, эта информация использ>ется в Microsoft Distributed Query для выполнения гетерогенных запросов к нескольким базам данных под управлением различных (!) SQL-серверов (например, MS SQL) посредством OLE DB-провайдеров.
* Тщательное следование парадигмам объектно-ориентированного проектирования, а также двухлетнее тестирование в реальных системах СУБД гарантируют высокий уровень надежности и стабильности IBProvider, который идеально подходит для использования в составе программного обеспечения с круглосуточным режимом работы.
В настоящий момент, оставив позади большой объем работ по созданию OLE DB для InterBase, можно пересмотреть роль и назначение этого драйвера. Вытеснив оригинальную клиентскую часть GDS32.DLL на второй план, IBProvider предоставляет мощный объектно-ориентированный низкоуровневый клиентский API для работы с InterBase. Встраиваясь в приложения баз данных, OLE DB-провайдер способен взять на себя всю работу по организации взаимодействия с сервером базы данных. Предоставление ресурсов для работы с базой данных в виде СОМ-объектов снимает традиционные ограничения, накладываемые на клиентские приложения баз данных. Приложение можно дробить на модули, которые можно создавать с помощью разных систем программирования. Используя сценарии, написанные на VBScript/JScript, в программы можно добавлять логику, которую невозможно реализовать на уровне базы данных. OLE DB является общепризнанным промышленным стандартом доступа к данным, что позволяет легко разворачивать и управлять приложениями, разработанными с использованием IBProvider.
Таким образом, разработка крупных масштабируемых клиентских приложений для InterBase с помощью средств разработки компании Microsoft, а также любых других систем, поддерживающих OLE DB, становится более реальной и доступной, чем можно было себе представить ранее.
Использование IBProvider в клиентских приложениях
Низкоуровневые прикладные интерфейсы для работы с СУБД (API) обычно не используются в клиентских приложениях из-за большого объема кода, необходимого для подготовки и выполнения SQL-запросов. Это относится и к OLE DB-интерфейсам. Поэтому примеры, демонстрирующие взаимодействие с различными OLE DB-провайдерами непосредственно через их СОМ-интерфейсы, носят исключительно демонстрационный характер и имеют мало общего с реальным программированием приложений баз данных Для решения повседневных задач обычно используют надстройки в виде других СОМ-объектов или библиотек классов, которые существенно упрощают работу с OLE DB. Работать с IBProvider можно двумя основными способами - через стандартные ADODB компоненты и с помощью собственной библиотеки классов для поддержки IBProvider. написанной для компилятора Borland C++ Builder.
Компоненты ADODB
В настоящее время этот набор компонентов стал промышленным стандартом взаимодействия с OLE DB-провайдерами. ADODB (www.microsoft.com/data) - это весьма удобный высокоуровневый интерфейс, реализующий классическую иерархию объектов для работы с базами данных в виде СОМ-объектов, поддерживающих технолог ию OLE Automation.
Реализация OLE DB-интерфейсов большинства провайдеров не является взаимозаменяемой и больше ориентирована на использование из программ, написанных на C++, что приводит к проблемам совместимости и переносимости приложений между различными OLE DB-провайдерами. Поэтому ADODB-компонеты, сглаживающие различия между разными OLE DB-провайдерами и доступные для использования практически везде - начиная от VisualBasic и заканчивая тем же C++, - лучше подходят для использования в качестве универсальной платформонезависимой основы для приложений баз данных.
Но у ADODB-компонентов имеется ряд недостатков, которые являются обратной стороной достоинств:
* Ограничения на типы данных, накладываемые структурой VARIANT.
* Некоторое снижение производительности за счет того, что создание объектов ADODB производится через инфраструктуру СОМ.
* Отсутствие встроенной поддержки использования нескольких независимых транзакций в рамках одного подключения, чем InterBase выгодно отличается от других SQL-серверов базы данных.
* Появляется дополнительный уровень взаимодействия с OLE DB.
Для того, чтобы избежать недостатков ADODB-компонентов, была разработана специализированная библиотека классов C++, которая реализует доступ к OLE DB провайдерам (в том числе и к IBProvider) с максимально возможной эффективностью. Эта библиотека поставляется в составе дистрибутива IBProvider.
Библиотека классов C++ для работы с OLE DB
Созданная как дополнительный слой ("обертка") над СОМ-объектами, эта библиотека классов обеспечивает более тесную интеграцию с OLE DB-провайдерами. В ней нет всего списка возможностей, который предлагает ADODB, но предоставляемый сервис делает ее более приспособленной для построения независимых и эффективных компонентов, работающих с базами данных через OLE DB.
К основным достоинствам данной библиотеки классов относится:
* автоматическое создание и разрушение объектов;
* изоляция классов для работы с базами данных друг от друга, что обеспечивает исключительную модульность и гибкость приложений на основе данной библиотеки;
* возможность подключения объекта C++ к уже существующему OLE DB компоненту;
* удобная работа с наборами полей и параметров, значительно более гибкая по сравнению с компонентами ADODB и VCL;
* возможность выбора способа обработки ошибок - через исключения или через код возврата.
Поскольку данная библиотека доступа создавалась специально для использования в больших проектах, её классы значительно уменьшают сложность взаимодействия с OLE DB-провайдером В случае необходимости использовать ADODB (например, для совместной работы модулей проекта, написанных на C++ и на VBScript, в рамках одной транзакции) в библиотеке реализованы механизмы "шлюзования".
Разумеется, существуют еще несколько других библиотек, упрощающих работу с OLE DB-провайдерами. Однако в нижеследующих примерах будут использоваться только компоненты ADODB и библиотека классов C++ для работы с OLE DB. Поэтому, прежде чем приступить к работе над описанными примерами, убедитесь в наличии всех необходимых программных продуктов. Помните, что вы можете скачать все примеры и нужные для их работы программы на сайте поддержки данной книги www.InterBase-world com.
Инсталляция IBProvider
Перед установкой OLE DB-провайдера убедитесь, что на вашей машине инсталлирована клиентская часть InterBase Для этого на компьютере как минимум, должна находиться GDS32.DLL. Обычно она находится в системном каталоге Windows (System - для 95/98/МЕ, System32 - для NT4/Win2000) Подробнее обустановке клиентской части InterBase см. главу "Установка InterBase - взгляд изнутри" (ч. 4)
В минимальный набор дистрибутива IBProvider входят два модуля: _IBProvider.dll и cw3250mt.dll. Скопируйте оба файла в системный каталог Windows и выполните команду regsvr32 _B3Provider.dll для регистрации провайдера в системе.
Если вы обладаете готовым дистрибутивом IBProvider, то программа инсталляции выполнит все необходимые операции самостоятельно.
Обратите внимание, что при инсталляции провайдера в Windows NT4/Windows 2000 у вас должны быть права на запись в реестр Поэтому операцию регистрации лучше всего выполнять, обладая правами администратора.
После установки провайдера перезагрузка ОС не требуется
Инсталляция ADODB-компонентов
Компоненты ADO входят в состав свободно распространяемого дистрибутива Microsoft Data Access Components и доступны для скачивания на сайте компании Microsoft - www microsoft com/data. Для написания примеров использовались ADODB-компоненты из дистрибутива версии 2.6.
Примеры использования ADODB
Для создания примеров работы с IBProvider через ADODB был применен Visual Basic for Application (VBA) из Microsoft Excel 97. Для использования ADODB-компонентов нужно их добавить в список библиотек, употребляемых Visual Basic Для этого:
* Откройте редактор кода Visual Basic (Alt+Fl 1).
* Выберите пункт меню Сервис\Ссылки.
* Найдите в списке строку Microsoft ActiveX Data Objects 2.6 Library и поставьте рядом с ней галочку.
* Закройте окно, нажав кнопку "ОК".
Использование библиотеки классов
Библиотека классов поставляется в виде исходных текстов. Поэтому для ее использования нужно выполнять следующие требования:
* Явно добавить в проект файлы из каталога Lib:
ole_lib\oledb\oledb_client_lib.cpp Основные классы для работы с OLE DB
ole_lib\oledb\oledb_client_base.cpp
ole_lib\oledb\oledb_common.cpp
ole_lib\oledb\oledb_variant.cpp
ole_lib\oledb\oledb_ado_lib.cpp Утилиты стыковки с ADODB
ole_lib\ole_base.cpp
ole_lib\ole_auto.cpp
Win32Lib\win321ib.cpp
structure\util_classes.cpp
util_func.cpp
* Начало каждого срр-файла, включенного в проект, должно выглядеть следующим образом:
ttinclude <_pch_.h> #pragma hdrstop
* Добавить в параметры проекта (опция Conditional defines) макрос INCLUDE_OLEDB_HEADER.
* При использовании в проекте VCL компонент, нужно добавить в параметры проекта макрос _USE_VCL_. В этом случае файл
* Основной каталог include, используемый компилятором C++ Builder, должен содержать заголовочные файлы OLE DB SDK. BCB5 и Free Borland C++ Compiler уже содержат все необходимое. В ВСВЗ нужно добавить эти файлы самостоятельно, используя OLE DB SDK версии не выше 2.1.
Представленная в составе дистрибутива IBProvider библиотека классов является основой для проектов, её использующих. Поэтому предполагается, чго заголовочный файл <_pch_.h> прямо или косвенно включен в каждый срр-файл проекта. Возможность параллельного использования с другими библиотеками осуществляется за счет определения пространств имен. Поддержка библиотеки VCL добавлена изначально. Для поддержки других библиотек потребуется модифицировать <_pch_.h>.
Перенос на другие компиляторы C++ полностью зависит от степени их совместимости с последним стандартом C++ и от сложности перехода на другую реализацию STL.
Примеры использования библиотеки классов
Для написания и тестирования примеров использовался Borland C++ Builder 3-й версии (с установленным пакетом исправлений, который доступен для скачивания на сайте компании Borland). Библиотека классов самостоятельно конфигурируется под использование компилятора и STL из ВСВ5, поэтому примеры переносятся на Borland C++ Builder 5-й версии без проблем.
В примерах, включенных в текст этого раздела, опускаются этап инициализации СОМ и обработка исключений. Все это, естественно, присутствует в оригинале примеров, доступных для скачивания с сайта поддержки этой книги www.lnterBase-world.com.
Также для изучения технологии использования библиотеки классов для работы с OLE DB из C++ рекомендуется посмотреть примеры из дистрибутива IBProvider.
Тестовая база данных
Для тестирования использовался Firebird 1.0 и база данных employee.gdb, входящая в дистрибутив этого сервера баз данных. На этом сервере был создан пользователь "gamer" с паролем "vermin"
Для сокращения объема кода, проводящего подключение к базе данных, использовался текстовый файл employee.ibp, содержащий следующую информацию:
data source=c266:d:\database\employee.gdb;
user=gamer;
password=vermut;
auto_cornmit = true ;
ctype=win!251;
Операционная система
Все перечисленные компоненты для написания примеров были установлены на одном компьютере, работающем под управлением Windows NT4 Service Pack 5, Internet Explorer 5.
Состав компонентов IBProvider
Давайте рассмотрим составные части IBProvider. Компоненты, входящие в состав OLE DB-провайдера, делятся на 4 основные группы:
Источник Оанны\ (Data Source). Компоненты этой группы отвечают за инициализацию и управление подключением к базе данных. Здесь же предоставляется интерфейс для создания сессии.
Сессия (Session). Компонент управления транзакцией. У одного источника данных может быть несколько сессий. Кроме управления транзакциями, сессия обеспечивает создание команд, открытие таблиц и получение информации о метаданных базы данных.
Команда (Command). Компонент для подготовки и выполнения SQL-запросов к базе данных Команда выполняется в рамках конкретной сессии, однако в случае работы в режиме автоматического запуска и подтверждения транзакций (autocommit) выполняется в рамках собственной транзакции. Внутри одной сессии может существовать множество команд.
Набор строк (Ronset). Компонент, реализующий интерфейсы навигации по результатам SQL-запроса (результирующему множеству) и доступа к его содержимому.
Для описания взаимодействующих сторон, будет использоваться следующая терминология:
Клиент - это любой фрагмент системного или прикладного кода, использующий интерфейс OLE DB. Сюда могут входить и сами компоненты доступа. Так же, для обозначения этой стороны взаимодействия, будут использоваться термины пользователь и потребитель. Компонентов доступа - это любой программный компонент, предоставляющий интерфейс OLE DB. Параллельно будут использоваться OLE DB- поставщик, OLE DB-провайдер, провайдер и IBProvider. Настройка и определение функциональности компонентов осуществляется через их свойства. Свойства - это атрибуты объекта. Например, свойства набора строк определяют верхний предел объема оперативной памяти для хранения данных, поддержку закладок и потоковую модель. Клиенты устанавливают значения свойств, чтобы потребовать от соответствующего объекта некоторого заданного поведения, и читают свойства, чтобы определить возможности объекта Каждое свойство характеризуется значением, типом, описанием, атрибутом чтения/записи
Свойство идентифицируется GUID (глобальный уникальный идентификатор, представляющий собой структуру длиной 128 бит) и целым числом, представляющим идентификатор свойства. Набор свойств - это совокупность свойств с одним и тем же GUID.
Источник данных
Создание компонента Data Source является отправной точкой для работы с базой данных через IBProvider. Существует несколько сценариев создания и инициализации компонента доступа. Они отличаются объемом работы, выполняемой в клиентском приложении, библиотекой доступа к OLE DB и самим IBProvider.
Вариант 1. Клиент самостоятельно осуществляет все этапы:
ADODB
Dim en As New ADODB.Connection
cn.Provider = "LCPI.IBProvider.1"
cn.Properties("data source") =
"localhost:d:\database\employee.gdb"
en.Properties("user id") = "gamer"
en.Properties("password") = "vermut"
cn.Open
C++
t_db_data_source cn;
_THROW_OLEDB_FAILED(cn,create("LCPI.IBProvider.1"))
t_db_ob]_props cn_props(/*refresh=*/false);
_THROW_OLEDB_FAILED(cn_props,attach_data_source(en.m_obj, DBPROPSET_DBINITALL))
_THROW_OLEDB_FAILED(cn_props,set("data source" "iocalhost:d:\\database\\employee. gdo")) ;
_THROW_OLEDB_FAILED(cn_props,set("user id","gamer"));
_THROW_OLEDB_FAILED(cn_props,set("password","vermut"));
_THROW_OLEDB_FAILED(en,attach(""));
Вариант 2. Создание и инициализацию выполняет клиентская библиотека:
ADODB
Dim en As New ADODB.Connection
Call en.Open("provider=LCPI.IBProvider.1; data
source=Iocalhost:d:\database\employee.gdb", "gamer", "vermut")
C++
t_db_data_source cn;
_THROW_OLEDB_FAILED(en,attach("provider=LCPI.IBProvider.1;"
"data source=localhost:d:\\database\\employee.gdb;"
"user id=gamer;password=vermut"));
Вариант 3. Провайдер создает клиентская библиотека, инициализацию выполняет сам провайдер:
ADODB
Dim en As New ADODB.Connection
Call en.Open("file name=d:\database\employee.ibp")
C++
t_do_data_source cn;
_THROW_OLEDB_FAILED(cn,
attach!"file name=d:\\database\\employee.ibp"));
//или явно указываем провайдер и файл с параметрами
_THROW_OLEDB_FAILED(en,
attach("provider=LCPI.IBProvider.1;"
"file name=d:\\database\\employee.ibp"));
где "employee.ibp" - обычный текстовый файл, в котором хранится строка подключения вида
data souгсе=Iocalhost:d:\\database\\employee.gdb;
user id=gamer;
password=vermut
Пока OLE DB-провайдер не подключен к базе данных, параметры инициализации будут единственно доступным набором свойств. В IBProvider определены стандартные свойства инициализации и собственные, предназначенные для специанализированной настройки дальнейшей работы с базой данных. (За подробностями обращайтесь к документации по IBProvider.)
После успешного подключения к базе данных становятся доступными свойства информационного набора, с помощью которых компонент источника данных предоставляет сведения о сервере базы данных. Часть этих свойств стандартизовано спецификацией OLE DB. Остальные свойства предоставляют информацию, специфичную для IBProvider, содержащую расширенные сведения о сервере и базе данных.
Пример получения значений информационных свойств:
ADODB
'подключение к базе данных
....
'стандартные свойства
Debug.Print en.Properties("provider version")
Debug.Print en.Properties("provider friendly name")
'специфические свойства
Debug.Print en.Properties("IB Base Level")
Debug.Print en.Properties("IB GDS32 Version")
Debug.Print en Properties("IB Version")
C++
//Подключение к базе данных
//...
t_db_obj_props cn_props(false);
_THROW_OLEDB_FAILED(cn_props,
attach_data_source(cn.m_obi, DBPROPSET_DATASOURCEINFOALL));
..печать всех информационных свойств
for(UINT i = 0; i! =cn_props .GetltemsInContainer () ;+ + i)
{
cout< ; } Компонент Data Source имеет еще несколько возможностей: например, сохранение параметров подключения к базе данных в файле и перечисление до- пус!имы\ символов для названий объектов базы данных. Однако в основном он используется для создания объектов сессий.
Сессия
Основная функция сессии - установить рамки транзакции с заданными параметрами (подробнее о транзакциях см. главу "Транзакции. Параметры транзакций" (ч 1))
Хотя в ADODB понятие сессии совмещено с понятием источника данных, в OLE DB это два различных объекта. Надо полагать, что основная причина такой иерархии объектов ADODB заключается в архитектуре пула подключений, используемого в серверных приложениях Microsoft. Гораздо проще и эффективнее осуществлять балансировку загрузки на уровне отдельных подключений к базе данных, чем на уровне сессий. Как правило, в SQL-серверах через два раздельных подключения можно осуществлять параллельные запросы к базе данных, а через разные сессии одного подключения такая работа будет осуществляться последовательно. Тем не менее InterBase может одновременно обслуживать несколько транзакций в рамках одного подключения и в данном случае выгодно отличается от большинства других SQL-серверов. Поэтому IBProvider поддерживает возможность создания нескольких объектов сессий, принадлежащих одному источнику данных.
Уровни изоляции транзакции
В IBProvider реализована поддержка трех уровней изоляции транзакций: READ COMMITTED, REPEATABLE READ (SNAPSHOT), SERIALIZABLE (SNAPSHOT TABLE STABILITY). При работе через ADODB след>ет обратить внимание на значение свойства ADODB.Connection.IsolationLevel. Библиотека классов C++ по умолчанию использует режим REPEATABLE READ. Подробнее об у ровнях изоляции транзакций вы можете узнать в главе "Транзакции. Параметры транзакций" (ч. 1).
Управление транзакциями
Поскольку корректное использование транзакций является важным условием разработки эффективных приложений баз данных, то IBProvider по умолчанию требует явного участия пользователя в процессе управления транзакциями.
Причинами отказа от автоматического запуска и завершения транзакции являются относительно высокие затраты ресурсов на эту операцию и желание контролировать все действия с базой данных.
Надо сказать, что последнее обстоятельство является наиболее важным, поскольку при разработке большой программной системы, состоящей и множества независимых модулей, явный контроль операций с базой данных позволяет избегать многих ошибок.
В то же время иногда автоматический запуски завершение транзакции могут оказаться очень удобными для решения небольших и несложных задач.
Помимо автоматических транзакций для работы с данными в IBProvider определена еще одна категория внутренних транзакций (inner transaction), используемых для чтения метаданных базы данных По умолчанию внутренних транзакций разрешены, поскольку CASE-дизайнеры и системы построения отчетов для получения метаданных явно не управляют транзакциями.
Автоматические транзакции
Для разрешения провайдеру самостоятельно управлять транзакциями нужно указать в строке инициализации параметр "auto_commit=true":
Call сn.Open(
"data source=localhost:d:\database\employee.gdb;auto_commit=true",
"gamer", "vermut")
В этом случае все создаваемые объекты сессий для данного источника данных будут способны самостоятельно запускаться и завершать транзакции без явного участия пользователя. Для выборочного разрешения такого режима можно воспользоваться свойством сессии "Session AutoCommit". Если это свойство равно true, то сессия может обслуживать запросы к базе данных без необходимости явного запуска и подтверждения.
По умолчанию автоматические транзакции используют уровень изоляции SNAPSHOT. Если требуется установить другой уровень изоляции, то нужно либо установить параметр инициализации источника данных "auto_commit_level", либо изменить свойство сессии "Autocommit Isolation Levels" в одно из следующих значений:
* 0 х 1000 - READ COMMITED;
* 0 x 10000 - REPEAT ABLE READ. Это режим по умолчанию;
* 0 x 100000 - SERIALIZABLE.
О принципе функционирования автоматических транзакций следует сказать следующее. Автоматическая транзакция не управляется через интерфейс сессии. За её завершение и откат отвечает команда или набор строк внутри этой сессии. Если команда не возвращает набор строк (rowset), то транзакция фиксируется сразу. Если внутри автоматической транзакции появляется набор строк, то транзакция завершается при освобождении этого набора То есть внутри одной сессии. у которой свойство "Session AutoCommit" равно true, может существовать несколько активных транзакций. Естественно, что в этом случае пользователь также может явно управлять запуском и завершением транзакции, принадлежащей сессии. В случае явного запуска транзакции, для дальнейших запросов и операций в рамках этой сессии будет использоваться контекст именно этой транзакции.
Несмотря на то, что ffiProvider старается выполнить как можно больше операций в рамках одной автоматической транзакции, все равно производительность приложения, не осуществляющего самостоятельного контроля над транзакциями, не может сравниться с приложениями, явно управляющими транзакциями.
Управление транзакциями через SQL
Помимо управления транзакцией через OLE DB-интерфейсы сессии, IBProvider осуществляет специальную поддержку SQL-запросов вида: "SET TRANSACTION...", "COMMIT" и "ROLLBACK". В этом случае будет использоваться транзакция, принадлежащая сессии. Управление транзакциями через SQL-запросы позволяет указывать специфические параметры контекста транзакции, которые не стандартизированы в OLE DB и которые возможно использовать благодаря особенностям InterBase API.
Примеры работы с транзакциями
Ниже приведены примеры, демонстрирующие способы запуска и завершения транзакций, поддерживаемые OLE DB-провайдером.
ADODB:
явное управление транзакцией:
Dim en As New ADODB.Connection
сn.Provider = "LCPI.IBProvider.1"
Call en.Open(
"data source=localhost:d:\database\employee.gdb",
"gamer","vermut")
'стандартный способ
сn IsolationLevel = adXactRepeatableRead
сn.BeginTrans
'...
'можно указать использование commit retaining
'cn.Attributes = adXactAbortRetaining + adXactCommitRetaining
cn.CoimutTrans
'управление транзакцией через SQL (можно использовать специфику
InterBase)
Dim cmd As New ADODB.Command
cmd.ActiveConnection = en
cmd.CommandText = "set transaction"
cmd.Execute
'...
cmd CommandText = "rollback"
cmd Execute
автоматический запуск транзакций - разрешение и запрещение:
Dim en As New ADODB.Connection
en Provider = "LCPI.IBProvider.1"
'auco_commit=true включение автоматических транзакций
'для всех сессий
Call cn.Open(
"data source=localhost:d:\database\employee.gdb;auto_commit=true",
"gamer", "vermut")
Dim cmd As New ADODB.Command
Dim rs As ADODB Recordset
cmd ActiveConnection = cn
cmd.CommandText = "select * from rdb$database"
Sec rs = cmd.Execute 'транзакция запускается неявно
'...
'и Судет завершена при закрытии результирующего множества
rs Close
'альтернативой auto_commit=true является установка
'(после успешного подключения к база данных)
'свойства сессии Session AutoCommit=true.
'В ADODB это одно и то же,
'поскольку на одно подключение - одна сессия
'через это же свойство можно "выключить" глобальное
'разрешение на автоматический
'запуск транзакции, что дальше и демонстрируется
cn Properties("Session AutoCommit") = False
cmd.CommandText = "select * from rdb$database"
Set rs = cmd Execute
'выдаст олибку "Automatic transaction is disabled"
При программировании на C++ принципы взаимодействия с сессией точно такие же. Но в C++ сессия будет отдельным объектом.
В нижеследующем примере на C++ демонстрируется трюк, который часто используется для моделирования принудительного завершения транзакций. Дело в том, что InterBase реализует многоверсионную архитектуру данных (подробнее о многоверсионности данных см. главу "Транзакции Параметры транзакций" (ч 1)) Одной из особенностей такой архитектуры является то, что любые транзакции желательно завершать подтверждением (commit), а не откатом (lollback).
Однако, как правило, транзакцию, в рамках которой выполняется операция чтения данных, не подтверждают, а откатывают. Особенно в случае достаточно длинного участка кода, который генерирует исключения в случае непредвиденных ошибок загрузки информации Поэтому и нужно принудительно завершать транзакции так. как это показано в нижеследующем примере.
try
{
t_db_data_source cn;
_THROto_OLEDB_FAILED(en,attacn("provider=LCPI.IBProvxCter.1,"
"data source=localhost:d:\\database\\employee.gdb;"
"user id=gamer;"
"password=vermut"));
t_db_session session;
// метод create перегружен для разных типов аргумента, поэтому
// можно передавать
// как C++ объект (t_db_data_source), так и IUnknown источника
// данных
_THROW_OLEDB_FAILED(session,create(en)) ,
// запуск транзакции
_THROW_OLEDB_FAILED(session,start_transaction() ) ;
// создаем объект для принудительного завершения транзакции
t_auto_mem_fun_l
_auto_commit_(session, /*commit_retaining=*/false, &t_db_session::commit);
//... теперь, что бы ни произошло, транзакция
// будет "закоммичена"
throw runtime_error("This is my test error");
}
catcn(const exception& exc)
{
cout<< "error:"< } По умолчанию библиотека не генерирует исключений, поэтому даже если сбой произошел из-за проблем с самой базой данных, то принудительное завершение транзакции, выполняемое в деструкторе _auto_commit_, не возбудит исключения.
Распределенные транзакции
Еще одним способом инициирования транзакции является подключение сессии к координатору распределенных транзакций. В общих чертах, координатор представляет собой сессию, транслирующую вызовы собственных интерфейсов управления транзакциией в идентичные групповые вызовы интерфейсов списка дочерних сессий. Как правило, от пользователя не требуется никакого участия для подключения к координатору. За это отвечает окружение, у которого пользовательский код запрашивает подключение к базе данных.
На практике распределенные транзакции обычно используются в СОМ+ (MTS) и Microsoft Distributed Query. В первом случае существует следующая особенность. Когда компоненты просят у своего окружения предоставить им подключение к базе данных, то на каждый такой запрос создается отдельная пара источник данных - сессия. Связано это с описанным выше принципом работы пула подключений. Если компонентов, обрабатывающих пользовательский запрос, очень много и они работают с одной и той же базой данных с идентичными параметрами подключения, то имеет смысл один раз получить подключение и потом предоставлять его компонентам. Иначе в распределенной транзакции будет использовано множество сессий, каждая из которых соответствует процессу или потоку на сервере базы данных, что может привести к резкому снижению производительности сервера СУБД.
Использование нескольких сессий в ADODB
Несмотря на то что модель объектов ADODB не предоставляет прямой возможности одновременного использования нескольких сессий с одним источником данных, это ограничение можно обойти. Решение основывается на применение внутреннего интерфейса ADOConnectionConstruction компоненты ADODB.Connection.
void clone_adodb_connection(IDispatch* pCurrentConnection,
IDispatchPtr& spNewConnection)//throw
{
//объявляем типы смарт-указателей для интерфейсов
//конструирования ADODB-подключения
DECLARE_IPTR_TYPE(ADOConnectionConstruction);
DECLARE_IPTR_TYPE(ADOConnectionConstructionl5);
//1 получаем источник данных, привязанный к pCurrentConnection
ADOConnectionConstructionPtr
spConstruct(pCurrentConnection);
ADOConnectionConstruetionl5Ptr
spConstructlS(pCurrentConnection);
if(!spConstruct && !spConstruct15)
t_ole_error::throw_error("Объект - не ADODB.Connection",
E_INVALIDARG);
IUnknownPtr spDataSource;
//берем указатель на OLE DB-источник данных
if((bool)spConstruct15)
spConstruct15->get_DSO(&spDataSource.ref_ptr());
if(!spDataSource && (bool)spConstruct)
spConstruct->get_DSO(&spDataSource.ref_ptr());
if(!spDataSource)
t_ole_error::throw_error(
"ADODB.Connection не инициализирован",E_FAIL);
//2 создаем новую сессию для spDataSource ------------------
IUnknownPtr spNewSession;
IDBCreateSessionPtr spDBCreateSession(spDataSource);
assert((bool) spDBCreateSession);
if(FAILED(spDBCreateSession->CreateSession
(NULL,IID_IUnknown,kspNewSession.ref_ptr())))
{
t_ole_error::throw_error(
"Ошибка создания новой сессии",E_FAIL);
}
assert((bool)spNewSession);
//3 создаем новый экземпляр ADODB.Connection ----------------
IUnknownPtr spUnkNewConnection;
HRESULT hr=SafeCreateInstance("ADODB.Connection",
NULL,CLSCTX_INPROC,IID_IUnknown,
(void**)&spUnkNewConnection.ref_ptr());
if(FAILED(hr))
t_ole_error::throw_error(
"Ошибка создания \"ADODB.Connection\"",hr);
spConstruet = spUnkNewConnection;
spConstruct15=spUnkNewConnection;
if(!spConstructlS && !spConstruct)
throw t_ole_error(
"Ошибка подключения к \"ADODB.Connection\"",E_FAIL);
spDataSource->AddRef(); //ADO не вызывает для них AddRef spNewSession->AddRef();
//при конструировании ADODB.Connection
//пытается установить свои свойства,
//в результате чего, если IBProvider уже подключен
//к базе данных, может произойти ошибка
//тем не менее подключение уже сконструировано
//и вполне работоспособно.
if((bool)spConstructlS) //IID_Connect-on15
{
spConstruct15->WrapDSOandSession(spDataSource,spNewSession);
hr = spUnkNewConnection ->
Querylnterface(IID_ConnectionlS,spNewConnection);
}
else //IID_Connection
{
spConstruct->WrapDSOandSession(spDataSource,spNewSession);
hr = spUnkNewConnection ->
Querylnterface(IID_Connection,spNewConnection);
}
if (FAILED(hr))
t_ole_error::throw_error(
"Ошибка получения IDispatch из ADODB.Connection",hr);
assert((bool)spNewConnection);
//всё — spNewConnection подключен к тому же
//источнику данных, но обладает
//собственной сессией.
}//cione_adodb_connection
Чтение метаданных
Помимо управления транзакциями, сессия предоставляет еще одну полезную возможность - получение метаданных для базы данных (о метаданных см. главу "Структура базы данных InterBase" (ч. 4)). Поскольку в некоторых системах, например в Microsoft Distributed Query, операция получения метаданных выполняется очень часто, то IBProvider хранит информацию о них в оперативной памяти (т. е. кеширует). Кэширование метаданных можно настраивать для обеспечения оптимального быстродействия. Определить режим кеширования можно через свойство инициализации источника данных "schema_cache" и свойство сессии - "Session Schema Cache". Этим свойствам можно присваивать следующие значения:
* Кэширование запрещено. Данные будут всегда перечитываться.
* Глобальное кеширование на уровне Data Source. Это режим по умолчанию.
* Кеширование на уровне Session.
Если при запросе метаданных сессия содержит явно запущенную транзакцию, то провайдер не будет использовать дополнительную внутреннюю транзакцию для получения данных, а воспользуется уже существующей. Если явно запущенной транзакции нет, то IBProvider автоматически запустит внутреннюю транзакцию с уровнем изоляции, указанной в свойстве сессии "Autocommit Isolation Levels". Для запрещения автоматического запуска провайдером внутренних транзакций для извлечения метаданные необходимо определить в строке инициализации источника данных "inner_trans=false" или установить свойство сессии "Session InnerTrans=false".
Получение и вывод списка таблиц базы данных:
ADODB
Dim cn As New ADODB.Connection
Call cn.Open("file name=d:\database\employee.ibp")
Dim rs As ADODB.Recordset
Set rs = cn.OpenSchema(adSchemaTables)
Cells.Clear
Dim col As Long, row As Long
row = 1
'печать названия колоник
For col = 0 To rs.Fields.Count - 1
Cells(row, col + 1) = rs(col).Name
Next col
'печать содержимого
While Not rs.EOF
row = row + 1
For col = 0 To rs.Fields.Count - 1
Cellsfrow, col + 1) = rs(col).Value
Next col
rs.MoveNext
Wend
Здесь следует обратить внимание на одну особенность. Спецификация OLE DB для некоторых полей таблиц метаданных определяет типы, несовместимые с VARIANT, например UI8. Поэтому при попытке получения значения из этих полей через ADODB может возникнуть ошибка;
C++
try
{
t_db_data_source сn;
_THROW_OLEDB_FAILED(cn,attach("file
name=d:\\database\\employee.ibp"));
t_db_session session;
_THROW_OLEDB_FAILED(session,create(сn));
//библиотека напрямую не поддерживает
//работу с интерфейсом получения
//наборов информационной схемы,
//поэтому напишем необходимый код "в лоб".
IDBSchemaRowsetPtr spSR(session.session_obj());
if(!spSR)
t_ole_error::throw_error(
"query interface [IDBSchemaRowset]",spSR.m_hr);
IUnknownPtr spUnk;
HRESULT hr=spSR->GetRowset(NULL,DBSCHEMA_TABLES,0,NULL,
IID_IUnknown,0,NULL,&spUnk.ref_ptr());
if(FAILED(hr))
t_ole_error::throw_disp_error(hr,"get tables list");
//подключаем полученный набор к курсору
t_db_cursor cursor;
_THROW_OLEDB_FAILED(cursor,attach(spUnk))
//получаем описание полей результирующего
//множества (набора данных)
t_db_row row;
_THROW_OLEDB_FAILED(cursor,describe(row))
//печатаем содержимое набора
while(cursor.fetch(row)==S_OK)
{
for(t_db_row::size_type i=0;i!=row.count;++i)
cout< cout< }//while //проверяем причину выхода из цикла _THROW_OLEDB_FAILED(cursor,m_last_result) } catch(const exception& exc){ cout<<"error:"< }
Команда
Команда используется для выполнения SQL-запросов к базе данных Важно не путать команду, которая является СОМ-объектом, с текстом команды, который представляет собой строку. Обычно команды используют для описания данных, например для создания таблицы и предоставления привилегий, и манипуляции данными, например для обновления и удаления строк Особый случай манитчя- ции данными - создание набора строк (примером служит оператор SQL SELECT).
Спецификация OLE DB определяет гибкий набор интерфейсов для выполнения и обработки результатов SQL-запросов. Определяется так последовательность шагов:
* Создание команды.
* Установка текста запроса.
* Подготовка запроса.
* Подготовка параметров запроса.
* Установка свойств результирующего множества (набора данных).
* Выполнение запроса.
Создание команды
Как уже было отмечено ранее, объект команды создается объектом сессии.
С помощью отдельной сессии можно создать много команд
По умолчанию команда пользуется транзакцией породившей ее сессии Если же сессия не содержит активной транзакции и разрешен режим автоматического подтверждения/отката, то команда будет выполняться в своей собственной автоматической транзакции, не зависящей от сессии.
Примеры создания команд.
ADODB
Dim сn As New ADODB.Connection
сn.Open "file name=d:\database\employee.ibp"
Dim cmd As New ADODB.Command cmd.ActiveConnection = сn
C++
t_db_data_source сn;
_THROW_OLEDB_FAILED(cn, attach(
"file name=d:\\database\\employee.ibp"));
t_db_session session;
_THROW_OLEDB_FAILED(session,create(en));
t_db_command cmdl,cmd2;
//Создаем команду традиционным способом,
//используя объект C++ сессии
_THROW_OLEDB_FAILED(cmdl,create(session));
//Команду также можно создать, обладая
//только указателем на lUnknown OLE DB-сессии.
//Это более подходящий способ для СОМ-объектов
IUnknownPtr spSession(session session_obj());
_THTOW_OLEDB_FAILED(cmd2,create(spSession));
Установка текста команды
Если команда только что создана, она еще не содержит текста. Поэтому текст SQL-запроса нужно установить
Пример установки текста запроса:
ADODB
cmd.Command.Text = "select x from job"
При этом IBPrivider сбрасывает флаг подготовленности команды и очищает список параметров Как это ни странно, здесь могут происходить ошибки:
* Команда обнаружит смешанное использование параметров - именованных " param" и неименованных, обозначаемых вопросительным знаком ('"?")
* Сбой преобразования SQL-запросов из ODBC-диалекта в вид, пригодный для передачи на сервер
Все действия, связанные с установкой текста команды, осуществляются локально, т. е. обращение к серверу базы данных не производится.
Подготовка команды
Если пользователю нужна информация о наборе рядов, который она создаст, то команду нужно подготовить:
C++
t_db_row row;
_THROW_OLEDB_FAILED (cmd, prepare("select * from iob",&row))
Поскольку с точки зрения взаимодействия с InterBase подготовка представляет собой передачу текста SQL-запроса серверу базы данных, то этот этап будет выполнен всегда - либо явным указанием пользователя, либо самой командой. При этом повторный вызов операции подготовки для одного и того же текста запроса игнорируется. Реализация команды провайдера для InterBase не осуществляет переподготовку запроса при повторном выполнении команды, поэтому явная подготовка с целью оптимизации многократного использования команды не имеет смысла
ADODB способно самостоятельно определять необходимость явной подготовки команды, поэтому об этом можно не заботиться Библиотека классов всегда проводит явную подготовку команды, выполняя ее сразу же после установки текста запроса.
Подготовка параметров SQL-запроса
Многократно выполняемые SQL-запросы, как правило, содержат параметры, представляющие собой переменные в тексте SQL-запроса. IBProvider поддерживает два вида параметров: именованные и неименованные. Перед выполнением параметризованного SQL-запроса команда должна обладать описаниями параметров. Описание параметра — это его тип, имя, направление передачи значения (in-out). Пользователь может самостоятельно сформировать описания параметров или поручить формирование параметров команде.
Явное определение параметров SQL-запроса, несмотря на свою громоздкость при работе через ADODB. обеспечивает более эффективную работу с приложениями, поскольку исключается лишнее обращение к серверу для получения их описаний.
Пример явного определения параметров SQL-запроса:
ADODB
cmd.CommandText="select * from job where job_code=?"
cmd.Parameters.Append cmd.CreateParameter(,adBSTR,adParamlnput)
cmd(0)="Eng"
C++
t_db_row row;
t_db_row param(1);
_THROW_OLEDB_FAILED(cmd2,
prepare("select * from job where job_code=?",&row))
//тип параметра определяется его значением
param[0]="Eng";
param.count=1;
_THROW_OLEDB_FAILED(cmd2,execute(¶m));
//Тип параметра задается отдельно от значения,
//в этом случае провайдер выполнит преобразование значения
//в указанный тип.
set_param(param,0,adBSTR,"Eng");
param.count=1;
_THROW_OLEDB_FAILED(cmd2,execute(¶m));
Автоматическое определение описаний параметров SQL-запроса позволяет клиентскому приложению перепоручить отслеживание типов параметров InterBase и конвертору типов IB Provider.
Пример явного указания команде сгенерировать описания типов:
ADODB
cmd.CommandText = "select * from job where job_code=?"
cmd.Parameters.Refresh
cmd(0) = "Eng"
Явное указание обновления списка параметров (cmd.Parameters.Refresh) обычно можно опустить. Однако иногда это необходимо. Например, для выполнения такого цикла:
ADODB
Dim cmd As New ADODB.Command
Dim is As ADODB.Recordset
cmd.ActiveConnection = сn
cmd.CommandText = "select * from job where job_code=?"
Dirr i AS_ Long For i = 0 To 10
cmd.Parameters.Refresh
cmd(0) = "Eng"
Set rs = cmd,Execute
'...
'rs.Close
Next i
Вся хитрость заключается в том, что ADODB при выполнении второй итерации будет создавать новую OLE DB-команду, поскольку предыдущая занята обслуживанием результирующего множества SQL-запроса, созданного на первом шаге. Без строки cmd.Parameters.Refresh внутренний список описания параметров новой команды не будет сформирован, хотя коллекция ADODB.Command.Parameters будет содержать элементы. В результате при вызове метода cmd.execute в команду передаются значения параметров, описание которых у нее отсутствует. Принудительное обновление решает эту проблему. Понятно, что создание новой команды снижает производительность описанного выше алгоритма. Поэтому для того, чтобы ADODB могло повторно воспользоваться OLE DB-командой, нужно закрывать результирующее множество (rs.Close).
Повторный вызов cmd.Parameters.Refresh для одного и того же запроса не приводит к повторному обращению к серверу, поэтому расходы на такое дублирование ничтожны.
Автоматическая генерация описания параметров:
C++
_THROW_OLEDB_FAILED(cmd2,describe_params(param));
param[0]="Eng";
_THROW_OLEDB_FAILED(cmd2,execute(¶m) ) ;
Существует единственное исключение, когда IBProvider обязательно выполнит дополнительный запрос на сервер для получения описания параметров SQL- запроса. Это касается слуиая, когда в параметре передается массив. Для такого типа параметров необходима дополнительная информация об имени таблицы и поля, в которые будут производить запись данных, а также информация о размерности массива. Подробности см. далее в разделе "Работа с массивами".
В вышеприведенных примерах были использованы неименованные параметры, обозначаемые в тексте запроса символом вопросительного знака. Именно такое обозначение параметров поддерживает и сам InterBase. Однако иногда удобно использовать именованные параметры в SQL-запросах:
* Именованный параметр можно многократно указывать в разных частях одного запроса.
* Порядок описания параметров может не соответствовать порядку использования параметров в тексте запроса. Это недопустимо для неименованных параметров.
В ADODB за удобство именованных параметров приходиться "платить" использованием режима автоматической генерации описания параметров (ADODB.Command.Parameters.Refresh). Причина заключается в том, что имя параметра, указываемое в ADODB.Command.CreateParameter, не передается команде. При использовании классов C++ такого ограничения нет - описание параметров можно формировать обоими способами. Еще одним ограничением, ADODB является невозможность использования именованных параметров для BLOB-полей -только неименованные параметры '?'.
Как уже было сказано выше, команда запрещает одновременное использование в тексте запроса именованных и неименованных параметров.
Сам InterBase поддерживает неименованные параметры. Поэтому команда вынуждена заменять в тексте запроса именованные параметры на неименованные параметры. Окончательный текст запроса, используемый для передачи на сервер, доступен через свойство команды "Prepare Stmt"
Пример многократного выполнения параметризованного запроса, содержащего именованный параметр:
ADODB
Dim cmd As New ADODB.Command
Dim rs As ADODB.Recordset
cmd.ActiveConnection = en
cmd.CommandText = "select * from job where job_code=:job_code"
Dim i As Long
For i = 0 To 10
cmd.Parameters.Refresh
cmd("job_code") = "Eng"
Debug.Print cmd.Properties("prepare stmt")
Set rs = cmd.Execute
'...
rs.Close
Next i
Установка свойств результирующего множества
Перед выполнением команды, создающей набор рядов, можно задать различные свойства этого набора. Например, поддерживаемые интерфейсы, возможности позиционирования и верхняя граница объема оперативной памяти, используемой для хранения данных. Эти свойства задаются на уровне объекта команды и будут скопированы в набор свойств объекта результирующего множества.
Пример настройки свойств набора результирующего множества команды:
ADODB
'разрешить поддержку закладок для
'произвольного позиционирования в наборе
cmd.Properties("Use bookmarks") = True
'Использовать 1 MB памяти для кеширования рядов
cmd.Properties("Memory Usage") = 1024
C++
t_db_obj_props cmd_props(false);
_THROW_OLEDB_FAILED(cmd_props,
attach_command(cmd2.command_obj()));
_THROW_OLEDB_FAILED(cmd_props,set("Use Bookmarks",true));
_THROW_OLEDB_FAILED(cmd_props,set("Memory Usage",1024));
Выполнение команды
Вызов операции execute является последним этапом выполнения SQL-запроса к базе данных, в ко юром )частв)е] объект команды Первоначальное и почти полное описание всех этапов выполнения этой операции заняло больше двух листов, забитых сухой технической информацией, дочитывая которую забываешь, с чего все началось. Шутка. Поэтому ограничимся коротким списком задач, выполняемых командой при вызове операции выполнения SQL-запроса.
* Проверка параметров. Количество разнообразных ошибок, вылавливаемых на этом этапе, превышает полтора десятка.
* Получение транзакции, в рамках которой будет выполняться SQL-запрос. Это может быть собственная активная транзакция родительской сессии или отдельная автоматически завершаемая транзакция (если таковые разрешены).
* Создание нового дескриптора низкоуровневого запроса, если текущий, принадлежащий команде, обслуживает набор строк, сформированных предыдущим вызовом операции execute. Такая ситуация может произойти при многократных вызовах execute для одного и того же SQL-запроса.
* Подготовка команды, если эта операция еще не была выполнена.
* Вызов InterBase API для выполнения запроса.
* Возвращение результата (если таковые создаются) через OUT-параметры или объект набора строк (rowset)
При выполнении SQL-запросов модификации данных (INSERT, UPDATE, DELETE) можно узнать число строк, затронутых запросом:
ADODB
cmd.CommandText =
"insert into project (proj_id,proj_name,proj_desc) " & _
"values(?,?,?)"
cmd(0) = 1001
cmd(l) = "test 1001"
cmd(2) = "test 1001"
Dim RowAffected As Long 'кол-ве вставленных строк
cmd.Execute RowAffected
Debug.Print "insert " & CStr(RowAffected) & " rows"
Набор строк
Наборы строк - это центральные объекты, которые позволяют всем компонентам доступа к данным OLE DB представлять свои данные в табличной форме. Фактически набор строк - это совокупность строк, состоящих из полей данных. Компоненты доступа к базовым таблицам предоставляют свои данные в форме набор строк. Процессоры запросов (команда) представляют в форме набора строк результаты SQL-запросов. Это позволяет создавать слои объектов, поставляющих и потребляющих данные посредством одного и того же объекта.
СУБД InterBase поддерживает только однонаправленное движение курсора по набору строк, возвращаемому SQL-запросами. Под курсором здесь и далее будет подразумеваться текущая позиция в наборе строк. Этого вполне достаточно для очень широкого круга задач. Положительной стороной однонаправленного обхода наборов строк в InterBase является возможность загрузки приложением большого объема данных без хранения в памяти уже обработанной информации. IBProvider по умолчанию обеспечивает именно такой способ "навигации" по множеству строк.
Хотя понятие курсора и присутствует в OLE DB, его основное назначение заключается в получении идентификаторов строк (HROW), а не самих данных полей строки. С помощью этих идентификаторов клиент может получать интересующие его данные в конкретной строке результирующего набора данных. То есть получив идентификатор строки, пользователь может выполнять многократное чтение полей одной и той же строки. Например, при первом чтении определяется размер данных BLOB-поля, а при втором осуществляется загрузка его содержимого.
Клиент обязан освободить идентификатор строки, когда последний ему уже не нужен. Но может это и не сделать, имитируя с помощью массива идентификаторов строк произвольный доступ к результирующему множеству SQL- запроса. При использовании ADODB этого можно добиться с помощью свойства ADODB.Recordset.CacheSize. В этом случае провайдер начнет осуществлять кеширование данных заблокированных рядов.
Помимо последовательного обхода всех строк множества, IBProvider поддерживает пропуск рядов и возможность возвращения курсора на начало множества за счет повторного выполнения запроса.
Пример создания набора строк, способа пропуска строк и возвращения курсора на начало набора:
ADODB
cmd.CommandText = "select * from job where job_code=:job_code"
cmd(";job_code") = "Eng"
Set rs = cmd.Execute
'последовательный обход всех строк множества
While Not rs.EOF
rs.MoveNext
Wend
rs.MoveFirst 'Restart
rs.Move 1 'пропускаем первый ряд
'...
rs.MoveFirst 'Restart
rs.Kove 2 'пропускаем первые два ряда
'...
Произвольный доступ к результирующему множеству SQL-запросов IBProvider имитирует за счет кеширования выбранных данных на стороне клиента. Для работы в этом режиме провайдер использует более совершенный компонент управления множеством, реализующий возможности обратной выборки и произвольного перемещения по набору данных, а также возможность "приблизительного" позиционирования. И кроме того, в режиме произвольного доступа набор строк предоставляет закладки строк, с помощью которых клиент может быстро возвращаться к некоторой строке. В некотором смысле закладки строк эквивалентны идентификатору строки (HROW), но гораздо более эффективны и не требуют никаких ресурсов для хранения. Кроме того, при работе через ADODB значение закладки текущей строки можно получить и сохранить для дальнейшего использования (см. ADODB.Recordset.Bookmark), а идентификатор строки - нет.
Ниже приведен пример создания набора строк, поддерживающего произвольный доступ, "программируя" его характеристики напрямую через свойства команды.
Пример позиционирования курсора набора рядов в случайном порядке.
ADODB
Dim cmd As New ADODB.Command
Dim rs As ADODB.Recordset
cmd.ActiveConnection = cn
cmd.CommandText = "select * from job where job_code=:job_code"
cmd("job_code") = "Eng"
'включаем поддержку закладок
cmd.Properties("Use Bookmarks") = True
Set rs = cmd.Execute
Dim i As Long
For i = 0 To rs.RecordCount
'нумерация с единицы
rs.AbsolutePosition = CLng(Rnd * rs.RecordCount) + 1
'...
Next i
В общем, клиент независимо от режима доступа может заставить провайдер хранить данные выбранных строк. В первом случае это будет осуществлено за счет явного участия пользователя и провайдера, во втором случае - провайдер будет осуществлять это самостоятельно.
Поэтому набор строк OLE DB-провайдера для InterBase всегда использует собственный механизм контроля над объемом расходуемой памяти для хранения результирующего множества. Он заключается в удержании в указанном объеме памяти только наиболее часто используемых строк и вытеснении остальных строк во временный файл. При этом создание файла откладывается до последнего момента. Такой способ хранения данных выгодно отличает IBProvider от других компонентов доступа, которые основываются на поддержке со стороны ОС и использовании ее файла подкачки.
По умолчанию IBProvider удерживает в памяти 32 строки, независимо от их размера. Часто этого может оказаться недостаточно. Поэтому спецификация OLE DB определяет стандартное свойство набора строк "Memory Usage", которое позволяет отрегулировать верхнюю границу используемой памяти.
|
0 |
IBProvider удерживает в памяти 32 ряда. По умолчанию. |
|
1...99 |
Использовать процент от доступной памяти ОС (как физической гак и файла подкачки) |
|
100... |
Использование указанного размера памяти в килобайтах. |
Естественно, нужно осознавать, что кеш результирующего набора данных в IBProvider является вторичным по отношению к файловому кешу ОС. Поэтому в случае экстремально больших размеров кеша в IBProvider вместо увеличения производительности можно получить прямо противоположный эффект.
Единственным ограничением, которое присутствует в текущей версии IBProvider (1.6.2), является невозможность редактирования выбранного множества строк, т. е. работы с так называемыми "живыми" запросами, которые часто используются в приложениях, создаваемых с помощью средств разработки компании Borland.
Практическое использование IBProvider
Работа с BLOB-полями
IBProvider предоставляет поддержку двум типам BLOB-полей: содержащих текст (SUB_TYPE TEXT) и бинарные данные. При этом доступ к BLOB может быть организован как к данным в памяти, так и к объекту-хранилищу. В любом случае провайдер не хранит сами данные BLOB-поля, а каждый раз загружает их по требованию клиента.
ADODB. Чтение BLOB:
Dim cn As New ADODB.Connection
cn.Open "file name=d:\database\employee.ibp"
cn.BeginTrans
Dim cmd As New ADODB.Command
Dim rs As ADODB.Recordset
cmd.ActiveConnection = cn
'JOB_REQUIREMENT - текстовое BLOB-поле
cmd.CommandTexc = "select nob_requirement from job"
Set rs = cmd.Execute
'доступ к BLOB как к данным в памяти
While Not rs.EOF
'печатаем размер BLOB-поля. обращение к ActualSize
'не производит загрузки самих данных
Debug.Print "size:" & CStr(rs(0).ActualSize)
If IsNull(rs(0)) Then
Debug.Print "NULL"
Else
Debug.Print rs(0)
End If
rs.MoveNext
Wend
Debug.Print "******************"
rs.MoveFirst
'чтение порциями по 40 байт
Dim seg As Variant, str As String
Const seg_size = 40
While Not rs.EOF
'пропускаем пустые BLOB-поля
If (Not IsNulKrs(0))) Then
str = ""
Do
seg = rs(0).GetChunk(seg_size)
'когда данных нет - GetChunk возвращает NULL
If IsNull(seg) Then Exit Do
str = str + seg
Debug.Print "get chunk: " & Len(seg) & " bytes"
Loop While True
Debug.Print ">" & CStr(rs(0).ActualSize) & " - " & Len(str)
Debug.Print ">" & str
End If
rs.MoveNext
Wend
cn.CommitTrans
ADODB. Запись BLOB-поля:
Dim cn As New ADODB.Connection
cn.Open "file name=d:\database\employee.ibp"
cn.BeginTrans
Dim cmd As New ADODB.Command
Dim rs As ADODB.Recordset
cmd.ActiveConnection = cn
'JOB_REQUIREMENT - текстовое BLOB-поле
cmd.CommandText = "select * from job"
Set rs = cmd.Execute
Dim upd_cmd As New ADODB.Command
upd_cmd.ActiveConnection = cn
upd_cmd.CommandText = _
"update job set job_requirement=? " & _
"where job_code=? and job_grade=? and " & _
"job_country=?"
upd_cmd.Parameters.Refresh
Dim RowAffected As Long
While Not rs.EOF
If (Not IsNull(rs("job_requirement"))) Then
upd_cmd(0) = UCase(rs("job_requirement"))
upd_cmd(l) = rs("job_code")
upd_cmd(2) = rs("job_grade")
upd_cmd(3) = rs("job_country")
upd_cmd.Execute RowAffected
Debug.Print "affect:" & CStr(RowAffected)
End If
rs.MoveNext
Wend
'отменяем все изменения в базе данных
cn.RollbackTrans
Работа с BLOB-полями через TBProvider на C++ также прозрачна. Хотя можно написать более интересные алгоритмы, например подстановка объекта-хранилища, полученного из результирующего множества, в качестве параметра в команду, привязанную к другой базе данных. Подробности см. в примерах из дистрибутива IBProvider и спецификации OLEDB - "BLOB's and OLE Objects".
Работа с массивами
Встроенная поддержка массивов является одним из основных пунктов списка достоинств InterBase как SQL сервера баз данных. И одновременно массивы возглавляют список его невостребованных возможностей. В практике сильная потребность в использовании массивов возникала только один раз. Эта работа была связана с анализом накапливаемой информации, касающейся функционирования торговой организации. Тогда основным препятствием оказалось отсутствие готового решения для работы с массивами InterBase из VBA (MS Office).
Поэтому в IBProvider была реализована поддержка массивов с предоставлением высокоуровневого представления этого несомненно полезного типа данных InterBase.
Особенности реализации поддержки массивов
* OLEDB-спецификация для представления типа данных "массив" использует структуру SAFEARRAY. Эта же структура употребления для управления массивами в Visual Basic.
* Элементы массивов не могут содержать NULL. Это ограничение связано с тем, что InterBase не поддерживает тип VARIANT.
* Все типы строк, хранящиеся в массивах, обрабатываются сервером как Си- строки, т. е. заканчивающиеся нулем. IBProvider исходит именно из такого способа хранения и не использует собственных символов типа \п для определения конца строки.
* Провайдер предоставляет полную поддержку для преобразования массивов из одного типа в другой. И пользуется ею по умолчанию, поскольку VB не понимает структуру SAFEARRAY, содержащую данные, несовместимые с VARIANT. Вообще говоря, наверное, можно было бы всегда возвращать массивы, содержащие VARIANT, но удалось обойтись без этой крайности. Отключить конвертирование массивов можно с помощью свойства инициализации источника данных (строка подключения) или набора строк "array_vt_type", установив его значение в false.
* Как и BLOB-поля, провайдер не хранит и не кеширует данные массива. Информация каждый раз загружается с сервера.
* Если при чтении массивов от пользователя не требуется никакой помощи, то для записи массивов провайдеру может потребоваться дополнительная информация. Дело в том, что запись массива, как и BLOB-поля, производиться отдельным обращением к InterBase API. Для этой операции требуется иметь описание, содержащее имя таблицы и имя колонки, в которую производится запись, тип элемента и сведения о размерности. Провайдер способен самостоятельно определить эту информацию только при работе с сервером InterBase 6.x и выше. Для работы с InterBase 4.x и InterBase 5.x IBProvider вводит нестандартное расширение, позволяющее определять в тексте запроса параметры вида "параметр.таблица.колонка". Этот синтаксис может быть использован как для именованных, так и для неименованных параметров:
update job set language_req=?.job.language_req
update job set language_req=:param.job.language_req
Переданные таким образом названия таблицы и колонки используются только для внутренних целей и недоступны вне провайдера. Если IBProvider смог самостоятельно получить эту информацию или значение параметра не является массивом, то пользовательская помощь игнорируется. В противном случае клиент отвечает за корректность переданных дополнительных сведений о параметре. Дополнительно заметим, что во 2-й и 3-й части такого составного имени параметра можно использовать квотированные названия объектов базы данных.
* Клиент не имеет возможности определить интересующее его подмножество массива. Провайдер всегда возвращает массив целиком. Это ограничение OLEDB, а не InterBase.
* При записи массива можно передавать подмножество. Но нужно учитывать, что массив всегда пересоздается. Поэтому в случае выполнения "UPDATE...", можно потерять предыдущую информацию из неуказанных элементов.
Пример чтения массивов.:
ADODB
Dim en As New ADODB.Connection
cn.Open "file name=d:\database\employee.ibp"
Dim cmd As New ADODB.Command, rs As ADODB.Recordset
cmd.ActiveConnection = cn
cmd. CornmandText = "select * from proj_dept_budget"
Set rs = cmd.Execute
Dim qhc As Variant ' QUART_HEAD_CNT
Dim i As Long
While Not rs.EOF
If IsNull(rs("quart_head_cnt")) Then
Debug.Print "NULL"
Else
qhc = rs("quart_head_cnt")
For i = LBound(qhc, 1) To UBound(qhc, 1)
Debug.Print "qhc[" & CStr(i) & "]=" & CStr(qhc(i))
Next i
End If
rs.MoveNext
Debug.Print "-------------------"
Wend
Пример записи массивов (InterBase 5.6):
ADODB
Dim en As New ADODB.Connection
cn.Open "file name=d:\database\employee.ibp"
Debug.Print en.Properties("IB Version")
cn.BeginTrans
Dim cmd As New ADODB.Command, rs As ADODB.Recordset
cmd.ActiveConnection = cn
cmd CommandText = "select * from proj_dept__budget"
Set rs = cmd.Execute
Dim upd_cmd As New ADODB.Command
upd_cmd.ActiveConnection = cn
upd_cmd.CommandText = _
"update proj_dept_budget " & _
"set quart_head_cnt=:a pro]_aept_budget.quart_head_cnt " & _
"where year=:year and proj_id=:proj_id and dept_no=:dept_no"
upd_cmd.Parameters.Refresh
Dim qhc As Variant ' QUAD_HEAD_CNT
Dim i As Long, RowAffected As Long
While Not rs.EOF
If Not IsNull(rs("quart_head_cnt")) Then
qhc = rs("quart_head_cnt")
For i = LBound(qhc, 1) To UBound(qhc, 1)
qhc(i) = 10 * qhc(i)
Next i
upd_cmd("a") = qhc
upd_cmd("year") = rs("year")
upd_cmd ("proj_id" ) = rs ("proj_id")
upd_cmd("dept_no") = rs("dept_no")
upd_cmd.Execute RowAffected ' транзакционные изменения
Debug.Print ">" & CStr(RowAffected)
End If
rs.MoveNext
Debug.Print -------------------
Wend
en.CommitTrans
Работа с хранимыми процедурами
Хранимые процедуры делятся на две категории - селективные (процедуры- выборки) и исполняемые.
Принцип работы с селективной хранимой процедурой, возвращающей ре- з>льтат своей работы в виде набора строк, очень похож на выполнение обычного SQL-запроса "SELECT..." содержащего параметры.
Вызов селективной процедуры "SUB_TOT_BUDGET"
ADODB
'вспомогательная функция конвертирования VARIANT в строку
'с поддержкой NULL
Function my_cstr(s As Variant) As String
If (IsNull(s)) Then
my_cstr = "NULL"
Else
my_cstr = CStr(s)
End If
End Function
Sub sproc_select()
Dim cn As New ADODB.Connection
cn.Open "file name=d:\database\employee.ibp"
cn.BeginTrans
Dim cmd As New ADODB.Command
cmd.ActiveConnection = cn
cmd.CommandText = "select * from SUB_TOT_BUDGET(?)"
cmd(0) = 100
Dim rs As ADODB.Recordset
Set rs = cmd.Execute
Dim col As Long
While Not rs.EOF
Debug.Print "----------------"
For col = 0 To rs.Fields.Count - 1
Debug.Print CStr(col) & ":" & rs.Fields(col).Name & " - " &
my_cstr(rs(col})
Next col
rs.MoveNext
Wend
cn.CommitTrans
End Sub
Вызов исполняемой ХП отличается от использования селективной ХП в том плане, что применяют SQL-запрос EXECUTE PROCEDURE... и получают результат работы через out-параметры. IBProvider различает только вызов исполняемой ХП, анализируя сигнатуру SQL-запроса. Наряду с SQL-выражением EXECUTE PROCEDURE..., непосредственно поддерживаемого InterBase, в тексте команды можно указывать EXECUTE ... и ЕХЕС ... IBProvider распознает в этих командах попытку вызова исполняемой ХП и автоматически приводит текст SQL-запроса к совместимому с InterBase. Для получения результата работы исполняемой ХП нужно либо самостоятельно описать out-параметры, либо попросить команду сформировать эти описания самостоятельно (ADODB Command Paiameters.Refresh). Основными правилами здесь являются:
* В тексте запроса out-параметры не упоминаются
* Описание out-параметров после in-параметров.
* Не обязательно определять все out-параметры. При работе через ADODB. это могут быть первые out-параметры из всего списка (пропуски не допускаются). При прямой работе с OLE DB-командой можно указывать имена интересующих выходящих параметров ХП, тем самым получать out-параметры в любой комбинации.
Тестовая база данных employee.gdb не содержит готовых примеров исполняемых ХП, поэтому для следующего примера будет определена своя собственная простейшая хранимая процедура.
Определение исполнимой хранимой процедуры:
SQL
create procedure sp_calculate_values(x integer,у integer)
returns(valuel integer,value2 varchar(64))
as
begin
valuel=x+y;
value2=x-y;
end
Вызов и обработка результатов исполнимой хранимой процедуры SP_CALCULATE_VALUES:
ADODB
Sub sproc_exec()
Dim en As New ADODB.Connection
cn.Open "file name=d:\database\employee.ibp"
cn.BeginTrans
Dim cmd As New ADODB.Command
cmd.ActiveConnection = cn
'автоматическое определение параметров
cmd.CommandText = "exec sp_calculate_values(:xl,:x2)"
cmd('x1") =200
cmd("x2") = 100
cmd.Execute
Debug.Print "outl=" & CStr(cmd("valuel"))
Debug.Print "out2=" & CStr(cmd("value2"))
' явное определение параметров
cmd.CommandText = "execute sp_calculate_values(?,?)"
cmd.Parameters.Append cmd.CreateParameter(, adlnteger,
adParamlnput, , 200)
cmd.Parameters.Append cmd.CreateParameter(, adlnteger,
adParamlnput, , 300)
cmd.Parameters.Append cmd.CreateParameter("vl", adlnteger,
adParamOutput)
cmd.Parameters.Append cmd.CreateParameter("v2", adBSTR,
adParamOutput)
cmd.Execute
Debug.Print "vl=" & CStr(cmd("vl"))
Debug.Print "v2=" & CStr(cmd("v2"))
сn.CommitTrans
End Sub
При явном определении параметров можно попробовать испытать мрован к'р на "прочность", задав некорректный порядок перечисления параметров. Например, сначала out-параметры, потом in-параметры.
Создание СОМ-объектов для работы с базой данных
Самым эффективным применением технологии OLEDB является создание и использование специализированных компонентов для работы с базой данных. Этот подход изначально начал применяться для серверов приложений (application servers). Однако ничто не мешает реализовывать re же самые принципы при создании обычного приложения базы данных. В этом случае, помимо обычных преимуществ компонентной технологии, исчезают типичные проблемы, связанные с передачей и разделением ресурсов сервера баз данных между несколькими модулями клиентского приложения. Для малосвязанных модулей достаточно разделять одно подключение, в случае использования сервисных компонентов может потребоваться совместная работа в контексте одной транзакции. Поскольку эти ресурсы представлены в виде СОМ-объектов, то для корректной работы требуется только правильно управлять их счетчиком ссылок. Однако для опытного программиста, использующего СОМ-технологии в реальной работе, это не проблема.
Исходя из накопленного опыта создания таких компонентов и их использования из программ, написанных на C++, VBA и VBScript, можно порекомендовать следующую структуру СОМ-объектов:
* Дуальный (dual) интерфейс автоматизации, через который выполняется основное взаимодействие с объектом. Этот же интерфейс предоставляет свойство Connection для того, чтобы устанавливать и получать подключение, используя ADODB-компоненты. Как уже было сказано ранее, ADODB.Connection одновременно является и источником данных и сессией.
* Обычный интерфейс (наследующий ILJnknown) для инициализации компонента посредством указателя на ITJnknown сессии.
* Внутренняя работа с базой данных осуществляется через низкоуровневые интерфейсы OLEDB посредством классов C++. Таким образом, компонент изолируется от ADODB и обеспечивает более производительное функционирование собственных алгоритмов.
Принцип наиболее эффективной работы также не очень сложный - компонент должен свести к минимуму число создающихся и подготавливающихся команд. Так же имеет смысл загрузить в память содержимое таблиц, небольших по размеру и хранящих фиксированные данные. В основном под эту категорию попадают таблицы справочников. Тогда можно исключить из запросов все возможные обращения для выборки этой информации, что в конечном итоге, уменьшает нагрузку на сервер базы данных.
В качестве поддержки совместного использования ADODB и OLEDB в одном проекте инструментальная библиотека представляет две утилиты:
* construct_adodb_connection - создание ADODB подключения на базе существующего источника данных и сессии;
* get_adodb_session - получение OLEDB-сессии, обслуживаемой ADODB-подключением.
Несмотря на открывающиеся в связи с использованием IBProvider перспективы, связанные с дроблением ваших приложений для InterBase на модули, главное не переусердствовать. Не стоит делать компоненты, предназначенные для коллекций, с собственным механизмом чтения и записи. Помните, что любой использующий команды объект делает как минимум 4-5 обращений к серверу:
* Создание
* Подготовка.
* Выполнение.
* Выборка результата.
* Разрушение
Поэтому для групповых операций больше всего приемлем классический подход, когда реализуется групповая загрузка и запись, отделенная от самих данных.
Еще одной хорошей идеей является создание в приложении обычных классов с реализацией той логики, которая скорее всего не потребуется вне границ вашего приложения. Согласитесь, что написание класса и СОМ-компонента требует несравнимых усилий. Кроме того, не забывайте, что создание СОМ-объектов производиться через СОМ-инфраструктуру, поэтому накладные расходы распространяются и на время выполнения приложения. Поэтому обычные классы все равно остаются основным "тактическим средством" больших приложений, разработанных в объектно-ориентированном стиле
Ниже приводиться пример СОМ-объекта, который подключается к сессии и используется для того, чтобы получить значение генератора (см. главу "Таблицы Первичные ключи и генераторы" (ч. 1)). Здесь мы ограничимся лишь IDL-описанием двух интерфейсов и реализацией их методов. Помимо этого, используются возможности инструментальной библиотеки из дистрибутива IBProvider I.6.2. В реальном случае этот код, конечно же, лучше оформить в виде обычного класса. Тогда можно исключить одновременную поддержку ADODB и OLEDB. Кроме того, в данном примере не оптимизирована работа метода GenID для случая повторного использования подготовленной команды, для случая многократного вызова метода с идентичными аргументами.
IDL-описание интерфейсов:
////////////////////////////////////////////////////////////
//interface IDBSessionObject
// уcтановка/получение рабочей OLEDB-сессии объекта
[
object,
uuid(98E5AB40-333E-llD6-AC8F-OOAOC907DB93),
pointer_default(unique)
]
interface IDBSessionObject:IUnknown
{
HRESULT SetDBSession([in] lUnknown* pSession);
HRESULT GetDBSession([out]lUnknown** ppSession);
};//interface IDBSessionObject
/////////////////////////////////////////////
//interface IDBGenID
// интерфейс получения значения генератора
[
object,
uuid(98E5AB41-333E-llD6-AC8F-OOAOC907DB93),
dual,
oleautomation,
pointer_default(unique),
nonextensible
]
interface IDBGenID:IDispatch
{
[propput]
HRESULT Connection([in]IDispatch* pConnection);
[propget]
HRESULT Connection([out,retval]IDispatch** ppConnection);
HRESULT Convert([in]BSTR GenName,
[in]LONG Count,
[out,retval]LONG* pResult);
};//interface IDBGenID
Реализация методов установки сессии:
//m_spADODBConnection - член класса,
// содержащий указатель на ADODB-подключение
//m_spSession - член класса,
// содержащий указатель на используемую OLEDB-сессию
//m_Cmd - команда (t_db_command) получения значения генератора
//IDBSessionObject interface ------------------------------
HRESULT _stdcall TDBGenID::SetDBSession(lUnknown* pSession)
{
::SetErrorlnfo(0,NULL);
HRESULT hr=S_OK;
_OLE_TRY_
{
//освобождаем ADODB connection
m_spADODBConnection.Release();
m_spSession=pSession;
//инициализируем объекты взаимодействия с базой данных
m_Cmd destroy();
}
_OLE_DIS P_CATCHES_
return hr;
}//SetDBSession
HRESULT _stdcall TDBGenID::GetDBSession(lUnknown** ppSession)
{
::SetErrorlnfo(0,NULL);
return m_spSession.CopyTo(ppSession);
}//GetDBSession
//IOC2_ObjectLoader interface -----------
HRESULT _stdcall TDBGenID::put_Connection
(IDispatch* pConnection)
{
::SetErrorInf0(0,NULL);
HRESULT hr=NOERROR;
_OLE_TRY_
{
IDispatchPtr spConnection(pConnection) ; //блокируем в памяти
//освобождаем текущие подключения
SetDBSession(NULL);
if(pConnection) {
IUnknownPtr spDBSession;
get_adodb_session(pConnection,spDBSession); //throw
if(SUCCEEDED(hr=SetDBSession(spDBSession)))
m_spADODBConnection=pConnection;
}//pConnection!=NULL
}
_OLE_DISP_CATCHES_
return hr;
}//put_Connection
HRESULT _stdcall TDBGenID::get_Connection
(IDispatch** ppConnection)
{
::SetErrorlnfо(0,NULL);
if(ppConnection==NULL)
return E_POINTER;
*ppConnection=NULL;
HRESULT hr=S_OK;
_OLE_TRY_
{
if(!m_spADODBConnection && (bool)m_spSession)
{
IGetDataSourcePtr spGetDataSource(m_spSession);
if(i spGetDataSource)
t_ole_error::throw_error
("query IGetDataSource interface",spGetDataSource.m_hr);
IUnknownPtr spDataSource;
if(FAILED(hr=get_data_source(spGetDataSource,spDataSource)))
t_ole_error::throw_error("Получение источника данных",hr);
IDBPropertiesPtr spDBProperties(spDataSource);
if(!spDBProperties)
t_ole_error::throw_error
("query IDBProperties interface",spDBProperties.m_hr);
construct_adodb_connection(spDBProperties,m_spSession,
m_spADODBConnection);//throw
}//if - создание ADODB-объекта
hr=m_spADODBConnection.CopyTo(ppConnection);
}
_OLE_DISP_CATCHES_
return hr;
}//get_Connection
Реализация метода получения значения генератора:
HRESULT _stdcall TDBGenID::GenID(BSTR GenName,LONG Count,
LONG* pResult)
{
::SetErrorlnfо(0,NULL);
if(pResult==NULL)
return E_POINTER;
HRESULT hr=S_OK;
_OLE_TRY_
{
if(!m_spSession)
throw runtime_error("Объект неинициализирован");
if(!m_Cmd.is_created())
_THROW_OLEDB_FAILED(m_Cmd,create(m_spSession));
structure::str_formatter stmt
("select gen_id(%l,%2) from rdb$database");
t_db_row row(1);
_THROW_OLEDB_FAILED (m_Cmd, prepare ( stmt«GenName«Count, &row) )
_THROW_OLEDB_FAILED(m_Cmd,execute(NULL));
if(m_Cmd.fetch(row)==S_OK)
*pResult=row[0].as_integer;
else
{
//проверим причину сбоя получения данных
_THROW_OLEDB_FAILED(m_Cmd,m_last_result)
throw runtime_error("Получено пустое множество");
}
}
_OLE_DIS P_CATCHES_
return hr;
}//GenID
Использование скриптов в клиентских приложениях базы данных InterBase
Время от времени у любого программиста появляется желание вынести часть логики своих приложений на уровень, который можно было бы изменять без перекомпиляции приложения. А для определенного класса задач это требование изначально является первоочередным. Как правило, когда речь заходит о добавлении такой возможности, сразу вспоминают серверы приложений. Однако существуют задачи, для которых то же самое эффективнее реализовывать на уровне отдельного клиента.
Использование такого рода "программ" разгружает основной код приложения от алгоритмов, сильно подверженных переменчивым желаниям пользователей. Например:
* Проверка достоверности данных при сохранении.
* Контроль прав на чтение и изменение данных.
* Правила движения документов.
* Настраиваемый пользовательский интерфейс.
* Печать выходных форм.
* Встроенные отчеты.
При этом не существует больших проблем с выполнением сценариев, поскольку реализовано и доступно достаточно много компонентов для быстрого решения этой задачи. В том числе и бесплатный ActiveX-компонент ScriptControl от Microsoft.
Основные трудности при реализации такого подхода приходятся на осуществление тесной интеграции основного кода приложения и кода сценария. В числе важных вопросов находится и обеспечение доступа сценария к базе данных.
Самым тривиальным решением было бы создание внутри сценария собственного подключения к база данных. Но, как уже было замечено ранее, это медленно и неэффективно. Другим решением является передача готового подключения из основного кода приложения. И вот здесь применение ADODB- и OLEDB- компонентов доступа дает максимальный эффект.
Компоненты ADODB изначально приспособлены для использования в ActiveX-сценариях. Впрочем, для передачи в сценарий соединения с базой данных ADODB.Connection с выделенной сессией могут потребоваться некоторые усилия. Решение этой задачи было приведено в разделе описания сессии.
Компоненты OLEDB нельзя непосредственно использовать в сценариях. Но их можно "обернуть" в ADODB-компоненты и таким образом использовать в коде сценария. Подробности можно посмотреть в примерах, входящих в дистрибутив IBProvider.
Естественно, что для сложных задач проблема связи сценариев с базами данных не является основной. Тем не менее стоимость программного решения может резко возрасти, если приложение будет базироваться на компонентах доступа, которые нельзя ни напрямую, ни через какой-либо адаптер использовать в сценариях.
Использование пула подключений к базе данных
Для многопользовательских серверных приложений, обрабатывающих клиентские запросы с помощью запросов к отдельной базе данных, повторное употребление ресурсов SQL-сервера является одним из основных способов увеличения производительности. Поэтому пул подключений, кеширующий инициализированные источники данных, является важной составляющей такого рода программного обеспечения. Кроме того, важно понимать, что механизм пула подключений не реализуется самим OLE DB-провайдером. От последнего требуется только корректно обрабатывать уведомления о помещении в пул и обеспечивать многопоточный доступ к компонентам. IBProvider реализует оба требования, поэтому клиенту предлагается только провести корректную инициализацию источника данных.
Для включения пула подключений при работе через ADODB нужно указать в строке подключения параметры
"OLE DB Services=-l;free_threading=true"
Параметр "OLE DB Services=-l" указывает ADODB на необходимость использования пула подключений. Параметр "free_threading=true" устанавливает внутренний флаг, объявляющий поддержку многопоточного доступа.
Для демонстрации работы пула ниже приведен простой пример, выполняющий в цикле инициализацию и закрытие источника данных. Для запрещения пула подключений присвойте "OLE DB Services" нулевое значение. Замеры производительности проводятся очень грубо - в секундах, но этого оказалось достаточно, чтобы увидеть преимущества пула подключений. По истечении 60 с с момента добавления в пул неиспользуемые источники данных освобождаются и производиться отключение от сервера базы данных.
Для того чтобы подробно изучить процесс функционирования пула подключений, следует воспользоваться информацией на сайте компании Microsoft или посмотреть в документацию по OLE DB SDK (см. "Resource Pooling").
ADODB:
Dim en As New ADODB.Connection
Dim cnt As Long
Dim start As Date, total As Date
total = Time
For cnt = 1 To 10
start = Time
cn.Provider = "LCPI.IBProvider.1"
cn.Properties("OLE DB Services") = -1
cn.Properties("free_threading") = True
cn.Open "data source=localhost:d:\database\employee.gdb;", _
"gamer", "vermut"
Dim cmd As New ADODB.Command
cmd.ActiveConnection = cn
cmd.CommandText = "select count(*) from job"
cn.BeginTrans
cmd.Execute
cn.CommitTrans
cn.Close
Debug.Print ">" & CStr(CDate(Time - start))
'можно сделать задержку чуть больше 60 с,
'чтобы понаблюдать за освобождением
'инициализированного источника данных и
'потерю подключения к базе данных
'Application.Wait Time + CDate("О:1:05")
'Debug.Print "disconnect"
'Application.Wait Time + CDate("0:0:15")
Next cnt
Debug.Print "total:" & CStr(CDate(Time - total))
'освобождение последнего объекта, использующего
'пул подключений, приводит к уничтожению всех
' инициализированных источников данных
Set cn = Nothing
Распределенные запросы
Помимо определения самой спецификации OLE DB, Microsoft активно применяет ее в своих разработках, связанных с управлением данными. И одной из самых потрясающих разработок этой категории является Microsoft Distributed Query - программный компонент, входящий в состав MS SQL, позволяющий делать SQL-запросы к нескольким источникам данных с использованием OLE DB-провайдеров. И хотя возможность обращения в одном запросе сразу к нескольким источникам данных так же доступна и в BDE, процессор распределенных SQL-запросов, реализованный Microsoft, несомненно, представляет собой более мощный и более совершенный механизм для этих целей. Далее будут перечислены основные моменты и принципы использования IBProvider в распределенных запросах с применением MS SQL 7.
* MS Distributed Query потребовал полной стабильности в описании метаданных. Для этого пришлось реализовать в IBProvider полную поддержку всех типов InterBase и обеспечить совпадение описания метаданных в наборах информационной схемы с описанием колонок результирующих множеств.
* Из-за скрупулезной сверки данных результирующих множеств с описанием их метаданных не допускается усечение хвостовых пробелов полей типа CHAR. По умолчанию усечение производится. Чтобы запретить эту операцию, в строке подключения к базе данных нужно указать свойство инициализации источника данных "truncate_char=false".
* Процессор распределенных запросов не поддерживает массивы, поэтому не стоит их выбирать в результирующее множество.
* Несовпадение диапазона дат MS SQL и InterBase приводит к тому, что нельзя выбирать даты до 1 января 1753 года.
* При работе с 3-м диалектом подключения нужно соблюдать регистр символов имени объекта базы данных, независимо от того, квотировано оно или нет Дело в том, что процессор запросов начинает повсеместно использовать двойные кавычки для имен объектов базы данных независимо от того, хотите вы этого или нет. Для подключения 1-го диалекта квотированные имена не используются, поэтому большие и маленькие символы в названии объектов базы данных не различаются.
Регистрация базы данных к процессору распределенных запросов MS SQL 7:
* Скопируйте и зарегистрируйте IBProvider на компьютер с сервером баз данных MS SQL 7, процессор запросов которого будет использоваться для выполнения распределенных запросов.
* Откройте "SQL Server Enterprise Manager" (консоль управления MS SQL серверами) и подключитесь к интересующему вас серверу.
* Перейдите на "SecurityVLinked Servers" дерева элементов конфигурирования сервера. В контекстном меню этого элемента выберите пункт "New Linked Server..."
* В открывшемся диалоге нужно указать параметры подключения к базе данных InterBase через IBProvider. Для этого:
* В поле "Linked Server" укажите имя, которое будет использоваться в SQL- запросах для идентификации нашей базы данных. Например, "ГВ_ЕМР".
* В выпадающем списке "Provider Name" выберите "LCPI OLE DB Provider for InterBase".
* Нажмите кнопку Options и установите галочку напротив пункта "Allow InProcess". Закройте это окно, нажав кнопку ОК.
* В поле "Data Source" нужно указать путь к базе данных. Например, main:e:\database\employee.gdb.
* В поле "Provider string" указываются остальные параметры подключения:
"use id=gamer, password=vermut; free_threading=true; truncate_char=false".
* Закройте диалог ввода параметров подключения.
Если все параметры были введены правильно, то, перейдя в дереве на элемент "SecurityYLinked Servers\IB_EMP\Tables", можно посмотреть на список таблиц базы данных "employers.gdb". Если при указании параметров подключения была допущена ошибка, связанный сервер нужно удалить (выбрав в его контекстном меню "Удалить") и повторить операцию регистрации с самого начала.
После того как источник данных был подключен в качестве связанного сервера к MS SQL, можно начать эксперименты с SQL-запросами. Для этого нужно открыть SQL Server Query Analyzer. Это можно сделать из меню "Tools" консоли управления MS SQL-серверами или через меню группы программ для работы с MS SQL, которое доступно через кнопку "Пуск" панели задач Windows.
В поле ввода SQL-запросов Query Analyzer можно вводить как одиночный текст запроса, так и группу запросов, используя точку с запятой в качестве разделителя. При наборе запросов нужно использовать синтаксис MS SQL, а не InterBase, поскольку последний переходит в ранг обычного носителя данных взаимодействие с которым осуществляется через OLE DB-интерфейсы и очень простые SQL-запросы.
Как уже было описано ранее, любая операция с данными базы InterBase, требует наличия активной транзакции. Поэтому самым первым SQL-запросом будет команда запуска транзакции:
MS SQL
BEGIN TRANSACTION;
После этого можно вводить SQL-запросы на выборку данных из источника данных IВ_ЕМР:
MS SQL
SELECT EMP.* FROM IB_EMP...EMPLOYEE EMP WHERE
EMP.JOB_CODE='Eng';
где IВ_ЕМР...EMPLOYEE представляет собой составное имя объекта, которое полностью идентифицирует его расположение в пространстве имен сервера баз данных MS SQL.
Теперь можно зарегистрировать любую другую базу данных InterBase, выполнив действия по аналогии с вышеописанными. В том числе никто не запрещает зарегистрировать несколько раз одну и ту же базу данных под разными псевдонимами, например ПЗ_ЕМР и Ю_ЕМР_1. Конечно, в качестве связанного сервера может использоваться любой другой OLE DB-поставщик данных, который поддерживает необходимую для процессора запросов функциональность.
Пример нахождения записей описания служащих источника данных Ш_ЕМР_1, отсутствующих в базе данных Ш_ЕМР:
MS SQL
SELECT EMP1.*
FROM IB_EMP_1...EMPLOYEE EMP1
WHERE NOT EXISTS(SELECT * FROM IB_EMP... EMPLOYEE EMP
WHERE EMP1.FIRST_NAME=EMP.FIRST_NAME AND
EMP1.LAST_NAME=EMP.LAST_NAME)
Если IB_ЕМР и IB_ЕМР_1 являются псевдонимами одной и той же базы, то результирующее множество этого SQL-запроса должно быть пустым.
При первом обращении к связанному источнику данных его сессия подключается к координатору распределенной транзакции, активизированному командой "BEGIN TRANSACTION" и для дальнейшей работы будет использоваться транзакция, принадлежащая сессии. В предыдущем примере для выполнения запроса к координатору транзакций будет подключено две сессии, каждая из которых содержит активную транзакцию. Поэтому, теоретически, если между запусками этих двух транзакций таблица EMPLOYEER будет изменена, результирующее множество может оказаться непустым. На практике, конечно, с одной базой через два различных псевдонима обычно не работают.
Поскольку в настоящий момент IB Provider (версия 1.6.2) не реализует OLE DB-интерфейсы модификации результирующих множеств, использование процессора запросов для выполнения запросов "INSERT ...", "UPDATE ...", "DELETE..." невозможно.
Заключение
В этой главе рассмотрены способы разработки клиентских приложений для InterBase 6.x и его клонов с помощью технологии OLEDB. Показаны основные подходы к разработке приложений баз данных InterBase с использованием таких популярных средств разработки компании Microsoft, как Visual Basic и Visual C++. Мощные и гибкие возможности, предоставляемые IBProvider, опровергают распространенное мнение, что InterBase - это сервер, с которым можно работать только с помощью средств разработки от компании Borland.
Создание CGI-приложений под ОС Linux с использованием InterBase API
Подавляющее количество CGI-приложений ориентировано на чтение данных и отображение полученных результатов в виде HTML. В общем виде вся работа приложения может быть описана следующей схемой:
* Чтение переменных, специфичных для WWW (разбор переменных html-форм и т. д.).
* Подключение к базе данных.
* Некоторое количество выборок и вставок (возможно, с исполнением хранимых процедур).
* Отключение от базы данных.
* Отправка данных клиенту.
Следует отметить, что часто пп. 4 и 5 меняются местами, например, при отображении данных в виде HTML-таблиц, построении отчетов и в прочих ситуациях, когда данных, полученных из базы данных, может быть много и хранение их в оперативной памяти вплоть до разрыва соединения нецелесообразно.
Также необходимо помнить, что, как правило, "тяжелые" запросы, которые могут выполняться несколько минут, в CGI-приложениях не используются; в случае употребления таких запросов браузер клиента считает, что произошел сбой соединения и сообщает об истечении времени ожидания.
Еще одной особенностью CGI-приложений является то, что практически всегда известно количество, наименование и тип входных и выходных параметров. Также обычно не возникает необходимости в обработке исключительных ситуаций, таких, как разрыв соединения во время работы с базой данных, так как пользователь, увидев в своем браузере пустой или некорректный результат, обычно ее обновляет, что дает возможность вновь выполнить запрос.
CGI-приложение является по сути прослойкой между Интернетом и базой данных, поэтому особое внимание следует уделять корректной работе с памятью и данными, которые приложение будет получать из Интернента. Самый лучший вариант - считать, что изначально будут посылаться некорректные данные, поэтому придется разработать эффективную защиту от "замусоривания".
При работе на уровне API дополнительный разбор текстовых переменных не производится - они попадают в базу данных в том виде, в каком хранятся в памяти скрипта. Таким образом, можно, например, хранить текст в различных кодировках в полях таблиц с CHARACTER SET NONE. Также не возникает проблем с одинарными или двойными кавычками.
Весь процесс создания CGI-приложения можно условно разделить на две части: сначала в общем виде создается шаблон HTML-документа, который должен получиться в результате работы, а затем необходимо реализовать собственно CGI-скрипт.
На начальном этапе написания приложения достаточно заменить переменные, которые в рабочей версии будут выбираться из присылаемых браузером запросов, на константы. Обычно всю отладочную информацию также выводят в результирующий HTML-документ - это позволяет легко отлаживать приложение. После того как основной алгоритм программы заработает, можно вместо констант обрабатывать непосредственно переменные из HTTP-запросов.
Специфика CGI-приложений предполагает, что в качестве SQL-сервера хорошо проявит себя архитектура SuperServer, которая обеспечивает хорошую производительность на множестве маленьких запросов при относительно небольшом объеме занимаемой памяти.
CGI-приложения можно писать на любом языке программирования - от С до Perl, где есть соответствующие библиотеки для работы с WWW.
Давайте рассмотрим написание CGI-приложения под ОС Linux с использованием языка C/C++, который производит откомпилированный код и избавляет от необходимости распространять приложения в исходных кодах, как в случае Perl или РНР. Все примеры в данной главе написаны на C/C++, однако легко могут быть переписаны под FPC/PERL/PHP.
В комплект поставки InterBase и его клонов входит заголовочный файл ibase.h с описанием функций InterBase API, констант, макросов и т. д., доступных разработчику клиентских приложений InterBase на C/C++. Написание приложений с использованием чистого API может показаться непривычно громоздким из-за высокой детализации кода приложения. Зная работу с базой данных на уровне InterBase API, можно довольно легко написать свою обертку вокруг API- функций или воспользоваться уже существующими (например, IBProvider из предыдущей главы).
Прежде чем перейти к рассмотрению реальных примеров, необходимо ввести следующие понятия:
Параметры запроса - это переменные, которые передаются серверу (входящие) или возвращаются в качестве результата (исходящие). В примерах эти переменные носят соответственно названия isqlda и osqlda.
Большинство IB API-функций возвращают так называемый STATUS_VECTOR - массив целых чисел (long). Анализируя этот массив, можно узнать, произошел ли вызов функции успешно, и если нет-то по какой причине.
В качестве параметров используется особая структура, XSQLDA - extended SQL Descriptor Area. Она позволяет \знать (или передать) всю необходимую информацию о каждом конкретном параметре, а также сами данные в структуре SQLVAR - SQL Variable. В силу изложенного выше при написании CGI- приложений интерес представляют лишь несколько полей из этих структур:
Структура XSQLDA, описывающая параметры запросов
|
Поле |
Тип (для языка С) |
Описание |
|
version |
short |
Версия XSQLDA-структуры; должна быть установлена в соответствии с версией используемой клиентской библиотеки. Для текущих версий InterBase это значение соответствует SQDA_VERSION1 |
|
sqln |
short |
Количество элементов массива sqlvar (иными словами, количество передаваемых и/или получаемых переменных). Это поле должно быть обязательно заполнено для входящих и исходящих параметров до передачи данных запроса серверу |
|
sqld |
short |
Указывает количество входящих или исходящих параметров. Обычно это поле для исходящих параметров инициализируется библиотекой InterBase. 0 в этом поле означает, что запрос не является выборкой (non-SELECT query) |
Структура SQLVAR, описывающая панные параметров структуры XSQLDA
|
|
|
|
|
|
Поле |
Тип (для языка С) |
Описание |
|
|
sqldata |
char* |
Указатель на данные, которые необходимо передать серверу |
|
|
sqltype |
short |
Информация о типе передаваемых данных. Для полей, допускающих SQL-значение NULL- используется тип, на единицу больший, чем базовый. Например, для типа SQL INTEGER используется значение SQL_LONG, если NULL не допускается, и тип SQLJ.ONG+1, если в значении поля допускается NULL |
|
|
sqllen |
short |
Размер памяти, занимаемой переменной, на которую указывает sqldata |
|
|
sqlind |
short * |
Это поле - индикатор того, является ли значение передаваемой переменной NULL (в этом случае это поле должно быть равно единице) или нет (в этом случае значение этого поля 0). Заполнение этого поля является обязательным, если переменная может принимать значение NULL. Таким образом, если вы хотите передать значение NULL серверу и в sqltype указан не базовый тип (например, SQLJ.ONG+1), то инициализировать это поле обязательно; если же указан, например тип SQL_LONG, то это поле можно не инициализировать - сервер проигнорирует его значение. При чтении данных из результата это поле указывает, является ли полученное значение NULL или отличается от него. Анализировать необходимо именно это поле - результат сравнения переменной sqldata с пустым значением может быть абсолютно непредсказуемым |
|
Подробнее все поля этих структур описаны в [7] и представляют интерес > только при написании действительно сложных приложений или библиотек.
Теперь, когда даны необходимые определения, можно непосредственно по* I знакомиться с методами DSQL-программирования. Их всего 4: I
Нет переменных ни на входе ни на выходе. В этом случае обе структуры * SQLDA (isqlda, osqlda) должны быть инициализированы NULL (или любым пустым указателем в используемом вами языке - например, nil в Паскале) в вызове функций isc_dsql_execute, isc_dsql_execute2 и т. д. Обычно это запросы, которые удаляют записи с жестко заданными свойствами.
* Есть переменные как на входе, так и на выходе; в этом случае нужно инициализировать соответствующие структуры.
* Нет переменных на выходе, но есть на входе; в этом случае osqlda = NULL, a isqlda требуется инициализировать.
* Нет переменных на входе, но есть на выходе; в этом случае isqlda = NULL, a osqlda требуется инициализировать.
Теперь примеры. Для простоты будем работать только с одной таблицей, структура которой описана ниже.
Пример 1. Запрос без параметров
Предположим, у нас есть таблица следующей структуры:
CREATE TABLE BOOKS (
B_ID INTEGER NOT NULL,
B_INDEX CHAR(16) NOT NULL,
B_NAME VARCHAR(80) NOT NULL,
B_AUTHOR VARCHAR(SO) NOT NULL,
B_ADDED TIMESTAMP DEFAULT 'now' NOT NULL,
B_THEME VARCHAR(60) NOT NULL);
Для того чтобы отобразить результат запроса "select b_id. b_index, b_name. b_authoi, b_added, b_theme from books" в виде следующей таблицы (см. Рис. 3.1):
Рис 3.1. Результат выполнения SQL-запроса, представленный в браузере в виде HTML- таблицы
понадобится следующий скрипт: (examplel.с)
#include
#include
#include
#include
#include
// Эта структура предназначена для хранения переменных типа SQL_VARYING
#define SQL_VARCHAR(len) struct {short vary_length; char
vary_string[(len)+1];}
int main (void){
/ / Константы, необходимые для работы с базой данных - инициализируйте их в
// соответствии с реальным путем к базе, пользователем и паролем
char *dbname = "localhost:/var/db/demo.gdb";
char *uname = "sysdba";
char *upass = "masterkey";
char *query = "select b_id, b_index, b_name, b_author, b_added,
b_theme from books";
/ / Переменные для работы с базой данных
isc_db_handle db_handle = NULL;
isc_tr_handle transaction_handle = NULL;
isc_stmt_handle statement_handle=NULL;
char dpb_buffer[256], *dpb, *p;
short dpb_length;
ISC_STATUS status_vector[20] ;
XSQLDA *isqlda, *osqlda;
long fetch_code;
short
o_ind[20]={0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0, 0,0);
/ / Остальные переменные
int i = 0;
long b_id;
char b_index[17];
SQL_VARC HAR(100) b_name;
SQL_VARCHAR(100) b_author;
SQL_VARCHAR(100) b_theme;
ISC_TIMESTAMP b_added;
struct tm added_time;
char decodedTime[100];
Здесь наше приложение начинает вывод стандартного HTML-документа:
printf("Content-type:
text/plain\n\n
SELECT
without input parameters") ;
а затем подключается к базе данных - здесь два этапа
// создаем так называемый database parameter buffer, необходимый
/ / для подключения к базе данных
dpb=dpb_buffer;
*dpb++ = isc_dpb_versionl;
*dpb++ = isc_dpb_user_name;
*dpb++ = strlen(uname);
for(p = uname; *p; ) *dpb++ = *p++;
*dpb++ = isc_dpb_password;
*dpb++ = strlen(upass);
for (p=upass; *p;) *dpb++ = *p++;
dpb_length = dpb dpb_buffer;
// Подключаемся к базе
isc_attach_database(
status_vector,
strlen(dbname),
dbname,
&db_handle,
dpb_length,
dpb_buffer) ;
Далее идет стандартная для большинства API-функций проверка и анализ результата:
if (status_vector[0] == 1 && status_vector[1]){
isc_print_status(status_vector) ;
return(1);
}
Если подключение к базе данных произошло удачно, начинается транзакция:
if (db_handle){
isc_start_transaction(
status_vector,
&transaction_handle,
1,
&db_handle,
0,
NULL);
if (status_vector[0] == 1 && status_vector[1]){
isc_print_status(status_vector);
return(1);
}
}
Далее инициализируются структуры, которые будут заполняться результатами запроса:
osqlda = (XSQLDA *)malloc(XSQLDA_LENGTH(6));
osqlda -> version = SQLDA_VERSION1;
osqlda -> sqln = 6;
osqlda->sqlvar[0].sqldata = (char *)&b_id;
osqlda->sqlvar[0].sqltype = SQL_LONG;
osqlaa->sqlvar[0].sqlind = &o_ind[0];
osqlda->sqlvar[1].sqldata = (char *)&b_index;
osqlda->sqlvar[1].sqltype = SQL_TEXT;
osqlda->sqlvar[1].sqlind = &o_ind[l];
osqlaa->sqlvar[2].sqldata = (char *)&b_name;
osqlda->sqlvar[2].sqltype = SQL_VARYING;
osqlda->sqlvar[2J .sqlind = ko_ind[2];
osqlda->sqlvar[3].sqldata = (char *)&b_author;
osqlda->sqlvar[3].sqltype = SQL_VARYING;
osqlda->sqlvar[3].sqlind = &o_ind[3];
osqlda->sqlvar[4].sqldata = (char *)&b_added;
osqlda->sqlvar[4].sqltype = SQL_TIMESTAMP;
osqlda->sqlvar[4].sqlind = &o_ind[4];
osqlda->sqlvar[5].sqldata = (char *)&b_theme;
osqlda->sqlvar[5].sqltype = SQL_VARYING;
osqlda->sqlvar[5].sqlind = &o_ind[5];
А вот здесь, собственно, и начинается подготовка к исполнению запроса сервером:
isc_dsql_allocate_statement(
status_vector,
&db_handle,
&statement_handle);
if (status_vector[0] == 1 && status_vector[1]){
isc_print_status(status_vector);
return(1);
}
isc_dsql_prepare(
status_vector,
&transaction_handle,
&scatement_handle,
0,
query,
SQL_DIALECT_V6,
osqlda);
if (status_vector[0] == 1 && status_vector[1]){
isc_print_status(status_vector);
return(1);
}
isc_dsql_execute2(
status_vector,
&transaction_handle,
&statement_handle,
1,
NULL,
NULL);
if (status_vector[0] == 1 && status_vector[1]){
isc_print_status(status_vector) ;
return(1);
}
Здесь начинается таблица HTML-документа. Ситуация, когда в базе данных может не оказаться данных, подробно анализируется во втором примере.
printf("
| Book
ID | CODE | TITLE | AUTHOR | ADDED | THEME ");
После исполнения запроса сервер готов к передаче данных. "Доставкой" данных !лнимаегся функция isc_dsql_tetch()' while((fetch_code = isc_dsql_fetch( status_vector, &statement_handle, 1, osqlda))= = 0) { Для строковых переменных требуется корректно установить длину, так как размер возвращаемых данных не всегда соответствуем максимально возможному, и если этого не сделать, то вместе с реальными данными можно получить' "мусор" из памяти или остатки предыдущих строк: b_index[osqlda->sqlvar[1].sgllen]= ' \0 ' ; b_name.vary_string[b_name.vary_length] = '\0' ; b_author.vary_string[b_author.vary_length]='\0'; b_theme.vary_string[b_theme.vary_length]='\0'; Структуру типа TIMESTAMP, как и структуры DATE/TIME, перед выводом в документ можно преобразовать в строковый тип в нужном формате. Для этого сначала она декодируется в структуру tm, а затем в строку: isc_decode_timestamp(&b_added,&added_time); strftime(decodedTime,sizeof(decodedTime),"%d-%b-%Y %H:%M",&added_t ime); printf(" |
| %i | %s | %s | %s | %s | %s |
if (status_vector[0] == 1 && status_vector[1]){
isc_print_status(status_vector);
return(1);
}
free(osqlda);
isc_dsql_free_statement(
status_vector,
&statement_handle,
DSQL_drop);
if (status_vector[0] == 1 && status_vector[1]){
isc_print_status(status_vector);
recurn(l);
}
Затем завершить транзакцию и отключиться от базы данных:
if (transaction_handle){isc_commit_transaction(status_vector,
&transaction_handle);}
if (status_vector[0] == 1 && status_vector[1]){
isc_print_status(status_vector);
return(1),
}
if (db_handle) isc_detach_database(status_vector, &db_handle);
if (status_vector[0] == 1 && status_vector[1]){
isc_print_status(status_vector) ;
return(1);
}
return(0);
}// end of main
Обратите внимание на маленькую разницу в работе с переменными SQLJVARYING и SQL_TEXT (это соответственно VARCHAR и CHAR языка SQL). Разница в том, что если в базе данных хранится меньше символов, чем максимально возможно для столбца (например, объявлено CHAR(16), а хранится строка "12345"), то сервер добавит N пробелов в конец строки, где N является' разницей между максимально возможным количеством символов и реально хра-1 нящимся в поле таблицы. Тип SQL_VARYING свободен от этого недостача,< однако при получении данных нужно учитывать, что только определенное зна-1 чение символов является реально полученными; остальное количество - это| случайные данные из памяти компьютера, на котором исполняется скрипт. Для | удобства работы с этим типом обычно определяют структуру, где член структу- \ ры SQL_VARCHAR vary_length указывает размер полученной строки,^ a vary_string собственно содержит строку.
Если запрос гарантированно возвращает одно значение (например, одиночный SELECT или вызов хранимой процедуры), то использовать функцию; isc_dsql_fetch() нет необходимости, вместо этого в параметр функции! isc_dsql_execute2() можно подставить значение osqlda переменной Работа с ти-1 пами SQL DATE и TIME абсолютно не отличается от работы с переменнымиii типа TIMESTAMP - всего лишь используются другие функции для преобразо-" вания: isc_decode_sql_date() и isc_decode_sql_time(). j
Пример 2. Запрос с параметрами
Теперь рассмотрим пример исполнения запроса с параметрами - вызов xpaнимой процедуры, которая просто вставит данные из формы в эту же таблицу.| Принципиально этот пример практически ничем не отличается от вышеприведенного, за исключением того что в нем появляются две дополнительные части - одна разбирает переменные HTML-формы, другая (если переменные переданы) исполняет процедуру.
Вот текст этой ХП.
create procedure InsertData (b_index char(16),
b_name varchar(80),
b_author varchar(80),
b_theme varchar(60))
returns (result_code integer)
as
begin
insert into books (
B_ID,B_INDEX,B_NAME, B_AUTHOR,B_ADDED,BJTHEME)
values(0,.b_index, :b_name, :b_author, 'now', :b_theme);
result_code = 0;
when any
do begin
result_code=-l;
end
end
Текст ХП достаточно банальный, вместо него в действительности можно было бы воспользоваться командой INSERT, однако подразумевается, что в реальной процедуре производятся некоторые манипуляции с входными данными (например, код книги может генерироваться не генератором, а по определенному алгоритму) и в качестве результата либо происходит вставка данных, либо процедура возвращает код ошибки.
Текст скрипта второго примера выглядит так :
#include
#include
#include
#include
#include
#include "cgic.h"
#define SQL_VARCHAR(len) struct {short vary_length; char
vary_string[(len)+1];}
Вот здесь некоторое отличие: используемая для разбора переменных www- библиотека заменяет стандартную функцию main:
int cgiMain (void){ '
char *dbname = "localhost:/var/db/demo.gdb";
char *uname = "sysdba";
char "upass = "masterkey";
char *qaery = "select b_id, b_index, b_name, b_author, b_added,
b_theme from books";
На месте неизвестных входящих параметров - знаки вопроса:
char *SPCall = "execute procedure insertdata (?,?,?,?)";
isc_db_handle db_handle = NULL;
isc_tr_handle transaction_handle = NULL;
isc_stmt_handle statement_handle=NULL;
char dpb_buffer[256], *dpb, *p;
short dpb_length;
ISC_STATUS status_vector[20];
XSQLDA *isqlda, *osqlda;
Long fetch_code;
Short
o_ind[20]={0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0);
int i = 0;
int hDisplayed=0;
int formVarErr;
int ExecSP=l;
long res_code;
long b_id;
char b_index[17];
SQL_VARCHAR(100) b_name;
SQL_VARCHAR(100) b_author;
SQL_VARCHAR (100) b_theme;
ISC_TIMESTAMP b_added;
struct tm added_time;
char decodedTime[100];
char form_b_index[17],
form_b_name[81],
form_b_author[81],
form_b_theme[61];
В этой части происходит анализ переменных, полученных скриптом, и в зависимости от метода вызова принимается решение, исполнять ли ХП или нет.
printf("Content-type:
text/plain\n\n width=\%> Part 1: Executable SP demo with both types of parameters. if(strcmp(cgiRequestMethod,"POST")==0){ formVarErr = cgiFormStringNoNewlines("b_index",form_b_index,17); if (formVarErr!=cgiFormSuccess){ printf(" ExecSP=0, } formVarErr = cgiFormStringNoNewlines("b_name",form_b_name,81); if {formVarErr!=cgiFormSuccess){ printf (" ExecSP=0; } formVarErr = cgiFormStringNoNewlines("b_author",form_b_author,81); if (formVarErr!=cgiFormSuccess){ printf (" ExecSP=0; } formVarErr = cgiFormStringNoNewlines("b_theme",form_b_theme,61); if (formVarErr!=cgiFormSuccess){ printf(" ExecSP=0; } } else{ ExecSP=0; printf (" must be POST"); } Заметьте: если специфика приложения требует того, чтобы определенные www-переменные обязательно присутствовали и удовлетворяли определенным условиям (например, учетные данные пользователя могут быть защищены контрольной суммой), то именно в этом месте приложение производит решение о целесообразности продолжения работы. 1 После разбора переменных идет непосредственно работа с базой данных: dpb=dpb_buffеr; *dpb++ = isc_dpb_versionl; *dpb++ = isc_dpb_user_name; *dpb++ = strlen(uname); for(p = uname; *p;) *dpb++ = *p++; *dpb++ = isc_dpb_password; *dpb++ = strlen(upass); for (p=upass; *p;) *dpb++ = *p++; dpb_length = dpb- dpb_buffer; isc_attach_database( status_vector, strlen(dbname), dbname, &db_handle, dpb_length, dpb_buffer); if (status_vector[0] == 1 && status_vector[1]){ isc_print_status(status_vector); return(1}; } if (db_handle){ isc_start_transaction( status_vector, &transaction_handle, 1, &db_handle, 0, NULL); if (status_vector[0] == 1 && status_vector[1]){ isc_print_status(status_vector); return(l); } } Если были получены данные и они корректны, происходит вызов хранимой процедуры: if(ExecSP){ printf(" parameters: ' %s' , '%s' , ' %s' , '%s'.....",form_b_index,form_b_name,form_b_a uthor,form_b_theme); Как можно видеть, принципиально инициализация структур для входящих параметров не сильно отличается от инициализации исходящих параметров из первого примера: isqlda = (XSQLDA *)malloc(XSQLDA_LENGTH(4)); isqlda->version = SQLDA_VERSION1; isqlda->sqln = 4; isqlda->sqld = 4; isqlda->sqlvar[0] .sqldata = (char *)&form_b_index; isqlda->sqlvar[0].sqltype = SQL_TEXT; isqlda->sqlvar[0].sqllen = strlen(form_b_index); isqlda->sqlvar [1] . sqldata = (char * ) &f orm_b_name, isqlda->sqlvar[1].sqltype = SQL_TEXT; isqlda->sqlvar[1].sqllen = strlen(form_b_name); isqlda->sqlvar[2].sqldata = (char *)&form_b_author; isqlda->sqlvar[2].sqltype = SQL_TEXT; isqlda->sqlvar[2].sqllen = strlen(form_b_author); isqlda->sqlvar[3].sqldata = (char *)&form_b_theme; isqlda->sqlvar[3].sqltype = SQL_TEXT; isqlda->sqlvar[3].sqllen = strlen(form_b_theme); osqlda = (XSQLDA *)malloc(XSQLDA_LENGTH(1)); osqlda -> version = SQLDA_VERSION1; osqlda -> sqln = 1; osqlda -> sqld = 1; osqlda->sqlvar[0].sqldata = (char *)&res_code; osqlda->sqlvar[0].sqltype = SQL_LONG; osqlda->sqlvar[0].sqllen = sizeof(long); osqlda->sqlvar[0].sqlind = &o_ind[0]; Вызов ХП происходит сразу, без предварительной подготовки (подробнее об этом будет рассказано несколько ниже): isc_dsql_exec_immed2( status_vector, &db_handle, &transaction_handle, 0, SPCall, SQL_DIALECT_V6, isqlda, osqlda}; if (status_vector[0] == 1 && status_vector[1]){ isc_print_status(status_vector) ; return(1); } if(res_code==0){ printf(" } else{ printf(" failed with result_code=%i.",res_code); } free(isqlda); free(osqlda); } Далее идет выборка данных из таблицы базы данных - это несколько модифицированная часть из первого примера, которая анализирует, были ли получены данные или таблица оказалось густой и отображать нечего. printf (" parameters osqlda = (XSQLDA *)malloc(XSQLDA_LENGTH(6)); osqlda -> version = SQLDA_VERSION1; osqlda -> sqln = 6; osqlda->sqlvar[0].sqldata = (char *)&b_id; osqlda->sqlvar[0].sqltype = SQL_LONG; osqlda->sqlvar[0].sqlind = &o_ind[0]; osqlda->sqlvar[1].sqldata = (char *)&b_index; osqlda->sqlvar[1].sqltype = SQL_TEXT; osqlda->sqlvar[1].sqlind = &o_ind[l]; osqlda->sqlvar[2].sqldata = (char *)&b_name; osqlda->sqlvar[2].sqltype = SQLJVARYING; osqlda->sqlvar[2].sqlind = &o_ind[2]; osqlda->sqlvar[3].sqldata = (char *)&b_author; osqlda->sqlvar[3].sqltype = SQL_VARYING; osqlda->sqlvar[3].sqlind = &o_ind[3]; osqlda->sqlvar[4].sqldata = (char *)&b_added; osqlda->sqlvar[4].sqltype = SQL_TIMESTAMP; osqlda->sqlvar[4].sqlind = &o_ind[4]; osqlda->sqlvar[5].sqldata = (char *)&b_theme; osqlda->sqlvar[5].sqltype = SQL_VARYING; osqlda->sqlvar[5].sqlind = &o_ind[5]; isc_dsql_allocate_statement( status_vector, &db_handle, &statement_handle); if (stacus_vector[0] == 1 && status_vector[1]){ isc_print_status(status_vector); return{1); } isc_dsql_prepare( status_vector, &transaction_handle, &statement_handle, 0, query, SQL_DIAL,ECT_Y6, osqlda); if (status_vector [ 0] == 1 && status_vector[1]) { isc_print_status(status_vector) ; return(1); } Заметьте, что если бы запрос гарантированно возвращал одну запись, то надобность в вызове функции isc_dsql_fetch()oтпaлa бы, а на месте последних двух пустых значений в вызове нижеследующей функции были бы соответственно isqlda и osqlda: isc_dsql__execute2 ( status_vector, &transaction_handle, &statement_handle, 1, NULL, NULL); if (status_vector[0] == 1 && status_vector[1]){ isc_print_status (status_vector); return(1); } while((fetch_code = isc_dsql_fetch( status_vector, &staternent .handle, 1, osqlda))==0) { Вот здесь и производится проверка на существование хотя бы одной записи в таблице: if (!hDisplayed){ hDisplayed=l; printf (" cellpadding=l cellspacing=l> } Далее идет уже знакомая по предыдущему примеру обработка текстовых переменных: b_index[osqlda->sqlvar[1].sqllen]='\0'; b_name.vary_string[b_name.vary_length]='\0'; b_author.vary_string[b_author.vary_length]='\0'; b_theme.vary_string[b_theme.vary_length]='\0'; и преобразование TIMESTAMP в удобочитаемое выражение: isc_decode_timestamp(&b_added,&added_time); strftime(decodedTime,sizeof(decodedTime),"%d-%b-%Y %H: %M", &added_t ime) ; printf(" b_id, b_index, b_name.vary_string, b_author.vary_string, decodedTime, b_theme.vary_string); } if (status_vector[0] == 1 && status_vector[1]){ isc_print_status(status_vector); return(1); } free(osqlda); isc_dsql_free_statement( status_vector, &statement_handle, DSQL_drop); if (scacus_vector[0] == 1 && status_vector[1]){ isc_print_status(status_vector) ; return(1); } Завершаем транзакцию и отключаемся от базы данных: if (transaction_handle){ isc_commit_transaction(status_vector, &transaction_handle); } if (status_vector[0] == 1 && status_vector[1]){ isc_pnnt_status (status_vector) ; return(1); } if (db_handle) isc_detach_database(status_vector, &db_handle); if (status_vector[0] == 1 && status_vector[1]){ isc_print_status(status_vector); return(1); } Завершаем документ HTML-формой для ввода данных: if(hDisplayed){ printf(" } else{ printf (" empty
");
Error: Book index missed or too long");
Error: Book author missed or too long");
Error: Book theme missed or too long");
Attempt to call SP with the following
");
Book ID CODE TITLE AUTHOR
ADDED %i %s %s
%s %s %s
");
") ;
}
printf ( " align=right>"};
printf ("