Часть IV Дополнительные темы
Глава 22 Идеалы и история
Когда кто-то говорит: “Мне нужен такой язык
программирования, которому достаточно
просто сказать, его я хочу”,
дайте ему леденец.
Алан Перлис (Alan Perlis)
В этой главе очень кратко и выборочно изложена история языков программирования и описаны идеалы, во имя которых они были разработаны. Эти идеалы и выражающие их языки программирования образуют основу профессионализма. Поскольку в настоящей книге используется язык С++, мы сосредоточили свое внимание именно на нем, а также на языках, появившихся под его влиянием. Цель этой главы — изложить основы и перспективы развития идей, представленных в книге. Описывая каждый из языков, мы рассказываем о его создателе или создателях: язык — это не просто абстрактное творение, но и конкретное решение, найденное людьми для стоявших перед ними проблем в определенный момент времени.
22.1. История, идеалы и профессионализм
 История — это чушь”, — безапелляционно заявил Генри Форд (Henry Ford). Противоположное мнение широко цитируется еще с античных времен: “Тот, кто не знает историю, обречен повторить ее”. Проблема заключается в том, чтобы выбрать, какую историю следует знать, а какую следует отбросить: другое известное изречение утверждает, что “95% всей информации — это чушь” (со своей стороны заметим, что 95%, вероятно, являются преуменьшенной оценкой). Наша точка зрения на связь истории с современностью состоит в том, что без понимания истории невозможно стать профессионалом. Люди, очень мало знающие предысторию своей области знаний, как правило, являются легковерными, поскольку история любого предмета замусорена правдоподобными, но не работоспособными идеями. “Плоть” истории состоит из идей, ценность которых доказывается практикой.
История — это чушь”, — безапелляционно заявил Генри Форд (Henry Ford). Противоположное мнение широко цитируется еще с античных времен: “Тот, кто не знает историю, обречен повторить ее”. Проблема заключается в том, чтобы выбрать, какую историю следует знать, а какую следует отбросить: другое известное изречение утверждает, что “95% всей информации — это чушь” (со своей стороны заметим, что 95%, вероятно, являются преуменьшенной оценкой). Наша точка зрения на связь истории с современностью состоит в том, что без понимания истории невозможно стать профессионалом. Люди, очень мало знающие предысторию своей области знаний, как правило, являются легковерными, поскольку история любого предмета замусорена правдоподобными, но не работоспособными идеями. “Плоть” истории состоит из идей, ценность которых доказывается практикой.
 Мы бы с удовольствием поговорили о происхождении ключевых идей, лежащих в основе многих языков программирования и разных видов программного обеспечения, таких как операционные системы, базы данных, графические системы, сети, веб, сценарии и так далее, но эти важные и полезные приложения можно найти повсюду. Места, имеющегося в нашем распоряжении, едва хватает лишь для того, чтобы хотя бы поверхностно описать идеалы и историю языков программирования.
Мы бы с удовольствием поговорили о происхождении ключевых идей, лежащих в основе многих языков программирования и разных видов программного обеспечения, таких как операционные системы, базы данных, графические системы, сети, веб, сценарии и так далее, но эти важные и полезные приложения можно найти повсюду. Места, имеющегося в нашем распоряжении, едва хватает лишь для того, чтобы хотя бы поверхностно описать идеалы и историю языков программирования.
 Конечная цель программирования заключается в создании полезных систем. В горячке споров о методах и языках программирования об этом легко забыть. Помните об этом! Если вам требуется напоминание, перечитайте еще раз главу 1.
Конечная цель программирования заключается в создании полезных систем. В горячке споров о методах и языках программирования об этом легко забыть. Помните об этом! Если вам требуется напоминание, перечитайте еще раз главу 1.
22.1.1. Цели и философия языка программирования
Что такое язык программирования? Для чего он предназначен? Ниже приводятся распространенные варианты ответа на первый вопрос.
• Инструмент для инструктирования машин.
• Способ записи алгоритмов.
• Средство общения программистов.
• Инструмент для экспериментирования.
• Средство управления компьютеризированными устройствами.
• Способ выражения отношения между понятиями.
• Средство выражения проектных решений высокого уровня.
Наш ответ таков: “Все вместе и еще больше!” Очевидно, что здесь речь идет об универсальных языках программирования. Кроме них существуют специализированные и предметно-ориентированные языки программирования, предназначенные для более узких и более точно сформулированных задач. Какие свойства языка программирования считаются желательными?
• Переносимость.
• Типовая безопасность.
•Точная определенность.
• Высокая производительность.
• Способность точно выражать идеи.
• Легкая отладка.
• Легкое тестирование.
• Доступ ко всем системным ресурсам.
• Независимость от платформы.
• Возможность выполнения на всех платформах.
• Устойчивость на протяжении десятилетий.
• Постоянное совершенствование в ответ на изменения, происходящие в прикладной области.
• Легкость обучения.
• Небольшой размер.
• Поддержка популярных стилей программирования (например, объектно-ориентированного и обобщенного программирования).
• Возможность анализа программ.
• Множество возможностей.
• Поддержка со стороны крупного сообщества.
• Поддержка со стороны новичков (студентов, учащихся).
• Исчерпывающие возможности для экспертов (например, конструкторов инфраструктуры).
• Доступность большого количества инструментов для разработки программ.
• Доступность большого количества компонентов программного обеспечения (например, библиотек).
• Поддержка со стороны сообщества разработчиков открытого кода.
• Поддержка со стороны поставщиков основных платформ (Microsoft, IBM и т.д.).
К сожалению, все эти возможности нельзя получить одновременно. Это досадно, поскольку каждое из этих свойств объективно является положительным: каждое из них приносит пользу, а язык, не имеющий этих свойств, вынуждает программистов выполнять дополнительную работу и осложняет им жизнь. Причина, из-за которой невозможно получить все эти возможности одновременно, носит фундаментальный характер: некоторые из них являются взаимоисключающими. Например, язык не может полностью не зависеть от платформы и в то же время открывать доступ ко всем системным ресурсам; программа, обращающаяся к ресурсу, не существующему на конкретной платформе, не сможет на ней работать вообще. Аналогично, мы очевидно хотели бы, чтобы язык (а также инструменты и библиотеки, необходимые для его использования) был небольшим и легким для изучения, но это противоречит требованию полной поддержки программирования на всех системах и в любых предметных областях.
Идеалы в программировании играют важную роль. Они служат ориентирами при выборе технических решений и компромиссов при разработке каждого языка, библиотеки и инструмента, который должен сделать проектировщик. Да, когда вы пишете программы, вы играете роль проектировщика и должны принимать проектные решения.
22.1.2. Идеалы программирования
Предисловие к книге The C++ Programming Language начинается со слов: “Язык C++ — универсальный язык программирования, разработанный для того, чтобы серьезные программисты получали удовольствие от работы”. Что это значит? Разве программирование не предусматривает поставку готовой продукции? А почему ничего не сказано о правильности, качестве и сопровождении программ? А почему не упомянуто время от начального замысла новой программы до ее появления на рынке? А разве поддержка разработки программного обеспечения не важна? Все это, разумеется, тоже важно, но мы не должны забывать о программисте. Рассмотрим другой пример. Дональд Кнут (Don Knuth) сказал: “Самое лучшее в компьютере Alto то, что он ночью не работает быстрее”. Alto — это компьютер из центра Xerox Palo Alto Research Center (PARC), бывший одним из первых персональных компьютеров. Он отличался от обычных компьютеров, предназначенных для совместного использования и провоцировавших острое соперничество между программистами за дневное время работы.
Наши инструменты и методы программирования предназначены для того, чтобы программист работал лучше и достигал более высоких результатов. Пожалуйста, не забывайте об этом. Какие принципы мы можем сформулировать, чтобы помочь программисту создавать наилучшее программное обеспечение с наименьшими затратами энергии? Мы уже выражали наше мнение по всей книге, поэтому этот раздел по существу представляет собой резюме.
Основная причина, побуждающая нас создавать хорошую структуру кода, — стремление вносить в него изменения без излишних усилий. Чем лучше структура, тем легче изменить код, найти и исправить ошибку, добавить новое свойство, настроиться на новую архитектуру, повысить быстродействие программы и т.д. Именно это мы имеем в виду, говоря “хорошо”.
В оставшейся части раздела мы рассмотрим следующие вопросы.
• Что мы хотим от кода?
• Два общих подхода к разработке программного обеспечения, сочетание которых обеспечивает лучший результат, чем использование по отдельности.
• Ключевые аспекты структуры программ, выраженные в коде.
• Непосредственное выражение идей.
• Уровень абстракции.
• Модульность.
• Логичность и минимализм.
Идеалы должны воплощаться в жизнь. Они являются основой для размышлений, а не просто забавными фразами, которыми перекидываются менеджеры и эксперты. Наши программы должны приближаться к идеалу. Когда мы заходим в тупик, то возвращаемся назад, чтобы увидеть, не является ли наша проблема следствием отступления от принципов (иногда это помогает). Когда мы оцениваем программу (желательно еще до ее поставки пользователям), мы ищем нарушение принципов, которые в будущем могут вызвать проблемы. Применяйте идеалы как можно чаще, но помните, что практичные концепции (например, производительность и простота), а также слабости языка (ни один язык не является совершенным) часто позволяют лишь достаточно близко приблизиться к идеалу, но не достичь его.
Идеалы могут помочь нам принять конкретные технические решения. Например, мы не можем принять решение о выборе интерфейса для библиотеки самолично и в полной изоляции (см. раздел 14.1). В результате может возникнуть путаница. Вместо этого мы должны вспомнить о нашем первом принципе и решить, что именно является важным для данной конкретной библиотеки, а затем создать логичный набор интерфейсов. А главное — следовало бы сформулировать принципы проектирования и принятия компромиссных решений для каждого проекта в его документации и прокомментировать их в коде.
Начиная проект, обдумайте принципы и посмотрите, как они связаны с задачами и ранее существующими решениями вашей задачи. Это хороший способ выявления и уточнения идей. Когда позднее, на этапе проектирования и программирования, вы зайдете в тупик, вернитесь назад и найдите место, где ваш код отклонился от идеалов, — именно там, вероятнее всего, кроются ошибки и возникают проблемы, связанные с проектированием. Этот подход является альтернативой методу отладки, принятому по умолчанию, когда программист постоянно проверяет одно и то же место с помощью одного и того же метода поиска ошибок. “Ошибка всегда кроется там, где вы ее не ожидаете, — или вы ее уже нашли”.
22.1.2.1. Чего мы хотим?
Как правило, мы хотим следующего.
• Правильность. Да, очень трудно определить, что мы имеем в виду под словом “правильный”, но это важная часть работы. Часто это понятие в рамках конкретного проекта определяют для нас другие люди, но в этом случае мы должны интерпретировать то, что они говорят.
• Легкость сопровождения. Любая успешная программа со временем изменяется; она настраивается на новое аппаратное обеспечение и платформу, дополняется новыми возможностями и при этом из нее необходимо удалить новые ошибки. В следующих разделах мы покажем, как структура программы позволяет достичь этого.
• Производительность. Производительность (эффективность) — понятие относительное. Она должна быть адекватной цели программы. Часто программисты утверждают, что эффективный код по необходимости должен быть низкоуровневым, а высокоуровневая структура ухудшает эффективность программы. В противоположность этому мы считаем, что следование рекомендуемым нами принципам часто позволяет обеспечивать высокую эффективность кода. Примером такого кода является библиотека STL, которая одновременно является абстрактной и очень эффективной. Низкая производительность часто может быть следствием как чрезмерного увлечения низкоуровневыми деталями, так и пренебрежения ими.
• Своевременная поставка. Поставка совершенной программы на год позже запланированного срока — не слишком хорошее событие. Очевидно, что люди хотят невозможного, но мы должны создать качественное программное обеспечение за разумный срок. Бытует миф, утверждающий, что законченная в срок программа не может быть высококачественной. В противоположность этому мы считаем, что упор на хорошую структуру (например, управление ресурсами, инварианты и проект интерфейса), ориентация на тестирование и использование подходящих библиотек (часто разработанных для конкретных приложений или предметных областей) позволяют полностью уложиться в сроки.
Все сказанное стимулирует наш интерес к структуре кода.
• Если в программе есть ошибка (каждая большая программа содержит ошибки), то найти ее легче, если программа имеет четкую структуру.
• Если программу необходимо объяснить постороннему или как-то модифицировать, то четкую структуру понять намного легче, чем мешанину низкоуровневых деталей.
• Если программа испытывает проблемы с производительностью, то настроить высокоуровневую программу, как правило, намного легче (поскольку она точнее соответствует общим принципам и имеет хорошо определенную структуру), чем низкоуровневую. Для начинающих программистов высокоуровневая структура намного понятнее. Кроме того, высокоуровневый код намного легче тестировать и настраивать, чем низкоуровневый.
Программа обязательно должна быть понятной. Хорошим считается все, что помогает нам понимать программу и размышлять о ней. В принципе порядок лучше беспорядка, если только порядок не является результатом чрезмерного упрощения.
22.1.2.2. Общие подходы
Существуют два подхода к созданию правильного программного обеспечения.
• Снизу–вверх. Система компонуется только из составляющих частей, правильность которых уже доказана.
• Сверху–вниз. Система компонуется из составляющих частей, предположительно содержащих ошибки, а затем вылавливаются все ошибки.
Интересно, что наиболее надежные системы созданы с помощью сочетания обоих подходов, хотя они очевидным образом противоречат друг другу. Причина проста: для крупных реальных систем ни один из этих подходов не гарантирует требуемой правильности, адаптируемости и удобства сопровождения.
• Мы не можем создать и проверить основные компоненты, заранее устранив все источники ошибок.
• Мы не можем полностью компенсировать недостатки основных компонентов (библиотек, подсистем, иерархий классов и т.д.), объединив их в законченную систему.
Однако сочетание этих двух подходов может дать больше, чем каждый из них по отдельности: мы можем создать (или позаимствовать, или приобрести) компоненты, имеющие достаточно высокое качество, так что остальные проблемы можно устранить с помощью обработки ошибок и систематического тестирования. Кроме того, если мы продолжаем создавать все более хорошие компоненты, то из них можно создавать все большие части системы, сокращая долю необходимого “беспорядочного специального” кода.
Тестирование является существенной частью разработки программного обеспечения. Более подробно оно обсуждается в главе 26. Тестирование — это систематический поиск ошибок. Тестируйте как можно раньше и как можно чаще. Например, мы пытаемся разрабатывать наши программы так, чтобы упростить тестирование и помешать ошибкам скрыться в запутанном коде.
22.1.2.3. Непосредственное выражение идей
Когда мы выражаем какую-то идею — высоко- или низкоуровневую, — желательно выразить ее непосредственно в коде, а не устранять проблему обходным путем. Основной принцип выражения идей непосредственно в коде имеет несколько специфических вариантов.
• Выражение идей непосредственно в коде. Например, аргумент лучше представлять с помощью специального типа (например,
MonthColorint• Независимое представление в коде независимых идей. Например, за некоторым исключением, стандартная функция
sort()Objectbefore()vector::sort()sort()• Представление отношений между идеями непосредственно в коде. Наиболее общими отношениями, которые можно непосредственно выразить в коде, являются наследование (например, класс
CircleShapevector• Свободное сочетание идей, выраженных в коде, там и только там, где такая комбинация имеет смысл. Например, функция
sort()<sort()• Простое выражение простых идей. Следование принципам, сформулированным выше, может привести к созданию кода, носящего слишком общий характер. Например, мы можем столкнуться с иерархией классов с более сложной таксономией (структурой наследования), чем требуется, или с семью параметрами для каждого (очевидно) простого класса. Для того чтобы избежать возможных осложнений, мы пытаемся создавать простые версии для наиболее распространенных или наиболее важных ситуаций. Например, кроме общей версии функции
sort(b,e,op)opsort(b,e)sort(c)sort(c,op)op22.1.2.4. Уровень абстракции
Мы предпочитаем работать на максимально возможном уровне абстракции, иначе говоря, стремимся выражать свои решения в как можно более общем виде.
Рассмотрим, например, как представлены записи в телефонной книге, которая может храниться в вашем мобильном телефоне. Мы могли бы представить множество пар (имя, значение) с помощью класса
vector> mapvector> string[max]Value_type[max]intvoid*PhonebookPhonebook Причина, по которой мы предпочитаем оставаться на высоком уровне абстракции (если в нашем распоряжении есть соответствующий механизм абстракций и наш язык поддерживает его на приемлемом уровне эффективности), заключается в том, что такие формулировки ближе к нашим размышлениям о задаче и ее решениях, чем решения, выраженные в терминах аппаратного обеспечения компьютера.
Как правило, основной причиной перехода на низкий уровень абстракции называют эффективность. Однако это следует делать только в случае реальной необходимости (раздел 25.2.2). Использование низкоуровневых (более примитивных) языковых свойств не всегда повышает производительность программы. Иногда оно исключает возможности оптимизации. Например, используя класс
Phonebookstring[max]Value_type[max]map22.1.2.5. Модульность
Модульность — это принцип. Мы хотим составлять наши системы из компонентов (функций, классов, иерархий классов, библиотек и т.д.), которые можно создавать, анализировать и тестировать по отдельности. В идеале нам также хотелось бы проектировать и реализовывать такие компоненты таким образом, чтобы их можно было использовать в нескольких программах (повторно). Повторное использование (reuse) — это создание систем из ранее протестированных компонентов, которые уже были использованы где-то, а также проектирование и применение таких компонентов. Мы уже касались этой темы, обсуждая классы, иерархии классов, проектирование интерфейсов и обобщенное программирование. Большинство из того, что мы говорили о стилях программирования в разделе 22.1.3, связано с проектированием, реализацией и использованием компонентов, допускающих повторное использование. Следует подчеркнуть, что не каждый компонент можно использовать в нескольких программах; некоторые программы являются слишком специализированными, и их нелегко приспособить для использования в других условиях.
Модульность кода должна отражать основные логические разделы приложения. Не следует повышать степень повторного использования, просто погружая два совершенно разных класса А и В в повторно используемый компонент C. Объединение интерфейсов классов A и B в новом модуле C усложняет код.

Здесь оба пользователя используют модуль С. Пока вы не заглянете внутрь модуля С, вы можете подумать, что оба пользователя получают преимущества благодаря тому, что совместно используют общедоступный компонент. Выгоды от совместного использования (повторного) могут (в данном случае этого не происходит) включать в себя более легкое тестирование, меньший объем кода, расширения пользовательской базы и т.д. К сожалению, за исключением случая излишнего упрощения, это не редкая ситуация.
Чем можно помочь? Может быть, следует создать общий интерфейс классов А и В?

Эти диаграммы подсказывают, что следует использовать наследование и параметризацию соответственно. В обоих случаях, для того чтобы работа имела смысл, интерфейс должен быть меньше, чем простое объединение интерфейсов классов А и В. Иначе говоря, для того чтобы пользователь получил выгоду от принятого решения, классы А и В должны иметь фундаментальную общность. Обратите внимание на то, что мы снова вернулись к интерфейсам (см. разделы 9.7 и 25.4.2) и, как следствие, к инвариантам (см. раздел 9.4.3).
22.1.2.6. Логичность и минимализм
Логичность и минимализм — основные принципы выражения идей. Следовательно, мы можем забыть о них, как о вопросах, касающихся внешней формы. Однако запутанный проект очень трудно реализовать элегантно, поэтому требование логичности и минимализма можно рассматривать как критерии проектирования, влияющие на большинство мельчайших деталей программы.
• Не добавляйте свойство, если сомневаетесь в его необходимости.
• Похожие свойства должны иметь похожие интерфейсы (и имена), но только если их сходство носит фундаментальный характер.
• Непохожие свойства должны иметь непохожие имена (и по возможности разные интерфейсы), но только если их различие носит фундаментальный характер
Логичное именование, стиль интерфейса и стиль реализации облегчают эксплуатацию программы. Если код логичен, то программист не будет вынужден изучать новый набор соглашений, касающихся каждой части крупной системы. Примером является библиотека STL (см. главы 20-21, раздел Б.4–6). Если обеспечить логичность не удается (например, из-за наличия старого кода или кода, написанного на другом языке), то целесообразно создать интерфейс, который обеспечит согласование стиля с остальной частью программы. В противном случае этот чужеродный (“странный”, “плохой”) код “заразит” каждую часть программы, вынужденную к нему обращаться.
Для того чтобы обеспечить минимализм и логичность, следует тщательно (и последовательно) документировать каждый интерфейс. В этом случае легче будет заметить несогласованность и дублирование кода. Документирование предусловий, постусловий и инвариантов может оказаться особенно полезным, поскольку оно привлекает внимание к управлению ресурсами и сообщениям об ошибках. Логичная обработка ошибок и согласованная стратегия управления ресурсами играют важную роль для обеспечения простоты программы (см. раздел 19.5).
Некоторые программисты придерживаются принципа проектирования KISS (“Keep It Simple, Stupid” — “Делай проще, тупица”). Нам даже доводилось слышать, что принцип KISS — единственный стоящий принцип проектирования. Однако мы предпочитаем менее вызывающие формулировки, например “Keep simple things simple” (“Не усложняй простые вещи”) и “Keep it simple: as simple as possible, but no simpler” (“Все должно быть как можно более простым, но не проще”). Последнее высказывание принадлежит Альберту Эйнштейну (Albert Einstein). Оно подчеркивает опасность чрезмерного упрощения, выходящего за рамки здравого смысла и разрушающего проект. Возникает очевидный вопрос: “Просто для кого и по сравнению с чем?”
22.1.3. Стили и парадигмы
Когда мы проектируем и реализуем программы, мы должны придерживаться последовательного стиля. Язык С++ поддерживает четыре главных стиля, которые можно считать фундаментальными.
• Процедурное программирование.
• Абстракция данных.
• Объектно-ориентированное программирование.
• Обобщенное программирование.
Иногда их называют (несколько помпезно) парадигмами программирования. Существует еще несколько парадигм, например: функциональное программирование (functional programming), логическое программирование (logic programming), продукционное программирование (rule-based programming), программирование в ограничениях (constraints-based programming) и аспектно-ориентированное программирование (aspect-oriented programming). Однако язык С++ не поддерживает эти парадигмы непосредственно, и мы не можем охватить их в одной книге, поэтому откладываем эти вопросы на будущее.
• Процедурное программирование. Основная идея этой парадигмы — составлять программу из функций, применяемых к аргументам. Примерами являются библиотеки математических функций, таких как
sqrt()cos()struct• Абстракция данных. Основная идея этой парадигмы — сначала создать набор типов для предметной области, а затем писать программы для их использования. Классическим примером являются матрицы (разделы 24.3–24.6). Интенсивно используется явное сокрытие данных (например, использование закрытых членов класса). Распространенными примерами абстракции данных являются стандартные классы
stringvector• Объектно-ориентированное программирование. Основная идея этой парадигмы программирования — организовать типы в иерархии, чтобы выразить их отношения непосредственно в коде. Классический пример — иерархия Shape, описанная в главе 14. Этот подход имеет очевидную ценность, когда типы действительно имеют иерархические взаимоотношения. Однако существует сильная тенденция к его избыточному применению; иначе говоря, люди создают иерархии типов, не имея на это фундаментальных причин. Если люди создают производные типы, то задайте вопрос: “Зачем?” Что выражает это выведение? Чем различие между базовым и производным классом может мне помочь в данном конкретном случае?
• Обобщенное программирование. Основная идея этой парадигмы программирования — взять конкретные алгоритмы и поднять их на более высокий уровень абстракции, добавив параметры, позволяющие варьировать типы без изменения сущности алгоритма. Простым примером такого повышения уровня абстракции является функция
high()find()sort() Итак, подведем итоги! Часто люди говорят о стилях программирования (парадигмах) так, будто они представляют собой противоречащие друг другу альтернативы: либо вы используете обобщенное программирование, либо объектно-ориентированное. Если хотите выразить решения задач наилучшим образом, то используйте комбинацию этих стилей. Выражение “наилучшим образом” означает, что вашу программу легко читать, писать, легко эксплуатировать и при этом она достаточно эффективна.
Рассмотрим пример: классический класс
Shapevoid draw_all(vector& v) { for(int i = 0; idraw(); }Этот фрагмент кода действительно выглядит “довольно объектно-ориентированным”. Он основан на иерархии классов и вызове виртуальной функции, при котором правильная функция
draw()ShapeCircleCircle::draw()Open_polylineOpen_polyline::draw()vectorvoid draw_all(vector& v) { for_each(v.begin(),v.end(),mem_fun(&Shape::draw));}Третьим аргументом функции
for_each()f(x)p–>f()Shape::draw()mem_fun()for_each()mem_fun()mem_fun() Зачем же мы написали вторую версию примера для рисования всех фигур? По существу, она не отличается от первой, к тому же на несколько символов длиннее! В свое оправдание укажем, что выражение концепции цикла с помощью функции
for_each()forfor_each()template void draw_all(Iter b, Iter e) { for_each(b,e,mem_fun(&Shape::draw));}Теперь этот код работает со всеми видами последовательностей фигур. В частности, мы можем даже вызвать его для всех элементов массива объектов класса
ShapePoint p(0,100);Point p2(50,50);Shape* a[] = { new Circle(p,50), new Triangle(p,p2,Point(25,25)) };draw_all(a,a+2);За неимением лучшего термина мы называем программирование, использующее смесь наиболее удобных стилей, мультипарадигменным (multi-paradigm programming).
22.2. Обзор истории языков программирования
На заре человечества программисты высекали нули и единицы на камнях! Ну хорошо, мы немного преувеличили. В этом разделе мы вернемся к началу (почти) и кратко опишем основные вехи истории языков программирования в аспекте их связи с языком С++.
Существует много языков программирования. Они появляются со скоростью примерно 2000 языков за десять лет, впрочем скорость их исчезновения примерно такая же. В этом разделе мы вспомним о десяти языках, изобретенных за последние почти шестьдесят лет. Более подробную информацию можно найти на веб-странице http://research.ihost.com/hopl/HOPL.html, там же имеются ссылки на все статьи, опубликованные на трех конференциях ACM SIGPLAN HOPL (History of Programming Languages — история языков программирования). Эти статьи прошли строгое рецензирование, а значит, они более полны и достоверны, чем среднестатистические источники информации в сети веб. Все языки, которые мы обсудим, были представлены на конференциях HOPL. Набрав полное название статьи в поисковой веб-машине, вы легко ее найдете. Кроме того, большинство специалистов по компьютерным наукам, упомянутых в этом разделе, имеют домашние страницы, на которых можно найти больше информации об их работе.
Мы вынуждены приводить только очень краткое описание языков в этой главе, ведь каждый упомянутый язык (и сотни не упомянутых) заслуживает отдельной книги. В каждом языке мы выбрали только самое главное. Надеемся, что читатели воспримут это как приглашение к самостоятельному поиску, а не подумают: “Вот и все, что можно сказать о языке Х!”. Напомним, что каждый упомянутый здесь язык был в свое время большим достижением и внес важный вклад в программирование. Просто из-за недостатка места мы не в состоянии отдать этим языкам должное, но не упомянуть о них было бы совсем несправедливо. Мы хотели бы также привести несколько строк кода на каждом из этих языков, но, к сожалению, для этого не хватило места (см. упр. 5 и 6).
Слишком часто об артефактах (например, о языках программирования) говорят лишь, что они собой представляют, или как о результатах анонимного процесса разработки. Это неправильное изложение истории: как правило, особенно на первых этапах, на язык влияют идеи, место работы, личные вкусы и внешние ограничения одного человека или (чаще всего) нескольких людей. Таким образом, за каждым языком стоят конкретные люди. Ни компании IBM и Bell Labs, ни Cambridge University, ни другие организации не разрабатывают языки программирования, их изобретают люди, работающие в этих организациях, обычно в сотрудничестве со своими друзьями и коллегами.
Стоит отметить курьезный феномен, который часто приводит к искаженному взгляду на историю. Фотографии знаменитых ученых и инженеров часто делались тогда, когда они уже были знаменитыми и маститыми членами национальных академий, Королевского общества, рыцарями Святого Джона, лауреатами премии Тьюринга и т.д. Иначе говоря, на фотографиях они на десятки лет старше, чем в те годы, когда они сделали свои выдающиеся изобретения. Почти все они продуктивно работали до самой глубокой старости. Однако, вглядываясь в далекие годы возникновения наших любимых языков и методов программирования, попытайтесь представить себе молодого человека (в науке и технике по-прежнему слишком мало женщин), пытающегося выяснить, хватит ли у него денег для того, чтобы пригласить свою девушку в приличный ресторан, или отца молодого семейства, решающего, как совместить презентацию важной работы на конференции с отпуском. Седые бороды, лысые головы и немодные костюмы появятся много позже.
22.2.1. Первые языки программирования
Когда в 1949 году появились первые электронные компьютеры, позволяющие хранить программы, каждый из них имел свой собственный язык программирования. Существовало взаимно однозначное соответствие между выражением алгоритма (например, вычисления орбиты планеты) и инструкциями для конкретной машины. Очевидно, что ученый (пользователями чаще всего были ученые) писали математические формулы, но программа представляла собой список машинных инструкций. Первые примитивные списки состояли из десятичных или восьмеричных цифр, точно соответствовавших их представлению в машинной памяти. Позднее появился ассемблер и “автокоды”; иначе говоря, люди разработали языки, в которых машинные инструкции и средства (например, регистры) имели символьные имена. Итак, программист мог написать “LD R0 123”, чтобы загрузить содержимое памяти, расположенной по адресу 123, в регистр 0. Однако каждая машина по-прежнему имела свой собственный набор инструкций и свой собственный язык программирования.

Ярким представителем разработчиков языков программирования в то время является, несомненно, Дэвид Уилер (David Wheeler) из компьютерной лаборатории Кембриджского университета (University of Cambridge Computer Laboratory). В 1948 году он написал первую реальную программу, которая когда-либо была выполнена на компьютере, хранившем программы в своей памяти (программа, вычислявшая таблицу квадратов; см. раздел 4.4.2.1). Он был одним из десяти людей, объявивших о создании первого компилятора (для машинно-зависимого автокода). Он изобрел вызов функции (да, даже такое очевидное и простое понятие было когда-то изобретено впервые). В 1951 году он написал блестящую статью о разработке библиотек, которая на двадцать лет опередила свое время! В соавторстве с Морисом Уилксом (Maurice Wilkes) (см. выше) и Стенли Гиллом (Stanley Gill) он написал первую книгу о программировании. Он получил первую степень доктора философии в области компьютерных наук (в Кембриджском университете в 1951 году), а позднее внес большой вклад в развитие аппаратного обеспечения (кэш-архитектура и ранние локальные сети) и алгоритмов (например, алгоритм шифрования TEA (см. раздел 25.5.6) и преобразование Бэрроуза–Уилера (Burrows-Wheeler transform) — алгоритм сжатия, использованный в архиваторе bzip2). Дэвид Уилер стал научным руководителем докторской диссертации Бьярне Страуструпа (Bjarne Stroustrup). Как видите, компьютерные науки — молодая дисциплина. Дэвид Уилер выполнил большую часть своей выдающейся работы, будучи еще аспирантом. Впоследствии он стал профессором Кембриджского университета и членом Королевского общества (Fellow of the Royal Society).
Ссылки
Burrows, M., and David Wheeler. “A Block Sorting Lossless Data Compression Algorithm.” Technical Report 124, Digital Equipment Corporation, 1994.
Bzip2 link: www.bzip.org.
Cambridge Ring website: http://koo.corpus.cam.ac.uk/projects/earlyatm/ cr82.
Campbell-Kelly, Martin. “David John Wheeler.”Biographical Memoirs of Fellows of the Royal Society, Vol. 52, 2006. (Его формальная биография.)
EDSAC: http://en.wikipedia.org/wiki/EDSAC.
Knuth, Donald. The Art of Computer Programming. Addison-Wesley, 1968, and many revisions. Look for “David Wheeler” in the index of each volume.
TEA link: http://en.wikipedia.org/wiki/Tiny_Encryption_Algorithm.
Wheeler, D. J. “The Use of Sub-routines in Programmes.” Proceedings of the 1952 ACM National Meeting. (Это библиотека технических отчетов, начиная с 1951 года.)
Wilkes, M. V., D. Wheeler, and S. Gill. Preparation of Programs for an Electronic Digital Computer. Addison-Wesley Press, 1951; 2nd edition, 1957. Первая книга о программировании.
22.2.2. Корни современных языков программирования
Ниже приведена диаграмма важнейших первых языков.

Важность этих языков частично объясняется тем, что они широко используются (а в некоторых случаях используются и ныне), а частично тем, что они стали предшественниками важных современных языков, причем часто наследники имели те же имена. Этот раздел посвящен трем ранним языкам — Fortran, COBOL и Lisp, — ставшим прародителями большинства современных языков программирования.
22.2.2.1. Язык программирования Fortran
Появление языка Fortran в 1956 году, вероятно, является наиболее значительным событием в истории языков программирования. Fortran — это сокращение словосочетания “Formula Translation”[9]. Его основная идея заключалась в генерации эффективного машинного кода, ориентированного на людей, а не на машины. Система обозначений, принятая в языке Fortran, напоминала систему, которой пользовались ученые и инженеры, решающие математические задачи, а не машинные инструкции (тогда лишь недавно появившиеся) электронных компьютеров.
С современной точки зрения язык Fortran можно рассматривать как первую попытку непосредственного представления предметной области в коде. Он позволял программистам выполнять операции линейной алгебры точно так, как они описаны в учебниках. В языке Fortran есть массивы, циклы и стандартные математические формулы (использующие стандартные математические обозначения, такие как x+y и sin(x)). Язык содержал стандартную библиотеку математических функций, механизмы ввода-вывода, причем пользователь мог самостоятельно определять дополнительные функции и библиотеки.
Система обозначений была достаточно машинно-независимой, так что код на языке Fortran часто можно было переносить из одного компьютера в другой с минимальными изменениями. Это было огромное достижение в то время. По этим причинам язык Fortran считается первым высокоуровневым языком программирования.
Считалось важным, чтобы машинный код, сгенерированный на основе исходного кода, написанного на языке Fortran, был как можно ближе к оптимальному с точки зрения эффективности: машины были огромными и чрезвычайно дорогими (во много раз больше зарплаты коллектива программистов), удивительно (по современным меркам) медленными (около 100 тыс. операций в секунду) и имели абсурдно малую память (8 K). Однако люди умудрялись втискивать в эти машины полезные программы, и это ограничивало применение улучшенной системы обозначений (ведущее к повышению производительности работы программиста и усилению переносимости программ).
Язык Fortran пользовался огромным успехом в области научных и инженерных вычислений, для которых он собственно и предназначался. С момента своего появления он постоянно эволюционировал. Основными версиями языка Fortran являются версии II, IV, 77, 90, 95 и 03, причем до сих пор продолжаются споры о том, какой из языков сегодня используется чаще: Fortran77 или Fortran90.
Первое определение и реализация языка Fortran были выполнены коллективом сотрудников компании IBM под руководством Джона Бэкуса (John Backus): “Мы не знали, чего хотели и как это сделать. Язык просто вырастал”. Что они могли знать? До сих пор никто ничего подобного не делал, но постепенно они разработали или открыли основную структуру компилятора: лексический, синтаксический и семантический анализ, а также оптимизацию. И по сей день язык Fortran является лидером в области оптимизации математических вычислений. Среди открытий, появившихся после языка Fortran, была система обозначений для специальной грамматики: форма Бэкуса–Наура (Backus-Naur Form — BNF). Впервые она была использована в языке Algol-60 (см. раздел 22.2.3.1) и в настоящее время используется в большинстве современных языков. Мы использовали вариант формы BNF в нашей грамматике, описанной в главах 6 и 7.

Много позже Джон Бэкус стал основоположником новой области языков программирования (функционального программирования), опирающейся на математический подход к программированию в отличие от машинно-ориентированного подхода, основанного на чтении и записи содержимого ячеек памяти. Следует подчеркнуть, что в чистой математике нет понятия присваивания и даже оператора. Вместо этого вы “просто” указываете, что должно быть истинным в определенных условиях. Некоторые корни функционального программирования уходят в язык Lisp (см. раздел 22.2.2.3), а другие идеи функционального программирования отражены в библиотеке STL (см. главу 21).
Ссылки
Backus, John. “Can Programming Be Liberated from the von Neumann Style?” Communications of the ACM, 1977. (Его лекция по случаю присуждения премии Тьюринга.)
Backus, John. “The History of FORTRAN I, II, and III.” ACM SIGPLAN Notices, Vol. 13 No. 8, 1978. Special Issue: History of Programming Languages Conference.
Hutton, Graham. Programming in Haskell. Cambridge University Press, 2007. ISBN 0521692695.
ISO/IEC 1539. Programming Languages — Fortran. (The “Fortran 95” standard.)
Paulson, L. C. ML for the Working Programmer. Cambridge University Press, 1991. ISBN 0521390222.
22.2.2.2. Язык программирования COBOL
Для программистов, решающих задачи, связанные с бизнесом, язык COBOL (Common Business-Oriented Language — язык программирования для коммерческих и деловых задач) был (и кое-где остается до сих пор) тем, чем язык Fortran был (и кое-где остается до сих пор) для программистов, проводящих научные вычисления. Основной упор в этом языке сделан на манипуляции данными.
• Копирование.
• Хранение и поиск (хранение записей).
• Вывод на печать (отчеты).
Подсчеты и вычисления рассматривались как второстепенные вопросы (что часто было вполне оправданно в тех областях приложений, для которых предназначался язык COBOL). Некоторые даже утверждали (или надеялись), что язык COBOL настолько близок к деловому английскому языку, что менеджеры смогут программировать самостоятельно и программисты скоро станут не нужны. Менеджеры многие годы лелеяли эту надежду, страстно желая сэкономить на программистах. Однако этого никогда не произошло, и даже намека на это не было.
Изначально язык COBOL был разработан комитетом CODASYL в 1959-60 годах по инициативе Министерства обороны США (U.S. Department of Defense) и группы основных производителей компьютеров для выполнения вычислений, связанных с деловыми и коммерческими задачами. Проект был основан на языке FLOW-MATIC, изобретенным Грейс Хоппер. Одним из ее вкладов в разработку языка было использование синтаксиса, близкого к английскому языку (в отличие от математических обозначений, принятых в языке Fortran и доминирующих до сих пор). Как и язык Fortran, а также все успешные языки программирования, COBOL претерпевал непрерывные изменения. Основными версиями были 60, 61, 65, 68, 70, 80, 90 и 04.
Грейс Мюррей Хоппер (Grace Murray Hopper) имела степень доктора философии по математике, полученную в Йельском университете (Yale University). Во время Второй мировой войны она работала на военно-морской флот США на самых первых компьютерах. Через несколько лет, проведенных в только что возникшей компьютерной промышленности, она вернулась на службу в военно-морской флот.
“Контр-адмирал доктор Грейс Мюррей Хоппер (Военно-морской флот США) была замечательной женщиной, достигших грандиозных результатов в программировании на первых компьютерах. На протяжении всей своей жизни она была лидером в области разработки концепций проектирования программного обеспечения и внесла большой вклад в переход от примитивных методов программирования к использованию сложных компиляторов. Она верила, что лозунг “мы всегда так делали” не всегда является хорошим основанием для того, чтобы ничего не менять”.
Анита Борг (Anita Borg) из выступления на конференции
“Grace Hopper Celebration of Women in Computing”, 1994

Грейс Мюррей Хоппер часто называют первой, кто назвал ошибку в компьютере “жучком” (bug). Безусловно, она была одной из первых, кто использовал этот термин и подтвердил это документально.

Жучок был реальным (молью) и повлиял на аппаратное обеспечение самым непосредственным образом. Большинство современных “жучков” гнездятся в программном обеспечении и внешне выглядят не так эффектно.
Ссылки
Биография Г. М. Хоппер: http://tergestesoft.com/~eddysworld/hopper.htm. ISO/IEC 1989:2002. Information Technology — Programming Languages — COBOL.
Sammet, Jean E. “The Early History of COBOL.” ACM SIGPLAN Notices, Vol. 13, No. 8,
1978. Special Issue: History of Programming Languages Conference.
22.2.2.3. Язык программирования Lisp
Язык Lisp был разработан в 1958 году Джоном Маккарти (John McCarthy) из Массачусетского технологического института (MIT) для обработки связанных списков и символьной информации (этим объясняется его название: LISt Processing). Изначально язык Lisp интерпретировался, а не компилировался (во многих случаях это положение не изменилось и в настоящее время). Существуют десятки (а вероятнее всего, сотни) диалектов языка Lisp. Часто говорят, что язык Lisp подразумевает разнообразные реализации. В данный момент наиболее популярными диалектами являются языки Common Lisp и Scheme.
Это семейство языков было и остается опорой исследований в области искусственного интеллекта (хотя поставляемые программные продукты часто написаны на языке C или C++). Одним из основных источников вдохновения для создателей языка Lisp было лямбда-исчисление (точнее, его математическое описание).
Языки Fortran и COBOL были специально разработаны для устранения реальных проблем в соответствующих предметных областях. Разработчики и пользователи языка Lisp больше интересовались собственно программированием и элегантностью программ. Часто их усилия приводили к успеху. Язык Lisp был первым языком, не зависевшим от аппаратного обеспечения, причем его семантика имела математическую форму. В настоящее время трудно точно определить область применения языка Lisp: искусственный интеллект и символьные вычисления нельзя спроектировать на реальные задачи так четко, как это можно сделать для деловых вычислений или научного программирования. Идеи языка Lisp (и сообщества разработчиков и пользователей языка Lisp) можно обнаружить во многих современных языках программирования, особенно в функциональных языках.

Джон Маккарти получил степень бакалавра по математике в Калифорнийском технологическом институте (California Institute of Technology), а степень доктора философии по математике — в Принстонском университете (Princeton University). Следует подчеркнуть, что среди разработчиков языков программирования много математиков. После периода плодотворной работы в MIT в 1962 году Маккарти переехал в Станфорд, чтобы участвовать в основании лаборатории по изучению искусственного интеллекта (Stanford AI lab). Ему приписывают изобретение термина “искусственный интеллект” (artificial intelligence), а также множество достижений в этой области.
Ссылки
Abelson, Harold, and Gerald J. Sussman. Structure and Interpretation of Computer Programs, Second Edition. MIT Press, 1996. ISBN 0262011530.
ANSI INCITS 226-1994 (formerly ANSI X3.226:1994). American National Standard for Programming Language — Common LISP.
McCarthy, John. “History of LISP.” ACM SIGPLAN Notices, Vol. 13 No. 8, 1978.
Special Issue: History of Programming Languages Conference.
Steele, Guy L. Jr. Common Lisp: The Language. Digital Press, 1990. ISBN 1555580416.
Steele, Guy L. Jr., and Richard Gabriel. “The Evolution of Lisp”. Proceedings of the ACM History of Programming Languages Conference (HOPL-2). ACM SIGPLAN Notices, Vol. 28 No. 3, 1993.
22.2.3. Семейство языков Algol
В конце 1950-х годов многие почувствовали, что программирование стало слишком сложным, специализированным и слишком ненаучным. Возникло убеждение, что языки программирования излишне разнообразны и что их следует объединить в один язык без больших потерь для общности на основе фундаментальных принципов. Эта идея носилась в воздухе, когда группа людей собралась вместе под эгидой IFIP (International Federation of Information Processing — Международная федерация по обработке информации) и всего за несколько лет создала новый язык, который совершил революцию в области программирования. Большинство современных языков, включая язык С++, обязаны своим существованием этому проекту.
22.2.3.1. Язык программирования Algol-60
“Алгоритмический язык” (“ALGOrithmic Language” — Algol), ставший результатом работы группы IFIP 2.1, открыл новые концепции современных языков программирования.
• Контекст лексического анализа.
• Использование грамматики для определения языка.
• Четкое разделение синтаксических и семантических правил.
• Четкое разделение определения языка и его реализации.
• Систематическое использование типов (статических, т.е. на этапе компиляции).
• Непосредственная поддержка структурного программирования.
Само понятие “универсальный язык программирования” пришло вместе с языком Algol. До того времени языки предназначались для научных вычислений (например, Fortran), деловых расчетов (например, COBOL), обработки списков (например, Lisp), моделирования и т.д. Из всех перечисленных язык Algol-60 ближе всего к языку Fortran.
К сожалению, язык Algol-60 никогда не вышел за пределы академической среды. Многим он казался слишком странным. Программисты, предпочитавшие Fortran, утверждали, что программы на Algol-60 работают слишком медленно, программисты, работавшие на языке Cobol, говорили, что Algol-60 не поддерживает обработку деловой информации, программисты, работавшие на языке Lisp, говорили, что Algol-60 недостаточно гибок, большинство остальных людей (включая менеджеров, управляющих инвестициями в разработку программного обеспечения) считали его слишком академичным, и, наконец, многие американцы называли его слишком европейским. Большинство критических замечаний было справедливым. Например, в отчете о языке Algol-60 не был определен ни один механизм ввода-вывода! Однако эти замечания можно адресовать большинству современных языков программирования, — ведь именно язык Algol установил новые стандарты во многих областях программирования.
Главная проблема, связанная с языком Algol-60, заключалась в том, что никто не знал, как его реализовать. Эта проблема была решена группой программистов под руководством Питера Наура (Peter Naur), редактора отчета по языку Algol-60 и Эдсгером Дейкстрой (Edsger Dijkstra).

Питер Наур получил образование астронома в Копенгагенском университете (University of Copenhagen) и работал в Техническом университете Копенгагена (Technical University of Copenhagen — DTH), а также на датскую компанию Regnecentralen, производившую компьютеры. Программирование он изучал в 1950–1951 годы в компьютерной лаборатории в Кембридже (Computer Laboratory in Cambridge), поскольку в то время в Дании не было компьютеров, а позднее сделал блестящую академическую и производственную карьеру. Он был одним из авторов создания формы BNF (Backus-Naur Form — форма Бэкуса–Наура), использовавшейся для описания грамматики, а также одним из первых поборников формальных рассуждений о программах (Бьярне Страуструп впервые — приблизительно в 1971 году — узнал об использовании инвариантов из технических статей Питера Наура). Наур последовательно придерживался вдумчивого подхода к вычислениям, всегда учитывая человеческий фактор в программировании. Его поздние работы носили философский характер (хотя он считал традиционную академическую философию совершенной чепухой). Он стал первым профессором даталогии в Копенгагенском университете (датский термин “даталогия” (datalogi) точнее всего переводится как “информатика”; Питер Наур ненавидел термин “компьютерные науки” (computer scienses), считая его абсолютно неправильным, так как вычисления — это не наука о компьютерах).

Эдсгер Дейкстра (Edsger Dijkstra) — еще один великий ученый в области компьютерных наук. Он изучал физику в Лейдене, но свои первые работы выполнил в Математическом центре (Mathematisch Centrum) в Амстердаме. Позднее он работал в нескольких местах, включая Эйндховенский технологический университет (Eindhoven University of Technology), компанию Burroughs Corporation и университет Техаса в Остине (University of Texas (Austin)). Кроме плодотворной работы над языком Algol, он стал пионером и горячим сторонником использования математической логики в программировании и теории алгоритмов, а также одним из разработчиков и конструкторов операционной системы ТНЕ — одной из первых операционных систем, систематически использующей параллелизм. Название THE является аббревиатурой от Technische Hogeschool Eindhoven — университета, в котором Эдсгер Дейкстра работал в то время. Вероятно, самой известной стала его статья “Go-To Statement Considered Harmful”, в которой он убедительно продемонстрировал опасность неструктурированных потоков управления.
Генеалогическое дерево языка Algol выглядит впечатляюще.

Обратите внимание на языки Simula67 и Pascal. Они являются предшественниками многих (вероятно, большинства) современных языков.
Ссылки
Dijkstra, EdsgerW. “Algol 60 Translation: An Algol 60 Translator for the x1 and Making a Translator for Algol 60”. Report MR 35/61. Mathematisch Centrum (Amsterdam), 1961.
Dijkstra, Edsger. “Go-To Statement Considered Harmful”. Communications of the ACM, Vol. 11 No. 3, 1968.
Lindsey, C. H. “The History of Algol-68”. Proceedings of the ACM History of Programming Languages Conference (HOPL-2). ACM SIGPLAN Notices, Vol. 28 No. 3, 1993.
Naur, Peter, ed. “Revised Report on the Algorithmic Language Algol 60”. A/S Regnecentralen (Copenhagen), 1964.
Naur, Peter. “Proof of Algorithms by General Snapshots”. BIT, Vol. 6, 1966, p. 310–316. Вероятно, первая статья о том, как доказать правильность программы.
Naur, Peter. “The European Side of the Last Phase of the Development of ALGOL 60”. ACM SIGPLAN Notices, Vol. 13 No. 8, 1978. Special Issue: History of Programming Languages Conference.
Perlis, Alan J. “The American Side of the Development of Algol”. ACM SIGPLAN Notices, Vol. 13 No. 8, 1978. Special Issue: History of Programming Languages Conference.
van Wijngaarden, A., B. J. Mailloux, J. E. L. Peck, C. H. A. Koster, M. Sintzoff, C. H. Lindsey, L. G. L. T. Meertens, and R. G. Fisker, eds. Revised Report on the Algorithmic Language Algol 68 (Sept. 1973). Springer-Verlag, 1976.
22.2.3.2. Язык программирования Pascal
Язык Algol-68, указанный на генеалогическом дереве семейства языков Algol, был крупным и амбициозным проектом. Подобно языку Algol-60, он был разработан комитетом по языку Algol (рабочей группой IFIP 2.1), но его реализация затянулась до бесконечности, и многие просто потеряли терпение и стали сомневаться, что из этого проекта получится что-нибудь полезное. Один из членов комитета по языку, Никлаус Вирт (Niklaus Wirth), решил разработать и реализовать свой собственный язык, являющийся наследником языка Algol. В противоположность языку Algol-68, его язык, названный Pascal, был упрощенным вариантом языка Algol-60.
Разработка языка Pascal была завершена в 1970 году, и в результате он действительно оказался простым и достаточно гибким. Часто утверждают, что он был предназначен только для преподавания, но в ранних статьях его представляли как альтернативу языка Fortran, предназначенную для тогдашних суперкомпьютеров. Язык Pascal действительно несложно выучить, и после появления легко переносимых реализаций он стал популярным языком, который использовали для преподавания программирования, но языку Fortran он не смог составить конкуренции.

Язык Pascal создан профессором Никлаусом Виртом (Niklaus Wirth) из Технического университета Швейцарии в Цюрихе (Technical University of Switzerland in Zurich — ETH). Выше приведены его фотографии, сделанные в 1969 и 2004 годах. Он получил степень доктора философии (по электротехнике и компьютерным наукам) в Калифорнийском университете в Беркли (University of California at Berkeley) и на протяжении всей своей долгой жизни поддерживал связь с Калифорнией. Профессор Вирт был наиболее полным воплощением идеала профессионального разработчика языков программирования. На протяжении двадцати пяти лет от разработал и реализовал следующие языки программирования.
• Algol W.
• PL/360.
• Euler.
• Pascal.
• Modula.
• Modula-2.
• Oberon.
• Oberon-2.
• Lola (язык описания аппаратного обеспечения).
Никлаус Вирт описывал свою деятельность как бесконечный поиск простоты. Его работа оказала наибольшее влияние на программирование. Изучение этого ряда языков программирования представляет собой чрезвычайно интересное занятие. Профессор Вирт — единственный человек, представивший на конференции HOPL (History of Programming Languages) два языка программирования.
В итоге оказалось, что язык Pascal слишком простой и негибкий, чтобы найти широкое промышленное применение. В 1980-х годах его спасла от забвения работа Андерса Хейльсберга (Anders Hejlsberg) — одного из трех основателей компании Borland. Он первым разработал и реализовал язык Turbo Pascal (который, наряду со многими другими возможностями, воплотил гибкие механизмы передачи аргументов), а позднее добавил в него объектную модель, подобную модели языка С++ (допускающую лишь одиночное наследование и имеющую прекрасный модульный механизм). Он получил образование в Техническом университете Копенгагена (Technical University in Copenhagen), в котором Питер Наур иногда читал лекции, — мир, как известно, тесен. Позднее Андерс Хейльсберг разработал язык Delphi для компании Borland и язык C# для компании Microsoft. Упрощенное генеалогическое дерево семейства языков Pascal показано ниже.

Ссылки
Borland/Turbo Pascal. http://en.wikipedia.org/wiki/Turbo_Pascal.
Hejlsberg, Anders, ScottWiltamuth, and Peter Golde. The C# Programming Language, Second Edition. Microsoft .NET Development Series. ISBN 0321334434.
Wirth, Niklaus. “The Programming Language Pascal”. Acta Informatics, Vol. 1 Fasc 1, 1971.
Wirth, Niklaus. “Design and Implementation of Modula”. Software—Practice and Experience, Vol. 7 No. 1, 1977.
Wirth, Niklaus. “Recollections about the Development of Pascal”. Proceedings of the ACM History of Programming Languages Conference (HOPL-2). ACM SIGPLAN Notices, Vol. 28 No. 3, 1993.
Wirth, Niklaus. Modula-2 and Oberon. Proceedings of the Third ACM SIGPLAN Conference on the History of Programming Languages (HOPL-III). San Diego, CA, 2007. http://portal.acm.org/toc.cfm?id=1238844.
22.2.3.3. Язык программирования Ada
Язык программирования Ada предназначался для решения любых задач программирования, возникающих в Министерстве обороны США. В частности, он должен был стать языком, обеспечивающим создание читабельного и легко сопровождаемого кода для встроенных систем программирования. Его наиболее очевидными предками являются языки Pascal и Simula (см. раздел 22.2.6). Лидером группы разработчиков языка Ada был Жан Ишбиа (Jean Ichbiah), который ранее был председателем группы Simula Users’ Group. При разработке языка Ada основное внимание было уделено
• абстракции данных (но без наследования до 1995 года);
• строгой проверке статических типов;
• непосредственной языковой поддержке параллелизма.
Целью проекта Ada было воплощение принципов разработки программного обеспечения. В силу этого Министерство обороны не разрабатывало не язык, а сам процесс проектирования языка. В этом процессе принимали участие огромное число людей и организаций, которые конкурировали друг с другом за создание наилучшей спецификации и наилучшего языка, воплощающего идеи победившей спецификации. Этим огромным двадцатилетним проектом (1975–1998 гг.) с 1980 года управлял отдел AJPO (Ada Joint Program Office).
В 1979 году язык получил название в честь леди Аугусты Ады Лавлейс (Augusta Ada Lovelace), дочери поэта лорда Байрона (Byron). Леди Лавлейс можно назвать первой программисткой современности (если немного расширить понятие современности), поскольку она сотрудничала с Чарльзом Бэббиджем (Charles Babbage), лукасианским профессором математики в Кембридже (т.е. занимавшим должность, которую ранее занимал Ньютон!) в процессе создания революционного механического компьютера в 1840-х годах. К сожалению, машина Бэббиджа на практике себя не оправдала.

Благодаря продуманному процессу разработки язык Ada считается наилучшим языком, разработанным комитетом. Жан Ишбиа из французской компании, лидер победившего коллектива разработчиков, это решительно отрицал. Однако я подозреваю (на основании дискуссии с ним), что он смог бы разработать еще более хороший язык, если бы не был ограничен заданными условиями.
Министерство обороны США много лет предписывало использовать язык Ada в военных приложениях, что в итоге выразилось в афоризме: “Язык Ada — это не просто хорошая идея, это — закон!” Сначала язык Ada просто “настоятельно рекомендовался” к использованию, но, когда многим проектировщикам было прямо запрещено использовать другие языки программирования (как правило, С++), Конгресс США принял закон, требующий, чтобы в большинстве военных приложениях использовался только язык Ada. Под влиянием рыночных и технических реалий этот закон был впоследствии отменен. Таким образом, Бьярне Страуструп был одним и очень немногих людей, чья работа была запрещена Конгрессом США.
Иначе говоря, мы настаиваем на том, что язык Ada намного лучше своей репутации. Мы подозреваем, что, если бы Министерство обороны США не было таким неуклюжим в его использовании и точно придерживалось принципов, положенных в его основу (стандарты для процессов проектирования приложений, инструменты разработки программного обеспечения, документация и т.д.), успех был бы более ярким. В настоящее время язык Ada играет важную роль в аэрокосмических приложениях и областях, связанных с разработкой аналогичных встроенных систем.
Язык Ada стал военным стандартом в 1980 году, стандарт ANSI был принят в 1983 году (первая реализация появилась в 1983 году — через три года после издания первого стандарта!), а стандарт ISO — в 1987 году. Стандарт ISO был сильно пересмотрен (конечно, сравнительно) в издании 1995 года. Включение в стандарт значительных улучшений повысило гибкость механизмов параллелизма и поддержки наследования.
Ссылки
Barnes, John. Programming in Ada 2005. Addison-Wesley, 2006. ISBN 0321340787.
Consolidated Ada Reference Manual, consisting of the international standard (ISO/IEC 8652:1995). Information Technology — Programming Languages — Ada, as updated by changes from Technical Corrigendum 1 (ISO/IEC 8652:1995:TC1:2000). Официальная домашняя страница языка Ada: www.usdoj.gov/crt/ada/.
Whitaker, William A. ADA — The Project: The DoD High Order Language Working Group. Proceedings of the ACM History of Programming Languages Conference (HOPL-2). ACM SIGPLAN Notices, Vol. 28 No. 3, 1993.
22.2.4. Язык программирования Simula
Язык Simula был разработан в первой половине 1960-х годов Кристеном Нюгордом (Kristen Nygaard) и Оле-Йоханом Далем (Ole-Johan Dahl) в Норвежском вычислительном центре (Norwegian Computing Center) и университете Осло (Oslo University). Язык Simula несомненно принадлежит семейству языков Algol. Фактически язык Simula является практически полным надмножеством языка Algol-60. Однако мы уделили особое внимание языку Simula, потому что он является источником большинства фундаментальных идей, которые сегодня называют объектно-ориентированным программированием. Он был первым языком, в котором реализованы наследование и виртуальные функции. Слова class для пользовательского типа и virtual для функции, которую можно заместить и вызвать с помощью интерфейса базового класса, пришли в С++ из языка Simula.
Вклад языка Simula не ограничен языковыми свойствами. Он состоит в явно выраженном понятии объектно-ориентированного проектирования, основанного на идее моделирования реальных явлений в коде программы.
• Представление идей в виде классов и объектов классов.
• Представление иерархических отношений в виде иерархии классов (наследование).
Таким образом, программа становится множеством взаимодействующих объектов, а не монолитом.

Кристен Нюгорд — один из создателей языка Simula 67 (вместе с Оле-Йоханом Далем, на фото слева в очках) — был энергичным и щедрым гигантом (в том числе по росту). Он посеял семена фундаментальных идей объектно-ориентированного программирования и проектирования, особенно наследования, и неотступно придерживался их на протяжении десятилетий. Его никогда не устраивали простые, краткие и близорукие ответы. Социальные вопросы также волновали его на протяжении десятков лет. Он искренне выступал против вступления Норвегии в Европейский Союз, видя в этом опасность излишней централизации, бюрократизации и пренебрежения интересами маленькой страны, находящейся на далеком краю Союза. В середине 1970-х годов Кристен Нюгорд отдавал значительное время работе на факультете компьютерных наук в университете Аархуса (University of Aarhus) в Дании, где в это время Бьярне Страуструп проходил обучение по программе магистров.
Магистерскую степень по математике Кристен Нюгорд получил в университете Осло (University of Oslo). Он умер в 2002 году, всего через месяц после того, как (вместе с другом всей своей жизни Оле-Йоханом Далем) получил премию Тьюринга — наивысший знак почета, которым Ассоциация по вычислительной технике (Association for Computing Machiner — ACM) отмечает выдающихся ученых в области компьютерных наук.
Оле-Йохан Дал был более традиционным академическим ученым. Его очень интересовали спецификации языков и формальные методы. В 1968 году он стал первым профессором по информатике (компьютерным наукам) в университете Осло.

В августе 2000 года король Норвегии объявил Даля и Нюгорда командорами ордена Святого Олафа (Commanders of the Order of Saint Olav). Все таки есть пророки в своем отечестве!
Ссылки
Birtwistle, G., O-J. Dahl, B. Myhrhaug, and K. Nygaard: SIMULA Begin. Studentlitteratur (Lund. Sweden), 1979. ISBN 9144062125.
Holmevik, J. R. “Compiling SIMULA: A Historical Study of Technological Genesis”. IEEE Annals of the History of Computing, Vol. 16 No. 4, 1994, p. 25–37.
Kristen Nygaard’s homepage: http://heim.ifi.uio.no/~kristen/.
Krogdahl, S. “The Birth of Simula”. Proceedings of the HiNC 1 Conference in Trondheim, June 2003 (IFIP WG 9.7, in cooperation with IFIP TC 3).
Nygaard, Kristen, and Ole-Johan Dahl. “The Development of the SIMULA Languages”. ACM SIGPLAN Notices, Vol. 13 No. 8, 1978. Special Issue: History of Programming Languages Conference.
SIMULA Standard. DATA processing — Programming languages — SIMULA. Swedish Standard, Stockholm, Sweden (1987). ISBN 9171622349.
22.2.5. Язык программирования С
В 1970-м году считалось, что серьезное системное программирование — в частности, реализация операционной системы — должно выполняться в ассемблерном коде и не может быть переносимым. Это очень напоминало ситуацию, сложившуюся в научном программировании перед появлением языка Fortran. Несколько индивидуумов и групп бросили вызов этой ортодоксальной точке зрения. В долгосрочной перспективе язык программирования C оказался наилучшим результатом этих усилий (подробнее об этом — в главе 27).
Деннис Ритчи (Dennis Ritchie) разработал и реализовал язык программирования С в Исследовательском центре по компьютерным наукам (Computer Science Research Center) компании Bell Telephone Laboratories в Мюррей-Хилл, штат НьюДжерси (Murray Hill, New Jersey). Прелесть языка С в том, что он был преднамеренно простым языком программирования, позволявшим непосредственно учитывать фундаментальные аспекты аппаратного обеспечения. Большинство усложнений (которые в основном были позаимствованы у языка С++ для обеспечения совместимости) было внесено позднее и часто вопреки желанию Денниса Ритчи. Частично успех языка С объясняется его широкой доступностью, но его реальная сила проявлялась в непосредственном отображении свойств языка на свойства аппаратного обеспечения (см. разделы 25.4–25.5). Деннис Ритчи лаконично описывал язык С как строго типизированный язык со слабым механизмом проверки; иначе говоря, язык С имел систему статических (распознаваемых на этапе компиляции) типов, а программа, использовавшая объект вопреки его определению, считалась неверной. Однако компилятор языка С не мог распознавать такие ситуации. Это было логично, поскольку компилятор языка С мог выполняться в памяти, размер которой составлял 48К. Вскоре язык С вошел в практику, и люди написали программу lint, которая отдельно от компилятора проверяла соответствие кода системе типов.

Кен Томпсон (Ken Thompson) и Деннис Ритчи стали авторами системы Unix, возможно, наиболее важной операционной системы за все времена. Язык C ассоциировался и по-прежнему ассоциируется с операционной системой Unix, а через нее — с системой Linux и движением за открытый код.
Деннис Ритчи вышел на пенсию из компании Lucent Bell Labs. На протяжении сорока лет он работал в Исследовательском центре по компьютерным наукам компании Bell Telephone. Он закончил Гарвардский университет (Harvard University) по специальности “физика”, степень доктора философии в прикладной математике он также получил в этом университете.

В 1974–1979 годах на развитие и адаптацию языка С++ оказали влияние многие люди из компании Bell Labs. В частности, Дуг Мак-Илрой (Doug McIlroy) был всеобщим любимцем, критиком, собеседником и генератором идей. Он оказал влияние не только на языки C и C++, но и на операционную систему Unix, а также на многое другое.
Брайан Керниган (Brian Kernighan) — программист и экстраординарный писатель. Его программы и проза — образцы ясности. Стиль этой книги частично объясняется подражанием его шедевру — учебнику The C Programming Language (известным как K&R по первым буквам фамилий его авторов — Брайана Кернигана и Денниса Ритчи).
Мало выдвинуть хорошие идеи, для того чтобы польза была ощутимой, их необходимо выразить в простейшей форме и ясно сформулировать, чтобы вас поняло много людей. Многословность — злейший враг ясности; кроме него следует упомянуть также запутанное изложение и излишнюю абстрактность. Пуристы часто насмехаются над результатами такой популяризации и предпочитают “оригинальные результаты”, представленные в форме, доступной только экспертам. Мы к пуристам не относимся: новичкам трудно усвоить нетривиальные, но ценные идеи, хотя это необходимо для их профессионального роста и общества в целом.

В течение многих лет Брайан Керниган участвовал во многих важных программистских и издательских проектах. В качестве примера можно назвать язык AWK — один из первых языков подготовки сценариев, получивший название по инициалам своих авторов (Aho, Weinberger и Kernighan), а также AMPL — (A Mathematical Programming Language — язык для математического программирования).
В настоящее время Брайан Керниган — профессор Принстонского университета (Princeton University); он превосходный преподаватель, ясно излагающий сложные темы. Более тридцати лет он работал в Исследовательском центре по компьютерным наукам компании Bell Telephone. Позднее компания Bell Labs стала называться AT&T Bell Labs, а потом разделилась на компании AT&T Labs и Lucent Bell Labs. Брайан Керниган закончил университет Торонто (University of Toronto) по специальности физика; степень доктора философии по электротехнике он получил в Принстонском университете.
Генеалогическое дерево семейства языка C представлено ниже.

Корни языка С уходят в так никогда и не завершившийся проект по разработке языка CPL в Англии, язык BCPL (Basic CPL), разработанный сотрудником Кембриджского университета (Cambridge University) Мартином Ричардсом (Martin Richards) во время его посещения Массачусетсского технологического института (MIT), а также в интерпретируемый язык B, созданный Кеном Томпсоном. Позднее язык C был стандартизован институтами ANSI и ISO и подвергся сильному влиянию языка C++ (например, в нем появились проверка аргументов функций и ключевое слово const).
Разработка языка CPL была целью совместного проекта Кембриджского университета и Имперского колледжа Лондона (Imperial College). Изначально планировалось выполнить проект в Кембридже, поэтому буква “C” официально означает слово “Cambridge”. Когда партнером в проекте стал Имперский колледж, официальным объяснением буквы “C” стало слово “Combined” (“совместный”). На самом деле (по крайней мере, нам рассказывали) его всегда связывали с именем Christopher в честь Кристофера Стрэчи (Christopher Strachey), основного разработчика языка CPL.
Ссылки
Домашняя веб-страница Брайана Кернигана: http://cm.bell-labs.com/cm/cs/ who/bwk.
Домашняя веб-страница Денниса Ритчи: http://cm.bell-labs.com/cm/cs/who/dmr. ISO/IEIC 9899:1999. Programming Languages — C. (The C standard.)
Kernighan, Brian, and Dennis Ritchie. The C Programming Language. Prentice Hall, 1978. Second Edition, 1989. ISBN 0131103628.
Список сотрудников Исследовательского центра по компьютерным наукам компании Bell Labs: http://cm.bell-labs.com/cm/cs/alumni.html.
Ritchards, Martin. BCPL — The Language and Its Compiler. Cambridge University Press, 1980. ISBN 0521219655.
Ritchie, Dennis. The Development of the C Programming Language. Proceedings of the ACM History of Programming Languages Conference (HOPL-2). ACM SIGPLAN Notices, Vol. 28 No. 3, 1993.
Salus, Peter. A Quarter Century of UNIX. Addison-Wesley, 1994. ISBN 0201547775.
22.2.6. Язык программирования С++
Язык C++ — универсальный язык программирования с уклоном в системное программирование. Перечислим его основные свойства.
• Он лучше языка С.
• Поддерживает абстракцию данных.
• Поддерживает объектно-ориентированное программирование.
• Поддерживает обобщенное программирование.
Язык С++ был разработан и реализован Бьярне Страуструпом из Исследовательского центра по компьютерным наукам компании Bell Telephone Laboratories в Мюррей-Хилл (Murray Hill), штат Нью-Джерси (New Jersey), где работали также Деннис Ритчи, Брайан Керниган, Кен Томпсон, Дуг Мак-Илрой и другие великаны системы Unix.

Бьярне Страуструп получил степень магистра по математике и компьютерным наукам в своем родном городе Эрхусе (Еrhus), Дания. Затем он переехал в Кембридж (Cambridge), где получил степень доктора философии по компьютерным наукам, работая с Дэвидом Уилером (David Wheeler). Цель создания языка С+ заключалась в следующем.
• Сделать методы абстрагирования доступными и управляемыми в рамках широко распространенных проектов.
• Внедрить объектно-ориентированное и обобщенное программирование в прикладные области, где основным критерием успеха является эффективность.
До появления языка С++ эти методы (часто необоснованно объединяемые под общим названием “объектно-ориентированное программирование”) были практически неизвестны в индустрии. Как и в научном программировании до появления языка Fortran, так и в системном программировании до появления языка С считалось, что эти технологии слишком дорогие для использования в реальных приложениях и слишком сложные для обычных программистов.
Работа над языком С++ началась в 1979 году, а в 1985 году он был выпущен для коммерческого использования. Затем Бьярне Страуструп и его друзья из компании Bell Labs и нескольких других организаций продолжали совершенствовать язык С++, и в 1990 году началась официальная процедура его стандартизации. С тех пор определение языка C++ было сначала разработано ANSI (Национальный институт стандартизации США), а с 1991 года — ISO (Международная организация по стандартизации). Бьярне Страуструп играл главную роль в этом процессе, занимая должность председателя ключевой подгруппы, ответственной за создание новых свойств языка. Первый международный стандарт (C++98) был ратифицирован в 1998 году, а над вторым стандартом (C++0x) работа продолжается по сей день.
Наиболее значительным событием в истории языка С++ спустя десять лет после его появления стала стандартная библиотека контейнеров и алгоритмов — STL. Она стала результатом многолетней работы, в основном под руководством Александра Степанова (Alexander Stepanov), направленной на создание как можно более универсального и эффективного программного обеспечения и вдохновляемой красотой и полезностью математики.

Алекс Степанов — изобретатель библиотеки STL и пионер обобщенного программирования. Он закончил
Московский государственный университет и работал в области робототехники и алгоритмов, используя разные языки программирования (включая Ada, Scheme и C++). С 1979 года он работал в академических организациях США, а также в промышленных компаниях, таких как GE Labs, AT&T Bell Labs, Hewlett-Packard, Silicon Graphics и Adobe.
Генеалогическое дерево языка C++ приведено ниже.
Язык C with Classes был создан Бьярне Страуструпом как результат синтеза идей языков C и Simula. Этот язык вышел из употребления сразу после реализации его наследника — языка C++.

Обсуждение языков программирования часто сосредоточено на их элегантности и новых свойствах. Однако языки С и С++ стали самыми успешными языками программирования за всю историю компьютерных технологий не поэтому: их сила заключается в гибкости, производительности и устойчивости. Большинство систем программного обеспечения существует несколько десятилетий, часто исчерпывая свои аппаратные ресурсы и подвергаясь совершенно неожиданным изменениям. Языки С и С++ смогли преуспеть в этой среде. Мы очень любим изречение Денниса Ритчи: “Одни языки люди разрабатывали, чтобы доказать свою правоту, а другие — для того, чтобы решить задачу”. Язык С относится ко второй категории языков. Бьярне Страуструп любит говорить: “Даже я знаю, как разработать язык, который красивее языка С++”. Цель языка С++, как и языка С, — не абстрактная красота (хотя мы очень ее ценим), а полезность.
Я часто сожалел, что не мог использовать в этой книге возможности версии C++0x. Это упростило бы многие примеры и объяснения. Примерами компонентов стандартной библиотеки версии С++0х являются классы
unordered_maparrayregexpСсылки
Публикации Александра Степанова: www.stepanovpapers.com.
Домашняя страница Бьярне Страуструпа: www.research.att.com/~bs.
ISO/IEC 14882:2003. Programming Languages — C++. (Стандарт языка C++.)
Stroustrup, Bjarne. “A History of C++: 1979–1991. Proceedings of the ACM History of Programming Languages Conference (HOPL-2). ACM SIGPLAN Notices, Vol. 28 No. 3, 1993.
Stroustrup, Bjarne. The Design and Evolution of C++. Addison-Wesley, 1994. ISBN 0201543303.
Stroustrup, Bjarne. The C++ Programming Language (Special Edition). Addison-Wesley, 2000. ISBN 0201700735.
Stroustrup, Bjarne. “C and C++: Siblings”; “C and C++: A Case for Compatibility”; and “C and C++: Case Studies in Compatibility”. The C/C++ Users Journal. July, Aug., and Sept. 2002.
Stroustrup, Bjarne. “Evolving a Language in and for the RealWorld: C++ 1991–2006”. Proceedings of the Third ACM SIGPLAN Conference on the History of Programming Languages (HOPL-III). San Diego, CA, 2007. http://portal.acm.org/toc. cfm?id=1238844.
22.2.7. Современное состояние дел
Как в настоящее время используются языки программирования и для чего они нужны? На этот вопрос действительно трудно ответить. Генеалогическое дерево современных языков, даже в сокращенном виде, слишком перегружено и запутано.

Фактически большинство статистических данных, найденных в веб (или в других местах), ничуть не лучше обычных слухов, поскольку они пытаются оценить явления, слабо связанные с интенсивностью использования, например, количество упоминаний в сети веб какого-нибудь языка программирования, продаж компиляторов, академических статей, продаж книг и т.д. Эти показатели завышают популярность новых языков программирования по сравнению со старыми. Как бы то ни было, кто такой программист? Человек, использующий язык программирования каждый день? А может быть, студент, пишущий маленькие программы с целью изучения языка? А может быть, профессор, только рассуждающий о программировании? А может быть, физик, создающий программы почти каждый год? Является ли профессиональным программистом тот, кто — про определению — использует несколько языков программирования каждую неделю несколько раз или только один раз? Разные статистические показатели будут приводить к разным ответам.
Тем не менее мы обязаны ответить на этот вопрос, поскольку в 2008 году в мире было около десяти миллионов профессиональных программистов. Об этом свидетельствуют отчет С89 С++ компании IDC (специализирующейся на сборе данных), дискуссии с издателями и поставщиками компиляторов, а также различные источники в сети веб. Можете с нами спорить, но нам точно известно, что от одного до ста миллионов человек хотя бы наполовину подходят под разумное определение программиста. Какие языки они используют? Вероятно (просто вероятно), что более 90% их программ написано на языках Ada, C, C++, C#, COBOL, Fortran, Java, PERL, PHP и Visual Basic.
Кроме упомянутых выше языков, мы могли бы перечислять десятки и даже сотни названий. Однако мы считаем необходимым упомянуть только интересные или важные языки. Если вам нужна дополнительная информация, можете найти ее самостоятельно. Профессионалы знают несколько языков и при необходимости могут изучить новый. Не существует единственного правильного языка для всех людей и для всех приложений. На самом деле все основные системы, которые нам известны, используют несколько языков.
22.2.8. Источники информации
Описание каждого языка содержит свой собственный список ссылок. Ниже приведены ссылки для нескольких языков.
Страницы и фотографии разработчиков языков программирования
www.angelfire.com/tx4/cus/people/.
Несколько примеров языков программирования
http://dmoz.org/Computers/Programming/Languages/.
Учебники
Scott, Michael L. Programming Language Pragmatics. Morgan Kaufmann, 2000. ISBN 1558604421.
Sebesta, Robert W. Concepts of Programming Languages. Addison-Wesley, 2003. ISBN 0321193628.
Книги об истории языков программирования
Bergin, T.J., and R.G. Gibson, eds. History of Programming Languages — II. Addison-Wesley, 1996. ISBN 0202295021.
Hailpern, Brent, and Barbara G. Ryder, eds. Proceedings of the Third ACM SIGPLAN Conference on the History of Programming Languages (HOPL-III).
San Diego, CA, 2007. http://portal.acm.org/toc.cfm?id=1238844.
Lohr, Steve. Go To: The Story of the Math Majors, Bridge Players, Engineers, Chess Wizards, Maverick Scientists and Iconoclasts—The Programmers Who Created the Software Revolution. Basic Books, 2002. ISBN 9780465042265.
Sammet, Jean. Programming Languages: History and Fundamentals. Prentice-Hall, 1969. ISBN 0137299885.
Wexelblat, Richard L., ed. History of Programming Languages. Academic Press, 1981. ISBN 0127450408.
Контрольные вопросы
1. Зачем нужна история?
2. Зачем нужны языки программирования? Приведите примеры.
3. Перечислите некоторые фундаментальные принципы хороших языков программирования.
4. Что такое абстракция? Что такое высокий уровень абстракции?
5. Назовите высокоуровневые идеалы программирования.
6. Перечислите потенциальные преимущества высокоуровневого программирования.
7. Что такое повторное использование кода и в чем заключается его польза?
8. Что такое процедурное программирование? Приведите конкретный пример.
9. Что такое абстракция данных? Приведите конкретный пример.
10. Что такое объектно-ориентированное программирование? Приведите конкретный пример.
11. Что такое обобщенное программирование? Приведите конкретный пример.
12. Что такое мультипарадигменное программирование? Приведите конкретный пример.
13. Когда была выполнена первая программа на компьютере, допускающем хранение данных в памяти?
14. Какую выдающуюся работу выполнил Дэвид Уилер?
15. Расскажите об основном вкладе Джона Бэкуса в создание первого языка программирования.
16. Какой первый язык разработала Грейс Мюррей Хоппер?
17. В какой области компьютерных наук выполнил свою главную работу Джон Мак-Карти?
18. Какой вклад внес Питер Наур в создание языка Algol-60?
19. Какую выдающуюся работу выполнил Эдсгер Дейкстра?
20. Какой язык спроектировал и реализовал Никлаус Вирт?
21. Какой язык разработал Андерс Хейльсберг?
22. Какова роль Жана Ишбиа в проекте Ada?
23. Какой стиль программирования впервые открыл язык Simula?
24. Где (кроме Осло) преподавал Кристен Нюгорд?
25. Какую выдающуюся работу выполнил Оле-Йохан Дал?
26. Какая операционная система была разработана под руководством Кена Томпсона?
27. Какую выдающуюся работу выполнил Дуг Мак-Илрой?
28. Назовите наиболее известную книгу Брайана Кернигана.
29. Где работал Деннис Ритчи?
30. Какую выдающуюся работу выполнил Бьярне Страуструп?
31. Какие языки пытался использовать Алекс Степанов для проектирования библиотеки STL?
32. Назовите десять языков программирования, не описанных в разделе 22.2.
33. Диалектом какого языка программирования является язык Scheme?
34. Назовите два наиболее известных наследника языка C++.
35. Почему язык C стал частью языка C++?
36. Является ли слово Fortran аббревиатурой? Если да, то какие слова в нем использованы?
37. Является ли слово COBOL аббревиатурой? Если да, то какие слова в нем использованы?
38. Является ли слово Lisp аббревиатурой? Если да, то какие слова в нем использованы?
39. Является ли слово Pascal аббревиатурой? Если да, то какие слова в нем использованы?
40. Является ли слово Ada аббревиатурой? Если да, то какие слова в нем использованы?
41. Назовите самый лучший язык программирования.
Термины
В этой главе раздел “Термины” содержит названия языков, имена людей и названия организаций.
• Языки
• Ada
• Algol
• BCPL
• C
• C++
• COBOL
• Fortran
• Lisp
• Pascal
• Scheme
• Simula
• Люди
• Чарльз Бэббидж
• Джон Бэкус
• Оле-Йохан Дал
• Эдсгер Дейкстра
• Андерс Хейльсберг
• Грейс Мюррей Хоппер
• Жан Ишбиа
• Брайан Керниган
• Джон Маккарти
• Дуг Мак-Илрой
• Питер Наур
• Кристен Нюгорд
• Деннис Ритчи
• Алекс Степанов
• Бьярне Страуструп
• Кен Томпсон
• Дэвид Уилер
• Никлаус Вирт
• Организации
• Bell Laboratories
• Borland
• Cambridge University (England)
• ETH (Швейцарский федеральный технический университет)
• IBM
• MIT
• Norwegian Computer Center
• Princeton University
• Stanford University
• Technical University of Copenhagen
• U.S. Department of Defense
• U.S. Navy
Упражнения
1. Дайте определение понятия программирование.
2. Дайте определение понятия язык программирования.
3. Пролистайте книгу и прочитайте эпиграфы к главам. Какие из них принадлежат специалистам по компьютерным наукам? Напишите один абзац, суммирующий их высказывания.
4. Пролистайте книгу и прочитайте эпиграфы к главам. Какие из них не принадлежат специалистам по компьютерным наукам? Назовите страну, где они родились, и область работы каждого из них.
5. Напишите программу “Hello, World!” на каждом из языков, упомянутых в этой главе.
6. Для каждого из упомянутых языков программирования найдите популярный учебник и первую законченную программу, написанную на нем. Напишите эту программу на всех остальных языках, упомянутых в главе. Предупреждение: скорее всего, вам придется написать около ста программ.
7. Очевидно, мы пропустили много важных языков. В частности, мы были вынуждены отказаться от описания всех языков, появившихся после языка С++. Назовите пять современных языков, которые вы считаете достойными внимания, и напишите полторы страницы о трех из них.
8. Зачем нужен язык С++? Напишите 10–20-страничное сочинение.
9. Зачем нужен язык С? Напишите 10–20-страничное сочинение.
10. Выберите один язык программирования (не C и не C++) и напишите 10–20-страничное сочинение о его истории, целях и возможностях. Приведите много конкретных примеров. Кто использует эти языки и почему?
11. Кто в настоящее время занимает Лукасианскую кафедру в Кембридже (Lucasian Chair in Cambridge)?
12. Кто из разработчиков языков программирования, перечисленных в главе, имеет научную степень по математике, а кто нет?
13. Кто из разработчиков языков программирования, перечисленных в главе, имеет степень доктора философии, а кто нет? В какой области?
14. Кто из разработчиков языков программирования, перечисленных в главе, является лауреатом премии Тьюринга? За какие достижения? Найдите официальные объявления о присуждении премии Тьюринга лауреатам, упомянутым в главе.
15. Напишите программу, которая считывает файл, содержащий пары (имя, год), например (Algol,1960) и (C,1974), и рисует соответствующий график.
16. Модифицируйте программу из предыдущего упражнения так, чтобы она считывала из файла кортежи (имя, год, (предшественники)), например (Fortran, 1956, ()), (Algol, 1960, (Fortran)) и (C++, 1985, (C, Simula)), и рисовала граф со стрелками, направленными от предшественников к последователям. Используя эту программу, нарисуйте улучшенные варианты диаграмм из разделов 22.2.2 и 22.2.7.
Послесловие
Очевидно, что мы лишь вскользь затронули историю языков программирования и идеалов программного обеспечения. Поскольку мы считаем эти вопросы очень важными, мы не можем, к нашему величайшему огорчению, глубоко изложить их в настоящей книге. Надеемся, что нам удалось передать свои чувства и идеи, относящиеся к нескончаемому поиску наилучшего программного обеспечения и методов программирования при проектировании и реализации языков программирования. Иначе говоря, помните, пожалуйста, что главное, это программирование, т.е. разработка качественного обеспечения, а язык программирования — просто инструмент для ее реализации.
Глава 23 Обработка текста
“Ничто не может быть настолько очевидным,
чтобы быть действительно очевидным...
Употребление слова “очевидно” свидетельствует
об отсутствии логических аргументов”.
Эррол Моррис (Errol Morris)
В этой главе речь идет в основном об извлечении информации из текста. Мы храним свои знания в виде слов, зафиксированных в документах, таких как книги, сообщения электронной почты, или распечатанных таблиц, чтобы впоследствии извлечь их оттуда в форме, удобной для вычислений. Здесь мы опишем возможности стандартной библиотеки, которые интенсивнее остальных используются для обработки текстов: классы
stringiostreammapregex23.1. Текст
По существу, мы постоянно работаем с текстом. Наши книги заполнены текстом, большая часть того, что мы видим на экране компьютера, — это текст, и исходный код наших программ является текстом. Наши каналы связи (всех видов) переполнены словами. Всю информацию, которой обмениваются два человека, можно было бы представить в виде текста, но не будем заходить так далеко. Изображения и звуки обычно лучше всего представлять в виде изображений и звуков (т.е. в виде совокупности битов), но все остальное можно обрабатывать с помощью программ анализа и преобразования текста.
Начиная с главы 3 мы использовали классы
iostreamsstring23.2. Строки
Класс string содержит последовательность символов и несколько полезных операций, таких как добавление символа к строке, определение длины строки и конкатенация двух строк. На самом деле стандартный класс string содержит довольно мало операций, но большинство из них оказываются полезными только при низкоуровневой обработке действительно сложных текстов. Здесь мы лишь упомянем о нескольких наиболее полезных операциях. При необходимости их полное описание (и исчерпывающий список операций из класса
string
Операции ввода-вывода описаны в главах 10-11, а также в разделе 23.3. Обратите внимание на то, что операции ввода в объект класса string при необходимости увеличивают его размер, поэтому переполнение никогда не происходит.
Операции
insert()append()erase() На самом деле стандартная строка в библиотеке описывается шаблонным классом
basic_stringbasic_string a_unicode_string; Стандартный класс
stringbasic_stringchartypedef basic_string string; // строка — это basic_string Мы не будем описывать символы или строки кода Unicode, но при необходимости вы можете работать с ними точно так же, как и с обычными символами и строками (к ним применяются точно такие же конструкции языка, класс
stringiostreamВ контексте обработки текста важно помнить, что практически все можно представить в виде строки символов. Например, на этой странице число
12.333 Если вы считываете это число, то должны сначала превратить эти символы в число с плавающей точкой и лишь потом применять к нему арифметические операции. Это приводит к необходимости конвертирования чисел в объекты класса
stringstringstring<<template string to_string(const T& t) { ostringstream os; os << t; return os.str();}Рассмотрим пример.
string s1 = to_string(12.333);string s2 = to_string(1+5*6–99/7);Значение строки
s112.333s217to_string()T<<Обратное преобразование, из класса
stringstruct bad_from_string:std::bad_cast // класс для сообщений об ошибках при преобразовании строк{ const char* what() const // override bad_cast’s what() { return "bad cast from string"; }};template T from_string(const string& s) { istringstream is(s); T t; if (!(is >> t)) throw bad_from_string(); return t;}Рассмотрим пример.
double d = from_string("12.333"); void do_something(const string& s)try{ int i = from_string(s); // ...}catch (bad_from_string e) { error ("Неправильная строка ввода",s);}Дополнительная сложность функции
from_string()to_string()stringstringstringint d = from_string("Mary had a little lamb"); // Ой! Итак, возможна ошибка, которую мы представили в виде исключения типа
bad_from_stringfrom_string()get_int()Обратите внимание на то, что функции
to_string()from_string()Ts==to_string(from_string(s)) // для всех s и
t==from_string(to_string(t)) // для всех t Здесь слово “разумный” означает, что тип
T>><< Следует подчеркнуть, что реализации функций
to_string()from_string()stringstream<<>>struct bad_lexical_cast:std::bad_cast{ const char* what() const { return "bad cast"; }};templateTarget lexical_cast(Source arg){ std::stringstream interpreter; Target result; if (!(interpreter << arg) // записываем arg в поток || !(interpreter >> result) // считываем result из потока || !(interpreter >> std::ws).eof()) // поток пуст? throw bad_lexical_cast(); return result;}Довольно забавно и остроумно, что инструкция
!(interpreter>>std::ws).eof()stringstreamintstringlexical_castlexical_cast("123") lexical_cast("123") lexical_cast("123.5") Довольно элегантное, хотя и странное, имя
lexical_castboost23.3. Потоки ввода-вывода
Рассматривая связь между строками и другими типами, мы приходим к потокам ввода-вывода. Библиотека ввода-вывода не просто выполняет ввод и вывод, она осуществляет преобразования между форматами и типами строк в памяти. Стандартные потоки ввода-вывода обеспечивают возможности для чтения, записи и форматирования строк символов. Библиотека
iostream
Стандартные потоки организованы в виде иерархии классов (см. раздел 14.3).

В совокупности эти классы дают нам возможность выполнять ввод-вывод, используя файлы и строки (а также все, что выглядит как файлы и строки, например клавиатуру и экран; см. главу 10). Как указано в главах 10-11, потоки
iostreamstringstreamiostreamistreamostream Как и строки, потоки ввода-вывода можно применять и к широким наборам данных, и к обычным символам. Снова следует подчеркнуть, что, если вам необходимо работать с вводом-выводом символов Unicode, лучше всего спросить совета у экспертов; для того чтобы стать полезной, ваша программа должна не просто соответствовать правилам языка, но и выполнять определенные системные соглашения.
23.4. Ассоциативные контейнеры
Ассоциативные контейнеры (ассоциативные массивы и хеш-таблицы) играют ключевую роль (каламбур) в обработке текста. Причина проста — когда мы обрабатываем текст, мы собираем информацию, а она часто связана с текстовыми строками, такими как имена, адреса, почтовые индексы, номера карточек социального страхования, место работы и т.д. Даже если некоторые из этих текстовых строк можно преобразовать в числовые значения, часто более удобно и проще обрабатывать их именно как текст и использовать его для идентификации. В этом отношении ярким примером является подсчет слов (см. раздел 21.6). Если вам неудобно работать с классом
mapРассмотрим сообщение электронной почты. Мы часто ищем и анализируем сообщения электронной почты и ее регистрационные записи с помощью какой-то программы (например, Thunderbird или Outlook). Чаще всего эти программы скрывают детали, характеризующие источник сообщения, но вся информация о том, кто его послал, кто получил, через какие узлы оно прошло, и многое другое поступает в программы в виде текста, содержащегося в заголовке письма. Так выглядит полное сообщение. Существуют тысячи инструментов для анализа заголовков. Большинство из них использует регулярные выражения (как описано в разделе 23.5–23.9) для извлечения информации и какие-то разновидности ассоциативных массивов для связывания их с соответствующими сообщениями. Например, мы часто ищем сообщение электронной почты для выделения писем, поступающих от одного и того же отправителя, имеющих одну и ту же тему или содержащих информацию по конкретной теме.
Приведем упрощенный файл электронной почты для демонстрации некоторых методов извлечения данных из текстовых файлов. Заголовки представляют собой реальные заголовки RFC2822 с веб-страницы www.faqs.org/rfcs/rfc2822.html. Рассмотрим пример.
xxx
xxx
––––
From: John Doe
To: Mary Smith
Subject: Saying Hello
Date: Fri, 21 Nov 1997 09:55:06 –0600
Message–ID: <1234@local.machine.example>
This is a message just to say hello.
So, "Hello".
––––
From: Joe Q. Public
To: Mary Smith <@machine.tld:mary@example.net>, , jdoe@test
.example
Date: Tue, 1 Jul 2003 10:52:37 +0200
Message–ID: <5678.21–Nov–1997@example.com>
Hi everyone.
––––
To: "Mary Smith: Personal Account"
From: John Doe
Subject: Re: Saying Hello
Date: Fri, 21 Nov 1997 11:00:00 –0600
Message–ID:
In–Reply–To: <3456@example.net>
References: <1234@local.machine.example> <3456@example.net>
This is a reply to your reply.
––––
––––
По существу, мы сократили файл, отбросив большинство информации и облегчив анализ, завершив каждое сообщение строкой, содержащей символы –––– (четыре пунктирные линии). Мы собираемся написать “игрушечное приложение”, которое будет искать все сообщения, посланные отправителем John Doe, и выводить на экран их тему под рубрикой “Subject”. Если мы сможем это сделать, то научимся делать много интересных вещей.
Во-первых, мы должны решить, хотим ли мы иметь произвольный доступ к данным или анализировать их как входные потоки. Мы выбрали первый вариант, поскольку в реальной программе нас, вероятно, интересовали бы несколько отправителей или несколько фрагментов информации, поступившей от конкретного отправителя. Кроме того, эту задачу решить труднее, поэтому нам придется проявить больше мастерства. В частности, мы снова применим итераторы.
Наша основная идея — считать весь почтовый файл в структуру, которую мы назовем
Mail_filevectorvectorДля этого мы добавим итераторы, а также функции
begin()end()

В заключение выведем на экран все темы сообщений, поступивших от John Doe, чтобы проиллюстрировать созданный нами механизм доступа к структурам. Мы используем для этого основные средства стандартной библиотеки.
#include#include#include#include#includeusing namespace std;Определим класс
Messagevectortypedef vector::const_iterator Line_iter; class Message { // объект класса Message ссылается // на первую и последнюю строки сообщения Line_iter first; Line_iter last;public: Message(Line_iter p1, Line_iter p2) :first(p1), last(p2) { } Line_iter begin() const { return first; } Line_iter end() const { return last; } // ...};Определим класс
Mail_filetypedef vector::const_iterator Mess_iter; struct Mail_file { // объект класса Mail_file содержит все строки // из файла и упрощает доступ к сообщениямstring name; // имя файла vector lines; // строки по порядку vector m; // сообщения по порядку Mail_file(const string& n); // считываем файл n в строки Mess_iter begin() const { return m.begin(); } Mess_iter end() const { return m.end(); }};Отметьте, что мы добавили в структуры данных итераторы, чтобы иметь возможность систематически перемещаться по структуре. На самом деле мы не собираемся использовать здесь стандартные библиотечные алгоритмы, но если захотим, то итераторы позволят нам сделать это.
Для того чтобы найти и извлечь информацию, содержащуюся в сообщении, нужны две вспомогательные функции.
// Ищет имя отправителя в объекте класса Message;// возвращает значение true, если имя найдено;// если имя найдено, помещает имя отправителя в строку s:bool find_from_addr(const Message* m,string& s);// возвращает тему сообщения, если ее нет, возвращает символ " ":string find_subject(const Message* m);Итак, мы можем написать код для извлечения информации из файла.
int main(){ Mail_file mfile("my–mail–file.txt"); // инициализируем структуру // mfile данными из файла // сначала собираем сообщения, поступившие от каждого // отправителя, в объекте класса multimap: multimap sender; for (Mess_iter p = mfile.begin(); p!=mfile.end(); ++p) { const Message& m = *p; string s; if (find_from_addr(&m,s)) sender.insert(make_pair(s,&m)); } // Теперь перемещаемся по объекту класса multimap // и извлекаем темы сообщений, поступивших от John Doe: typedef multimap::const_iterator MCI; pair pp = sender.equal_range("John Doe "); for(MCI p = pp.first; p!=pp.second; ++p) cout << find_subject(p–>second) << '\n';} Рассмотрим подробнее использование ассоциативных массивов. Мы использовали класс
multimapmultimap• создать ассоциативный массив;
• использовать ассоциативный массив.
Мы создаем объект класса
multimapinsert()for (Mess_iter p = mfile.begin(); p!=mfile.end(); ++p) { const Message& m = *p; string s; if (find_from_addr(&m,s)) sender.insert(make_pair(s,&m));}В ассоциативный массив включаются пары (ключ, значение), созданные с помощью функции
make_pair()find_from_addr()Почему мы используем ссылку
mpfind_from_addr(p,s)Mess_iterMessageПочему мы сначала записали объекты класса
MessagemultimapMessagemap• Сначала мы создаем универсальную структуру, которую можно использовать для многих вещей.
• Затем используем ее в конкретном приложении.
Таким образом, мы создаем коллекцию в той или иной степени повторно используемых компонентов. Если бы мы сразу создали ассоциативный массив в объекте класса
Mail_filemultimapsenderAddressСоздание приложений по этапам (или слоям (layers), как их иногда называют) может значительно упростить проектирование, реализацию, документацию и эксплуатацию программ. Дело в том, что каждая часть приложения решает отдельную задачу и делает это вполне очевидным образом. С другой стороны, для того чтобы сделать все сразу, нужен большой ум. Очевидно, что извлечение информации и заголовков сообщений электронной почты — это детский пример приложения. Значение разделения задач, выделения модулей и поступательного наращивания приложения по мере увеличения масштаба приложения проявляется все более ярко.
Для того чтобы извлечь информацию, мы просто ищем все упоминания ключа "John Doe", используя функцию
equal_range()[first,second]equal_range()find_subject()typedef multimap::const_iterator MCI; pair pp = sender.equal_range("John Doe"); for (MCI p = pp.first; p!=pp.second; ++p) cout << find_subject(p–>second) << '\n';Перемещаясь по элементам объекта класса map, мы получаем последовательность пар (ключ,значение), в которых, как в любом другом объекте класса
pairstringkeyfirstMessagesecond23.4.1. Детали реализации
Очевидно, что мы должны реализовать используемые нами функции. Соблазнительно, конечно, сэкономить бумагу и спасти дерево, предоставив читателям самостоятельно решить эту задачу, но мы решили, что пример должен быть полным.
Конструктор класса
Mail_filelinesmMail_file::Mail_file(const string& n) // открывает файл с именем "n" // считывает строки из файла "n" в вектор lines // находит сообщения в векторе lines и помещает их в вектор m, // для простоты предполагая, что каждое сообщение заканчивается // строкой "––––" line{ ifstream in(n.c_str()); // открываем файл if (!in) { cerr << " нет " << n << '\n'; exit(1); // прекращаем выполнение программы}string s; while (getline(in,s)) lines.push_back(s); // создаем вектор // строк Line_iter first = lines.begin(); // создаем вектор сообщений for (Line_iter p = lines.begin(); p!=lines.end(); ++p) { if (*p == "––––") { // конец сообщения m.push_back(Message(first,p)); first = p+1; // строка –––– не является частью // сообщения } }}Обработка ошибок носит слишком элементарный характер. Если бы писали эту программу для своих друзей, то постарались бы сделать ее лучше.
ПОПРОБУЙТЕ
Что значит “более хорошая обработка ошибок”? Измените конструктор класса
Mail_fileФункции
find_from_addr()find_subject()int is_prefix(const string& s, const string& p) // Является ли строка p первой частью строки s?{ int n = p.size(); if (string(s,0,n)==p) return n; return 0;}bool find_from_addr(const Message* m, string& s){ for(Line_iter p = m–>begin(); p!=m–>end(); ++p) if (int n = is_prefix(*p,"From: ")) { s = string(*p,n); return true; } return false;}string find_subject(const Message* m){ for(Line_iter p = m.begin(); p!=m.end(); ++p) if (int n = is_prefix(*p,"Subject: ")) return string(*p,n); return "";} Обратите внимание на то, как мы используем подстроки: конструктор
string(s,n)ss[n]s[n]..s[s.size()–1]string(s,0,n)s[0]..s[n–1] Почему функции
find_from_addr()find_subject()boolstring• Функция
find_from_addr()""find_from_addr()trues""false• Функция
find_subject()""Насколько полезным является такое различие, которое проводит функция
find_from_addr()find_from_addr()find_subject()find_from_addr()Эта программа не является оптимальной с точки зрения производительности, но мы надеемся, что в типичных ситуациях она работает достаточно быстро. В частности, она считывает входной файл только один раз и не хранит несколько копий текста из этого файла. Для крупных файлов было бы целесообразно заменить класс
multimapunordered_multimapВведение в стандартные ассоциативные контейнеры (
mapmultimapsetunordered_mapunordered_multimap23.5. Проблема
Потоки ввода-вывода и класс
stringstring s;while (cin>>s) { if (s.size()==7 && isalpha(s[0]) && isalpha(s[1]) && isdigit(s[2]) && isdigit(s[3]) && isdigit(s[4]) && isdigit(s[5]) && isdigit(s[6])) cout << " найдена " << s << '\n';}Здесь значение
isalpha(x)truexisdigit(x)truex• Оно громоздко (четыре строки, восемь вызовов функций).
• Мы пропускаем (умышленно?) почтовые индексы, не отделенные от своего контекста пробелом (например, "TX77845", TX77845–1234 и ATX77845).
• Мы пропускаем (умышленно?) почтовые индексы с пробелом между буквами и цифрами (например, TX 77845).
• Мы принимаем (умышленно?) почтовые индексы, в которых буквы набраны в нижнем регистре (например, tx77845).
• Если вы решите проанализировать почтовые индексы, имеющие другой формат (например, CB3 0FD), то будете вынуждены полностью переписать весь код.
Должен быть более хороший способ! Перед тем как его описать, рассмотрим поставленные задачи. Предположим, что мы хотим сохранить “старый добрый код”, дополнив его обработкой указанных ситуаций.
• Если мы хотим обрабатывать не один формат, то следует добавить инструкцию
ifswitch• Если мы хотим учитывать верхний и нижний регистры, то должны явно конвертировать строки (обычно в нижний регистр) или добавить дополнительную инструкцию
if• Мы должны как-то (как?) описать контекст, в котором выполняется поиск. Это значит, что мы должны работать с отдельными символами, а не со строками, т.е. потерять многие преимущества, предоставляемые потоками
iostreamЕсли хотите, попробуйте написать код в этом стиле, но нам очевидно, что в этом случае вы запутаетесь в сети инструкций
if123!123456!2007–06–05
June 5, 2007
jun 5, 2007
5 June 2007
6/5/2007
5/6/07
...
В этот момент, если не раньше, опытный программист воскликнет: “Должен быть более хороший способ!” (чем нагромождение ординарного кода) и станет его искать. Простейшим и наиболее широко распространенным решением этой задачи является использование так называемых регулярных выражений (regular expressions).
Регулярные выражения являются основой большинства методов обработки текстов и команды
grepРегулярные выражения, которые мы будем использовать, реализованы в библиотеке, которая станет частью следующего стандарта языка С++ (C++0x). Они сопоставимы с регулярными выражениями из языка Perl. Этой теме посвящено много книг, учебников и справочников, например, рабочий отчет комитета по стандартизации языка C++ (в сети веб он известен под названием WG21), документация Джона Мэддокса (John Maddock)
boost::regexПОПРОБУЙТЕ
В последних двух абзацах “неосторожно” упомянуты несколько имен и аббревиатур без каких-либо объяснений. Поищите в веб информацию о них.
23.6. Идея регулярных выражений
Основная идея регулярного выражения заключается в том, что оно определяет шаблон (pattern), который мы ищем в тексте. Посмотрим, как мы могли бы точно описать шаблон простого почтового кода, такого как TX77845. Результат первой попытки выглядит следующим образом:
wwddddd
где символ w означает любую букву, а символ d — любую цифру. Мы используем символ w (от слова “word”), поскольку символ l (от слова “letter”) слишком легко перепутать с цифрой 1. Эти обозначения вполне подходят для нашего простого примера, но что произойдет, если мы попробуем применить их для описания формата почтового кода, состоящего из девяти цифр (например, TX77845–5629). Что вы скажете о таком решении?
wwddddd–dddd
Они выглядят вполне логичными, но как понять, что символ d означает “любая цифра”, а знак – означает “всего лишь” дефис? Нам необходимо как-то указать, что символы w и d являются специальными: они представляют классы символов, а не самих себя (символ w означает “a или b или c или ...”, а символ d означает “1 или 2, или 3, или ...”). Все это слишком сложно. Добавим к букве, обозначающей имя класса символов, обратную косую черту, как это сделано в языке С++ (например, символ \n означает переход на новую строку). В этом случае получим такую строку:
\w\w\d\d\d\d\d–\d\d\d\d
Выглядит довольно некрасиво, но, по крайней мере, мы устранили неоднозначность, а обратные косые черты ясно обозначают то, что за ними следует “нечто необычное”. Здесь повторяющиеся символы просто перечислены один за другим. Это не только утомительно, но и провоцирует ошибки. Вы можете быстро сосчитать, что перед обратной косой чертой до дефиса действительно стоят пять цифр, а после — четыре? Мы смогли, но просто сказать 5 и 4 мало, чтобы в этом убедиться, поэтому придется их пересчитать. После каждого символа можно было бы поставить счетчик, указывающий количество его повторений.
\w2\d5–\d4
Однако на самом деле нам нужна какая-то синтаксическая конструкция, чтобы показать, что числа 2, 5 и 4 в этом шаблоне являются значениями счетчиков, не просто цифрами 2, 5 и 4. Выделим значения счетчиков фигурными скобками.
\w{2}\d{5}–\d{4}
Теперь символ { является таким же специальным символом, как и обратная косая черта, \, но этого избежать невозможно, и мы должны просто учитывать этот факт.
Итак, все бы ничего, но мы забыли о двух обстоятельствах: последние четыре цифры в почтовом коде ZIP являются необязательными. Иногда допустимыми являются оба варианта: TX77845 и TX77845–5629. Этот факт можно выразить двумя основными способами:
\w{2}\d{5} или \w{2}\d{5}–\d{4}
и
\w{2}\d{5} и необязательно –\d{4}
Точнее говоря, сначала мы должны выразить идею группирования (или частичного шаблона), чтобы говорить о том, что строки \w{2}\d{5} и –\d{4} являются частями строки \w{2}\d{5}–\d{4}. Обычно группирование выражается с помощью круглых скобок.
(\w{2}\d{5})(–\d{4})
Теперь мы должны разбить шаблон на два частичных шаблона (sub-patterns), т.е. указать, что именно мы хотим с ними делать. Как обычно, введение новой возможности достигается за счет использования нового специального символа: теперь символ ( является специальным, как и символы \ и {. Обычно символ | используется для обозначения операции “или” (альтернативы), а символ ? — для обозначения чего-то условного (необязательного). Итак, можем написать следующее:
(\w{2}\d{5})|(\w{2}\d{5}–\d{4})
и
(\w{2}\d{5})(–\d{4})?
Как и фигурные скобки при обозначении счетчиков (например, \w{2}), знак вопроса (?) используется как суффикс. Например, (–\d{4})? означает “необязательно –\d{4}”; т.е. мы интерпретируем четыре цифры, перед которыми стоит дефис, как суффикс. На самом деле мы не используем круглые скобки для выделения пятизначного почтового кода ZIP (\w{2}\d{5}) для выполнения какой-либо операции, поэтому их можно удалить.
\w{2}\d{5}(–\d{4})?
Для того чтобы завершить наше решение задачи, поставленной в разделе 23.5, можем добавить необязательный пробел после двух букв.
\w{2} ?\d{5}(–\d{4})?
Запись “?” выглядит довольно странно, но знак вопроса после пробела указывает на то, что пробел является необязательным. Если бы мы хотели, чтобы пробел не выглядел опечаткой, то должны были бы заключить его в скобки.
\w{2}( )?\d{5}((–\d{4})?
Если бы кто-то сказал, что эта запись выглядит слишком неразборчивой, то нам пришлось бы придумать обозначение для пробела, например \s (s — от слова “space”). В этом случае запись выглядела бы так:
\w{2}\s?\d{5}(–\d{4})?
А что если кто-то поставит два пробела после букв? В соответствии с определенным выше шаблоном это означало бы, что мы принимаем коды TX77845 и TX 77845, но не TX 77845. Это неправильно.
Нам нужно средство, чтобы сказать “ни одного, один или несколько пробелов”, поэтому мы вводим суффикс *.
\w{2}\s*\d{5}(–\d{4})?
Было бы целесообразно выполнять каждый этап в строгой логической последовательности. Эта система обозначения логична и очень лаконична. Кроме того, мы не принимали проектные решения с потолка: выбранная нами система обозначений очень широко распространена. При решении большинства задач, связанных с обработкой текста, нам необходимо читать и записывать эти символы. Да, эти записи похожи на результат прогулки кошки по клавиатуре, и ошибка в единственном месте (наш лишний или пропущенный пробел) полностью изменяет их смысл, но с этим приходится смириться. Мы не можем предложить ничего радикально лучшего, и этот стиль обозначений за тридцать лет распространился очень широко. Впервые он был использован в команде
grep23.7. Поиск с помощью регулярных выражений
Теперь применим шаблон почтовых кодов ZIP из предыдущего раздела для поиска почтовых кодов в файле. Программа определяет шаблон, а затем ищет его, считывая файл строка за строкой. Когда программа находит шаблон в какой-то строке, она выводит номер строки и найденный код.
#include #include #include #include using namespace std;int main(){ ifstream in("file.txt"); // файл ввода if (!in) cerr << "нет файла \n"; boost::regex pat ("\\w{2}\\s*\\d{5}(–\\d{4})?"); // шаблон // кода ZIP cout << "шаблон: " << pat << '\n'; int lineno = 0; string line; // буфер ввода while (getline(in,line)) { ++lineno; boost::smatch matches; // записываем сюда совпавшие строки if (boost::regex_search(line, matches, pat)) cout << lineno << ": " << matches[0] << '\n'; }}Эта программа требует объяснений. Сначала рассмотрим следующий фрагмент:
#include ...boost::regex pat ("\\w{2}\\s*\\d{5}(–\\d{4})?"); // шаблон кода ZIPboost::smatch matches; // записываем сюда совпавшие строкиif (boost::regex_search(line, matches, pat))Мы используем реализацию библиотеки
Boost.RegexBoost.RegexBoost.Regexboostboost::regexВернемся к регулярным выражениям! Рассмотрим следующий фрагмент кода:
boost::regex pat ("\\w{2}\\s*\\d{5}(–\\d{4})?");cout << "шаблон: " << pat << '\n';Здесь мы сначала определили шаблон
patregex\\w{2}\\s*\\d{5}(–\\d{4})?
Если бы вы запустили программу, то увидели бы на экране следующую строку:
pattern: \w{2}\s*\d{5}(–\d{4})?
В строковых литералах языка С++ обратная косая черта означает управляющий символ (раздел A.2.4), поэтому вместо одной обратной косой черты (\) в литеральной строке необходимо написать две (\\).
Шаблон типа
regexstring<<regexstringregexregexboost::smatch matches;if (boost::regex_search(line, matches, pat)) cout << lineno << ": " << matches[0] << '\n'; Функция
regex_search(line, matches, pat) linepatmatchesregex_search(line, matches, pat)falseПеременная
matchessmatchssmatchmatches[0]matches[i]iNmatches.size()==N+1 Что такое частичный шаблон (sub-pattern)? Можно просто сказать: “Все, что заключено в скобки внутри шаблона”. Глядя на шаблон "\\w{2}\\s*\\d{5}(–\\d{4})?", мы видим скобки вокруг четырехзначного кода ZIP. Таким образом, мы видим только один частичный шаблон, т.е.
matches.size()==2while (getline(in,line)) { boost::smatch matches; if (boost::regex_search(line, matches, pat)) { cout << lineno << ": " << matches[0] << '\n'; // полное // совпадение if (1 cout << "\t: " << matches[1] << '\n'; // частичное // совпадение }}Строго говоря, мы не обязаны проверять выражение
1patmatchedmatches[1].matchedmatches[i].matchedfalsematches[i]matches[17]Мы применили нашу программу к файлу, содержащему следующие строки:
address TX77845
ffff tx 77843 asasasaa
ggg TX3456–23456
howdy
zzz TX23456–3456sss ggg TX33456–1234
cvzcv TX77845–1234 sdsas
xxxTx77845xxx
TX12345–123456
Результат приведен ниже.
pattern: "\w{2}\s*\d{5}(–\d{4})?"
1: TX77845
2: tx 77843
5: TX23456–3456
: –3456
6: TX77845–1234
: –1234
7: Tx77845
8: TX12345–1234
: –1234
Следует подчеркнуть несколько важных моментов.
• Мы не дали себя запутать неверно отформатированным кодом ZIP в строке, начинающейся символами ggg (кстати, что в нем неправильно?).
• В строке, содержащей символы zzz, мы нашли только первый код ZIP (мы ищем только один код в строке).
• В строках 5 и 6 мы нашли правильные суффиксы.
• В строке 7 мы нашли код ZIP, скрытый среди символов xxx.
• Мы нашли (к сожалению?) код ZIP, скрытый в строке TX12345–123456.
23.8. Синтаксис регулярных выражений
Мы рассмотрели довольно элементарный пример сравнения регулярных выражений. Настало время рассмотреть регулярные выражения (в форме, использованной в библиотеке
regex Регулярные выражения (regular expressions, regexps или regexs), по существу, образуют небольшой язык для выражения символьных шаблонов. Этот мощный (выразительный) и лаконичный язык иногда выглядит довольно таинственным. За десятилетия использования регулярных выражений в этом языке появилось много тонких свойств и несколько диалектов. Здесь мы опишем подмножество регулярных выражений (большое и полезное), которое, возможно, в настоящее время является наиболее распространенным диалектом (язык Perl). Если читателям понадобится более подробная информация о регулярных выражениях или возникнет необходимость объяснить их другим людям, они могут найти все, что нужно, в веб. Существует огромное количество учебников (очень разного качества) и спецификаций. В частности, в веб легко найти спецификацию
boost::regex Библиотека
boost::regex23.8.1. Символы и специальные символы
Регулярные выражения определяют шаблон, который можно использовать для сопоставления символов из строки. По умолчанию символ в шаблоне соответствует самому себе в строке. Например, регулярное выражение (шаблон) "abc" соответствует подстроке abc строки Is there an abc here?
Реальная мощь регулярных выражений заключается в специальных символах и сочетаниях символов, имеющих особый смысл в шаблоне.

Например, выражение
x.yсоответствует любой строке, состоящей из трех символов, начинающейся с буквы
xyxxyx3yxayyxy3xyxyОбратите внимание на то, что выражения
{...}*+?Если хотите использовать в шаблоне один из специальных символов, вы должны сделать его управляющим, поставив перед ним обратную косую черту; например, символ
+\+23.8.2. Классы символов
Самые распространенные сочетания символов в сжатом виде представлены как специальные символы.

Символы в верхнем регистре означают “не вариант специального символа в нижнем регистре”. В частности, символ \W означает “не буква”, а не “буква в верхнем регистре”.
Элементы третьего столбца (например,
[[:digit:]]Как и библиотеки
stringiostreamregexstringiostream23.8.3. Повторения
Повторяющиеся шаблоны задаются постфиксными операторами.

Например, выражение
Ax*
соответствует символу A, за котором не следует ни одного символа или следует несколько символов x:
A
Ax
Axx
Axxxxxxxxxxxxxxxxxxxxxxxxxxxxx
Если мы требуем, чтобы символ
x+*Ax+
соответствует символу A, за которым следует один или несколько символов x:
Ax
Axx
Axxxxxxxxxxxxxxxxxxxxxxxxxxxxx
но не
A
В общем случае необязательный символ (ни одного или несколько) указывается с помощью знака вопроса. Например, выражение
\d–?\d
соответствует двум цифрам с необязательным дефисом между ними:
1–2
12
но не
1––2
Для задания конкретного количества вхождений или конкретного диапазона вхождений используются фигурные скобки. Например, выражение
\w{2}–\d{4,5}
соответствует только строкам, содержащим две буквы и дефис, за которым следуют четыре или пять цифр:
Ab–1234
XX–54321
22–54321
но не
Ab–123
?b–1234
Да, цифры задаются символами \w.
23.8.4. Группировка
Для того чтобы указать, что некое регулярное выражение является частичным шаблоном (sub-pattern), его следует заключить в круглые скобки. Рассмотрим пример.
(\d*:)
Данное выражение определяет частичный шаблон, не содержащий ни одной или содержащий несколько цифр, за которыми следует двоеточие. Группу можно использовать как часть более сложного шаблона. Рассмотрим пример.
(\d*:)?(\d+)
Данное выражение задает необязательную и, возможно, пустую последовательность цифр, за которыми следуют двоеточие и последовательность из одной или нескольких цифр. Этот лаконичный и точный способ выражения шаблонов изобрели обычные люди!
23.8.5. Варианты
Символ “или” (|) задает альтернативу. Рассмотрим пример.
Subject: (FW:|Re:)?(.*)
Это выражение распознает тему сообщения электронной почты с необязательными символами FW: или Re:, за которыми может не стоять ни одного символа или может стоять несколько символов. Рассмотрим пример.
Subject: FW: Hello, world!
Subject: Re:
Subject: Norwegian Blue
но не
SUBJECT: Re: Parrots
Subject FW: No subject!
Пустая альтернатива не допускается.
(|def)
// ошибкаОднако мы можем указать несколько альтернатив сразу.
(bs|Bs|bS|BS)
23.8.6. Наборы символов и диапазоны
Специальные символы представляют собой обозначение наиболее распространенных классов символов: цифр (\d); букв, цифр и знака подчеркивания (\w) и др. (см. раздел 23.7.2). Однако часто бывает полезно определить свой собственный специальный символ. Сделать это очень легко. Рассмотрим пример.

В спецификации класса символов дефис (–) используется для указания диапазона, например, [1–3] (1, 2 или 3) и [w–z] (w, x, y или z). Пожалуйста, будьте аккуратны при использовании таких диапазонов: не все языки содержат одинаковые буквы, и порядки их следования в алфавитах разных языков могут отличаться. Если вам необходим диапазон, не являющийся частичным диапазоном букв и цифр, принятых в английском языке, то обратитесь к документации.
Следует подчеркнуть, что мы используем специальные символы, такие как \w (означающий “любой словообразующий символ”), в спецификации класса символов. Как же нам вставить обратную косую черту (\) в класс символов? Как обычно, превращаем ее в управляющий символ: \\.
Если первым символом в спецификации класса символов является символ
^^
В последнем регулярном выражении символ ^ стоит не на первом месте после квадратной скобки ([), значит, это простой символ, а не оператор отрицания. Регулярные выражения могут быть очень хитроумными.
Реализация библиотеки
regex[[:alnum:]]"[[:alnum:]]+string s = "\"[[:alnum:]]+\"";Более того, чтобы поместить строковый литерал в объект класса
regexregexregex s("\\\"[[:alnum:]]+\\\"");Использование регулярных выражений вынуждает вводить множество обозначений. Перечислим стандартные классы символов.

Реализация библиотеки
regex23.8.7. Ошибки в регулярных выражениях
Что произойдет, если мы зададим неправильное регулярное выражение? Рассмотрим пример.
regex pat1("(|ghi)"); // пропущенный оператор альтернативыregex pat2("[c–a]"); // не диапазонКогда мы присваиваем шаблон объекту класса
regexbad_expressionРассмотрим небольшую программу, позволяющую исследовать механизм сравнения регулярных выражений.
#include #include #include #include #includeusing namespace std;using namespace boost; // если вы используете реализацию библиотеки // boost// получаем извне шаблон и набор строк// проверяем шаблон и ищем строки, содержащие этот шаблонint main(){ regex pattern; string pat; cout << "введите шаблон: "; getline(cin,pat); // считываем шаблон try { pattern = pat; // проверка шаблона cout << "Шаблон: " << pattern << '\n'; } catch (bad_expression) { cout << pat << "Не является корректным регулярным выражением\n"; exit(1); } cout << "Введите строки:\n"; string line; // входной буфер int lineno = 0; while (getline(cin,line)) { ++lineno; smatch matches; if (regex_search(line, matches, pattern)) { cout << " строка " << lineno << ": " << line << '\n'; for (int i = 0; i cout << "\tmatches[" << i << "]: " << matches[i] << '\n'; } else cout << "не соответствует \n"; }}ПОПРОБУЙТЕ
Запустите эту программу и попробуйте применить ее для проверки нескольких шаблонов, например abc, x.*x, ( .* ), \([^)]*\) и \ w+\w+(Jr\.) ?.
23.9. Сравнение регулярных выражений
Регулярные выражения в основном используются в двух ситуациях.
• Поиск строки, соответствующей регулярному выражению в (произвольно длинном) потоке данных, — функция
regex_search()• Сравнение регулярного выражения со строкой (заданного размера) — функция
regex_match()Одним из примеров является поиск почтовых индексов в разделе 23.6. Рассмотрим извлечение данных из следующей таблицы.

Эта совершенно типичная и не очень сложная таблица (количество учеников в 2007 году в средней школе, в которой учился Бьярне Страуструп) извлечена с веб страницы, на которой она выглядела именно так, как нам нужно.
• Содержит числовые поля.
• Содержит символьные поля в строках, понятных только людям, знающим контекст, из которого извлечена таблица. (В данном случае ее могут понять только люди, знающие датский язык.)
• Символьные строки содержат пробелы.
• Поля отделены друг от друга разделителем, роль которого в данном случае играет символ табуляции.
Мы назвали эту таблицу совершенно типичной и не очень сложной, но следует иметь в виду, что одна тонкость в ней все же скрывается: на самом деле мы не можем различить пробелы и знаки табуляции; эту проблему читателям придется устранить самостоятельно.
Проиллюстрируем использование регулярных выражения для решения следующих задач.
• Убедимся, что таблица сформирована правильно (т.е. каждая строка имеет правильное количество полей).
• Убедимся, что суммы подсчитаны правильно (в последней строке содержатся суммы чисел по столбцам).
Если мы сможем это сделать, то сможем сделать почти все! Например, мы смогли бы создать новую таблицу, в которой строки, имеющие одинаковые первые цифры (например, годы: первый класс должен иметь номер 1), объединены или проверить, увеличивается или уменьшается количество студентов с годами (см. упр. 10-11).
Для того чтобы проанализировать эту таблицу, нам нужны два шаблона: для заголовка и для остальных строк.
regex header( "^[\\w ]+( [\\w ]+)*$");regex row( "^[\\w ]+(\\d+)(\\d+)(\\d+)$"); Помните, мы хвалили синтаксис регулярных выражений за лаконичность и полезность, а не за легкость освоения новичками? На самом деле регулярные выражения имеют заслуженную репутацию языка только для письма (write-only language). Начнем с заголовка. Поскольку он не содержит никаких числовых данных, мы могли бы просто отбросить первую строку, но — исключительно для приобретения опыта — попробуем провести ее структурный анализ. Она содержит четыре словарных поля (буквенно-цифровых поля”, разделенных знаками табуляции). Эти поля могут содержать пробелы, поэтому мы не можем просто использовать управляющий символ
\w[\w][\w]+^[\w ]+^([\w]+)([\w]+)*$$"^[\\w ]+( [\\w ]+)*$"Мы не можем проверить, что знак табуляции действительно является таковым, но в данном случае он раскрывается в ходе набора текста и распознается сам.
Приступим к самой интересной части упражнения: к шаблону для строк, из которых мы хотим извлекать числовые данные. Первое поле вновь имеет шаблон
^[\w]+\d+^[\w ]+( \d+)(\d+)(\d+)$После его вставки в строковый литерал он превращается в такую строку:
"^[\\w ]+(\\d+)(\\d+)(\\d+)$"Теперь мы сделали все, что требовалось. Сначала проверим, правильно ли сформирована таблица.
int main(){ ifstream in("table.txt"); // входной файл if (!in) error("Нет входного файла\n"); string line; // буфер ввода int lineno = 0; regex header( "^[\\w ]+( [\\w ]+)*$"); // строка заголовка regex row("^[\\w]+(\\d+)(\\d+)(\\d+)$"); // строка данных if (getline(in,line)) { // проверяем строку заголовка smatch matches; if (!regex_match(line,matches,header)) error("Нет заголовка"); } while (getline(in,line)) { // проверяем строку данных ++lineno; smatch matches; if (!regex_match(line,matches,row)) error("неправильная строка",to_string(lineno)); }}Для краткости мы не привели здесь директивы
#includeregex_match()regex_search()regex_match()regex_search()regex_match()regex_search()Теперь можем перейти к верификации данных в таблице. Мы подсчитаем количество мальчиков (“drenge”) и девочек (“piger”), учащихся в школе. Для каждой строки мы проверим, действительно ли в последнем поле (“ELEVER IALT”) записана сумму первых двух полей. Последняя строка (“Alle klasser”) содержит суммы по столбцам. Для проверки этого факта модифицируем выражение row, чтобы текстовое поле содержало частичное совпадение и можно было распознать строку “Alle klasser”.
int main(){ ifstream in("table.txt"); // входной файл if (!in) error("Нет входного файла"); string line; // буфер ввода int lineno = 0; regex header( "^[\\w ]+( [\\w ]+)*$"); regex row("^([\\w ]+)(\\d+)(\\d+)( \d+)$"); if (getline(in,line)) { // проверяем строку заголовка boost::smatch matches; if (!boost::regex_match(line, matches, header)) { error("Нет заголовка"); } }// суммы по столбцам: int boys = 0; int girls = 0; while (getline(in,line)) { ++lineno; smatch matches; if (!regex_match(line, matches, row)) cerr << "Неправильная строка: " << lineno << '\n'; if (in.eof()) cout << "Конец файла\n"; // проверяем строку: int curr_boy = from_string(matches[2]); int curr_girl = from_string(matches[3]); int curr_total = from_string(matches[4]); if (curr_boy+curr_girl != curr_total) error("Неправильная сумма\n"); if (matches[1]=="Alle klasser") { // последняя строка if (curr_boy != boys) error("Количество мальчиков не сходится\n"); if (curr_girl != girls) error("Количество девочек не сходится\n"); if (!(in>>ws).eof()) error("Символы после итоговой строки"); return 0; } // обновляем суммы: boys += curr_boy; girls += curr_girl; } error("Итоговой строки нет");}Последняя строка по смыслу отличается от остальных: в ней содержатся суммы. Мы распознаем ее по метке (“Alle klasser”). Мы решили, что после последнего символа не должны стоять символы, не являющиеся разделителями (для распознавания этого факта используется функция
lexical_cast()Для того чтобы извлечь числа из полей данных, мы использовали функцию
from_string()stringint23.10. Ссылки
Регулярные выражения — популярный и полезный инструмент, доступный во многих языках программирования и во многих форматах. Они поддерживаются элегантной теорией, основанной на формальных языках, и эффективной технологией реализации, основанной на конечных автоматах. Описание регулярных выражений, их теории, реализации и использования конечных автоматов выходит за рамки рассмотрения настоящей книги. Однако поскольку эта тема в компьютерных науках является довольно стандартной, а регулярные выражения настолько популярны, найти больше информации при необходимости не составляет труда.
Перечислим некоторые из этих источников.
Aho, Alfred V., Monica S. Lam, Ravi Sethi, and Jeffrey D. Ullman. Compilers: Principles, Techniques, and Tools, Second Edition (обычно называемая “The Dragon Book”). Addison-Wesley, 2007. ISBN 0321547985.
Austern, Matt, ed. “Draft Technical Report on C++ Library Extensions”. ISO/IEC DTR 19768, 2005. www.open-std.org/jtc1/sc22/wg21/docs/papers/2005/n2336.pdf.
Boost.org. Хранилище библиотек, согласованных со стандартной библиотекой языка С++. www.boost.org.
Cox, Russ. “Regular Expression Matching Can Be Simple and Fast (but Is Slow in Java, Perl, PHP, Python, Ruby, ...)”. http://swtch.com/~rsc/regexp/regexp1.html.
Maddoc, J. boost::regex documentation. www.boost.org/libs/regex/doc/index.html.
Schwartz, Randal L., Tom Phoenix, and Brian D. Foy. Learning Perl, Fourth Edition.
O’Reilly, 2005. ISBN 0596101058.
Задание
1. Выясните, является ли библиотека
regexstd::regextr1::regex2. Запустите небольшую программу из раздела 23.7; для этого может понадобиться инсталлировать библиотеку
boost::regexregexregex3. Используйте программу из задания 2 для проверки шаблонов из раздела 23.7.
Контрольные вопросы
1. Где мы находим “text”?
2. Какие возможности стандартной библиотеки чаще всего используются для анализа текста?
3. Куда вставляет элемент функция
insert()4. Что такое Unicode?
5. Как конвертировать тип в класс
string6. В чем заключается разница между инструкцией
cin>>sgetline(cin,s)sstring7. Перечислите стандартные потоки.
8. Что собой представляет ключ ассоциативного массива
map9. Как перемещаться по элементам контейнера класса
map10. В чем заключается разница между классами
mapmultimapmapmultimap11. Какие операции требуются для однонаправленного итератора?
12. В чем заключается разница между пустым и отсутствующим полем? Приведите два примера.
13. Зачем нужен символ управляющей последовательности при формировании регулярных выражений?
14. Как превратить регулярное выражение в переменную типа
regex15. Какие строки соответствуют шаблону
\w+\s\d{4}regex16. Как (в программе) выяснить, является ли строка корректным регулярным выражением?
17. Что делает функция
regex_search()18. Что делает функция
regex_match()19. Как представить символ точки (
.20. Как выразить понятие “не меньше трех” в регулярном выражении?
21. Относится ли символ 7 к группе
\w_22. Какое обозначение используется для символов в верхнем регистре?
23. Как задать свой собственный набор символов?
24. Как извлечь значение из целочисленного поля?
25. Как представить число с плавающей точкой с помощью регулярного выражения?
26. Как извлечь число с плавающей точкой из строки, соответствующей шаблону?
27. Что такое частичное совпадение (sub-match)? Как его обнаружить?
Термины

Упражнения
1. Запустите программу, работающую с файлом сообщений электронной почты; протестируйте ее, используя свой собственный, более длинный файл. Убедитесь, что в этом файле есть сообщения, вызывающие сообщения об ошибках, например, сообщения с двумя адресными строками, несколько сообщений с одинаковыми адресами и/или темами и пустые сообщения. Кроме того, протестируйте программу на примере, который вообще не является сообщением и не соответствует программной спецификации, например, на файле, не содержащем строк ----.
2. Добавьте класс
multimap3. Модифицируйте пример из раздела 23.4 и примените регулярные выражения для выявления темы и отправителя сообщения электронной почты.
4. Найдите реальный файл с сообщениями электронной почты (т.е. файл, содержащий реальные сообщения) и модифицируйте программу так, чтобы она могла выявлять темы по именам отправителей, которые вводятся пользователем с клавиатуры.
5. Найдите большой файл с сообщениями электронной почты (тысячи сообщений), а затем запишите его в объекты класса
multimapunordered_multimapmultimap6. Напишите программу, обнаруживающую даты в текстовом файле. Выведите на печать каждую строку, содержащую хотя бы одну дату в формате
linenumber:line7. Напишите программу (аналогичную предыдущей), которая находит номера кредитных карточек в файле. Разберитесь в том, какие форматы на самом деле используются для записи номеров кредитных карточек, и реализуйте их проверку в вашей программе.
8. Модифицируйте программу из раздела 23.8.7 так, чтобы на ее вход поступали шаблон и имя файла. Результатом работы программы должны быть пронумерованные строки (
line–number:line9. Используя функцию
eof()10. Модифицируйте программу для проверки таблицы из раздела 23.9 так, чтобы она выводила новую таблицу, в которой строки, имеющие одинаковые первые цифры (означающие год: первому классу соответствует число 1), были объединены.
11. Модифицируйте программу для проверки таблицы из раздела 23.9 так, чтобы проверить, возрастает или убывает количество учеников с годами.
12. Напишите программу, основываясь на программе, выявляющей строки, содержащие даты (упр. 6), найдите все даты и переведите их в формат ISO год/месяц/день. Эта программа должна считывать информацию из входного файла и выводить ее в выходной файл, идентичный входному, за одним исключением: даты в нем записаны в другом формате.
13. Соответствует ли точка (
.'\n'14. Напишите программу, которую, подобно программе из раздела 23.8.7, можно использовать для экспериментирования с сопоставлением шаблонов с помощью их ввода извне. Однако теперь программа должна считывать данные из файла и записывать их в память (разделение на строки производится с помощью символа перехода на новую строку
'\n'15. Опишите шаблон, который нельзя представить с помощью регулярного выражения.
16. Только для экспертов: докажите, что шаблон из предыдущего упражнения действительно не является регулярным выражением.
Послесловие
Легко впасть в заблуждение, считая, что компьютеры и вычисления относятся только к числам, что вычисления являются частью математики. Очевидно, это не так. Просто посмотрите на экран компьютера; он заполнен текстом и пикселями. Может быть, ваш компьютер еще и воспроизводит музыку. Для каждого приложения важно выбрать правильный инструмент. В контексте языка С++ это значит правильно выбрать подходящую библиотеку. Для манипуляций текстом основным инструментом часто является библиотека регулярных выражений. Кроме того, не следует забывать об ассоциативных контейнерах map и стандартных алгоритмах.
Глава 24 Числа
“Любая сложная проблема имеет ясное, простое
и при этом неправильное решение”.
Г.Л. Менкен (H.L. Mencken)
Эта глава представляет собой обзор основных инструментов для численных расчетов, предоставляемых языком и его библиотекой. Мы рассмотрим фундаментальные проблемы, связанные с размером, точностью и округлением. В центре внимания этой главы — многомерные массивы в стиле языка С и библиотека N-мерных матриц. Мы также опишем генерирование случайных чисел, которые часто необходимы для тестирования и моделирования, а также для программирования игр. В заключение будут упомянуты стандартные математические функции и кратко изложены основные функциональные возможности библиотеки, предназначенные для работы с комплексными числами.
24.1. Введение
Для некоторых людей, скажем, многих ученых, инженеров и статистиков, серьезные числовые расчеты являются основным занятием. В работе многих людей числовые расчеты играют значительную роль. К этой категории относятся специалисты по компьютерным наукам, иногда работающие с физиками. У большинства людей необходимость в числовых расчетах, выходящая за рамки простых арифметических действий над целыми числами и числами с десятичной точкой, возникает редко. Цель этой главы — описать языковые возможности, необходимые для решения простых вычислительных задач. Мы не пытаемся учить читателей численному анализу или тонкостям операций над числами с десятичной точкой; эти темы выходят за рамки рассмотрения нашей книги и тесно связаны с конкретными приложениями. Здесь мы собираемся рассмотреть следующие темы.
• Вопросы, связанные с встроенными типами, имеющими фиксированный размер, например точность и переполнение.
• Массивы, как в стиле языка С, так и класс из библиотека
Matrix• Введение в случайные числа.
• Стандартные математические функции из библиотеки.
• Комплексные числа.
Основное внимание уделено многомерным массивам в стиле языка С и библиотеке N-мерных матриц
Matrix24.2. Размер, точность и переполнение
Когда вы используете встроенные типы и обычные методы вычислений, числа хранятся в областях памяти фиксированного размера; иначе говоря, целочисленные типы (
intlongfloatdoublefloat x = 1.0/333;float sum = 0;for (int i=0; i<333; ++i) sum+=x;cout << setprecision(15) << sum << "\n";Выполнив эту программы, мы получим не единицу, а
0.999999463558197Мы ожидали чего-то подобного. Число с плавающей точкой состоит только из фиксированного количества битов, поэтому мы всегда можем “испортить” его, выполнив вычисление, результат которого состоит из большего количества битов, чем допускает аппаратное обеспечение. Например, рациональное число 1/3 невозможно представить точно как десятичное число (однако можно использовать много цифр его десятичного разложения). Точно так же невозможно точно представить число 1/333, поэтому, когда мы складываем 333 копии числа
xfloat Всегда проверяйте, насколько точными являются результаты. При вычислениях вы должны представлять себе, каким должен быть результат, иначе столкнетесь с глупой ошибкой или ошибкой вычислений. Помните об ошибках округления и, если сомневаетесь, обратитесь за советом к эксперту или почитайте учебники по численным методам.
ПОПРОБУЙТЕ
Замените в примере число 333 числом 10 и снова выполните программу. Какой результат следовало ожидать? Какой результат вы получили? А ведь мы предупреждали!
Влияние фиксированного размера целых чисел может проявиться более резко. Дело в том, что числа с плавающей точкой по определению являются приближениями действительных чисел, поэтому они могут терять точность (т.е. терять самые младшие значащие биты). С другой стороны, целые числа часто переполняются (т.е. теряют самые старшие значащие биты). В итоге ошибки, связанные с числами с плавающей точкой, имеют более сложный характер (которые новички часто не замечают), а ошибки, связанные с целыми числами, бросаются в глаза (их трудно не заметить даже новичку). Мы предпочитаем, чтобы ошибки проявлялись как можно раньше, тогда их легче исправить.
Рассмотрим целочисленную задачу.
short int y = 40000;int i = 1000000;cout << y << " " << i*i << "\n";Выполнив эту программу, получим следующий результат:
–25536 –727379968Этого следовало ожидать. Здесь мы видим эффект переполнения. Целочисленные типы позволяют представить лишь относительно небольшие целые числа. Нам просто не хватит битов, чтобы точно представить каждое целое число, поэтому нам необходим способ, позволяющий выполнять эффективные вычисления. В данном случае двухбайтовое число типа
shortintxxsizeof(x)sizeof(char)==1
Эти размеры характерны для операционной системы Windows и компилятора компании Microsoft. В языке С++ есть много способов представить целые числа и числа с плавающей точкой, используя разные размеры, но при отсутствии важных причин лучше придерживаться типов
charintdoubleЦелое число можно присвоить переменной, имеющей тип числа с плавающей точкой. Если целое число окажется больше, чем может представить тип числа с плавающей точкой, произойдет потеря точности. Рассмотрим пример.
cout << "размеры: " << sizeof(int) << ' ' << sizeof(float) << '\n';int x = 2100000009; // большое целое числоfloat f = x;cout << x << ' ' << f << endl;cout << setprecision(15) << x << ' ' << f << '\n';На нашем компьютере мы получили следующий результат:
Sizes: 4 42100000009 2.1e+0092100000009 2100000000Типы
floatintfloatintf9 С другой стороны, когда мы присваиваем число с плавающей точкой перемен- ной целочисленного типа, происходит усечение; иначе говоря, дробная часть — цифры после десятичной точки — просто отбрасываются. Рассмотрим пример.
float f = 2.8;int x = f;cout << x << ' ' << f << '\n';Значение переменной
x23floatint При вычислениях следует опасаться возможного переполнения и усечения.
Язык C++ не решит эту проблему за вас. Рассмотрим пример.
void f(int i, double fpd){ char c = i; // да: тип char действительно представляет // очень маленькие целые числа short s = i; // опасно: переменная типа int может // не поместиться // в памяти, выделенной для переменной // типа short i = i+1; // что, если число i станет максимальным? long lg = i*i; // опасно: переменная типа long не может // вместить результат float fps = fpd; // опасно: большее число типа large может // не поместиться в типе float i = fpd; // усечение: например, 5.7 –> 5 fps = i; // можно потерять точность (при очень // больших целых)}void g(){ char ch = 0; for (int i = 0; i<500; ++i) cout << int(ch++) << '\t';}Если сомневаетесь, поэкспериментируйте! Не следует отчаиваться и в то же время нельзя просто читать документацию. Без экспериментирования вы можете не понять содержание весьма сложной документации, связанной с числовыми типами.
ПОПРОБУЙТЕ
Выполните функцию
g()f()csi Представление целых чисел и их преобразование еще будет рассматриваться в разделе 25.5.3. По возможности ограничивайтесь немногими типами данных, чтобы минимизировать вероятность ошибок. Например, используя только тип
doublefloatdoublefloatintdoublecomplexcharbool24.2.1. Пределы числовых диапазонов
Каждая реализация языка C++ определяет свойства встроенных типов в заголовках
intcharcout << "количество байтов в типе int: " << sizeof(int) << '\n';cout << "наибольшее число типа int: " << INT_MAX << endl;cout << "наименьшее число типа int: " << numeric_limits::min() << '\n';if (numeric_limits::is_signed) cout << "тип char имеет знак n";else cout << "тип char не имеет знака\n";cout << "char с минимальным значением: " << numeric_limits::min() <<'\n'; cout << "минимальное значение типа char: " << int(numeric_limits::min()) << '\n'; Если вы пишете программу, которая должна работать на разных компьютерах, то возникает необходимость сделать эту информацию доступной для вашей программы. Иначе вам придется “зашить” ответы в программу, усложнив ее сопровождение.
Эти пределы также могут быть полезными для выявления переполнения.
24.3. Массивы
Массив (array) — это последовательность, в которой доступ к каждому элементу осуществляется с помощью его индекса (позиции). Синонимом этого понятия является вектор (vector). В этом разделе мы уделим внимание многомерным массивам, элементами которых являются тоже массивы. Обычно многомерный массив называют матрицей (matrix). Разнообразие синонимов свидетельствует о популярности и полезности этого общего понятия. Стандартные классы
vectorarray
Массивы имеют фундаментальное значение в большинстве вычислений, связанных с так называемым “перемалыванием чисел” (“number crunching”). Наиболее интересные научные, технические, статистические и финансовые вычисления тесно связаны с массивами.
Часто говорят, что массив состоит из строки столбцов.

Столбец — это последовательность элементов, имеющих одинаковые первые координаты (х-координаты). Строка — это множество элементов, имеющих одинаковые вторые координаты (y-координаты).
24.4. Многомерные массивы в стиле языка С
В качестве многомерного массива можно использовать встроенный массив в языке С++ . В этом случае многомерный массив интерпретируется как массив массивов, т.е. массив, элементами которого являются массивы. Рассмотрим пример.
int ai[4]; // 1-мерный массивdouble ad[3][4]; // 2-мерный массивchar ac[3][4][5]; // 3-мерный массивai[1] = 7;ad[2][3] = 7.2;ac[2][3][4] = 'c'; Этот подход наследует все преимущества и недостатки одномерного массива.
• Преимущества
• Непосредственное отображение с помощью аппаратного обеспечения.
• Эффективные низкоуровневые операции.
• Непосредственная языковая поддержка.
• Проблемы
• Многомерные массивы в стиле языка являются массивами массивов(см. ниже).
• Фиксированные размеры (например, фиксированные на этапе компиляции). Если хотите определять размер массива на этапе выполнения программы, то должны использовать свободную память.
• Массивы невозможно передать аккуратно. Массив превращается в указатель на свой первый элемент при малейшей возможности.
• Нет проверки диапазона. Как обычно, массив не знает своего размера.
• Нет операций над массивами, даже присваивания (копирования).
Встроенные массивы широко используются в числовых расчетах. Они также являются основным источником ошибок и сложностей. Создание и отладка таких программ у большинства людей вызывают головную боль. Если вы вынуждены использовать встроенные массивы, почитайте учебники (например, The C++ Programming Language, Appendix C, p. 836–840). К сожалению, язык C++ унаследовал многомерные массивы от языка C, поэтому они до сих пор используются во многих программах.
Большинство фундаментальных проблем заключается в том, что передать многомерные массивы аккуратно невозможно, поэтому приходится работать с указателями и выполнять явные вычисления, связанные с определением позиций в многомерном массиве. Рассмотрим пример.
void f1(int a[3][5]); // имеет смысл только в матрице [3][5]void f2(int [ ][5], int dim1); // первая размерность может быть // переменнойvoid f3(int [5 ][ ], int dim2); // ошибка: вторая размерность // не может быть переменнойvoid f4(int[ ][ ], int dim1, int dim2); // ошибка (совсем // не работает)void f5(int* m, int dim1, int dim2) // странно, но работает{ for (int i=0; i for (int j = 0; j}Здесь мы передаем массив
mint*mdim1, dim2m[i*dim2+j]m[i,j]mm[i,j]Этот способ слишком сложен, примитивен и уязвим для ошибок. Он также слишком медленный, поскольку явное вычисление позиции элемента усложняет оптимизацию. Вместо того чтобы учить вас, как справиться с этой ситуацией, мы сконцентрируемся на библиотеке С++, которая вообще устраняет проблемы, связанные с встроенными массивами.
24.5. Библиотека Matrix
Каково основное предназначение массива (матрицы) в численных расчетах?
• “Мой код должен выглядеть очень похожим на описание массивов, изложенное в большинстве учебников по математике”.
• Это относится также к векторам, матрицам и тензорам.
• Проверка на этапах компиляции и выполнения программы.
• Массивы любой размерности.
• Массивы с произвольным количеством элементов в любой размерности.
• Массивы являются полноценными переменными/объектами.
• Их можно передавать куда угодно.
• Обычные операции над массивами.
• Индексирование:
()• Срезка:
[]• Присваивание:
=• Операции пересчета (
+=–=*=%=• Встроенные векторные операции (например,
res[i] = a[i]*c+b[2]• Скалярное произведение (res = сумма элементов
a[i]*b[i]inner_product• По существу, обеспечивает автоматическое преобразование традиционного исчисления массивов/векторов в текст программы, который в противном случае вы должны были бы написать сами (и добиться, чтобы они были не менее эффективными).
• Массивы при необходимости можно увеличивать (при их реализации не используются “магические” числа).
Библиотека
MatrixMatrixMatrixMatrix.hNumeric_libMatrixMatrix24.5.1. Размерности и доступ
Рассмотрим простой пример.
#include "Matrix.h"using namespace Numeric_lib;void f(int n1, int n2, int n3){ Matrix ad1(n1); // элементы типа double; // одна размерность Matrix ai1(n1); // элементы типа int; // одна размерность ad1(7) = 0; // индексирование ( ) в стиле языка Fortran ad1[7] = 8; // индексирование [ ] в стиле языка C Matrix ad2(n1,n2); // двумерный Matrix ad3(n1,n2,n3); // трехмерный ad2(3,4) = 7.5; // истинное многомерное // индексирование ad3(3,4,5) = 9.2;} Итак, определяя переменную типа
MatrixMatrixMatrixMatrixMatrixMatrixad2(n1,n2) ad2n1n2n1n2MatrixMatrixКак и во встроенных массивах и объектах класса
vectorMatrixMatrix Это просто и взято прямо из учебника. Если у вас возникнут проблемы, нужно лишь обратиться к нужному учебнику по математике, а не к руководству по программированию. Единственная тонкость здесь заключается в том, что мы не указали количество размерностей в объекте класса
MatrixЭто позволяет нам лучше справляться с большим количеством размерностей. Индекс
[x]MatrixaMatrixa[x]Matrix(x,y,z)MatrixПосмотрим, что произойдет, если мы сделаем ошибку.
void f(int n1,int n2,int n3){ Matrix ai0; // ошибка: 0-размерных матриц не бывает Matrix ad1(5); Matrix ai(5); Matrix ad11(7); ad1(7) = 0; // исключение Matrix_error // (7 — за пределами диапазона) ad1 = ai; // ошибка: разные типы элементов ad1 = ad11; // исключение Matrix_error // (разные размерности)Matrix ad2(n1); // ошибка: пропущена длина 2-й // размерности ad2(3) = 7.5; // ошибка: неправильное количество // индексов ad2(1,2,3) = 7.5; // ошибка: неправильное количество // индексов Matrix ad3(n1,n2,n3); Matrix ad33(n1,n2,n3); ad3 = ad33; // OK: одинаковые типы элементов, // одинаковые размерности}Несоответствия между объявленным количеством размерностей и их использованием обнаруживается на этапе компиляции. Выход за пределы диапазона перехватывается на этапе выполнения программы; при этом генерируется исключение
Matrix_error Первая размерность матрицы — это строка, а вторая — столбец, поэтому индекс — это двумерная матрица (двумерный массив), имеющая вид (строка,столбец). Можно также использовать обозначение [строка][столбец], так как индексирование двумерной матрицы с помощью одномерного индекса порождает одномерную матрицу — строку. Эту ситуацию можно проиллюстрировать следующим образом.

Этот объект класса
Matrix
Класс
Matrixvoid init(Matrix& a) // инициализация каждого элемента // характеристическим значением{ for (int i=0; i for (int j = 0; j a(i,j) = 10*i+j;}void print(const Matrix& a) // вывод элементов построчно { for (int i=0; i for (int j = 0; j cout << a(i,j) <<'\t'; cout << '\n'; }} Итак,
dim1()dim2()MatrixMatrixvoid init(Matrix& a); // ошибка: пропущены тип элементов // и количество размерностейОбратите внимание на то, что библиотека
MatrixMatrix24.5.2. Одномерный объект класса Matrix
Что можно сделать с простейшим объектом класса
MatrixКоличество размерностей в объявлении такого объекта можно не указывать, потому что по умолчанию это число равно единице.
Matrix a1(8); // a1 — это одномерная матрица целых чисел Matrix a(8); // т.е. Matrix a(8); Таким образом, объекты
aa1MatrixMatrixMatrixa.size(); // количество элементов в объекте класса Matrixa.dim1(); // количество элементов в первом измеренииМожно также обращаться к элементам матрицы, используя схему их размещения в памяти, т.е. через указатель на ее первый элемент.
int* p = a.data(); // извлекаем данные с помощью указателя на массивЭто полезно при передаче объектов класса
Matrixa(i); // i-й элемент (в стиле языка Fortran) с проверкой // диапазонаa[i]; // i-й элемент (в стиле языка C) с проверкой диапазонаa(1,2); // ошибка: a — одномерный объект класса MatrixМногие алгоритмы обращаются к части объекта класса
Matrixslice()MatrixMatrixa.slice(i); // элементы, начиная с a[i] и заканчивая последнимa.slice(i,n); // n элементов, начиная с a[i] и заканчивая a[i+n–1]Индексы и срезки можно использовать как в левой части оператора присваивания, так и в правой. Они ссылаются на элементы объекта класса
Matrixa.slice(4,4) = a.slice(0,4); // присваиваем первую половину матрицы // второйНапример, если объект a вначале выглядел так:
{ 1 2 3 4 5 6 7 8 }то получим
{ 1 2 3 4 1 2 3 4 }Обратите внимание на то, что чаще всего срезки задаются начальными и последними элементами объекта класса
Matrixa.slice(0,j)[0:j]a.slice(j)[j:a.size()]a.slice(4) = a.slice(0,4); // присваиваем первую половину матрицы // второйИначе говоря, обозначения — дело вкуса. Вы можете указать такие индексы
ina.slice(i,n)aaa.slice(i,a.size())[i:a.size()]a.slice(a.size())a.slice(a.size(),2)Matrixa.slice(i,0)Matrixa.slice(i,n)n0 Копирование всех элементов выполняется как обычно.
Matrix a2 = a; // копирующая инициализация a = a2; // копирующее присваивание К каждому элементу объекта класса
Matrixa *= 7; // пересчет: a[i]*=7 для каждого i (кроме того, +=, –=, /= // и т.д.)a = 7; // a[i]=7 для каждого iЭто относится к каждому оператору присваивания и каждому составному оператору присваивания (
=+=–=/=*=%=^=&=|=>>=<<=Matrixa.apply(f); // a[i]=f(a[i]) для каждого элемента a[i]a.apply(f,7); // a[i]=f(a[i],7) для каждого элемента a[i]Составные операторы присваивания и функция
apply()MatrixMatrixb = apply(abs,a); // создаем новый объект класса Matrix // с условием b(i)==abs(a(i))Функция
absapply(f,x)x.apply(f)++=b = a*7; // b[i] = a[i]*7 для каждого ia *= 7; // a[i] = a[i]*7 для каждого iy = apply(f,x); // y[i] = f(x[i]) для каждого ix.apply(f); // x[i] = f(x[i]) для каждого iВ результате
a==bx==y В языке Fortran второй вариант функции
applyf(x)apply(f,x)fКроме того, для того чтобы обеспечить соответствие с вариантом функции-члена
applya.apply(f,x)b = apply(f,a,x); // b[i]=f(a[i],x) для каждого iРассмотрим пример.
double scale(double d, double s) { return d*s; }b = apply(scale,a,7); // b[i] = a[i]*7 для каждого iОбратите внимание на то, что “автономная” функция
apply()MatrixMatrixapply()Matrixvoid scale_in_place(double& d, double s) { d *= s; }b.apply(scale_in_place,7); // b[i] *= 7 для каждого iВ классе
MatrixMatrix a3 = scale_and_add(a,8,a2); // объединенное умножение // и сложениеint r = dot_product(a3,a); // скалярное произведение Операцию
scale_and_add()result(i)=arg1(i)*arg2+arg3(i)iMatrixinner_productresult+=arg1(i)*arg2(i)iMatrixresultОдномерные массивы очень широко распространены; их можно представить как в виде встроенного массива, так и с помощью классов
vectorMatrixMatrix*=Matrix Полезность этой библиотеки можно объяснить тем, что она лучше согласована с математическими операциями, а также тем, что при ее использовании не приходится писать циклы для работы с каждым элементом матрицы. В любом случае в итоге мы получаем более короткий код и меньше возможностей сделать ошибку. Операции класса
MatrixКласс
MatrixMatrixvoid some_function(double* p, int n){ double val[] = { 1.2, 2.3, 3.4, 4.5 }; Matrix data(p,n); Matrix constants(val); // ...}Это часто бывает полезным, когда мы получаем данные в виде обычных массивов или векторов, созданных в других частях программы, не использующих объекты класса
MatrixОбратите внимание на то, что компилятор может самостоятельно определить количество элементов в инициализированном массиве, поэтому это число при определении объекта
constants4datapn24.5.3. Двумерный объект класса Matrix
Общая идея библиотеки
MatrixMatrixMatrix a(3,4); int s = a.size(); // количество элементовint d1 = a.dim1(); // количество элементов в строкеint d2 = a.dim2(); // количество элементов в столбцеint* p = a.data(); // извлекаем данные с помощью указателя в стиле // языка СМы можем запросить общее количество элементов и количество элементов в каждой размерности. Кроме того, можем получить указатель на элементы, размещенные в памяти в виде матрицы.
Мы можем использовать индексы.
a(i,j); // (i,j)-й элемент (в стиле языка Fortran) с проверкой // диапазонаa[i]; // i-я строка (в стиле языка C) с проверкой диапазонаa[i][j]; // (i,j)-й элемент (в стиле языка C) В двумерном объекте класса
Matrix[i]MatrixiMatrix(a[i].data())a(i,j)a[i][j]
Мы можем получить срезки.
a.slice(i); // строки от a[i] до последнейa.slice(i,n); // строки от a[i] до a[i+n–1]
Срезка двумерного объекта класса
MatrixMatrix a2 = a; // копирующая инициализация a = a2; // копирующее присваиваниеa *= 7; // пересчет (и +=, –=, /= и т.д.)a.apply(f); // a(i,j)=f(a(i,j)) для каждого элемента a(i,j)a.apply(f,7); // a(i,j)=f(a(i,j),7) для каждого элемента a(i,j)b=apply(f,a); // создаем новую матрицу с b(i,j)==f(a(i,j))b=apply(f,a,7); // создаем новую матрицу с b(i,j)==f(a(i,j),7)Оказывается, что перестановка строк также полезна, поэтому мы предусмотрим и ее.
a.swap_rows(1,2); // перестановка строк a[1] <–> a[2] Перестановки столбцов
swap_columns()[i](i,j)iКоличество действий, которые можно было бы выполнить над двумерными матрицами, кажется бесконечным.
enum Piece { none, pawn, knight, queen, king, bishop, rook };Matrix board(8,8); // шахматная доска const int white_start_row = 0;const int black_start_row = 7;Piece init_pos[] = {rook,knight,bishop, queen,king,bishop,knight,rook};Matrix start_row(init_pos); // инициализация элементов из // init_posMatrix clear_row(8); // 8 элементов со значениями // по умолчаниюИнициализация объекта
clear_rownone==0Matrix start_row = {rook,knight,bishop,queen,king,bishop,knight,rook};Однако он не работает (по крайней мере, пока не появится новая версия языка C++ (C++0x)), поэтому пока приходится прибегать к трюкам с инициализацией массива (в данном случае
init_posMatrixstart_rowclear_rowboard[white_start_row] = start_row; // расставить белые фигурыfor (int i = 1; i<7; ++i) board[i] = clear_row; // очистить середину // доскиboard[black_start_row] = start_row; // расставить черные фигурыОбратите внимание на то, что когда мы извлекли строку, используя выражение
[i]lvalueboard[i]24.5.4. Ввод-вывод объектов класса Matrix
Библиотека
MatrixMatrixMatrix a(4); cin >> a;cout << a;Этот фрагмент кода прочитает четыре разделенные пробелами числа типа
double{ 1.2 3.4 5.6 7.8 }Вывод очень прост, поэтому мы просто можем увидеть то, что ввели. Механизм ввода-вывода двумерных объектов класса
MatrixMatrixMatrix m(2,2); cin >> m;cout << m;Он прочитает запись
{ { 1 2 } { 3 4 }}Вывод очень похож.
Операторы
<< >>Matrix<<>>MatrixMatrixIO.hMatrix.hMatrixIO.h24.5.5. Трехмерный объект класса Matrix
По существу, трехмерные объекты класса
MatrixMatrix a(10,20,30); a.size(); // количество элементовa.dim1(); // количество элементов в размерности 1a.dim2(); // количество элементов в размерности 2a.dim3(); // количество элементов в размерности 3int* p = a.data(); // извлекает данные по указателю (в стиле языка С)a(i,j,k); // (i,j,k)-й элемент (в стиле языка Fortran) // с проверкой диапазонаa[i]; // i-я строка (в стиле языка C) // с проверкой диапазонаa[i][j][k]; // (i,j,k)-й элемент (в стиле языка С)a.slice(i); // строки от i-й до последнейa.slice(i,j); // строки от i-й до j-йMatrix a2 = a; // копирующая инициализация a = a2; // копирующее присваиваниеa *= 7; // пересчет (и +=, –=, /= и т.д.)a.apply(f); // a(i,j,k)=f(a(i,j,k)) для каждого элемента a(i,j,k)a.apply(f,7); // a(i,j,k)=f(a(i,j,k),7) для каждого элемента a(i,j,k)b=apply(f,a); // создает новую матрицу с условием b(i,j,k)==f(a(i,j,k))b=apply(f,a,7); // создает новую матрицу с условием b(i,j,k)==f(a(i,j,k),7)a.swap_rows(7,9); // переставляет строки a[7] <–> a[9]Если вы умеете работать с двумерными объектами класса
Matrixaa[i]ia[i][j]ja[i][j][k]intkПоскольку мы видим трехмерный мир, при моделировании чаще используются трехмерные объекты класса
Matrixint grid_nx; // разрешение сетки; задается вначалеint grid_ny;int grid_nz;Matrix cube(grid_nx, grid_ny, grid_nz); Если добавить время в качестве четвертого измерения, то получим четырехмерное пространство, в котором необходимы четырехмерные объекты класса
Matrix24.6. Пример: решение систем линейных уравнений
Если вы знаете, какие математические вычисления выражает программа для численных расчетов, то она имеет смысл, а если нет, то код кажется бессмысленным. Если вы знаете основы линейной алгебры, то приведенный ниже пример покажется вам простым; если же нет, то просто полюбуйтесь, как решение из учебника воплощается в программе с минимальной перефразировкой.
Данный пример выбран для того, чтобы продемонстрировать реалистичное и важное использование класса
Matrixa1,1x1 + ... + a1,nxn = b1
...
an,1x
+ ... + an,nxn = bn1
где буквы x обозначают n неизвестных, а буквы a и b — константы. Для простоты предполагаем, что неизвестные и константы являются числами с плавающей точкой.
Наша цель — найти неизвестные, которые одновременно удовлетворяют указанные n уравнений. Эти уравнения можно компактно выразить с помощью матрицы и двух векторов.
Ax = b
где A — квадратная матрица n×n коэффициентов:

Векторы x и b векторы неизвестных и константа соответственно.

В зависимости от матрицы A и вектора b эта система может не иметь ни одного решения, одно решение или бесконечно много решений. Существует много разных методов решения линейных систем. Мы используем классическую схему, которая называется исключением Гаусса. Сначала мы преобразовываем матрицу A и вектор b, так что матрица А становится верхней треугольной, т.е. все элементы ниже диагонали равны нулю. Иначе говоря, система выглядит так.

Алгоритм несложен. Для того чтобы элемент в позиции (i,j) стал равным нулю, необходимо умножить строку i на константу, чтобы элемент в позиции (i,j) стал равным другому элементу в столбце j, например a(k, j). После этого просто вычтем одно уравнение из другого и получим a(i,j)==0. При этом все остальные значения в строке i изменятся соответственно.
Если все диагональные элементы окажутся ненулевыми, то система имеет единственное решение, которое можно найти в ходе обратной подстановки. Сначала решим последнее уравнение (это просто).
an,nxn = bn
Очевидно, что x[n] равен b[n]/a(n,n). Теперь исключим строку n из системы, найдем значение x[n–1] и будем продолжать процесс, пока не вычислим значение x[1].
При каждом значении n выполняем деление на a(n,n), поэтому диагональные значения должны быть ненулевыми. Если это условие не выполняется, то обратная подстановка завершится неудачей. Это значит, что система либо не имеет решения, либо имеет бесконечно много решений.
24.6.1. Классическое исключение Гаусса
Посмотрим теперь, как этот алгоритм выражается в виде кода на языке С++. Во-первых, упростим обозначения, введя удобные имена для двух типов матриц, которые собираемся использовать.
typedef Numeric_lib::Matrix Matrix; typedef Numeric_lib::Matrix Vector; Затем выразим сам алгоритм.
Vector classical_gaussian_elimination(Matrix A,Vector b){ classical_elimination(A, b); return back_substitution(A, b);}Иначе говоря, мы создаем копии входных матрицы
Abclassical_elimination()back_substitution()void classical_elimination(Matrix& A,Vector& b){ const Index n = A.dim1(); // проходим от первого столбца до последнего, // обнуляя элементы, стоящие ниже диагонали: for (Index j = 0; j const double pivot = A(j, j); if (pivot == 0) throw Elim_failure(j); // обнуляем элементы, стоящие ниже диагонали в строке i for (Index i = j+1; i const double mult = A(i, j) / pivot; A[i].slice(j) = scale_and_add(A[j].slice(j), –mult, A[i].slice(j)); b(i) –= mult * b(j); // изменяем вектор b } }}Опорным называется элемент, лежащий на диагонали в строке, которую мы в данный момент обрабатываем. Он должен быть ненулевым, потому что нам придется на него делить; если он равен нулю, то генерируется исключение.
Vector back_substitution(const Matrix& A, const Vector& b){ const Index n = A.dim1(); Vector x(n); for (Index i = n – 1; i >= 0; ––i) { double s = b(i)–dot_product(A[i].slice(i+1),x.slice(i+1)); if (double m = A(i, i)) x(i) = s / m; else throw Back_subst_failure(i); } return x;} 24.6.2. Выбор ведущего элемента
Для того чтобы избежать проблем с нулевыми диагональными элементами и повысить устойчивость алгоритма, можно переставить строки так, чтобы нули и малые величины на диагонали не стояли. Говоря “повысить устойчивость”, мы имеем в виду понижение чувствительности к ошибкам округления. Однако по мере выполнения алгоритма элементы матрицы будут изменяться, поэтому перестановку строк приходится делать постоянно (иначе говоря, мы не можем лишь один раз переупорядочить матрицу, а затем применить классический алгоритм).
void elim_with_partial_pivot(Matrix& A, Vector& b){ const Index n = A.dim1(); for (Index j = 0; j < n; ++j) { Index pivot_row = j; // ищем подходящий опорный элемент: for (Index k = j + 1; k < n; ++k) if (abs(A(k, j)) > abs(A(pivot_row, j))) pivot_row = k; // переставляем строки, если найдется лучший опорный // элемент if (pivot_row != j) { A.swap_rows(j, pivot_row); std::swap(b(j), b(pivot_row)); } // исключение: for (Index i = j + 1; i < n; ++i) { const double pivot = A(j, j); if (pivot==0) error("Решения нет: pivot==0"); onst double mult = A(i, j)/pivot; A[i].slice(j) = scale_and_add(A[j].slice(j), –mult, A[i].slice(j)); b(i) –= mult * b(j); } }
}Для того чтобы не писать циклы явно и привести код в более традиционный вид, мы используем функции
swap_rows()scale_and_multiply()24.6.3. Тестирование
Очевидно, что мы должны протестировать нашу программу. К счастью, это сделать несложно.
void solve_random_system(Index n){ Matrix A = random_matrix(n); // см. раздел 24.7 Vector b = random_vector(n); cout << "A = " << A << endl; cout << "b = " << b << endl; try { Vector x = classical_gaussian_elimination(A, b); cout << "Решение методом Гаусса x = " << x << endl; Vector v = A * x; cout << " A * x = " << v << endl; } catch(const exception& e) { cerr << e.what() << std::endl; }}Существуют три причины, из-за которых можно попасть в раздел
catch• Ошибка в программе (однако, будучи оптимистами, будем считать, что этого никогда не произойдет).
• Входные данные, приводящие к краху алгоритма
classical_eliminationelim_with_partial_pivot• Ошибки округления.
Тем не менее наш тест не настолько реалистичен, как мы думали, поскольку случайные матрицы вряд ли вызовут проблемы с алгоритмом
classical_eliminationДля того чтобы проверить наше решение, выводим на экране произведение
A*xbif (A*x!=b) error("Неправильное решение");Поскольку числа с десятичной точкой являются лишь приближением действительных чисел, получим лишь приближенный ответ. В принципе лучше не применять операторы
==!=В библиотеке
MatrixVector operator*(const Matrix& m,const Vector& u){ const Index n = m.dim1(); Vector v(n); for (Index i = 0; i < n; ++i) v(i) = dot_product(m[i], u); return v;}И вновь простая операция над объектом класса
MatrixMatrixMatrixIO.hrandom_matrix()random_vector()IndexMatrixtypedefusingusing Numeric_lib::Index;24.7. Случайные числа
Если вы попросите любого человека назвать случайное число, то они назовут 7 или 17, потому что эти числа считаются самыми случайными. Люди практически никогда не называют число нуль, так как оно кажется таким идеально круглым числом, что не воспринимается как случайное, и поэтому его считают наименее случайным числом. С математической точки зрения это полная бессмыслица: ни одно отдельно взятое число нельзя назвать случайным. То, что мы часто называем случайными числами — это последовательность чисел, которые подчиняются определенному закону распределения и которые невозможно предсказать, зная предыдущие числа. Такие числа очень полезны при тестировании программ (они позволяют генерировать множество тестов), в играх (это один из способов гарантировать, что следующий шаг в игре не совпадет с предыдущим) и в моделировании (мы можем моделировать сущность, которая ведет себя случайно в пределах изменения своих параметров).
Как практический инструмент и математическая проблема случайные числа в настоящее время достигли настолько высокой степени сложности, что стали широко использоваться в реальных приложениях. Здесь мы лишь коснемся основ теории случайных чисел, необходимых для осуществления простого тестирования и моделирования. В заголовке
int rand(); // возвращает числа из диапазона // [0:RAND_MAX]RAND_MAX // наибольшее число, которое генерирует // датчик rand()void srand(unsigned int); // начальное значение датчика // случайных чиселПовторяющиеся вызовы функции
rand()int[0:RAND_MAX]rand()srand()srand()rand()Например, рассмотрим функцию
random_vector()random_vector(n)Matrixn[0:n]Vector random_vector(Index n){ Vector v(n); for (Index i = 0; i < n; ++i) v(i) = 1.0 * n * rand() / RAND_MAX; return v;}Обратите внимание на использование числа
1.0RAND_MAX0Сложнее получить целое число из заданного диапазона, например
[0:max]int val = rand()%max;Долгое время такой код считался совершенно неудовлетворительным, поскольку он просто отбрасывает младшие разряды случайного числа, а они, как правило, не обладают свойствами, которыми должны обладать числа, генерируемые традиционными датчиками случайных чисел. Однако в настоящее время во многих операционных системах эта проблема решена достаточно успешно, но для обеспечения переносимости своих программ мы рекомендуем все же скрывать вычисления случайных чисел в функциях.
int randint(int max) { return rand()%max; }int randint(int min, int max) { return randint(max–min)+min; } Таким образом, мы можем скрыть определение функции
randint()rand()Boost::random24.8. Стандартные математические функции
В стандартной библиотеке есть стандартные математические функции (
cossinlog
Стандартные математические функции могут иметь аргументы типов
floatdoublelong doublecomplex Если стандартная математическая функция не может дать корректного результата, она устанавливает флажок
errnoerrno = 0;double s2 = sqrt(–1);if (errno) cerr << "Что-то где-то пошло не так, как надо";if (errno == EDOM) // ошибка из-за выхода аргумента // за пределы области определения cerr << " фунция sqrt() для отрицательных аргументов не определена.";pow(very_large,2); // плохая идеяif (errno==ERANGE) // ошибка из-за выхода за пределы допустимого // диапазона cerr << "pow(" << very_large << ",2) слишком большое число для double";Если вы выполняете серьезные математические вычисления, то всегда должны проверять значение
errno0errno Как показано в примере, ненулевое значение флажка
errnoerrnoerrnoerrnoerrnoEDOMERANGEEDOMERANGEОбработка ошибок с помощью переменной
errno24.9. Комплексные числа
Комплексные числа широко используются в научных и инженерных вычислениях. Мы полагаем, что раз они вам необходимы, значит, вам известны их математические свойства, поэтому просто покажем, как комплексные числа выражаются в стандартной библиотеке языка С++. Объявление комплексных чисел и связанных с ними математических функций находятся в заголовке
template class complex { // комплексное число — это пара скалярных величин, // по существу, пара координат Scalar re, im;public: complex(const Scalar & r, const Scalar & i) :re(r), im(i) { } complex(const Scalar & r) :re(r),im(Scalar ()) { } complex() :re(Scalar ()), im(Scalar ()) { } Scalar real() { return re; } // действительная часть Scalar imag() { return im; } // мнимая часть // операторы : = += –= *= /=};Стандартная библиотека
complexfloatdoublelong doublecomplex
Примечание: в классе
complex<%Класс
complexdoubletypedef complex dcmplx; // иногда выражение complex // является слишком громоздкимvoid f(dcmplx z, vector& vc) { dcmplx z2 = pow(z,2); dcmplx z3 = z2*9.3+vc[3]; dcmplx sum = accumulate(vc.begin(), vc.end(), dcmplx()); // ...}Помните, что не все операции над числами типов
intdoublecomplexif (z2Обратите внимание на то, что представление (схема) комплексных чисел в стандартной библиотеке языка С++ сопоставима с соответствующими типами в языках C и Fortran.
24.10. Ссылки
По существу, вопросы, поднятые в этой главе, такие как ошибки округления, операции над матрицами и арифметика комплексных чисел, сами по себе интереса не представляют. Мы просто описываем некоторые возможности, предоставляемые языком С++, людям, которым необходимо выполнять математические вычисления.
Если вы подзабыли математику, то можете обратиться к следующим источникам информации.
Архив MacTutor History of Mathematics, размещенный на веб-странице http://www-gap.dcs.st-and.ac.uk/~history.
• Отличная веб-страница для всех, кто любит математику или просто хочет ее применять.
• Отличная веб-страница для всех, кто хочет увидеть гуманитарный аспект математики; например, кто из крупных математиков выиграл Олимпийские игры?
• Знаменитые математики: биографии, достижения.
• Курьезы.
• Знаменитые кривые.
• Известные задачи.
• Математические темы.
• Алгебра.
• Анализ.
• Теория чисел.
• Геометрия и топология.
• Математическая физика.
• Математическая астрономия.
• История математики.
• Многое другое
Freeman, T. L., and Chris Phillips. Parallel Numerical Algorithms. Prentice Hall, 1992.
Gullberg, Jan. Mathematics — From the Birth of Numbers. W. W. Norton, 1996. ISBN 039304002X. Одна из наиболее интересных книг об основах и пользе математики, которую можно читать одновременно и с пользой (например, о матрицах), и с удовольствием.
Knuth, Donald E. The Art of Computer Programming, Volume 2: Seminumerical Algorithms, Third Edition. Addison-Wesley, 1998. ISBN: 0202496842.
Stewart, G. W. Matrix Algorithms, Volume I: Basic Decompositions. SIAM, 1998. ISBN 0898714141.
Wood, Alistair. Introduction to Numerical Analysis. Addison-Wesley, 1999. ISBN 020194291X.
Задание
1. Выведите на экран размеры типов
charshortintlongfloatdoubleint*double*sizeof2. Используя оператор
sizeofMatrix a(10) Matrix b(10) Matrix c(10) Matrix d(10,10) Matrix e(10, 10,10) 3. Выведите на печать количество элементов в каждом из объектов, перечисленных в упр. 2.
4. Напишите программу, вводящую числа типа
intcinsqrt()intsqrt(x)xsqrt()5. Считайте десять чисел с плавающей точкой из потока ввода и запишите их в объект типа
MatrixMatrixpush_back()doubleMatrix6. Вычислите таблицу умножения
[0,n]*[0,m]Matrixnmcin7. Введите из потока
cincomplexcin>>complexMatrix8. Запишите шесть чисел типа
intMatrix m(2,3) Контрольные вопросы
1. Кто выполняет числовые расчеты?
2. Что такое точность?
3. Что такое переполнение?
4. Каковы обычные размеры типов
doubleint5. Как обнаружить переполнение?
6. Как определить пределы изменения чисел, например наибольшее число типа
int7. Что такое массив, строка и столбец?
8. Что такое многомерный массив в стиле языка C?
9. Какими свойствами должен обладать язык программирования (например, должна существовать библиотека) для матричных вычислений?
10. Что такое размерность матрицы?
11. Сколько размерностей может иметь матрица?
12. Что такое срезка?
13. Что такое пересылка? Приведите пример.
14. В чем заключается разница между индексированием в стиле языков Fortran и C?
15. Как применить операцию к каждому элементу матрицы? Приведите примеры.
16. Что такое объединенное умножение и сложение (fused operation)?
17. Дайте определение скалярного произведения.
18. Что такое линейная алгебра?
19. Опишите метод исключения Гаусса.
20. Что такое опорный элемент (в линейной алгебре и реальной жизни)?
21. Что делает число случайным?
22. Что такое равномерное распределение?
23. Где найти стандартные математические функции? Для каких типов аргументов они определены?
24. Что такое мнимая часть комплексного числа?
25. Чему равен корень квадратный из –1?
Термины

Упражнения
1. Аргументы функции
fa.apply(f)apply(f,a)triple(){ 1 2 3 4 5 }triple()a.apply(triple)apply(triple,a)apply()2. Повторите упр. 1, используя не функции, а объекты-функции. Подсказка: примеры можно найти в заголовке
Matrix.h3. Только для экспертов (средствами, описанными в книге эту задачу решить невозможно). Напишите функцию
apply(f,a)void (T&)T (const T&)Boost::bind4. Выполните программу исключения методом Гаусса, т.е. завершите ее, скомпилируйте и протестируйте на простом примере.
5. Примените программу исключения методом Гаусса к системе
A=={{0 1}{1 0}}b=={5 6}elim_with_partial_pivot()6. Замените циклами векторные операции
dot_product()scale_and_add()7. Перепишите программу исключения методом Гаусса без помощи библиотеки
MatrixMatrix8. Проиллюстрируйте метод исключения методом Гаусса.
9. Перепишите функцию
apply()MatrixMatrixapply(f,a)MatrixRf10. Насколько случайной является функция
rand()nddrandint(n)[0:n]nd11. Напишите функцию
swap_columns()Matrixswap_columns()swap_rows()12. Реализуйте операторы
Matrix operator*(Matrix&, Matrix&); и
Matrix operator+(Matrix&, Matrix&). При необходимости посмотрите их математические определения в учебниках.
Послесловие
Если вы не любите математику, то, возможно, вам не понравилась эта глава и вы выберете для себя область приложений, в которой изложенная выше информация не понадобится. С другой стороны, если вы любите математику, то мы надеемся, что вы оцените точность выражения математических понятий в представленном нами коде.
Глава 25 Программирование встроенных систем
“Слово “опасный ” означает, что кто-то может умереть”.
Сотрудник службы безопасности
В этой главе мы рассмотрим вопросы программирования встроенных систем; иначе говоря, обсудим темы, связанные в первую очередь с написанием программ для устройств, которые не являются традиционными компьютерами с экранами и клавиатурами. Основное внимание уделяется принципам и методам программирования таких устройств, языковым возможностям и стандартам кодирования, необходимым для непосредственной работы с аппаратным обеспечением. К этим темам относятся управление ресурсами и памятью, использование указателей и массивов, а также манипулирование битами. Главный акцент делается на безопасном использовании, а также на альтернативе использованию низкоуровневых средств. Мы не стремимся описывать специализированные архитектуры устройств или способы прямого доступа к памяти аппаратного обеспечения, для этого существует специализированная литература. В качестве иллюстрации мы выбрали реализацию алгоритма кодирования-декодирования.
25.1. Встроенные системы
Большая часть существующих компьютеров не выглядит как компьютеры. Они просто являются частью более крупной системы или устройства. Рассмотрим примеры.
• Автомобили. В современный автомобиль могут быть встроены десятки компьютеров, управляющих впрыскиванием топлива, следящих на работой двигателя, настраивающих радио, контролирующих тормоза, наблюдающих за давлением в шинах, управляющих дворниками на ветровом стекле и т.д.
• Телефоны. Мобильный телефон содержит как минимум два компьютера; один из них обычно специализируется на обработке сигналов.
• Самолеты. Современный самолет оснащен компьютерами, управляющими буквально всем: от системы развлечения пассажиров до закрылок, оптимизирующих подъемную силу крыла.
• Фотоаппараты. Существуют фотоаппараты с пятью процессорами, в которых каждый объектив имеет свой собственный процессор.
• Кредитные карточки (и все семейство карточек с микропроцессорами).
• Мониторы и контроллеры медицинского оборудования (например, сканеры для компьютерной томографии).
• Грузоподъемники (лифты).
• Карманные компьютеры.
• Кухонное оборудование (например, скороварки и хлебопечки).
• Телефонные коммутаторы (как правило, состоящие из тысяч специализированных компьютеров).
• Контроллеры насосов (например, водяных или нефтяных).
• Сварочные роботы, которые используются в труднодоступных или опасных местах, где человек работать не может.
• Ветряки. Некоторые из них способны вырабатывать мегаватты электроэнергии и имеют высоту до 70 метров.
• Контроллеры шлюзов на дамбах.
• Мониторы качества на конвейерах.
• Устройства считывания штриховых кодов.
• Автосборочные роботы.
• Контроллеры центрифуг (используемых во многих процессах медицинского анализа).
• Контроллеры дисководов.
Эти компьютеры являются частью более крупных систем, которые обычно не похожи на компьютеры и о которых мы никогда не думаем как о компьютерах. Когда мы видим автомобиль, проезжающий по улице, мы не говорим: “Смотрите, поехала распределенная компьютерная система!” И хотя автомобиль в том числе является и распределенной компьютерной системой, ее действия настолько тесно связаны с работой механической, электронной и электрической систем, что мы не можем считать ее изолированным компьютером. Ограничения, наложенные на работу этой системы (временные и пространственные), и понятие корректности ее программ не могут быть отделены от содержащей ее более крупной системы. Часто встроенный компьютер управляет физическим устройством, и корректное поведение компьютера определяется как корректное поведение самого физического устройства. Рассмотрим крупный дизельный судовой двигатель.
Обратите внимание на крышку пятого цилиндра, на котором стоит человек. Это большой двигатель, приводящий в движение большой корабль. Если такой двигатель выйдет из строя, мы узнаем об этом в утренних новостях. У такого двигателя в крышке каждого цилиндра находится управляющая система цилиндра, состоящая из трех компьютеров. Каждая система управления цилиндром соединена с системой управления двигателем (еще три компьютера) посредством двух независимых сетей. Кроме того, система управления двигателем связана с центром управления, в котором механики могут отдавать двигателю команды с помощью специализированной системы графического интерфейса. Всю эту систему можно контролировать дистанционно с помощью радиосигналов (через спутники) из центра управления морским движением. Другие примеры использования компьютеров приведены в главе 1.

Итак, что особенного есть в программах, выполняемых такими компьютерами, с точки зрения программиста? Обобщим вопрос: какие проблемы, не беспокоящие нас в “обычных” программах, выходят на первый план в разнообразных встроенных системах?
• Часто критически важной является надежность. Отказ может привести к тяжелым последствиям: большим убыткам (миллиарды долларов) и, возможно, чьей-то смерти (людей на борту корабля, терпящего бедствие, или животных, погибших вследствие разлива топлива в морских водах).
• Часто ресурсы (память, циклы процессора, мощность) ограничены. Для компьютера, управляющего двигателем, вероятно, это не проблема, но для мобильных телефонов, сенсоров, карманных компьютеров, компьютеров на космических зондах и так далее это важно. В мире, где двухпроцессорные портативные компьютеры с частотой 2 ГГц и объемом ОЗУ 2 Гбайт уже не редкость, главную роль в работе самолета или космического зонда могут играть компьютеры с частотой процессора 60 МГц и объемом памяти 256 Kбайт и даже маленькие устройства с частотой ниже 1 МГц и объемом оперативной памяти, измеряемой несколькими сотнями слов. Компьютеры, устойчивые к внешним воздействиям (вибрации, ударам, нестабильной поставке электричества, жаре, холоду, влаге, топтанию на нем и т.д.), обычно работают намного медленнее, чем студенческие ноутбуки.
• Часто важна реакция в реальном времени. Если инжектор топлива не попадет в инъекционный цикл, то с очень сложной системой мощностью 100 тысяч лошадиных сил может случиться беда; если инжектор пропустит несколько циклов, т.е. будет неисправен около секунды, то с пропеллером 10 метров в диаметре и весом 130 тонн могут произойти странные вещи. Мы бы очень не хотели, чтобы это случилось.
• Часто система должна бесперебойно работать много лет. Эти системы могут быть дорогими, как, например, спутник связи, вращающийся на орбите, или настолько дешевыми, что их ремонт не имеет смысла (например, MP3-плееры, кредитные карточки или инжекторы автомобильных двигателей). В США критерием надежности телефонных коммутаторов считается 20 минут простоя за двадцать лет (даже не думайте разбирать его каждый раз, когда захотите изменить его программу).
• Часто ремонт может быть невозможным или очень редким. Вы можете приводить корабли в гавань для ремонта его компьютеров или других систем каждые два года и обеспечить, чтобы компьютерные специалисты были в нужном месте в нужное время. Однако выполнить незапланированный ремонт часто невозможно (если корабль попадет в шторм посреди Тихого океана, то ошибки в программе могут сыграть роковую роль). Вы просто не сможете послать кого-то отремонтировать космический зонд, вращающийся на орбите вокруг Марса.
Некоторые системы подпадают под все перечисленные выше ограничения, а некоторые — только под одно. Это дело экспертов в конкретной прикладной области. Наша цель — вовсе не сделать из вас эксперта по всем вопросам, это было бы глупо и очень безответственно. Наша цель — ознакомить вас с основными проблемами и концепциями, связанными с их решением, чтобы вы оценили сложность навыков, которые вам потребуются при создании таких систем. Возможно, вы захотите приобрести более глубокие знания. Люди, разрабатывающие и реализующие встроенные системы, играют очень важную роль в развитии технической цивилизации. Это область, в которой профессионалы могут добиться многого.
Относится ли это к новичкам и к программистам на языке С++? Да, и еще раз да. Встроенных систем намного больше, чем обычных персональных компьютеров. Огромная часть программистской работы связана с программированием именно встроенных систем. Более того, список примеров встроенных систем, приведенный в начале раздела, составлен на основе моего личного опыта программирования на языке С++.
25.2. Основные понятия
Большая часть программирования компьютеров, являющихся частями встроенных систем, ничем не отличается от обычного программирования, поэтому к ним можно применить большинство идей, сформулированных в книге. Однако акцент часто другой: мы должны адаптировать средства языка программирования так, чтобы учесть ограничения задачи и часто манипулировать аппаратным обеспечением на самом низком уровне.
• Корректность. Это понятие становится еще более важным, чем обычно. Корректность — это не просто абстрактное понятие. В контексте встроенной системы программа считается корректной не тогда, когда она просто выдает правильные результаты, а тогда, когда она делает это за указанное время, в заданном порядке и с использованием только имеющегося набора ресурсов. В принципе детали понятия корректность тщательно формулируются в каждом конкретном случае, но часто такую спецификацию можно создать только после ряда экспериментов. Часто важные эксперименты можно провести только тогда, когда вся система (вместе с компьютером, на котором будет выполняться программа) уже построена. Исчерпывающая формулировка понятия корректности встроенной системы может быть одновременно чрезвычайно трудной и крайне важной. Слова “чрезвычайно трудная” могут означать “невозможно за имеющееся время и при заданных ресурсах”; мы должны попытаться сделать все возможное с помощью имеющихся средств и методов. К счастью, количество спецификаций, методов моделирования и тестирования и других технологий в заданной области может быть весьма впечатляющим. Слова “крайне важная” могут означать “сбой приводит к повреждению или разрушению”.
• Устойчивость к сбоям. Мы должны тщательно указать набор условий, которым должна удовлетворять программа. Например, при сдаче обычной студенческой программы вы можете считать совершенно нечестным, если преподаватель во время ее демонстрации выдернет провод питания из розетки. Исчезновение электропитания не входит в список условий, на которые должны реагировать обычные прикладные программы на персональных компьютерах. Однако потеря электропитания во встроенных системах может быть обычным делом и ваша программа должна это учитывать. Например, жизненно важные части системы могут иметь двойное электропитание, резервные батареи и т.д. В некоторых приложениях фраза: “Я предполагал, что аппаратное обеспечение будет работать без сбоев” не считается оправданием. Долгое время и в часто изменяющихся условиях аппаратное обеспечение просто не способно работать без сбоев. Например, программы для некоторых телефонных коммутаторов и аэрокосмических аппаратов написаны в предположении, что рано или поздно часть памяти компьютера просто “решит” изменить свое содержание (например, заменит нуль на единицу). Кроме того, компьютер может “решить”, что ему нравится единица, и игнорировать попытки изменить ее на нуль. Если у вас много памяти и вы используете ее достаточно долгое время, то в конце концов такие ошибки возникнут. Если память компьютера подвергается радиационному облучению за пределами земной атмосферы, то это произойдет намного раньше. Когда мы работаем с системой (встроенной или нет), мы должны решить, как реагировать на сбои оборудования. Обычно по умолчанию считают, что аппаратное обеспечение будет работать без сбоев. Если же мы имеем дело с более требовательными системами, то это предположение следует уточнить.
• Отсутствие простоев. Встроенные системы обычно должны долго работать без замены программного обеспечения или вмешательства опытного оператора. “Долгое время” может означать дни, месяцы, годы или все время функционирования аппаратного обеспечения. Это обстоятельство вполне характерно для встроенных систем, но не применимо к огромному количеству “обычных приложений”, а также ко всем примерам и упражнениям, приведенным в книге. Требование “должно работать вечно” выдвигает на первый план обработку ошибок и управление ресурсами. Что такое “ресурс”? Ресурс — это нечто такое, что имеется у машины в ограниченном количестве; программа может получить ресурс путем выполнения явного действия (выделить память) и вернуть его системе (освободить память) явно или неявно. Примерами ресурсов являются память, дескрипторы файлов, сетевые соединения (сокеты) и блокировки. Программа, являющаяся частью долговременной системы, должна освобождать свои ресурсы, за исключением тех, которые необходимы ей постоянно. Например, программа, забывающая закрывать файл каждый день, в большинстве операционных систем не выживет более месяца. Программа, не освобождающая каждый день по 100 байтов, за год исчерпает 32 Кбайт — этого достаточно, чтобы через несколько месяцев небольшое устройство перестало работать. Самое ужасное в такой “утечке” ресурсов заключается в том, что многие месяцы такая программа работает идеально, а потом неожиданно дает сбой. Если уж программа обречена потерпеть крах, то хотелось бы, чтобы это произошло пораньше и у нас было время устранить проблему. В частности, было бы лучше, если бы сбой произошел до того, как программа попадет к пользователям.
• Ограничения реального времени. Встроенную систему можно отнести к системам с жесткими условиями реального времени (hard real time), если она должна всегда давать ответ до наступления заданного срока. Если она должна давать ответ до наступления заданного срока лишь в большинстве случаев, а иногда может позволить себе просрочить время, то такую систему можно отнести к системам с мягкими условиями реального времени. Примерами систем с мягкими условиями реального времени являются контроллеры автомобильных окон и усилитель стереосистемы. Обычный человек все равно не заметит миллисекундной задержки в движении стекол, и только опытный слушатель способен уловить миллисекундное изменение высоты звука. Примером системы с жесткими условиями реального времени является инжектор топлива, который должен впрыскивать бензин в точно заданные моменты времени с учетом движения поршня. Если произойдет хотя бы миллисекундная задержка, то мощность двигателя упадет и он станет портиться; в итоге двигатель может выйти из строя, что, возможно, повлечет за собой дорожное происшествие или катастрофу.
• Предсказуемость. Это ключевое понятие во встроенных системах. Очевидно, что этот термин имеет много интуитивных толкований, но здесь — в контексте программирования встроенных систем — мы используем лишь техническое значение: операция считается предсказуемой (predictable), если на данном компьютере она всегда выполняется за одно и то же время и если все такие операции выполняются за одно и то же время. Например, если
xyxx+yyxxyyfind()• Параллелизм. Встроенные системы обычно реагируют на события, происходящие во внешнем мире. Это значит, что в программе многие события могут происходить одновременно, поскольку они соответствуют событиям в реальном мире, которые могут происходить одновременно. Программа, одновременно выполняющая несколько действий, называется параллельной (concurrent, parallel). К сожалению эта очень интересная, трудная и важная тема выходит за рамки рассмотрения нашей книги.
25.2.1. Предсказуемость
С точки зрения предсказуемости язык С++ очень хорош, но не идеален. Практически все средства языка С++ (включая вызовы виртуальных функций) вполне предсказуемы, за исключением указанных ниже.
• Выделение свободной памяти с помощью операторов
newdelete• Исключения (раздел 19.5).
• Оператор
dynamic_castВ приложениях с жесткими условиями реального времени эти средства использовать не следует. Проблемы, связанные с операторами
newdeletestringvectormapdynamic_castПроблемы с исключениями заключаются в том, что, глядя на конкретный раздел
throwcatchcatchcatchcatchthrow25.2.2. Принципы
При создании программ для встроенных систем существует опасность, что в погоне за высокой производительностью и надежностью программист станет использовать исключительно низкоуровневые средства языка. Эта стратегия вполне оправдана при разработке небольших фрагментов кода. Однако она легко превратит весь проект в непролазное болото, затруднит проверку корректности кода и повысит затраты времени и денег, необходимых для создания системы.
Как всегда, наша цель — работать на как можно более высоком уровне с учетом поставленных ограничений, связанных с нашей задачей. Не позволяйте себе опускаться до хваленого ассемблерного кода! Всегда стремитесь как можно более прямо выражать ваши идеи в программе (при заданных ограничениях). Всегда старайтесь писать ясный, понятный и легкий в сопровождении код. Не оптимизируйте его, пока вас к этому не вынуждают. Эффективность (по времени или по объему памяти) часто имеет большое значение для встроенных систем, но не следует пытаться выжимать максимум возможного из каждого маленького кусочка кода. Кроме того, во многих встроенных системах в первую очередь требуется, чтобы программа работала правильно и достаточно быстро; пока ваша программа работает достаточно быстро, система просто простаивает, ожидая следующего действия. Постоянные попытки написать несколько строчек кода как можно более эффективно занимают много времени, порождают много ошибок и часто затрудняют оптимизацию программ, поскольку алгоритмы и структуры данных становится трудно понимать и модифицировать. Например, при низкоуровневой оптимизации часто невозможно оптимизировать использование памяти, поскольку во многих местах возникает почти одинаковый код, который остальные части программы не могут использовать совместно из-за второстепенных различий. Джон Бентли (John Bentley), известный своими очень эффективными программами, сформулировал два закона оптимизации.
• Первый закон: “Не делай этого!”
• Второй закон (только для экспертов): “Не делай этого пока!”
Перед тем как приступать к оптимизации, следует убедиться в том, что вы понимаете, как работает система. Только когда вы будете уверены в этом, оптимизация станет (или может стать) правильной и надежной. Сосредоточьтесь на алгоритмах и структурах данных. Как только будет запущена первая версия системы, тщательно измерьте ее показатели и настройте как следует. К счастью, часто происходят приятные неожиданности: хороший код иногда работает достаточно быстро и не затрачивает слишком много памяти. Тем не менее не рассчитывайте на это; измеряйте. Неприятные сюрпризы также случаются достаточно часто.
25.2.3. Сохранение работоспособности после сбоя
Представьте себе, что вы должны разработать и реализовать систему, которая не должна выходить из строя. Под словами “не выходить из строя” мы подразумеваем “месяц работать без вмешательства человека”. Какие сбои мы должны предотвратить? Мы можем не беспокоиться о том, что солнце вдруг потухнет или на систему наступит слон. Однако в целом мы не можем предвидеть, что может пойти не так, как надо. Для конкретной системы мы можем и должны выдвигать предположения о наиболее вероятных ошибках. Перечислим типичные примеры.
• Сбой или исчезновение электропитания.
• Вибрация разъема.
• Попадание в систему тяжелого предмета, приводящее к разрушению процессора.
• Падение системы с высоты (от удара диск может быть поврежден).
• Радиоактивное облучение, вызывающее непредсказуемое изменение некоторых значений, записанных в ячейках памяти.
Труднее всего найти преходящие ошибки. Преходящей ошибкой (transient error) мы называем событие, которое случается иногда, а не каждый раз при выполнении программы. Например, процессор может работать неправильно, только если температура превысит 54 °C. Такое событие кажется невозможным, однако однажды оно действительно произошло, когда систему случайно забыли в заводском цехе на полу, хотя в лаборатории ничего подобного никогда не случалось.
Ошибки, которые не возникают в лабораторных условиях, исправить труднее всего. Вы представить себе не можете, какие усилия были предприняты, чтобы инженеры из лаборатории реактивных двигателей могли диагностировать сбои программного и аппаратного обеспечения на марсоходе (сигнал до которого идет двадцать минут) и, поняв в чем дело, устранить проблему.
Знание предметной области, т.е. сведения о системе, ее окружении и применении, играют важную роль при разработке и реализации систем, устойчивых к ошибкам. Здесь мы коснемся лишь самых общих вопросов. Подчеркнем, что каждый из этих общих вопросов был предметом тысяч научных статей и десятилетних исследований.
• Предотвращение утечки ресурсов. Не допускайте утечек. Старайтесь точно знать, какие ресурсы использует ваша программа, и стремитесь их экономить (в идеале). Любая утечка в конце концов выведет вашу систему или подсистему из строя. Самыми важными ресурсами являются время и память. Как правило, программа использует и другие ресурсы, например блокировки, каналы связи и файлы.
• Дублирование. Если для функционирования системы крайне важно, чтобы какое-то устройство работало нормально (например, компьютер, устройство вывода, колесо), то перед проектировщиком возникает фундаментальная проблема выбора: не следует ли продублировать критически важный ресурс? Мы должны либо смириться со сбоем, если аппаратное обеспечение выйдет из строя, или предусмотреть резервное устройство и предоставить его в распоряжение программного обеспечения. Например, контроллеры топливных инжекторов в судовых дизельных двигателях снабжены тремя резервными компьютерами, связанными продублированной сетью. Подчеркнем, что резерв не обязан быть идентичным оригиналу (например, космический зонд может иметь мощную основную антенну и слабую запасную). Отметим также, что в обычных условиях резерв можно также использовать для повышения производительности системы.
• Самопроверка. Необходимо знать, когда программа (или аппаратное обеспечение) работает неправильно. В этом отношении могут оказаться очень полезными компоненты аппаратного обеспечения (например, запоминающие устройства), которые сами себя контролируют, исправляют незначительные ошибки и сообщают о серьезных неполадках. Программное обеспечение может проверять целостность структур данных, инварианты (см. раздел 9.4.3) и полагаться на внутренний “санитарный контроль” (операторы контроля). К сожалению, самопроверка сама по себе является ненадежной, поэтому следует опасаться, чтобы сообщение об ошибке само не вызвало ошибку. Полностью проверить средства проверки ошибок — это действительно трудная задача.
• Быстрый способ выйти из неправильно работающей программы. Составляйте системы из модулей. В основу обработки ошибок должен быть положен модульный принцип: каждый модуль должен иметь свою собственную задачу. Если модуль решит, что не может выполнить свое задание, он может сообщить об этом другому модулю. Обработка ошибок внутри модуля должна быть простой (это повышает вероятность того, что она будет правильной и эффективной), а обработкой серьезных ошибок должен заниматься другой модуль. Высоконадежные системы состоят из модулей и многих уровней. Сообщения о серьезных ошибках, возникших на каждом уровне, передаются на следующий уровень, и в конце концов, возможно, человеку. Модуль, получивший сообщение о серьезной ошибке (которую не может исправить никакой другой модуль), может выполнить соответствующее действие, возможно, связанное с перезагрузкой ошибочного модуля или запуском менее сложного (но более надежного) резервного модуля. Выделить модуль в конкретной системе — задача проектирования, но в принципе модулем может быть класс, библиотека, программа или все программы в компьютере.
• Мониторинг подсистем в ситуациях, когда они не могут самостоятельно сообщить о проблеме. В многоуровневой системе за системами более низкого уровня следят системы более высоких уровней. Многие системы, сбой которых недопустим (например, судовые двигатели или контроллеры космической станции), имеют по три резервные копии критических подсистем. Такое утроение означает не просто наличие двух резервных копий, но и то, что решение о том, какая из подсистем вышла из строя, решается голосованием “два против одного”. Утроение особенно полезно, когда многоуровневая организация представляет собой слишком сложную задачу (например, когда самый высокий уровень системы или подсистемы никогда не должен выходить из строя).
Мы можем спроектировать систему так, как хотели, и реализовать ее так, как умели, и все равно она может оставаться неисправной. Прежде чем передавать пользователям, ее следует систематически и тщательно протестировать (подробнее об этом речь пойдет в главе 26).
25.3. Управление памятью
Двумя основными ресурсами компьютера являются время (на выполнение инструкций) и память (для хранения данных и кода). В языке С++ есть три способа выделения памяти для хранения данных (см. разделы 17.4 и A.4.2).
• Статическая память. Выделяется редактором связей и существует, пока выполняется программа.
• Стековая (автоматическая) память. Выделяется при вызове функции и освобождается после возвращения управления из функции.
• Динамическая память (куча). Выделяется оператором
newdeleteРассмотрим каждую из них с точки зрения программирования встроенных систем. В частности, изучим вопросы управления памятью с точки зрения задач, где важную роль играет предсказуемость (см. раздел 25.2.1), например, при программировании систем с жесткими условиями реального времени и систем с особыми требованиями к обеспечению безопасности.
Статическая память не порождает особых проблем при программировании встроенных систем: вся память тщательно распределяется еще до старта программы и задолго до развертывания системы.
Стековая память может вызывать проблемы, поскольку ее может оказаться недостаточно, но эту проблему устранить несложно. Разработчики системы должны сделать так, чтобы в ходе выполнения программы стек никогда не превышал допустимый предел. Как правило, это означает, что количество вложенных вызовов функций должно быть ограниченным; иначе говоря, мы должны иметь возможность показать, что цепочки вызовов (например,
f1f2fnfactorial(10)factorialfactorialДинамическое распределение памяти обычно запрещено или строго ограничено; иначе говоря, оператор new либо запрещен, либо его использование ограничено периодом запуска программы, а оператор
delete• Предсказуемость. Размещение данных в свободной памяти непредсказуемо; иначе говоря, нет гарантии, что эта операция будет выполняться за постоянное время. Как правило, это не так: во многих реализациях оператора
new • Фрагментация. Свободная память может быть фрагментированной; другими словами, после размещения и удаления объектов оставшаяся память может содержать большое количество “дыр”, представляющих собой неиспользуемую память, которая бесполезна, потому что каждая “дыра” слишком мала для того, чтобы в ней поместился хотя бы один объект, используемый в приложении. Таким образом, размер полезной свободной памяти может оказаться намного меньше разности между первоначальным размером и размером размещенных объектов.
В следующем разделе мы продемонстрируем. как может возникнуть такая неприемлемая ситуация. Отсюда следует, что мы должны избегать методов программирования, использующих операторы
newdelete25.3.1. Проблемы со свободной памятью
В чем заключается проблема, связанная с оператором
newnewdeleteMessage* get_input(Device&); // создаем объект класса Message // в свободной памятиwhile(/* ... */) { Message* p = get_input(dev); // ... Node* n1 = new Node(arg1,arg2); // ... delete p; Node* n2 = new Node (arg3,arg4); // ...}Каждый раз, выполняя этот цикл, мы создаем два объекта класса
NodeMessage2*sizeof(Node)2*sizeof(Node)Представим себе простой (хотя и вполне вероятный) механизм управления памятью. Допустим также, что объект класса
MessageNodeMessageNode
Итак, каждый раз, проходя цикл, мы оставляем неиспользованную память (“дыру”). Эта память может составлять всего несколько байтов, но если мы не можем использовать их, то это равносильно утечке памяти, а даже малая утечка рано или поздно выводит из строя долговременные системы. Разбиение свободной памяти на многочисленные “дыры”, слишком маленькие для того, чтобы в них можно было разместить объекты, называется фрагментацией памяти (memory fragmentation). В конце концов, механизм управления свободной памятью займет все “дыры”, достаточно большие для того, чтобы разместить объекты, используемые программой, оставив только одну “дыру”, слишком маленькую и потому бесполезную. Это серьезная проблема для всех достаточно долго работающих программ, широко использующих операторы
newdeleteПочему ни язык, ни система не может решить эту проблему? А нельзя ли написать программу, которая вообще не создавала бы “дыр” в памяти? Сначала рассмотрим наиболее очевидное решение проблемы маленьких бесполезных “дыр” в памяти: попробуем переместить все объекты класса
NodeК сожалению, система не может этого сделать. Причина заключается в том, что код на языке С++ непосредственно ссылается на объекты, размещенные в памяти. Например, указатели
n1n2
Теперь мы уплотняем память, перемещаем объекты так, чтобы неиспользуемая память стала непрерывным фрагментом.

К сожалению, переместив объекты и не обновив указатели, которые на них ссылались, мы создали путаницу. Почему же мы не обновили указатели, перемещая объекты? Мы могли бы написать такую программу, только зная детали структуры данных. В принципе система (т.е. система динамической поддержки языка С++) не знает, где хранятся указатели; иначе говоря, если у нас есть объект, то вопрос: “Какие указатели ссылаются на данный объект в данный момент?” не имеет ответа. Но даже если бы эту проблему можно было легко решить, такой подход (известный как уплотняющая сборка мусора (compacting garbage collection)) не всегда оправдывает себя. Например, для того чтобы он хорошо работал, обычно требуется, чтобы свободной памяти было в два раза больше, чем памяти, необходимой системе для отслеживания указателей и перемещения объектов. Этой избыточной памяти во встроенной системе может не оказаться. Кроме того, от эффективного механизма уплотняющей сборки мусора трудно добиться предсказуемости.
Можно, конечно, ответить на вопрос “Где находятся указатели?” для наших структур данных и уплотнить их, но проще вообще избежать фрагментации в начале блока. В данном примере мы могли бы просто разместить оба объекта класса
NodeMessagewhile( ... ) { Node* n1 = new Node; Node* n2 = new Node; Message* p = get_input(dev); // ...храним информацию в узлах... delete p; // ...}Однако перестройка кода для предотвращения фрагментации в общем случае не такая простая задача. Решить ее надежно очень трудно. Часто это приводит к противоречиям с другими правилами создания хороших программ. Вследствие этого мы предпочитаем ограничивать использование свободной памяти только методами, позволяющими избежать фрагментации в начале блока. Часто предотвратить проблему проще, чем ее решить.
ПОПРОБУЙТЕ
Выполните программу, приведенную выше, и выведите на печать адреса и размеры созданных объектов, чтобы увидеть, как возникают “дыры” в памяти и возникают ли они вообще. Если у вас есть время, можете нарисовать схему памяти, подобную показанным выше, чтобы лучше представить себе, как происходит фрагментация.
25.3.2. Альтернатива универсальной свободной памяти
Итак, мы не должны провоцировать фрагментацию памяти. Что для этого необходимо сделать? Во-первых, сам по себе оператор
newdeletedelete Если оператор
deletenewnew Существуют две структуры данных, которые особенно полезны для предсказуемого выделения памяти.
• Стеки. Стек (stack) — это структура данных, в которой можно разместить любое количество данных (не превышающее максимального размера), причем удалить можно только данные, которые были размещены последними; т.е. стек может расти и уменьшаться только на вершине. Он не вызывает фрагментации памяти, поскольку между двумя его ячейками не может быть “дыр”.
• Пулы. Пул (pool) — это коллекция объектов одинаковых размеров. Мы можем размещать объекты в пуле и удалять их из него, но не можем поместить в нем больше объектов, чем позволяет его размер. Фрагментация памяти при этом не возникает, поскольку объекты имеют одинаковые размеры.
Операции размещения и удаления объектов в стеках и пулах выполняются предсказуемо и быстро.
Таким образом, в системах с жесткими условиями реального времени и в системах, предъявляющих особые требования к обеспечению безопасности, при необходимости можно использовать стеки и пулы. Кроме того, желательно иметь возможность использовать стеки и пулы, разработанные, реализованные и протестированные независимыми поставщиками (при условии, что их спецификации соответствуют нашим требованиям).
Обратите внимание на то, что стандартные контейнеры языка С++ (
vectormapstringnew Следует подчеркнуть, что встроенные системы обычно выдвигают очень строгие требования к надежности, поэтому, принимая решение, вы ни в коем случае не должны отказываться от нашего стиля программирования, опускаясь на уровень низкоуровневых средств. Программа, заполненная указателями, явными преобразованиями и другими подобными вещами, редко бывает правильной.
25.3.3. Пример пула
Пул — это структура данных, из которой мы можем доставать объекты заданного типа, а затем удалять их оттуда. Пул содержит максимальное количество объектов, которое задается при его создании. Используя темно-серый цвет для размещенного объекта и светло-серый для места, готового для размещения объекта, мы можем проиллюстрировать пул следующим образом.

Класс
Pooltemplateclass Pool { // Пул из N объектов типа T public: Pool(); // создаем пул из N объектов типа T T* get(); // берем объект типа T из пула; // если свободных объектов нет, // возвращаем 0 void free(T*); // возвращаем объект типа T, взятый // из пула с помощью функции get() int available() const; // количество свободных объектов типа Tprivate: // место для T[N] и данные, позволяющие определить, какие объекты // извлечены из пула, а какие нет (например, список свободных // объектов)};Каждый объект класса
PoolPool sb_pool; Pool indicator_pool; Small_buffer* p = sb_pool.get();// ...sb_pool.free(p);Гарантировать, что пул никогда не исчерпается, — задача программиста. Точный смысл слова “гарантировать” зависит от приложения. В некоторых системах программист должен написать специальный код, например функцию
get()get()dial_buffer_pool.get()0Естественно, наш шаблонный класс
Pool25.3.4. Пример стека
Стек — это структура данных, из которой можно брать порции памяти и освобождать последнюю занятую порцию. Используя темно-серый цвет для размещенного объекта и светло-серый для места, готового для размещения объекта, мы можем проиллюстрировать пул следующим образом.

Как показано на рисунке, этот стек “растет” вправо. Стек объектов можно было бы определить как пул.
template class Stack { // стек объектов типа T // ...};Однако в большинстве систем необходимо выделять память для объектов разных размеров. В стеке это можно сделать, а в пуле нет, поэтому мы покажем определение стека, из которого можно брать “сырую” память для объектов, имеющих разные размеры.
templateclass Stack { // стек из N байтов public: Stack(); // создает стек из N байтов void* get(int n); // выделяет n байтов из стека; // если свободной памяти нет, // возвращает 0 void free(); // возвращает последнее значение, // возвращенное функцией get() int available() const; // количество доступных байтовprivate: // память для char[N] и данные, позволяющие определить, какие // объекты извлечены из стека, а какие нет (например, // указатель на вершину)};Поскольку функция
get()void*Stack<50*1024> my_free_store; // 50K памяти используется как стекvoid* pv1 = my_free_store.get(1024);int* buffer = static_cast(pv1); void* pv2 = my_free_store.get(sizeof(Connection));Connection* pconn = new(pv2) Connection(incoming,outgoing,buffer);Использование оператора
static_castnew(pv2)pv2incoming,outgoing,bufferЕстественно, наш шаблонный класс
Stack25.4. Адреса, указатели и массивы
Предсказуемость требуется в некоторых встроенных системах, а надежность — во всех. Это заставляет нас избегать некоторых языковых конструкций и методов программирования, уязвимых для ошибок (в контексте программирования встроенных систем). В языке С++ основным источником проблем является неосторожное использование указателей.
Выделим две проблемы.
• Явные (непроверяемые и опасные) преобразования.
• Передача указателей на элементы массива.
Первую проблему можно решить, строго ограничив использование явных преобразований типов (приведения). Проблемы, связанные с указателями и массивами, имеют более тонкие причины, требуют понимания и лучше всего решаются с помощью (простых) классов или библиотечных средств (например, класса array; см. раздел 20.9). По этой причине в данном разделе мы сосредоточимся на решении второй задачи.
25.4.1. Непроверяемые преобразования
Физические ресурсы (например, регистры контроллеров во внешних устройствах) и их основные средства управления в низкоуровневой системе имеют конкретные адреса. Мы должны указать эти адреса в наших программах и присвоить этим данных некий тип. Рассмотрим пример.
Device_driver* p = reinterpret_cast(0xffb8); Эти преобразования описаны также в разделе 17.8. Именно этот вид программирования требует постоянного использования справочников. Между ресурсом аппаратного обеспечения — адресом регистра (выраженного в виде целого числа, часто шестнадцатеричного) — и указателями в программном обеспечении, управляющим аппаратным обеспечением, существует хрупкое соответствие. Вы должны обеспечить его корректность без помощи компилятора (поскольку эта проблема не относится к языку программирования). Обычно простой (ужасный, полностью непроверяемый) оператор
reinterpret_castintЕсли явные преобразования (
reinterpret_caststatic_cast25.4.2. Проблема: дисфункциональный интерфейс
Как указывалось в разделе 18.5.1, массив часто передается функции как указатель на элемент (часто как указатель на первый элемент). В результате он “теряет” размер, поэтому получающая его функция не может непосредственно определить количество элементов, на которые ссылается указатель. Это может вызвать много трудноуловимых и сложно исправимых ошибок. Здесь мы рассмотрим проблемы, связанные с массивами и указателями, и покажем альтернативу. Начнем с примера очень плохого интерфейса (к сожалению, встречающегося довольно часто) и попытаемся его улучшить.
void poor(Shape* p, int sz) // плохой проект интерфейса{ for (int i = 0; i}void f(Shape* q, vector& s0) // очень плохой код { Polygon s1[10]; Shape s2[10]; // инициализация Shape* p1 = new Rectangle(Point(0,0),Point(10,20)); poor(&s0[0],s0.size()); // #1 (передача массива из вектора) poor(s1,10); // #2 poor(s2,20); // #3 poor(p1,1); // #4 delete p1; p1 = 0; poor(p1,1); // #5 poor(q,max); // #6} Функция
poor()ПОПРОБУЙТЕ
Прежде чем читать дальше, попробуйте выяснить, сколько ошибок вы можете найти в функции
f()poor()На первый взгляд данный вызов выглядит отлично, но это именно тот вид кода, который приносит программистам бессонные ночи отладки и вызывает кошмары у инженеров по качеству.
1. Передается элемент неправильного типа (например,
poor(&s0[0],s0.size()s0&s0[0]2. Используется “магическая константа” (в данном случае правильная):
poor(s1,10)3. Используется “магическая константа” (в данном случае неправильная):
poor(s2,20)4. Первый вызов
poor(p1,1)5. Передача нулевого указателя при втором вызове:
poor(p1,1)6. Вызов
poor(q,max)qqmaxВ каждом из перечисленных вариантов ошибки были простыми. Мы не столкнулись с какими-либо скрытыми ошибками, связанными с алгоритмами и структурами данных. Проблема заключается в интерфейсе функции
poor()p1s0Теоретически компилятор может выявить некоторые из этих ошибок (например, второй вызов
poor(p1,1)p1==0Shapepoor()ShapeКак мы пришли к выводу, что вызов
poor(&s0[0],s0.size())&s0[0]CircleCircle*Shape*ShapeCircle*Shapepoor()Shape*for (int i = 0; iИначе говоря, она ищет элементы, начиная с ячеек
&p[0]&p[1]&p[2]
В терминах адресов ячеек памяти эти указатели находятся на расстоянии
sizeof(Shape)poor()sizeof(Circle)sizeof(Shape)
Другими словами, функция
poor()draw()Circle Вызов функции
poor(s1,10)PolygonCirclePolygonShapeCirclesizeof(Shape)==sizeof(Polygon)PolygonShapePolygonpoor(s1,10)То, с чем мы столкнулись, является основанием для формулировки универсального правила, согласно которому из утверждения “класс
DBContainerContainerclass Circle:public Shape { /* ... */ };void fv(vector&); void f(Shape &);void g(vector& vd, Circle & d) { f(d); // OK: неявное преобразование класса Circle в класс Shape fv(vd); // ошибка: нет преобразования из класса vector // в класс vector} Хорошо, интерфейс функции
poor() Итак, мы не хотим передавать функциям встроенные массивы с помощью указателей и размера массива. Чем это заменить? Проще всего передать ссылку на контейнер, например, на объект класса vector. Проблема, которая возникла в связи с интерфейсом функции
void poor(Shape* p, int sz);исчезает при использовании функции
void general(vector&); Если вы программируете систему, в которой допускаются объекты класса
std::vectorvectorЕсли вы не можете ограничиться использованием класса
vectorArray_ref25.4.3. Решение: интерфейсный класс
К сожалению, во многих встроенных системах мы не можем использовать класс
std::vectorvectorvector • Он ссылается на объекты в памяти (он не владеет объектами, не размещает их, не удаляет и т.д.).
• Он знает свой размер (а значит, способен проверять выход за пределы допустимого диапазона).
• Он знает точный тип своих элементов (а значит, не может порождать ошибки, связанные с типами).
• Его несложно передать (скопировать) как пару (указатель, счетчик).
• Его нельзя неявно преобразовать в указатель.
• Он позволяет легко выделить поддиапазон в целом диапазоне.
• Его легко использовать как встроенный массив.
Свойство “легко использовать как встроенный массив” можно обеспечить лишь приблизительно. Если бы мы сделали это совершенно точно, то вынуждены были бы смириться с ошибками, которых стремимся избежать.
Рассмотрим пример такого класса.
templateclass Array_ref {public: Array_ref(T* pp, int s) :p(pp), sz(s) { } T& operator[ ](int n) { return p[n]; } const T& operator[ ](int n) const { return p[n]; } bool assign(Array_ref a) { if (a.sz!=sz) return false; for (int i=0; i return true; } void reset(Array_ref a) { reset(a.p,a.sz); } void reset(T* pp, int s) { p=pp; sz=s; } int size() const { return sz; } // операции копирования по умолчанию: // класс Array_ref не владеет никакими ресурсами // класс Array_ref имеет семантику ссылкиprivate: T* p; int sz;};Класс
Array_ref• В нем нет функций
push_back()at()• Класс Array_ref имеет форму ссылки, поэтому операция копирования просто копирует пары (
p, sz• Инициализируя разные массивы, можем получить объекты класса
Array_ref• Обновляя пару (
p, sizereset()Array_ref• В классе
Array_refArray_refКласс
Array_refarrayДля того чтобы облегчить создание объектов класса
Array_reftemplate Array_ref make_ref(T* pp, int s) { return (pp) ? Array_ref(pp,s):Array_ref(0,0); }Если мы инициализируем объект класса
Array_refPolygon[10]Shape*Мы решили проявить осторожность в отношении нулевых указателей (поскольку это обычный источник проблем) и пустых векторов.
template Array_ref make_ref(vector& v) { return (v.size()) ? Array_ref(&v[0],v.size()): Array_ref(0,0); }Идея заключается в том, чтобы передавать вектор элементов. Мы выбрали класс
vectorArray_refВ заключение предусмотрим обработку встроенных массивов в ситуациях, в которых компилятор знает их размер.
template Array_ref make_ref(T (&pp)[s]) { return Array_ref(pp,s); }Забавное выражение
T(&pp)[s]ppsTArray_refPolygon ar[0]; // ошибка: элементов нетИспользуя данный вариант класса
Array_refvoid better(Array_ref a) { for (int i = 0; i}void f(Shape* q, vector& s0) { Polygon s1[10]; Shape s2[20]; // инициализация Shape* p1 = new Rectangle(Point(0,0),Point(10,20)); better(make_ref(s0)); // ошибка: требуется Array_ref better(make_ref(s1)); // ошибка: требуется Array_ref better(make_ref(s2)); // OK (преобразование не требуется) better(make_ref(p1,1)); // OK: один элемент delete p1; p1 = 0; better(make_ref(p1,1)); // OK: нет элементов better(make_ref(q,max)); // OK (если переменная max задана корректно)}Мы видим улучшения.
• Код стал проще. Программисту редко приходится заботиться о размерах объектов, но когда это приходится делать, они задаются в специальном месте (при создании объекта класса
Array_ref• Проблема с типами, связанная с преобразованиями
Circle[]Shape[]Polygon[]Shape[]• Проблемы с неправильным количеством элементов объектов
s1s2• Потенциальная проблема с переменной max (и другими счетчиками элементов, необходимыми для использования указателей) становится явной — это единственное место, где мы должны явно указать размер.
• Использование нулевых указателей и пустых векторов предотвращается неявно и систематически.
25.4.4. Наследование и контейнеры
Что делать, если мы хотим обрабатывать коллекцию объектов класса
CircleShapebetter()draw_all()vectorvectorArray_refArray_ref Более того, для того чтобы сохранить динамический полиморфизм, мы должны манипулировать нашими полиморфными объектами с помощью указателей (или ссылок): точка в выражении
a[i].draw()better()–>Что нам делать? Во-первых, мы должны работать с указателями (или ссылками), а не с самими объектами, поэтому следует попытаться использовать классы
Array_refArray_refArray_refArray_refОднако мы по-прежнему не можем конвертировать класс
Array_refArray_refArray_refCircle*• Мы не хотим модифицировать наш объект класса
Array_refShapeArray_refArray_refArray_ref• Все массивы указателей имеют одну и ту же схему (независимо от объектов, на которые они ссылаются), поэтому нас не должна волновать проблема, упомянутая в разделе 25.4.2.
Иначе говоря, не произойдет ничего плохого, если объект класса
Array_refArray_ref
Нет никаких логических препятствий интерпретировать данный массив указателей типа
Circle*Shape*Array_ref Похоже, что мы забрели на территорию экспертов. Эта проблема очень сложная, и ее невозможно устранить с помощью рассмотренных ранее средств. Однако, устранив ее, мы можем предложить почти идеальную альтернативу дисфункциональному, но все еще весьма популярному интерфейсу (указатель плюс количество элементов; см. раздел 25.4.2). Пожалуйста, запомните: никогда не заходите на территорию экспертов, просто чтобы продемонстрировать, какой вы умный. В большинстве случаев намного лучше найти библиотеку, которую некие эксперты уже спроектировали, реализовали и протестировали для вас. Во-первых, мы переделаем функцию
better()void better2(const Array_ref a) { for (int i = 0; i if (a[i]) a[i]–>draw();}Теперь мы работаем с указателями, поэтому должны предусмотреть проверку нулевого показателя. Для того чтобы гарантировать, что функция
better2()Array_refconstconstArray_refassign()reset()const*Далее, мы должны устранить главную проблему: как выразить идею, что объект класса
Array_ref• в нечто подобное объекту класса
Array_refbetter2()• но только если объект класса
Array_refЭто можно сделать, добавив в класс
Array_reftemplateclass Array_ref {public: // как прежде template operator const Array_ref() { // проверка неявного преобразования элементов: static_cast(*static_cast(0));
// приведение класса Array_ref: return Array_ref(reinterpret_cast(p),sz); } // как прежде};Это похоже на головоломку, но все же перечислим ее основные моменты.
• Оператор приводит каждый тип
QArray_refArray_refArray_ref• Мы создаем новый объект класса
Array_refreinterpret_castArray_ref• Обратите внимание на квалификатор
constArray_refArray_refArray_refМы предупредили вас о том, что зашли на территорию экспертов и столкнулись с головоломкой. Однако эту версию класса
Array_refvoid f(Shape* q, vector& s0) { Polygon* s1[10]; Shape* s2[20]; // инициализация Shape* p1 = new Rectangle(Point(0,0),10); better2(make_ref(s0)); // OK: преобразование // в Array_ref better2(make_ref(s1)); // OK: преобразование // в Array_ref better2(make_ref(s2)); // OK (преобразование не требуется) better2(make_ref(p1,1)); // ошибка better2(make_ref(q,max)); // ошибка}Попытки использовать указатели приводят к ошибкам, потому что они имеют тип
Shape*better2()Array_refbetter2()better2()make_ref(&p1,1) В заключение отметим, что мы можем создавать простые, безопасные, удобные и эффективные интерфейсы, компенсируя недостатки массивов. Это была основная цель данного раздела. Цитата Дэвида Уилера (David Wheeler): “Каждая проблема решается с помощью новой абстракции” считается первым законом компьютерных наук. Именно так мы решили проблему интерфейса.
25.5. Биты, байты и слова
Выше мы уже упоминали о понятиях, связанных с устройством компьютерной памяти, таких как биты, байты и слова, но в принципе они не относятся к основным концепциям программирования. Вместо этого программисты думают об объектах конкретных типов, таких как
doublestringMatrixSimple_windowЕсли вы плохо помните двоичное и шестнадцатеричное представления целых чисел, то обратитесь к разделу A.2.1.1.
25.5.1. Операции с битами и байтами
Байт — это последовательность, состоящая из восьми битов.

Биты в байте нумеруются справа (от самого младшего бита) налево (к самому старшему). Теперь представим слово как последовательность, состоящую из четырех битов.

Нумерация битов в слове также ведется справа налево, т.е. от младшего бита к старшему. Этот рисунок слишком идеализирует реальное положение дел: существуют компьютеры, в которых байт состоит из девяти бит (правда, за последние десять лет мы не видели ни одного такого компьютера), а машины, в которых слово состоит из двух бит, совсем не редкость. Однако будем считать, что в вашем компьютере байт состоит из восьми бит, а слово — из четырех.
Для того чтобы ваша программа была переносимой, используйте заголовок
Как представить набор битов в языке C++? Ответ зависит от того, сколько бит вам требуется и какие операции вы хотите выполнять удобно и эффективно. В качестве наборов битов можно использовать целочисленные типы.
•
bool•
char•
short•
int•
long intУказанные выше размеры являются типичными, но в разных реализациях они могут быть разными, поэтому в каждом конкретном случае следует провести тестирование. Кроме того, в стандартных библиотеках есть свои средства для работы с битами.
•
std::vector•
std::bitset•
std::set• Файл: много битов (раздел 25.5.6).
Более того, для представления битов можно использовать два средства языка С++.
• Перечисления (
enum• Битовые поля; см. раздел 25.5.5.
Это разнообразие способов представления битов объясняется тем, что в конечном счете все, что существует в компьютерной памяти, представляет собой набор битов, поэтому люди испытывают необходимость иметь разные способы их просмотра, именования и выполнения операций над ними. Обратите внимание на то, что все встроенные средства работают с фиксированным количеством битов (например, 8, 16, 32 и 64), чтобы компьютер мог выполнять логические операции над ними с оптимальной скоростью, используя операции, непосредственно обеспечиваемые аппаратным обеспечением. В противоположность им средства стандартной библиотеки позволяют работать с произвольным количеством битов. Это может ограничивать производительность, но не следует беспокоиться об этом заранее: библиотечные средства могут быть — и часто бывают — оптимизированными, если количество выбранных вами битов соответствует требованиям аппаратного обеспечения.
Рассмотрим сначала целые числа. Для них в языке C++ предусмотрены побитовые логические операции, непосредственно реализуемые аппаратным обеспечением. Эти операции применяются к каждому биту своих операндов.

Вам может показаться странным то, что в число фундаментальных операций мы включили “исключительное или” (
^<<ostreamСледует подчеркнуть, что оператор
&&&|||&&||truefalseРассмотрим несколько примеров. Обычно битовые комбинации выражаются в шестнадцатеричном виде. Для полубайта (четыре бита) используются следующие коды.

Для представления чисел, не превышающих девяти, можно было бы просто использовать десятичные цифры, но шестнадцатеричное представление позволяет не забывать, что мы работаем с битовыми комбинациями. Для байтов и слов шестнадцатеричное представление становится действительно полезным. Биты, входящие в состав байта, можно выразить с помощью двух шестнадцатеричных цифр.

Итак, используя для простоты тип
unsignedunsigned char a = 0xaa;unsigned char x0 = ~a; // дополнение a
unsigned char b = 0x0f;unsigned char x1 = a&b; // a и b
unsigned char x2 = a^b; // исключительное или: a xor b
unsigned char x3 = a<<1; // сдвиг влево на один разряд
Вместо бита, который был “вытолкнут” с самой старшей позиции, в самой младшей позиции появляется нуль, так что байт остается заполненным, а крайний левый бит (седьмой) просто исчезает.
unsigned char x4 == a>>2; // сдвиг вправо на два разряда
В двух позициях старших битов появились нули, которые обеспечивают заполнение байта, а крайние правые биты (первый и нулевой) просто исчезают.
Мы можем написать много битовых комбинаций и потренироваться в выполнении операций над ними, но это занятие скоро наскучит. Рассмотрим маленькую программу, переводящую целые числа в их битовое представление.
int main(){ int i; while (cin>>i) cout << dec << i << "==" << hex << "0x" << i << "==" << bitset<8*sizeof(int)>(i) << '\n';}Для того чтобы вывести на печать отдельные биты целого числа, используется класс
bitsetbitset<8*sizeof(int)>(i)Класс
bitset8*sizeof(int)bitsetiПОПРОБУЙТЕ
Скомпилируйте программу для работы с битовыми комбинациями и попробуйте создать двоичные и шестнадцатеричные представления нескольких чисел. Если вас затрудняет представление отрицательных чисел, перечитайте раздел 25.5.3 и попробуйте снова.
25.5.2. Класс bitset
Для представления наборов битов и работы с ними используется стандартный шаблонный класс
bitsetbitsetbitset<4> flags;bitset<128> dword_bits;bitset<12345> lots;Объект класса
bitsetbitsetbitset<4> flags = 0xb;bitset<128> dword_bits(string("1010101010101010"));bitset<12345> lots;Здесь объект
lotsdword_bitsbitset'0''1'std::invalid_argumentstring s;cin>>s;bitset<12345> my_bits(s); // может генерировать исключение // std::invalid_argumentК объектам класса
bitsetb1b2b3bitsetb1 = b2&b3; // иb1 = b2|b3; // илиb1 = b2^b3; // xorb1 = ~b2; // дополнениеb1 = b2<<2; // сдвиг влевоb1 = b2>>3; // сдвиг вправоПо существу, при выполнении битовых операций (поразрядных логических операций) объект класса
bitsetunsigned intunsigned intbitsetbitsetcin>>b; // считываем объект класса bitset // из потока вводаcout<('c'); // выводим битовую комбинацию для символа 'c' Считывая данные в объект класса
bitset10121Число
10121Как в байтах и в словах, биты в объектах класса
bitset27Для объектов класса
bitsetbitsetint main(){ const int max = 10; bitset b; while (cin>>b) { cout << b << '\n'; for (int i =0; i // порядок cout << '\n'; }}Если вам нужна более полная информация о классе
bitset25.5.3. Целые числа со знаком и без знака
Как и во многих языках программирования, целые числа в языке С++ бывают двух видов: со знаком и без него. Целые числа без знака легко представить в памяти компьютера: нулевой бит означает единицу, первый бит — двойку, второй бит — четверку и т.д. Однако представление целого числа со знаком уже создает проблему: как отличить положительные числа от отрицательных? Язык С++ предоставляет разработчикам аппаратного обеспечения определенную свободу выбора, но практически во всех реализациях используется представление в виде двоичного дополнения. Крайний левый бит (самый старший) считается знаковым.

Если знаковый бит равен единице, то число считается отрицательным. Почти повсюду для представления целых чисел со знаком используется двоичное дополнение. Для того чтобы сэкономить место, рассмотрим представление четырехбитового целого числа со знаком.

Битовую комбинацию числа
–(x+1)x~xДо сих пор мы использовали только целые числа со знаком (например,
int • Для числовых расчетов используйте целые числа со знаком (например,
int• Для работы с битовыми наборами используйте целые числа без знака (например,
unsigned int Это неплохое эмпирическое правило, но ему трудно следовать, потому что есть люди, которые предпочитают в некоторых арифметических вычислениях работать с целыми числами без знака, и нам иногда приходится использовать их программы. В частности, по историческим причинам, которые возникли еще в первые годы существования языка С, когда числа типа
intv.size() Рассмотрим пример.
vector v; // ...for (int i = 0; i“Разумный” компилятор может предупредить, что мы смешиваем значения со знаком (т.е. переменную
iv.size()iv.size()intiintint++intv.size()inti Таким образом, с формальной точки зрения большинство циклов в этой книге было ошибочным и могло вызвать проблемы, т.е. для встроенных систем мы должны либо проверять, что цикл никогда не достигнет критической точки, либо заменить его другой конструкцией. Для того чтобы избежать этой проблемы, мы можем использовать либо тип size_type, предоставленный классом
vectorfor (vector::size_type i = 0; i cout << v[i] << '\n';for (vector::iterator p = v.begin(); p!=v.end(); ++p) cout << *p << '\n';Тип
size_typeПОПРОБУЙТЕ
Следующий пример может показаться безобидным, но он содержит бесконечный цикл:
void infinite(){ unsigned char max = 160; // очень большое for (signed char i=0; i cout << int(i) << '\n';}Выполните его и объясните, почему это происходит.
По существу, есть две причины, оправдывающие использование для представления обычных целых чисел типа int без знака, а не набора битов (не использующего операции
+–*/• Позволяет повысить точность на один бит.
• Позволяет отразить логические свойства целых чисел в ситуациях, когда они не могут быть отрицательными.
Из-за причин, указанных выше, программисты отказались от использования счетчиков цикла без знака.
Проблема, сопровождающая использование целых чисел как со знаком, так и без знака, заключается в том, что в языке С++ (как и в языке С) они преобразовываются одно в другое непредсказуемым и малопонятным образом.
Рассмотрим пример.
unsigned int ui = –1;int si = ui;int si2 = ui+2;unsigned ui2 = ui+2;Удивительно, но факт: первая инициализация прошла успешно, и переменная
uisisi2ui2ui20xffffffff Вам все понятно? Даже если так, мы все равно убеждены, что использование целых чисел без знака ради дополнительного повышения точности на один бит — это игра с огнем. Она может привести к путанице и стать источником ошибок.
Что произойдет при переполнении целого числа? Рассмотрим пример.
Int i = 0;while (++i) print(i); // выводим i как целое с пробеломКакая последовательность значений будет выведена на экран? Очевидно, что это зависит от определения типа Int (на всякий случай отметим, что прописная буква I не является опечаткой). Работая с целочисленным типом, имеющим ограниченное количество битов, мы в конечном итоге получим переполнение. Если тип Int не имеет знака (например,
unsigned charunsigned intunsigned long long++Intsigned charsigned charЧто происходит при переполнении целых чисел? В этом случае мы работаем так, будто в нашем распоряжении есть достаточное количество битов, и отбрасываем ту часть целого числа, которая не помещается в память, где мы храним результат. Эта стратегия приводит к потере крайних левых (самых старших) битов. Такой же эффект можно получить с помощью следующего кода:
int si = 257; // не помещается в типе charchar c = si; // неявное преобразование в charunsigned char uc = si;signed char sc = si;print(si); print(c); print(uc); print(sc); cout << '\n';si = 129; // не помещается в signed charc = si;uc = si;sc = si;print(si); print(c); print(uc); print(sc);Получаем следующий результат:

Объяснение этого результата таково: число 257 на два больше, чем можно представить с помощью восьми битов (255 равно “восемь единиц”), а число 129 на два больше, чем можно представить с помощью семи битов (127 равно “семь единиц”), поэтому устанавливается знаковый бит. Кстати, эта программа демонстрирует, что тип
charscucПОПРОБУЙТЕ
Напишите эти битовые комбинации на листке бумаги. Затем попытайтесь вычислить результат для
si=128Кстати, почему мы использовали функцию
print()cout << i << ' ';Однако, если бы переменная
icharprint()template void print(T i) { cout << i << '\t'; } void print(char i) { cout << int(i) << '\t'; }void print(signed char i) { cout << int(i) << '\t'; }void print(unsigned char i) { cout << int(i) << '\t'; } Вывод: вы можете использовать целые числа без знака вместо целых чисел со знаком (включая обычную арифметику), но избегайте этого, поскольку это ненадежно и приводит к ошибкам.
• Никогда не используйте целые числа без знака просто для того, чтобы получить еще один бит точности.
• Если вам необходим один дополнительный бит, то вскоре вам потребуется еще один.
К сожалению, мы не можем совершенно избежать использования арифметики целых чисел без знака.
• Индексирование контейнеров в стандартной библиотеке осуществляется целыми числами без знака.
• Некоторые люди любят арифметику чисел без знака.
25.5.4. Манипулирование битами
Зачем вообще нужно манипулировать битами? Ведь многие из нас предпочли бы этого не делать. “Возня с битами” относится к низкому уровню и открывает возможности для ошибок, поэтому, если у нас есть альтернатива, следует использовать ее. Однако биты настолько важны и полезны, что многие программисты не могут их игнорировать. Это может звучать довольно грозным и обескураживающим предупреждением, но оно хорошо продумано. Некоторые люди действительно любят возиться с битами и байтами, поэтому следует помнить, что работа с битами иногда необходима (и даже может принести удовольствие), но ею не следует злоупотреблять. Процитируем Джона Бентли: “Люди, развлекающиеся с битами, будут биты” (“People who play with bits will be bitten”).
Итак, когда мы должны манипулировать битами? Иногда они являются естественными объектами нашей предметной области, поэтому естественными операциями в таких приложениях являются операции над битами. Примерами таких приложений являются индикаторы аппаратного обеспечения (“влаги”), низкоуровневые коммуникации (в которых мы должны извлекать значения разных типов из потока байтов), графика (в которой мы должны составлять рисунки из нескольких уровней образов) и кодирование (подробнее о нем — в следующем разделе).
Для примера рассмотрим, как извлечь (низкоуровневую) информацию из целого числа (возможно, из-за того, что мы хотим передать его как набор байтов через двоичный механизм ввода-вывода).
void f(short val) // пусть число состоит из 16 битов, т.е. 2 байта{ unsigned char left = val>>8; // крайний левый // (самый старший) байт unsigned char right = val&0xff; // крайний правый // (самый младший) байт // ... bool negative = val&0x8000; // знаковый бит // ...}Такие операции не редкость. Они известны как “сдвиг и наложение маски” (“shift and mask”). Мы выполняем сдвиг (“shift”), используя операторы
<<>>&0xffПри необходимости именовать биты часто используются перечисления. Рассмотрим пример.
enum Printer_flags { acknowledge=1, paper_empty=1<<1, busy=1<<2, out_of_black=1<<3, out_of_color=1<<4, // ...};Этот код определяет перечисление, в котором каждый элемент равен именно тому значению, которому соответствует его имя.

Такие значения полезны, потому что они комбинируются совершенно независимо друг от друга.
unsigned char x = out_of_color | out_of_black; // x = 24 (16+8)x |= paper_empty; // x = 26 (24+2)Отметим, что оператор
|=&if (x& out_of_color) { // установлен ли out_of_color? (Да, если // установлен)// ...}Оператор
&unsigned char y = x &(out_of_color | out_of_black); // y = 24Теперь переменная
yxout_of_colorout_of_blackОчень часть переменные типа
enum// необходимо приведениеFlags z = Printer_flags(out_of_color | out_of_black);Приведение необходимо потому, что компилятор не может знать, что результат выражения
out_of_color | out_of_blackFlagsout_of_color | out_of_black25.5.5. Битовые поля
Как указывалось ранее, биты часто встречаются при программировании интерфейсов аппаратного обеспечения. Как правило, такие интерфейсы определяются как смесь битов и чисел, имеющих разные размеры. Эти биты и числа обычно имеют имена и стоят на заданных позициях в слове, которое часто называют регистром устройства (device register). В языке C++ есть специальные конструкции для работы с такими фиксированными схемами: битовые поля (bitfields). Рассмотрим номер страницы, используемый менеджером страниц глубоко внутри операционной системы. Вот как выглядит диаграмма, приведенная в руководстве по работе с операционной системой.

З2-битовое слово состоит из двух числовых полей (одно длиной 22 бита и другое — 3 бита) и четырех флагов (длиной один бит каждый). Размеры и позиции этих фрагментов фиксированы. Внутри слова существует даже неиспользуемое (и неименованное) поле. Эту схему можно описать с помощью следующей структуры:
struct PPN { // Номер физической страницы // R6000 Number unsigned int PFN:22; // Номер страничного блока int:3; // не используется unsigned int CCA:3; // Алгоритм поддержки // когерентности кэша // (Cache Coherency Algorithm) bool nonreachable:1; bool dirty:1; bool valid:1; bool global:1;};Для того чтобы узнать, что переменные PFN и CCA должны интерпретироваться как целые числа без знака, необходимо прочитать справочник. Но мы могли бы восстановить структуру непосредственно по диаграмме. Битовые поля заполняют слово слева направо. Количество битов указывается как целое число после двоеточия. Указать абсолютную позицию (например, бит 8) нельзя. Если битовые поля занимают больше памяти, чем слово, то поля, которые не помещаются в первое слово, записываются в следующее. Надеемся, что это не противоречит вашим желаниям. После определения битовое поле используется точно так же, как все остальные переменные.
void part_of_VM_system(PPN * p){ // ... if (p–>dirty) { // содержание изменилось // копируем на диск p–>dirty = 0; } // ...}Битовые поля позволяют не использовать сдвиги и наложение масок, для того чтобы получить информацию, размещенную в середине слова. Например, если объект класса
PPNpnCCAunsigned int x = pn.CCA; // извлекаем битовое поле CCAЕсли бы для представления тех же самых битов мы использовали целое число типа
intpniunsigned int y = (pni>>4)&0x7; // извлекаем битовое поле CCAИначе говоря, этот код сдвигает структуру
pnCCA0x7Смесь аббревиатур (
CCAPPNPFN25.5.6. Пример: простое шифрование
В качестве примера манипулирования данными на уровне битов и байтов рассмотрим простой алгоритм шифрования: Tiny Encryption Algorithm (TEA). Он был изобретен Дэвидом Уилером (David Wheeler) в Кембриджском университете (см. раздел 22.2.1). Он небольшой, но обеспечивает превосходную защиту от несанкционированной расшифровки.
Не следует слишком глубоко вникать в этот код (если вы не слишком любознательны или не хотите заработать головную боль). Мы приводим его просто для того, чтобы вы почувствовали вкус реального приложения и ощутили полезность манипулирования битами. Если хотите изучать вопросы шифрования, найдите другой учебник. Более подробную информацию об этом алгоритме и варианты его реализации на других языках программирования можно найти на веб-странице http://en.wikipedia.org/wiki/Tiny_Encryption_Algorithm или на сайте, посвященному алгоритму TEA и созданному профессором Саймоном Шепердом (Simon Shepherd) из Университета Брэдфорда (Bradford University), Англия. Этот код не является самоочевидным (без комментариев!).
Основная идея шифрования/дешифрования (кодирования/декодирования) проста. Я хочу послать вам некий текст, но не хочу, чтобы его прочитал кто-то другой. Поэтому я преобразовываю свой текст так, чтобы он стал непонятным для людей, которые не знают, как именно я его модифицировал, но так, чтобы вы могли произвести обратное преобразование и прочитать мой текст. Эта процедура называется шифрованием. Для того чтобы зашифровать текст, я использую алгоритм (который должен считать неизвестным нежелательным соглядатаям) и строку, которая называется ключом. У вас этот ключ есть (и надеемся, что его нет у нежелательного соглядатая). Когда вы получите зашифрованный текст, вы расшифруете его с помощью ключа; другими словами, восстановите исходный текст, который я вам послал.
Алгоритм TEA получает в качестве аргумента два числа типа
longv[0]v[1]longw[0]w[1]longk[0]..k[3]void encipher( const unsigned long *const v, unsigned long *const w, const unsigned long * const k) { unsigned long y = v[0]; unsigned long z = v[1]; unsigned long sum = 0; unsigned long delta = 0x9E3779B9; unsigned long n = 32; while(n–– > 0) { y += (z << 4 ^ z >> 5) + z ^ sum + k[sum&3]; sum += delta; z += (y << 4 ^ y >> 5) + y ^ sum + k[sum>>11 & 3]; } w[0]=y; w[1]=z; }}Поскольку все данные не имеют знака, мы можем выполнять побитовые операции, не опасаясь сюрпризов, связанных с отрицательными числами. Основные вычисления выполняются с помощью сдвигов (
<<>>^&sizeof(long)4nn==32Приведем соответствующую функцию декодирования.
void decipher( const unsigned long *const v, unsigned long *const w, const unsigned long * const k) { unsigned long y = v[0]; unsigned long z = v[1]; unsigned long sum = 0xC6EF3720; unsigned long delta = 0x9E3779B9; unsigned long n = 32; // sum = delta<<5, в целом sum = delta * n while(n–– > 0) { z –= (y << 4 ^ y >> 5) + y ^ sum + k[sum>>11 & 3]; sum –= delta; y –= (z << 4 ^ z >> 5) + z ^ sum + k[sum&3]; } w[0]=y; w[1]=z; }}Мы можем использовать алгоритм TEA для того, чтобы создать файл, который можно передавать по незащищенной линии связи.
int main() // отправитель{ const int nchar = 2*sizeof(long); // 64 бита const int kchar = 2*nchar; // 128 битов string op; string key; string infile; string outfile; cout << "введите имя файлов для ввода, для вывода и ключ:\n"; cin >> infile >> outfile >> key; while (key.size() ifstream inf(infile.c_str()); ofstream outf(outfile.c_str()); if (!inf || !outf) error("Неправильное имя файла"); const unsigned long* k = reinterpret_cast(key.data()); unsigned long outptr[2]; char inbuf[nchar]; unsigned long* inptr = reinterpret_cast long*>(inbuf); int count = 0; while (inf.get(inbuf[count])) { outf << hex; // используется шестнадцатеричный вывод if (++count == nchar) { encipher(inptr,outptr,k); // заполнение ведущими нулями: outf << setw(8) << setfill('0') << outptr[0] << ' ' << setw(8) << setfill('0') << outptr[1] << ' '; count = 0; } } if (count) { // заполнение while(count != nchar) inbuf[count++] = '0'; encipher(inptr,outptr,k); outf << outptr[0] << ' ' << outptr[1] << ' '; }}Основной частью кода является цикл
whilewhileinbufencipher()longinbufunsigned long*unsigned longКак передать зашифрованный текст? Здесь у нас есть выбор, но поскольку текст представляет собой простой набор битов, а не символы кодировки ASCII или Unicode, то мы не можем рассматривать его как обычный текст. Можно было бы использовать двоичный ввод-вывод (см. раздел 11.3.2), но мы решили выводить числа в шестнадцатеричном виде.

ПОПРОБУЙТЕ
Ключом было слово
bs Любой эксперт по безопасности скажет вам, что хранить исходный текст вместе с зашифрованным очень глупо. Кроме того, он обязательно сделает замечания о процедуре заполнения, двухбуквенном ключе и так далее, но наша книга посвящена программированию, а не компьютерной безопасности.
Мы проверили свою программу, прочитав зашифрованный текст и преобразовав его в исходный. Когда пишете программу, никогда не пренебрегайте простыми проверками ее корректности.
Центральная часть программы расшифровки выглядит следующим образом:
unsigned long inptr[2];char outbuf[nchar+1];outbuf[nchar]=0; // терминальный знакunsigned long* outptr = reinterpret_cast(outbuf); inf.setf(ios_base::hex,ios_base::basefield); // шестнадцатеричный // вводwhile (inf>>inptr[0]>>inptr[1]) { decipher(inptr,outptr,k); outf<}Обратите внимание на использование функции
inf.setf(ios_base::hex,ios_base::basefield);для чтения шестнадцатеричных чисел. Для дешифровки существует буфер вывода
outbuf Следует ли рассматривать алгоритм TEA как пример программирования встроенной системы? Не обязательно, но мы можем представить себе ситуацию, в которой необходимо обеспечить безопасность или защитить финансовые транзакции с помощью многих устройств. Алгоритм TEA демонстрирует много свойств хорошего встроенного кода: он основан на понятной математической модели, корректность которой не вызывает сомнений; кроме того, он небольшой, быстрый и непосредственно использует особенности аппаратного обеспечения.
Стиль интерфейса функций
encipher()decipher()25.6. Стандарты программирования
Существует множество источников ошибок. Самые серьезные и трудно исправимые ошибки связаны с проектными решениями высокого уровня, такими как общая стратегия обработки ошибок, соответствие определенным стандартам (или их отсутствие), алгоритмы, представление идей и т.д. Эти проблемы здесь не рассматриваются. Вместо этого мы сосредоточимся на ошибках, возникающих из-за плохого стиля, т.е. из-за кода, в котором средства языка программирования используются слишком небрежно или некорректно.
Стандарты программирования пытаются устранить вторую проблему, устанавливая “фирменный стиль”, в соответствии с которым программисты должны использовать средства языка С++, подходящие для конкретного приложения. Например, стандарты программирования для встроенных систем могут запрещать использование оператора
newforwhile Не существует одного общего стандарта программирования, приемлемого для всех приложений языка С++ и для всех программистов, работающих на этом языке.
Таким образом, проблемы, для устранения которых предназначены стандарты программирования, порождаются способами, которыми мы пытаемся выразить наши решения, а не внутренней сложностью решаемых задач. Можно сказать, что стандарты программирования пытаются устранить дополнительную сложность, а не внутреннюю.
Перечислим основные источники дополнительной сложности.
• Слишком умные программисты, использующие свойства, которые они не понимают, или получающие удовольствия от чрезмерно усложненных решений.
• Недостаточно образованные программисты, не знающие о наиболее подходящих возможностях языка и библиотек.
• Необоснованные вариации стилей программирования, в которых для решения похожих задач применяются разные инструменты, запутывающие программистов, занимающихся сопровождением систем.
• Неправильный выбор языка программирования, приводящий к использованию языковых конструкций, неподходящих для данного приложения или данной группы программистов.
• Недостаточно широкое использование библиотек, приводящее к многочисленным специфическим манипуляциям низкоуровневыми ресурсами.
• Неправильный выбор стандартов программирования, порождающий дополнительный объем работы или не позволяющий найти наилучшее решение для определенных классов задач, что само по себе становится источников проблем, для устранения которых вводились стандарты программирования.
25.6.1. Каким должен быть стандарт программирования?
Хороший стандарт программирования должен способствовать написанию хороших программ; т.е. должен давать программистам ответы на множество мелких вопросов, решение которых в каждом конкретном случае привело бы к большой потере времени. Старая поговорка программистов гласит: “Форма освобождает”. В идеале стандарт кодирования должен быть инструктивным, указывая, что следует делать. Это кажется очевидным, но многие стандарты программирования представляют собой простые списки запрещений, не содержащие объяснений, что с ними делать. Простое запрещение редко бывает полезным и часто раздражает.
Правила хорошего стандарта программирования должны допускать проверку, желательно с помощью программ. Другими словами, как только вы написали программу, вы должны иметь возможность легко ответить на вопрос: “Не нарушил ли я какое-нибудь правило стандарта программирования?” Хороший стандарт программирования должен содержать обоснование своих правил. Нельзя просто заявить программистам: “Потому что вы должны делать именно так!” В ответ на это они возмущаются. И что еще хуже, программисты постоянно стараются опровергнуть те части стандарта программирования, которые они считают бессмысленными, и эти попытки отвлекают их от полезной работы. Не ожидайте, что стандарты программирования ответят на все ваши вопросы. Даже самые хорошие стандарты программирования являются результатом компромиссов и часто запрещают делать то, что лишь может вызвать проблемы, даже если в вашей практике этого никогда не случалось. Например, очень часто источником недоразумений становятся противоречивые правила именования, но люди часто отдают предпочтение определенным соглашениям об именах и категорически отвергают остальные. Например, я считаю, что имена идентификаторов вроде CamelCodingStyle[10] весьма уродливы, и очень люблю имена наподобие underscore_style[11], которые намного понятнее, и многие люди со мной согласны. С другой стороны, многие разумные люди с этим не согласны. Очевидно, ни один стандарт именования не может удовлетворить всех, но в данном случае, как и во многих других, последовательность намного лучше отсутствия какой-либо систематичности.
Подведем итоги.
• Хороший стандарт программирования предназначен для конкретной предметной области и конкретной группы программистов.
• Хороший стандарт программирования должен быть инструктивным, а не запретительным.
• Рекомендация некоторых основных библиотечных возможностей часто является самым эффективным способом применения инструктивных правил.
• Стандарт программирования — это совокупность правил, описывающих желательный образец для кода, в частности:
• регламентирующие способ именования идентификаторов и выравнивания строк, например “Используйте схему Страуструпа”;
• указывающие конкретное подмножество языка, например “Не используйте операторы
newthrow• задающие правила комментирования, например “Каждая функция должна содержать описание того, что она делает”;
• требующие использовать конкретные библиотеки, например “используйте библиотеку
vectorstring• Большинство стандартов программирования имеет общие цели.
• Надежность.
• Переносимость.
• Удобство сопровождения.
• Удобство тестирования.
• Возможность повторного использования.
• Возможность расширения.
• Читабельность.
• Хороший стандарт программирования лучше, чем отсутствие стандарта.
Мы не начинаем ни один большой промышленный проект (т.е. проект, в котором задействовано много людей и который продолжается несколько лет), не установив стандарт программирования.
• Плохой стандарт программирования может оказаться хуже, чем полное отсутствие стандарта. Например, стандарты программирования на языке С++, суживающие его до языка С, таят в себе угрозу. К сожалению, плохие стандарты программирования встречаются чаще, чем хотелось бы.
• Программисты не любят стандарты программирования, даже хорошие. Большинство программистов хотят писать свои программы только так, как им нравится.
25.6.2. Примеры правил
В этом разделе мы хотели бы дать читателям представление о стандартах программирования, перечислив некоторые правила. Естественно, мы выбрали те правила, которые считаем полезными для вас. Однако мы не видели ни одного реального стандарта программирования, который занимал бы меньше 35 страниц. Большинство из них намного длиннее. Итак, не будем пытаться привести здесь полный набор правил. Кроме того, каждый хороший стандарт программирования предназначен для конкретной предметной области и конкретной группы программистов. По этой причине мы ни в коем случае не претендуем на универсальность.
Правила пронумерованы и содержат (краткое) обоснование. Мы провели различия между рекомендациями, которые программист может иногда игнорировать, и твердыми правилами, которым он обязан следовать. Обычно твердые правила обычно нарушаются только с письменного согласия руководителя. Каждое нарушение рекомендации или твердого правила требует отдельного комментария в программе. Любые исключения из правила должны быть перечислены в его описании. Твердое правило выделяется прописной буквой R в его номере. Номер рекомендации содержит строчную букву r.
Правила разделяются на несколько категорий.
• Общие.
• Правила препроцессора.
• Правила использования имен и размещения текста.
• Правила для классов.
• Правила для функций и выражений.
• Правила для систем с жесткими условиями реального времени.
• Правила для систем, предъявляющих особые требования к вопросам безопасности.
Правила для систем с жесткими условиями реального времени и систем, предъявляющих особые требования к вопросам безопасности, применяются только в проектах, которые явно такими объявлены.
По сравнению с хорошими реальными стандартами программирования наша терминология является недостаточно точной (например, что значит, “система, предъявляющая особые требования к вопросам безопасности”), а правила слишком лаконичны. Сходство между этими правилами и правилами JSF++ (см. раздел 25.6.3) не является случайным; я лично помогал формулировать правила JSF++. Однако примеры кодов в этой книге не следуют этим правилам — в конце концов, книга не является программой для систем, предъявляющих особые требования к вопросам безопасности.
Общие правила
R100. Любая функция или класс не должны содержать больше 200 логических строк кода (без учета комментариев).
Причина: длина функции или класса свидетельствует об их сложности, поэтому их трудно понять и протестировать.
r101. Любая функция или класс должны помещаться на экране и решать одну задачу.
Причина. Программист, видящий только часть функции или класса, может не увидеть проблему. Функция, решающая сразу несколько задач, скорее всего, длиннее и сложнее, чем функция, решающая только одну задачу.
R102. Любая программа должна соответствовать стандарту языка С++ ISO/IEC 14882:2003(E).
Причина. Расширения языка или отклонения от стандарта ISO/IEC 14882 менее устойчивы, хуже определены и уменьшают переносимость программ.
Правила препроцессора
R200. Нельзя использовать никаких макросов, за исключением директив управления исходными текстами
#ifdef#ifndefПричина. Макрос не учитывает область видимости и не подчиняется правилам работы с типами. Использование макросов трудно определить визуально, просматривая исходный текст.
R201. Директива
#include*.hПричина. Директива
#includeR202. Директивы
#includeПричина. Директива
#includeR203. Заголовочные файлы (
*.hПричина. Заголовочные файлы должны содержать объявления интерфейсов, а не детали реализации. Однако константы часто рассматриваются как часть интерфейса; некоторые очень простые функции для повышения производительности должны быть подставляемыми (а значит, объявлены в заголовочных файлах), а текущие шаблонные реализации требуют, чтобы в заголовочных файлах содержались полные определения шаблонов.
Правила использования имен и размещения текста
R300. В пределах одного и того же исходного файла следует использовать согласованное выравнивание.
Причина. Читабельность и стиль.
R301. Каждая новая инструкция должна начинаться с новой строки.
Причина. Читабельность.
Пример:
int a = 7; x = a+7; f(x,9); // нарушение int a = 7; // OK x = a+7; // OK f(x,9); // OKПример:
if (pПример:
if (p cout << *p; // OKR302. Идентификаторы должны быть информативными.
Идентификаторы могут состоять из общепринятых аббревиатур и акронимов.
В некоторых ситуациях имена
xyijСледует использовать стиль
number_of_elementsnumberOfElementsВенгерский стиль использовать не следует.
Только имена типов, шаблонов и пространств имен могут начинаться с прописной буквы.
Избегайте слишком длинных имен.
Пример:
Device_driverBuffer_poolПричина. Читабельность.
Примечание. Идентификаторы, начинающиеся с символа подчеркивания, зарезервированы стандартом языка С++ и, следовательно, запрещены для использования.
Исключение. При вызове функций из используемой библиотеки может потребоваться указать имена, определенные в ней.
Исключение. Названия макросов, которые используются как предохранители для директивы
#includeR303. Не следует использовать идентификаторы, которые различаются только по перечисленным ниже признакам.
• Смесь прописных и строчных букв.
• Наличие/отсутствие символа подчеркивания.
• Замена буквы O цифрой 0 или буквой D.
• Замена буквы I цифрой 1 или буквой l.
• Замена буквы S цифрой 5.
• Замена буквы Z цифрой 2.
• Замена буквы n буквой h.
Пример:
Head и head // нарушениеПричина. Читабельность.
R304. Идентификаторы не должны состоять только из прописных букв или прописных букв с подчеркиваниями.
Пример: BLUE и BLUE_CHEESE // нарушение
Причина. Имена, состоящие исключительно из прописных букв, широко используются для названия макросов, которые могут встретиться в заголовочных файлах применяемой библиотеки, включенных директивой.
Правила для функций и выражений
r400. Идентификаторы во вложенной области видимости не должны совпадать с идентификаторами во внешней области видимости.
Пример:
int var = 9; { int var = 7; ++var; } // нарушение: var маскирует varПричина. Читабельность.
R401. Объявления должны иметь как можно более маленькую область видимости.
Причина. Инициализация и использование переменной должны быть как можно ближе друг к другу, чтобы минимизировать вероятность путаницы; выход переменной за пределы области видимости освобождает ее ресурсы.
R402. Переменные должны быть проинициализированы.
Пример:
int var; // нарушение: переменная var не проинициализированаПричина. Неинициализированные переменные являются традиционным источником ошибок.
Исключение. Массив или контейнер, который будет немедленно заполнен данными из потока ввода, инициализировать не обязательно.
R403. Не следует использовать операторы приведения.
Причины. Операторы приведения часто бывают источником ошибок.
Исключение. Разрешается использовать оператор
dynamic_castИсключение. Приведение в новом стиле можно использовать для преобразования адресов аппаратного обеспечения в указатели, а также для преобразования указателей типа
void*R404. Встроенные массивы нельзя использовать в интерфейсах. Иначе говоря, указатель, используемый как аргумент функции, должен рассматриваться только как указатель на отдельный элемент. Для передачи массивов используйте класс
Array_refПричина. Когда массив передается в вызываемую функцию с помощью указателя, а количество его элементов не передается, может возникнуть ошибка. Кроме того, комбинация неявного преобразования массива в указатель и неявного преобразования объекта производного класса в объект базового класса может привести к повреждению памяти.
Правила для классов
R500. Для классов без открытых данных-членов используйте ключевое слово
classstructПричина. Ясность.
r501. Если класс имеет деструктор или член, являющийся указателем на ссылочный тип, то он должен иметь копирующий конструктор, а копирующий оператор присваивания должен быть либо определен, либо запрещен.
Причина. Деструктор обычно освобождает ресурс. По умолчанию семантика копирования редко бывает правильной по отношению к членам класса, являющимся указателями или ссылками, а также по отношению к классам без деструкторов.
R502. Если класс содержит виртуальную функцию, то он должен иметь виртуальный конструктор.
Причина. Если класс имеет виртуальную функцию, то его можно использовать в качестве базового интерфейсного класса. Функция, обращающаяся к этому объекту только через этот базовый класс, может удалить его, поэтому производные классы должны иметь возможность очистить память (с помощью своих деструкторов).
r503. Конструктор, принимающий один аргумент, должен быть объявлен с помощью ключевого слова
explicitПричина. Для того чтобы избежать непредвиденных неявных преобразований.
Правила для систем с жесткими условиями реального времени
R800. Не следует применять исключения.
Причина. Результат непредсказуем.
R801. Оператор
newПричина. Результат непредсказуем.
Исключение. Для памяти, выделенной из стека, может быть использован синтаксис размещения (в его стандартном значении).
R802. Не следует использовать оператор
deleteПричина. Результат непредсказуем; может возникнуть фрагментация памяти.
R803. Не следует использовать оператор
dynamic_castПричина. Результат непредсказуем (при традиционном способе реализации оператора).
R804. Не следует использовать стандартные библиотечные контейнеры, за исключением класса
std::arrayПричина. Результат непредсказуем (при традиционном способе реализации оператора).
Правила для систем, предъявляющих особые требования к вопросам безопасности
R900. Операции инкрементации и декрементации не следует использовать как элементы выражений.
Пример:
int x = v[++i]; // нарушениеПример:
++i;int x = v[i]; // OKПричина. Такую инкрементацию легко не заметить.
R901. Код не должен зависеть от правил приоритета операций ниже уровня арифметических выражений.
Пример:
x = a*b+c; // OKПример:
if( a // и (c<=d)Причина. Путаница с приоритетами постоянно встречается в программах, авторы которых слабо знают язык C/C++.
Наша нумерация непоследовательна, поскольку у нас должна быть возможность добавлять новые правила, не нарушая их общую классификацию. Очень часто правила помнят по их номерам, поэтому их перенумерация может вызвать неприятие пользователей.
25.6.3. Реальные стандарты программирования
Для языка С++ существует много стандартов программирования. Применение большинства из них ограничено стенами корпораций и не доступно для широкой публики. Во многих случаях стандарты делают доброе дело, но, вероятно, не для программистов, работающих в этих корпорациях. Перечислим стандарты, которые признаны хорошими в своих предметных областях.
Henricson, Mats, and Erik Nyquist. Industrial Strength C++: Rules and Recommendations. Prentice Hall, 1996. ISBN 0131209655. Набор правил, разработанных для телекоммуникационных компаний. К сожалению, эти правила несколько устарели: книга была издана до появления стандарта ISO C++. В частности, в них недостаточно широко освещены шаблоны.
Lockheed Martin Corporation. “Joint Strike Fighter Air Vehicle Coding Standards for the System Development and Demonstration Program”. Document Number 2RDU00001 Rev C. December 2005. Широко известен в узких кругах под названием “JSF++”. Это набор правил, написанных в компании Lockheed-Martin Aero, для программного обеспечения летательных аппаратов (самолетов). Эти правила были написаны программистами и для программистов, создающих программное обеспечение, от которого зависит жизнь людей (www.research.att.com/~bs/JSF-AV-rules.pdf).
Programming Research. High-integrity C++ Coding Standard Manual Version 2.4. (www.programmingresearch.com).
Sutter, Herb, and Andrei Alexandrescu. C++ Coding Standards: 101 Rules, Guidelines, and Best Practices. Addison-Wesley, 2004. ISBN 0321113586. Этот труд можно скорее отнести к стандартам метапрограммирования; иначе говоря, вместо формулирования конкретных правил авторы пишут, какие правила являются хорошими и почему.
Обратите внимание на то, что знания предметной области, языка и технологии программирования не могут заменить друг друга. В большинстве приложений — и особенно в большинстве встроенных систем программирования — необходимо знать как операционную систему, так и/или архитектуру аппаратного обеспечения. Если вам необходимо выполнить низкоуровневое кодирование на языке С++, то изучите отчет комитета ISO по стандартизации, посвященный проблемам производительности (ISO/IEC TR 18015; www.research.att.com/~bs/performanceTR.pdf); под производительностью авторы (и мы) понимают в основном производительность программирования для встроенных систем.
В мире встроенных систем существует множество языков программирования и их диалектов, но где только можно, вы должны использовать стандартизированные язык (например, ISO C++), инструменты и библиотеки. Это минимизирует время вашего обучения и повысит вероятность того, что вас не скоро уволят.
Задание
1. Выполните следующий фрагмент кода:
int v = 1; for (int i = 0; iv <<=1;}2. Выполните этот фрагмент еще раз, но теперь переменную
vunsigned int3. Используя шестнадцатеричные литералы, определите, чему равны следующие переменные типа
short unsigned int3.1. Каждый бит равен единице.
3.2. Самый младший бит равен единице.
3.3. Самый старший бит равен единице.
3.4. Самый младший байт состоит из одних единиц.
3.5. Самый старший байт состоит из одних единиц.
3.6. Каждый второй бит равен единице (самый младший бит также равен единице).
3.7. Каждый второй бит равен единице (а самый младший бит равен нулю).
4. Выведите на печать каждое из перечисленных выше значений в виде десятичного и шестнадцатеричного чисел.
5. Выполните задания 3-4, используя побитовые операции (
|&<<10Контрольные вопросы
1. Что такое встроенная система? Приведите десять примеров, не менее трех из которых не упоминались в этой главе.
2. Что есть особенного во встроенных системах? Приведите пять особенностей, присущих всем встроенным системам.
3. Определите понятие предсказуемости в контексте встроенных систем.
4. Почему встроенные системы иногда трудно модифицировать и ремонтировать?
5. Почему оптимизировать производительность системы иногда нецелесообразно?
6. Почему мы предпочитаем оставаться на высоком уровне абстракции, не опускаясь на нижний уровень программирования?
7. Какие ошибки называют преходящими? Чем они особенно опасны?
8. Как разработать систему, которая восстанавливает свою работу после сбоя?
9. Почему невозможно предотвратить сбои?
10. Что такое предметная область? Приведите примеры предметных областей.
11. Для чего необходимо знать предметную область при программировании встроенных систем?
12. Что такое подсистема? Приведите примеры.
13. Назовите три вида памяти с точки зрения языка С++.
14. Почему вы предпочитаете использовать свободную память?
15. Почему использование свободной памяти во встроенных системах часто нецелесообразно?
16. Как безопасно использовать оператор new во встроенной системе?
17. Какие потенциальные проблемы связаны с классом
std::vector18. Какие потенциальные проблемы связаны с исключениями во встроенных системах?
19. Что такое рекурсивный вызов функции? Почему некоторые программисты, разрабатывающие встроенные системы, избегают исключений? Что они используют вместо них?
20. Что такое фрагментация памяти?
21. Что такое сборщик мусора (в контексте программирования)?
22. Что такое утечка памяти? Почему она может стать проблемой?
23. Что такое ресурс? Приведите примеры.
24. Что такое утечка ресурсов и как ее систематически предотвратить?
25. Почему мы не можем просто переместить объекты из одной области памяти в другую?
26. Что такое стек?
27. Что такое пул?
28. Почему стек и пул не приводят к фрагментации памяти?
29. Зачем нужен оператор
reinterpret_cast30. Чем опасна передача указателей в качестве аргументов функции? Приведите примеры.
31. Какие проблемы могут возникать при использовании указателей и массивов? Приведите примеры.
32. Перечислите альтернативы использованию указателей (на массивы) в интерфейсах.
33. Что гласит первый закон компьютерных наук?
34. Что такое бит?
35. Что такое байт?
36. Из скольких битов обычно состоит байт?
37. Какие операции мы можем выполнить с наборами битов?
38. Что такое исключающее “или” и чем оно полезно?
39. Как представить набор (или последовательность) битов?
40. Из скольких битов состоит слово?
41. Из скольких байтов состоит слово?
42. Что такое слово?
43. Из скольких битов, как правило, состоит слово?
44. Чему равно десятичное значение числа
0xf745. Какой последовательности битов соответствует число
0xab46. Что такое класс
bitset47. Чем тип unsigned
intsigned int48. В каких ситуациях мы предпочитаем использовать тип
unsigned intsigned int49. Как написать цикл, если количество элементов в массиве очень велико?
50. Чему равно значение переменной типа
unsigned int–351. Почему мы хотим манипулировать битами и байтами (а не типами более высокого порядка)?
52. Что такое битовое поле?
53. Для чего используются битовые поля?
54. Что такое кодирование (шифрование)? Для чего оно используется?
55. Можно ли зашифровать фотографию?
56. Для чего нужен алгоритм TEA?
57. Как вывести число в шестнадцатеричной системе?
58. Для чего нужны стандарты программирования? Назовите причины.
59. Почему не существует универсального стандарта программирования?
60. Перечислите некоторые свойства хорошего стандарта программирования.
61. Как стандарт программирования может нанести вред?
62. Составьте список, содержащий не менее десяти правил программирования (которые считаете полезными). Чем они полезны?
63. Почему мы не используем идентификаторы вида ALL_CAPITAL?
Термины

Упражнения
1. Выполните упражнения из разделов ПОПРОБУЙТЕ, если вы этого еще не сделали.
2. Составьте список слов, которые можно получить из записи чисел в шестнадцатеричной системе счисления, читая 0 как o, 1 как l, 2 как to и т.д. Например, Foo1 и Beef. Прежде чем сдать их для оценки, тщательно устраните все вульгаризмы.
3. Проинициализируйте 32-битовое целое число со знаком битовой комбинацией и выведите его на печать: все нули, все единицы, чередующиеся нули и единицы (начиная с крайней левой единицы), чередующиеся нули и единицы (начиная с крайнего левого нуля), 110011001100, 001100110011, чередующиеся байты, состоящие из одних единиц и одних нулей, начиная с байта, состоящего из одних нулей. Повторите это упражнение с 32-битовым целым числом без знака.
4. Добавьте побитовые логические операторы operators
&|^~5. Напишите бесконечный цикл. Выполните его.
6. Напишите бесконечный цикл, который трудно распознать как бесконечный. Можно использовать также цикл, который на самом деле не является бесконечным, потому что он закончится после исчерпания ресурса.
7. Выведите шестнадцатеричные значения от 0 до 400; выведите шестнадцатеричные значения от –200 до 200.
8. Выведите числовой код каждого символа на вашей клавиатуре.
9. Не используя ни стандартные заголовки (такие как
intchar10. Проанализируйте пример битового поля из раздела 25.5.5. Напишите пример, в котором инициализируется структура
PPNPPN11. Повторите предыдущее упражнение, сохраняя биты к объекте класса
bitset<32>12. Напишите понятную программу для примера из раздела 25.5.6.
13. Используйте алгоритм TEA (см. раздел 25.5.6) для передачи данных между двумя компьютерами. Использовать электронную почту настоятельно не рекомендуется.
14. Реализуйте простой вектор, в котором могут храниться не более N элементов, память для которых выделена из пула. Протестируйте его при N==1000 и целочисленных элементах.
15. Измерьте время (см. раздел 26.6.1), которое будет затрачено на размещение 10 тысяч объектов случайного размера в диапазоне байтов [1000:0], с помощью оператора
newdelete16. Сформулируйте двадцать правил, регламентирующих стиль программирования (не копируя правила из раздела 25.6). Примените их к программе, состоящей более чем из 300 строк, которую вы недавно написали. Напишите короткий (на одной-двух страницах) комментарий о применении этих правил. Нашли ли вы ошибки в программе? Стал ли код яснее? Может быть, он стал менее понятным? Теперь модифицируйте набор правил, основываясь на своем опыте.
17. В разделах 25.4.3-25.4.4 мы описали класс
Array_refRectangle*vectorArray_refПослесловие
Итак, программирование встроенных систем сводится, по существу, к “набивке битов”? Не совсем, особенно если вы преднамеренно стремитесь минимизировать заполнение битов как источник потенциальных ошибок. Однако иногда биты и байты системы приходится “набивать”; вопрос только в том, где и как. В большинстве систем низкоуровневый код может и должен быть локализован. Многие из наиболее интересных систем, с которыми нам пришлось работать, были встроенными, а самые интересные и сложные задачи программирования возникают именно в этой предметной области.
Глава 26 Тестирование
“Я только проверил корректность кода, но не
тестировал его”.
Дональд Кнут (Donald Knuth)
В настоящей главе обсуждаются вопросы тестирования и проверки корректности работы программ. Это очень обширные темы, поэтому мы можем осветить их лишь поверхностно. Наша цель — описать некоторые практичные идеи и методы тестирования модулей, таких как функции и классы. Мы обсудим использование интерфейсов и выбор тестов для проверки программ. Основной акцент будет сделан на проектировании и разработке систем, упрощающих тестирование и его применение на ранних этапах разработки. Рассматриваются также методы доказательства корректности программ и устранения проблем, связанных с производительностью.
26.1. Чего мы хотим
Проведем простой эксперимент. Напишите программу для бинарного поиска и выполните ее. Не ждите, пока дочитаете эту главу или раздел до конца. Важно, чтобы вы выполнили это задание немедленно! Бинарный поиск — это поиск в упорядоченной последовательности, который начинается с середины.
• Если средний элемент равен искомому, мы заканчиваем поиск.
• Если средний элемент меньше искомого, проводим бинарный поиск в правой части.
• Если средний элемент больше искомого, проводим бинарный поиск в левой части.
• Результат поиска является индикатором его успеха и позволяет модифицировать искомый элемент. Для этого в качестве такого индикатора используется индекс, указатель или итератор.
Используйте в качестве критерия сравнения (сортировки) оператор “меньше” (
<binary_searchequal_rangeИтак, вы написали функцию для бинарного поиска. Если нет, то вернитесь к предыдущему абзацу. Почему вы уверены, что ваша функция поиска корректна? Изложите свои аргументы, обосновывающие корректность программы.
Вы уверены в своих аргументах? Нет ли слабых мест в вашей аргументации? Это была тривиальная программа, реализующая очень простой и хорошо известный алгоритм. Исходный текст вашего компилятора занимает около 200 Кбайт памяти, исходный текст вашей операционной системы — от 10 до 50 Мбайт, а код, обеспечивающий безопасность полета самолета, на котором вы отправитесь отдыхать во время ваших следующих каникул или на конференцию, составляет от 500 Кбайт до 2 Мбайт. Это вас утешает? Как применить методы, которые вы использовали для проверки функции бинарного поиска, к реальному программному обеспечению, имеющему гораздо большие размеры.
Любопытно, что, несмотря на всю сложность, большую часть времени большая часть программного обеспечения работает правильно. К этому числу критически важных требований программы мы не относим игровые программы на персональных компьютерах. Следует подчеркнуть, что программное обеспечение с особыми требованиями к безопасности практически всегда работает корректно. Мы не будем упоминать в этой связи программное обеспечение бортовых компьютеров авиалайнеров или автомобилей из-за того, что за последнее десятилетие были зарегистрированы сбои в их работе. Рассказы о банковском программном обеспечении, вышедшем из строя из-за чека на 0,00 доллара, в настоящее время устарели; такие вещи больше не происходят. И все же программное обеспечение пишут такие же люди, как вы. Вы знаете, что делаете ошибки; но если мы можем делать ошибки, то почему следует думать, что “они” их не делают?
Чаще всего мы считаем, что знаем, как создать надежную систему из ненадежных частей. Мы тяжело работаем над каждой программой, каждым классом и каждой функцией, но, как правило, терпим неудачу при первом же испытании. Затем мы отлаживаем, тестируем и заново проектируем программу, устраняя в ней как можно больше ошибок. Однако в любой нетривиальной системе остается несколько скрытых ошибок. Мы знаем о них, но не можем найти или (реже) не можем найти их вовремя. После этого мы заново проектируем систему, чтобы выявить неожиданные и “невозможные” события. В результате может получиться система, которая выглядит надежно. Отметим, что такая система может по-прежнему скрывать ошибки (как правило, так и бывает) и работать меньше, чем ожидалось. Тем не менее она не выходит из строя окончательно и выполняет минимально возможные функции. Например, при исключительно большом количестве звонков телефонная система может не справляться с правильной обработкой каждого звонка, но никогда не отказывает окончательно.
Можно было бы пофилософствовать и подискутировать о том, следует ли считать неожиданные ошибки реальными ошибками, но давайте не будем этого делать. Для разработчиков системы выгоднее сразу выяснить, как сделать свои системы более надежными.
26.1.1. Предостережение
Тестирование — необъятная тема. Существует несколько точек зрения на то, как осуществлять тестирование, причем в разных прикладных областях — свои традиции и стандарты тестирования. И это естественно: нам не нужны одинаковые стандарты надежности для видеоигр и программного обеспечения для бортовых компьютеров авиалайнеров, но в итоге возникает путаница в терминах и избыточное разнообразие инструментов. Эту главу следует рассматривать как источник идей, касающихся как тестирования ваших персональных проектов, так и крупных систем. При тестировании больших систем используются настолько разнообразные комбинации инструментов и организационных структур, что описывать их здесь совершенно бессмысленно.
26.2. Доказательства
Постойте! Почему бы просто не доказать, что наши программы корректны, и не возиться с тестами? Как лаконично указал Эдсгер Дейкстра (Edsger Dijkstra): “Тестирование может выявить наличие ошибок, а не их отсутствие”. Это приводит к очевидному желанию доказать корректность программ так, как математики доказывают теоремы.
К сожалению, доказательство корректности нетривиальных программ выходит за пределы современных возможностей (за исключением некоторых очень ограниченных прикладных областей), само доказательство может содержать ошибки (как и математические теоремы), и вся теория и практика доказательства корректности программ являются весьма сложными. Итак, поскольку мы можем структурировать свои программы, то можем раздумывать о них и убеждаться, что они работают правильно. Однако мы также тестируем программы (раздел 26.3) и пытаемся организовать код так, чтобы он был устойчив к оставшимся ошибкам (раздел 26.4).
26.3. Тестирование
В разделе 5.11 мы назвали тестирование систематическим поиском ошибок. Рассмотрим методы такого поиска.
Различают тестирование модулей (unit testing) и тестирование систем (system testing). Модулем называется функция или класс, являющиеся частью полной программы. Если мы тестируем такие модули по отдельности, то знаем, где искать проблемы в случае обнаружения ошибок; все ошибки, которые мы можем обнаружить, находятся в проверяемом модуле (или в коде, который мы используем для проведения тестирования). Это контрастирует с тестированием систем, в ходе которого тестируется полная система, и мы знаем, что ошибка находится “где-то в системе”. Как правило, ошибки, найденные при тестировании систем, — при условии, что мы хорошо протестировали отдельные модули, — связаны с нежелательными взаимодействиями модулей. Ошибки в системе часто найти труднее, чем в модуле, причем на это затрачивается больше сил и времени.
Очевидно, что модуль (скажем, класс) может состоять из других модулей (например, функций или других классов), а системы (например, электронные коммерческие системы) могут состоять из других систем (например, баз данных, графического пользовательского интерфейса, сетевой системы и системы проверки заказов), поэтому различия между тестированием модулей и тестированием систем не так ясны, как хотелось бы, но общая идея заключается в том, что при правильном тестировании мы экономим силы и нервы пользователей.
Один из подходов к тестированию основан на конструировании нетривиальных систем из модулей, которые, в свою очередь, сами состоят из более мелких модулей. Итак, начинаем тестирование с самых маленьких модулей, а затем тестируем модули, которые состоят из этих модулей, и так до тех пор, пока не приступим к тестированию всей системы. Иначе говоря, система при таком подходе рассматривается как самый большой модуль (если он не используется как часть более крупной системы).
Прежде всего рассмотрим, как тестируется модуль (например, функция, класс, иерархия классов или шаблон). Тестирование проводится либо по методу прозрачного ящика (когда мы можем видеть детали реализации тестируемого модуля), либо по методу черного ящика (когда мы видим только интерфейс тестируемого модуля). Мы не будем глубоко вникать в различия между этими методами; в любом случае следует читать исходный код того, что тестируется. Однако помните, что позднее кто-то перепишет эту реализацию, поэтому не пытайтесь использовать информацию, которая не гарантируется в интерфейсе. По существу, при любом виде тестирования основная идея заключается в исследовании реакции интерфейса на ввод информации.
Говоря, что кто-то (может быть, вы сами) может изменить код после того, как вы его протестируете, приводит нас к идее регрессивного тестирования. По существу, как только вы внесли изменение, сразу же повторите тестирование, чтобы убедиться, что вы ничего не разрушили. Итак, если вы улучшили модуль, то должны повторить его тестирование и, перед тем как передать законченную систему кому-то еще (или перед тем, как использовать ее самому), должны выполнить тестирование полной системы. Выполнение такого полного тестирования системы часто называют регрессивным тестированием (regression testing), поскольку оно подразумевает выполнение тестов, которые ранее уже выявили ошибки, чтобы убедиться, что они не возникли вновь. Если они возникли вновь, то программа регрессировала и ошибки следует устранить снова.
26.3.1. Регрессивные тесты
Создание крупной коллекции тестов, которые в прошлом оказались полезными для поиска ошибок, является основным способом конструирования эффективного тестового набора для системы. Предположим, у вас есть пользователи, которые будут сообщать вам о выявленных недостатках. Никогда не игнорируйте их отчеты об ошибках! В любом случае они свидетельствуют либо о наличии реальной ошибки в системе, либо о том, что пользователи имеют неправильное представление о системе. Об этом всегда полезно знать.
Как правило, отчет об ошибках содержит слишком мало посторонней информации, и первой задачей при его обработке является создание как можно более короткой программы, которая выявляла бы указанную проблему. Для этого часто приходится отбрасывать большую часть представленного кода: в частности, мы обычно пытаемся исключить использование библиотек и прикладной код, который не влияет на ошибку. Конструирование такой минимальной программы часто помогает локализовать ошибку в системном коде, и такую программу стоит добавить в тестовый набор. Для того чтобы получить минимальную программу, следует удалять код до тех пор, пока не исчезнет сама ошибка, — в этот момент следует вернуть в программу последнюю исключенную часть кода. Эту процедуру следует продолжать до тех пор, пока не будут удалены все возможные фрагменты кода, не имеющие отношения к ошибке.
Простое выполнение сотен (или десятков тысяч) тестов, созданных на основе прошлых отчетов об ошибках, может выглядеть не очень систематизированным, но на самом деле в этом случае мы действительно целенаправленно используем опыт пользователей и разработчиков. Набор регрессивных тестов представляет собой главную часть коллективной памяти группы разработчиков. При разработке крупных систем мы просто не можем рассчитывать на постоянный контакт с разработчиками исходных кодов, чтобы они объяснили нам детали проектирования и реализации. Именно регрессивные тесты не позволяют системе отклоняться от линии поведения, согласованной с разработчиками и пользователями.
26.3.2. Модульные тесты
Однако достаточно слов! Рассмотрим конкретный пример: протестируем программу для бинарного поиска. Ее спецификация из стандарта ISO приведена ниже (раздел 25.3.3.4).
template bool binary_search(ForwardIterator first, ForwardIterator last,const T& value); template bool binary_search(ForwardIterator first, ForwardIterator last,const T& value,Compare comp);Требует. Элементы
e[first, last]e!(valuecomp(e,value)!comp(value,e)e[first,last]e!(valuecomp(e,value)!comp(value,e)Возвращает. Значение
true[first,last]i!(*Icomp(*i,value)==false&&comp(value,*i)==falseСложность. Не более
log(last–first)+2Нельзя сказать, что непосвященному человеку легко читать эту формальную (ну хорошо, полуформальную) спецификацию. Однако, если вы действительно выполнили упражнение, посвященное проектированию и реализации бинарного поиска, которое мы настоятельно рекомендовали сделать в начале главы, то уже должны хорошо понимать, что происходит при бинарном поиске и как его тестировать. Данная (стандартная) версия функции для бинарного поиска получает в качестве аргументов пару однонаправленных итераторов (см. раздел 20.10.1) и определенное значение и возвращает значение
true<binary_searchЗдесь мы столкнемся только с ошибками, которые не перехватывает компилятор, поэтому примеры, подобные этому, для кого-то станут проблемой.
binary_search(1,4,5); // ошибка: int — это не однонаправленный // итераторvector v(10); binary_search(v.begin(),v.end(),"7"); // ошибка: невозможно найти // строку // в векторе целых чиселbinary_search(v.begin(),v.end()); // ошибка: забыли значение Как систематически протестировать функцию
binary_search()• Тест на возможные ошибки (находит большинство ошибок).
• Тест на опасные ошибки (находит ошибки, имеющие наихудшие возможные последствия).
Под опасными мы подразумеваем ошибки, которые могут иметь самые ужасные последствия. В целом это понятие носит неопределенный характер, но для конкретных программ его можно уточнить. Например, если рассматривать бинарный поиск изолированно от других задач, то все ошибки могут быть одинаково опасными. Но если мы используем функцию
binary_searchbinary_searchbinary_searchЛучшие тестировщики не только методичные, но и изворотливые люди (в хорошем смысле, конечно).
26.3.2.1. Стратегия тестирования
С чего мы начинаем испытание функции
binary_search[first,last]binary_search[first,last]lastbinary_searchbinary_searchbinary_searchДля функции
binary_search• Функция ничего не возвращает (например, из-за бесконечного цикла).
• Сбой (например, неправильное разыменование, бесконечная рекурсия).
• Значение не найдено, несмотря на то, что оно находится в указанной последовательности.
• Значение найдено, несмотря на то, что оно не находится в указанной последовательности.
Кроме того, необходимо помнить о следующих возможностях для пользовательских ошибок.
• Последовательность не упорядочена (например,
{2,1,5,–7,2,10}• Последовательность не корректна (например,
binary_search(&a[100],&a[50],77)Какую ошибку (с точки зрения тестировщиков) может сделать программист, создающий реализацию функции, при простом вызове функции
binary_search(p1,p2,v){ 1,2,3,5,8,13,21 } // "обычная последовательность"{ }{ 1 } // только один элемент{ 1,2,3,4 } // четное количество элементов{ 1,2,3,4,5 } // нечетное количество элементов{ 1, 1, 1, 1, 1, 1, 1 } // все элементы равны друг другу{ 0,1,1,1,1,1,1,1,1,1,1,1,1 } // другой элемент в начале{ 0,0,0,0,0,0,0,0,0,0,0,0,0,1 } // другой элемент в концеНекоторые тестовые последовательности лучше генерировать программой.
•
vector v1; // очень длинная последовательность for (int i=0; i<100000000; ++i) v.push_back(i);• Последовательности со случайным количеством элементов.
• Последовательности со случайными элементами (по-прежнему упорядоченные).
И все же этот тест не настолько систематический, насколько нам бы хотелось. Как-никак, мы просто выискали несколько последовательностей. Однако мы следовали некоторым правилам, которые часто полезны при работе с множествами значений; перечислим их.
• Пустое множество.
• Небольшие множества.
• Большие множества.
• Множества с экстремальным распределением.
• Множества, в конце которых происходит нечто интересное.
• Множества с дубликатами.
• Множества с четным и нечетным количеством элементов.
• Множества, сгенерированные с помощью случайных чисел.
Мы используем случайные последовательности просто для того, чтобы увидеть, повезет ли нам найти неожиданную ошибку. Этот подход носит слишком “лобовой” характер, но с точки зрения времени он очень экономный.
Почему мы рассматриваем четное и нечетное количество элементов? Дело в том, что многие алгоритмы разделяют входные последовательности на части, например на две половины, а программист может учесть только нечетное или только четное количество элементов. В принципе, если последовательность разделяется на части, то точка, в которой это происходит, становится концом подпоследовательности, а, как известно, многие ошибки возникают в конце последовательностей.
В целом мы ищем следующие условия.
• Экстремальные ситуации (большие или маленькие последовательности, странные распределения входных данных и т.п.).
• Граничные условия (все, что происходит в окрестности границы).
Реальный смысл этих понятий зависит от конкретной тестируемой программы.
26.3.2.2. Схема простого теста
Существуют две категории тестов: тесты, которые должны пройти успешно (например, поиск значения, которое есть в последовательности), и тесты, которые должны завершиться неудачей (например, поиск значения в пустой последовательности). Создадим для каждой из приведенных выше последовательностей несколько успешных и неудачных тестов. Начнем с простейшего и наиболее очевидного теста, а затем станем его постепенно уточнять, пока не дойдем до уровня, приемлемого для функции
binary_searchint a[] = { 1,2,3,5,8,13,21 };if (binary_search(a,a+sizeof(a)/sizeof(*a),1) == false) cout << " отказ";if (binary_search(a,a+sizeof(a)/sizeof(*a),5) == false) cout << " отказ";if (binary_search(a,a+sizeof(a)/sizeof(*a),8) == false) cout << " отказ";if (binary_search(a,a+sizeof(a)/sizeof(*a),21) == false) cout << " отказ";if (binary_search(a,a+sizeof(a)/sizeof(*a),–7) == true) cout << " отказ";if (binary_search(a,a+sizeof(a)/sizeof(*a),4) == true) cout << " отказ";if (binary_search(a,a+sizeof(a)/sizeof(*a),22) == true) cout << " отказ";Это скучно и утомительно, но это всего лишь начало. На самом деле многие простые тесты — это не более чем длинные списки похожих вызовов. Положительной стороной этого наивного подхода является его чрезвычайная простота. Даже новичок в команде тестировщиков может добавить в этот набор свой вклад. Однако обычно мы поступаем лучше. Например, если в каком-то месте приведенного выше кода произойдет сбой, мы не сможем понять, где именно. Это просто невозможно определить. Поэтому фрагмент нужно переписать.
int a[] = { 1,2,3,5,8,13,21 };if (binary_search(a,a+sizeof(a)/sizeof(*a),1) == false) cout << "1 отказ";if (binary_search(a,a+sizeof(a)/sizeof(*a),5) == false) cout << "2 отказ";if (binary_search(a,a+sizeof(a)/sizeof(*a),8) == false) cout << "3 отказ";if (binary_search(a,a+sizeof(a)/sizeof(*a),21) == false) cout << "4 отказ";if (binary_search(a,a+sizeof(a)/sizeof(*a),–7) == true) cout << "5 отказ";if (binary_search(a,a+sizeof(a)/sizeof(*a),4) == true) cout << "6 отказ";if (binary_search(a,a+sizeof(a)/sizeof(*a),22) == true) cout << "7 отказ";Если вы представите себе десятки тестов, то почувствуете огромную разницу. При тестировании реальных систем мы часто должны проверить многие тысячи тестов, поэтому знать, какой из них закончился неудачей, очень важно.
Прежде чем идти дальше, отметим еще один пример (полуформальный) методики тестирования: мы тестировали правильные значения, иногда выбирая их из конца последовательности, а иногда из середины. Для данной последовательности мы можем перебрать все ее значения, но на практике сделать это нереально. Для тестов, ориентированных на провал, выбираем одно значение в каждом из концов последовательности и одно в середине. И снова следует отметить, что этот подход не является систематическим, хотя он демонстрирует широко распространенный образец, которому можно следовать при работе с последовательностями или диапазонами значений.
Какими недостатками обладают указанные тесты?
• Один и тот же код приходится писать несколько раз.
• Тесты пронумерованы вручную.
• Вывод минимальный (мало информативный).
Поразмыслив, мы решили записать тесты в файл. Каждый тест должен иметь идентифицирующую метку, искомое значение, последовательность и ожидаемый результат. Например:
{ 27 7 { 1 2 3 5 8 13 21} 0 }Это тест под номером
277{ 1,2,3,5,8,13,21 }0falsestruct Test { string label; int val; vector seq; bool res;};istream& operator>>(istream& is, Test& t); // используется описанный // форматint test_all(istream& is){ int error_count = 0; Test t; while (is>>t) { bool r = binary_search( t.seq.begin(), t.seq.end(), t.val); if (r !=t.res) { cout << "отказ: тест " << t.label << "binary_search: " << t.seq.size() << "элементов, val==" << t.val << " –> " << t.res << '\n'; ++error_count; } } return error_count;}int main(){ int errors = test_all(ifstream ("my_test.txt"); cout << "Количество ошибок: " << errors << "\n";}Вот как выглядят некоторые тестовые данные.
{ 1.1 1 { 1 2 3 5 8 13 21 } 1 }{ 1.2 5 { 1 2 3 5 8 13 21 } 1 }{ 1.3 8 { 1 2 3 5 8 13 21 } 1 }{ 1.4 21 { 1 2 3 5 8 13 21 } 1 }{ 1.5 –7 { 1 2 3 5 8 13 21 } 0 }{ 1.6 4 { 1 2 3 5 8 13 21 } 0 }{ 1.7 22 { 1 2 3 5 8 13 21 } 0 }{ 2 1 { } 0 }{ 3.1 1 { 1 } 1 }{ 3.2 0 { 1 } 0 }{ 3.3 2 { 1 } 0 }Здесь видно, почему мы использовали строковую метку, а не число: это позволяет более гибко нумеровать тесты с помощью десятичной точки, обозначающей разные тесты для одной и той же последовательности. Более сложный формат тестов позволяет исключить необходимость повторения одной и той же тестовой последовательности в файле данных.
26.3.2.3. Случайные последовательности
Выбирая значения для тестирования, мы пытаемся перехитрить специалистов, создавших реализацию функции (причем ими часто являемся мы сами), и использовать значения, которые могут выявить слабые места, скрывающие ошибки (например, сложные последовательности условий, концы последовательностей, циклы и т.п.). Однако то же самое мы делаем, когда пишем и отлаживаем свой код. Итак, проектируя тест, мы можем повторить логическую ошибку, сделанную при создании программы, и полностью пропустить проблему. Это одна из причин, по которым желательно, чтобы тесты проектировал не автор программы, а кто-то другой.
Существует один прием, который иногда помогает решить эту проблему: просто сгенерировать много случайных значений. Например, ниже приведена функция, которая записывает описание теста в поток
coutrandint()std_lib.facilities.hvoid make_test(const string& lab,int n,int base,int spread) // записывает описание теста с меткой lab в поток cout // генерирует последовательность из n элементов, начиная // с позиции base // среднее расстояние между элементами равномерно распределено // на отрезке [0, spread]{ cout << "{ " << lab << " " << n << " { "; vector v; int elem = base; for (int i = 0; i elem+= randint(spread); v.push_back(elem); } int val = base + randint(elem–base); // создаем искомое значение bool found = false; for (int i = 0; i // найден ли элемент val if (v[i]==val) found = true; cout << v[i] << " "; } cout << "} " << found << " }\n";}Отметим, что для проверки, найден ли элемент
valbinary_searchНа самом деле функция
binary_searchint no_of_tests = randint(100); // создаем около 50 тестовfor (int i = 0; i string lab = "rand_test_"; make_test(lab+to_string(i), // to_string из раздела 23.2 randint(500), // количество элементов 0, // base randint(50)); // spread}Сгенерированные тесты, основанные на случайных числах, особенно полезны в ситуациях, когда необходимо протестировать кумулятивные эффекты многих операций, результат которых зависит от того, как были обработаны более ранние операции, т.е. от состояния системы (см. раздел 5.2).
Причина, по которой случайные числа не являются панацеей для тестирования функции
binary_searchbinary_search26.3.3. Алгоритмы и не алгоритмы
В качестве примера мы рассмотрели функцию
binary_search()Имеет точно определенные требования к входным данным.
• У него есть точно определенные указания, что он может и чего не может делать с входными данными (в данном случае он не изменяет эти данные).
• Не связан с объектами, которые не относятся явно к его входным данным.
• На его окружение не наложено никаких серьезных ограничений (например, не указано предельное время, объем памяти или объем ресурсов, имеющихся в его распоряжении).
У алгоритма бинарного поиска есть очевидные и открыто сформулированные пред- и постусловия (см. раздел 5.10). Иначе говоря, этот алгоритм — просто мечта тестировщика. Часто нам не так сильно везет и приходится тестировать плохой код (как минимум), сопровождаемый небрежными комментариями на английском языке и парой диаграмм.
Погодите! А не впадаем ли мы в заблуждение? Как можно говорить о корректности и тестировании, если у нас нет точного описания, что именно должен делать сам код? Проблема заключается в том, что многое из того, что должно делать программное обеспечение, нелегко выразить с помощью точных математических терминов. Кроме того, во многих случаях, когда это теоретически возможно, программист не обладает достаточным объемом математических знаний, чтобы написать и протестировать такую программу. Поэтому мы должны расстаться с идеальными представлениями о совершенно точных спецификациях и смириться с реальностью, в которой существуют не зависящие от нас условия и спешка.
А теперь представим себе плохую функцию, которую нам требуется протестировать. Под плохой функцией мы понимаем следующее.
• Входные данные. Требования к входным данным (явные или неявные) сформулированы не так четко, как нам хотелось бы.
• Выходные данные. Результаты (явные или неявные) сформулированы не так четко, как нам хотелось бы.
• Ресурсы. Условия использования ресурсов (время, память, файлы и пр.) сформулированы не так четко, как нам хотелось бы.
Под явным или неявным мы подразумеваем, что следует проверять не только формальные параметры и возвращаемое значение, но и влияние глобальных переменных, потоки ввода-вывода, файлы, распределение свободной памяти и т.д. Что же мы можем сделать? Во-первых, такая функция практически всегда бывает очень длинной, иначе ее требования и действия можно было бы описать более точно. Возможно, речь идет о функции длиной около пяти страниц или функции, использующей вспомогательные функции сложным и неочевидным способом. Для функции пять страниц — это много. Тем не менее мы видели функции намного-намного длиннее. К сожалению, это не редкость.
Если вы проверяете свой код и у вас есть время, прежде всего попробуйте разделить плохую функцию на функции меньшего размера, каждая из которых будет ближе к идеалу функции с точной спецификацией, и в первую очередь протестируйте их. Однако в данный момент мы будем предполагать, что наша цель — тестирование программного обеспечения, т.е. систематический поиск как можно большего количества ошибок, а не простое исправление выявленных дефектов.
Итак, что мы ищем? Наша задача как тестировщиков — искать ошибки. Где они обычно скрываются? Чем отличаются программы, которые чаще всего содержат ошибки?
• Неуловимые зависимости от другого кода. Ищите использование глобальных переменных, аргументы, которые передаются не с помощью константных ссылок, указатели и т.п.
• Управление ресурсами. Обратите внимание на управление памятью (операторы
newdelete• Поищите циклы. Проверьте условия выхода из них (как в функции
binary_search()• Инструкции
ifswitchРассмотрим примеры, иллюстрирующие каждый из перечисленных пунктов.
26.3.3.1. Зависимости
Рассмотрим следующую бессмысленную функцию.
int do_dependent(int a,int& b) // плохая функция // неорганизованные зависимости{ int val; cin>>val; vec[val] += 10; cout << a; b++; return b;}Для тестирования функции
do_dependent()cincoutvecДля того чтобы протестировать функцию
do_dependent()• Входные данные функции
• Значение переменной
a• Значения переменной
bintb• Ввод из потока
cinvalcin• Состояние потока
cout• Значение переменной
vecvec[val]• Выходные данные функции
• Возвращаемое значение.
• Значение переменной типа
intb• Состояние объекта
cin• Состояние объекта
cout• Состояние массива
vecvec[val]• Любые исключения, которые мог сгенерировать массив
vecvec[val] Это длинный список. Фактически он длиннее, чем сама функция. Он отражает наше неприятие глобальных переменных и беспокойство о неконстантных ссылках (и указателях). Все-таки в функциях, которые просто считывают свои аргументы и выводят возвращаемое значение, есть своя прелесть: их легко понять и протестировать.
Как только мы идентифицировали входные и выходные данные, мы тут же оказываемся в ситуации, в которой уже побывали, тестируя
binary_search()do_dependent()valvalvec26.3.3.2. Управление ресурсами
Рассмотрим бессмысленную функцию.
void do_resources1(int a, int b, const char* s) // плохая функция // неаккуратное использование ресурсов{ FILE* f = fopen(s,"r"); // открываем файл (стиль C) int* p = new int[a]; // выделяем память if (b<=0) throw Bad_arg(); // может генерировать исключение int* q = new int[b]; // выделяем еще немного памяти delete[] p; // освобождаем память, // на которую ссылается указатель p}Для того чтобы протестировать функцию
do_resources1()Перечислим очевидные недостатки.
• Файл
s• Память, выделенная для указателя
pb<=0• Память, выделенная для указателя
q0Кроме того, мы всегда должны рассматривать возможность того, что попытка открыть файл закончится неудачей. Для того чтобы получить этот неутешительный результат, мы намеренно использовали устаревший стиль программирования (функция
fopen()void do_resources2(int a, int b, const char* s) // менее плохой код{ ifstream is(s); // открываем файл vectorv1(a); // создаем вектор (выделяем память) if (b<=0) throw Bad_arg(); // может генерировать исключение vector v2(b); // создаем другой вектор (выделяем память) } Теперь каждый ресурс принадлежит объекту и освобождается его деструктором. Иногда, чтобы выработать идеи для тестирования, полезно попытаться сделать функцию более простой и ясной. Общую стратегию решения задач управления ресурсами обеспечивает метод RAII (Resource Acquisition Is Initialization — получение ресурса есть инициализация), описанный в разделе 19.5.2.
Отметим, что управление ресурсами не сводится к простой проверке, освобожден ли каждый выделенный фрагмент памяти. Иногда мы получаем ресурсы извне (например, как аргумент), а иногда сами передаем его какой-нибудь функции (как возвращаемое значение). В этих ситуациях довольно трудно понять, правильно ли распределятся ресурсы. Рассмотрим пример.
FILE* do_resources3(int a, int* p, const char* s) // плохая функция // неправильная передача ресурса{ FILE* f = fopen(s,"r"); delete p; delete var; var = new int[27]; return f;}Правильно ли, что функция
do_resources3()do_resources3()p Обратите внимание на то, что мы (преднамеренно) усложнили пример управления ресурсами, использовав глобальную переменную. Если в программе перемешано несколько источников ошибок, ситуация может резко ухудшиться. Как программисты мы стараемся избегать таких ситуаций. Как тестировщики — стремимся найти их.
26.3.3.3. Циклы
Мы уже рассматривали циклы, когда обсуждали функцию
binary_search()Большинство ошибок возникает в конце циклов.
• Правильно ли проинициализированы переменные в начале цикла?
• Правильно ли заканчивается цикл (часто на последнем элементе)?
Приведем пример, который содержит ошибку.
int do_loop(const vector& v) // плохая функция // неправильный цикл{ int i; int sum; while(i<=vec.size()) sum+=v[i]; return sum;}Здесь содержатся три очевидные ошибки. (Какие именно?) Кроме того, хороший тестировщик немедленно выявит возможности для переполнения при добавлении чисел к переменной
sum Многие циклы связаны с данными и могут вызвать переполнение при вводе больших чисел.
Широко известная и особенно опасная ошибка, связанная с циклами и заключающаяся в переполнении буфера, относится к категории ошибок, которые можно перехватить, систематически задавая два ключевых вопроса о циклах.
char buf[MAX]; // буфер фиксированного объемаchar* read_line() // опасная функция{ int i = 0; char ch; while(cin.get(ch) && ch!='\n') buf[i++] = ch; buf[i+1] = 0; return buf;}Разумеется, вы не написали бы ничего подобного! (А почему нет? Что плохого в функции
read_line()// опасный фрагментgets(buf); // считываем строку в переменную bufscanf("%s",buf); // считываем строку в переменную buf Поищите описание функций
gets()scanf()gets()26.3.3.4. Ветвление
Очевидно, что, делая выбор, мы можем принять неправильное решение. Из-за этого инструкции
ifswitch• Все ли возможные варианты предусмотрены?
• Правильные ли действия связаны с правильными вариантами выбора?
Рассмотрим следующую бессмысленную функцию:
void do_branch1(int x, int y) // плохая функция // неправильное использование инструкции if{ if (x<0) { if (y<0) cout << "Большое отрицательное число \n"; else cout << "Отрицательное число \n"; } else if (x>0) { if (y<0) cout << "Большое положительное число \n"; else cout << "Положительное число \n"; }}Наиболее очевидная ошибка в этом фрагменте заключается в том, что мы забыли о варианте, в котором переменная
xx>0 && y<0x>0 && y>=0Чем более сложными являются варианты использования инструкций
ifdo_branch1()do_branch1(–1,–1);do_branch1(–1, 1);do_branch1(1,–1);do_branch1(1,1);do_branch1(–1,0);do_branch1(0,–1);do_branch1(1,0);do_branch1(0,1);do_branch1(0,0);По существу, это наивный подход “перебора всех альтернатив”, которой мы применили, заметив, что функция
do_branch1()<>xОбработка инструкций
switchifvoid do_branch1(int x, int y) // плохая функция // неправильное использование инструкции switch{ if (y<0 && y<=3) switch (x) { case 1: cout << "Один\n"; break; case 2: cout << "Два\n"; case 3: cout << "Три\n"; }}Здесь сделаны четыре классические ошибки.
• Мы проверяем значения неправильной переменной (
yx• Мы забыли об инструкции
breakx==2• Мы забыли о разделе
defaultif• Мы написали
y<00 Как тестировщики мы всегда ищем непредвиденные варианты. Пожалуйста, помните, что просто устранить проблему недостаточно. Она может возникнуть снова, когда мы ее не ожидаем. Мы хотим писать тесты, которые систематически выявляют ошибки. Если мы просто исправим этот простой код, то можем либо неправильно решить задачу, либо внести новую ошибку. Цель анализа кода заключается не только в выявлении ошибок (хотя это всегда полезно), а в разработке удобного набора тестов, позволяющих выявить все ошибки (или, говоря более реалистично, большинство ошибок).
Подчеркнем, что циклы всегда содержат неявные инструкции if: они выполняют проверку условия выхода из цикла. Следовательно, циклы также являются инструкциями ветвления. Когда мы анализируем программы, содержащие инструкции ветвления, первым возникает следующий вопрос: все ли ветви мы проверили? Удивительно, но в реальной программе это не всегда возможно (потому что в реальном коде функции вызываются так, как удобно другим функциям, и не всегда любыми способами). Затем возникает следующий вопрос: какую часть кода мы проверили? И в лучшем случае мы можем ответить: “Мы проверили большинство ветвей”, объясняя, почему мы не смогли проверить остальные ветви. В идеале при тестировании мы должны проверить 100% кода.
26.3.4. Системные тесты
Тестирование любой более или менее значимой системы требует опыта. Например, тестирование компьютеров, управляющих телефонной системой, проводится в специально оборудованных комнатах с полками, заполненными компьютерами, имитирующими трафик десятков тысяч людей. Такие системы стоят миллионы долларов и являются результатом работы коллективов очень опытных инженеров. Предполагается, что после их развертывания основные телефонные коммутаторы будут непрерывно работать двадцать лет, а общее время их простоя составит не более двадцати минут (по любым причинам, включая исчезновение энергопитания, наводнения и землетрясения). Мы не будем углубляться в детали — легче научить новичка, не знающего физики, вычислить поправки к курсу космического аппарата, спускающегося на поверхность Марса, — но попытаемся изложить идеи, которые могут оказаться полезными при тестировании менее крупных проектов или для понимания принципов тестирования более крупных систем.
Прежде всего следует вспомнить, что целью тестирования является поиск ошибок, особенно часто встречающихся и потенциально опасных. Написать и выполнить большое количество тестов не просто. Отсюда следует, что для тестировщика крайне желательно понимать сущность тестируемой системы. Для эффективного тестирования систем знание прикладной области еще важнее, чем для тестирования отдельных модулей. Для разработки системы необходимо знать не только язык программирования и компьютерные науки, но и прикладную область, а также людей, которые будут использовать приложение. Это является одной из мотиваций для работы с программами: вы увидите много интересных приложений и встретите много интересных людей.
Для того чтобы протестировать полную систему, необходимо создать все ее составные части (модули). Это может занять значительное время, поэтому многие системные тесты выполняются только один раз в сутки (часто ночью, когда предполагается, что разработчики спят) после тестирования всех модулей по отдельности. В этом процессе ключевую роль играют регрессивные тесты. Самой подозрительной частью программы, в которой вероятнее всего кроются ошибки, является новый код и те области кода, в которых ранее уже обнаруживались ошибки. По этой причине важной частью тестирования (на основе регрессивных тестов) является выполнение набора предыдущих тестов; без этого крупная система никогда не станет устойчивой. Мы можем вносить новые ошибки с той же скоростью, с которой удаляются старые.
Обратите внимание на то, что мы считаем неизбежным случайное внесение новых ошибок при исправлении старых. Мы рассчитываем, что новых ошибок меньше, чем старых, которые уже удалены, причем последствия новых ошибок менее серьезные. Однако, по крайней мере пока, мы вынуждены повторять регрессивные тесты и добавлять новые тесты для нового кода, предполагая, что наша система вышла из строя (из-за новых ошибок, внесенных в ходе исправления).
26.3.4.1. Зависимости
Представьте себе, что вы сидите перед экраном, стараясь систематически тестировать программу со сложным графическим пользовательским интерфейсом. Где щелкнуть мышью? В каком порядке? Какие значения я должен ввести? В каком порядке? Для любой сложной программы ответить на все эти вопросы практически невозможно. Существует так много возможностей, что стоило бы рассмотреть предложение использовать стаю голубей, которые клевали бы по экрану в случайном порядке (они работали бы всего лишь за птичий корм!). Нанять большое количество новичков и глядеть, как они “клюют”, — довольно распространенная практика, но ее нельзя назвать систематической стратегией. Любое реальное приложение сопровождается неким повторяющимся набором тестов. Как правило, они связаны с проектированием интерфейса, который заменяет графический пользовательский интерфейс.
Зачем человеку сидеть перед экраном с графическим интерфейсом и “клевать”? Причина заключается в том, что тестировщики не могут предвидеть возможные действия пользователя, которые он может предпринять по ошибке, из-за неаккуратности, по наивности, злонамеренно или в спешке. Даже при самом лучшем и самом систематическом тестировании всегда существует необходимость, чтобы систему испытывали живые люди. Опыт показывает, что реальные пользователи любой значительной системы совершают действия, которые не предвидели даже опытные проектировщики, конструкторы и тестировщики. Как гласит программистская пословица: “Как только ты создашь систему, защищенную от дурака, природа создаст еще большего дурака”.
Итак, для тестирования было бы идеальным, если бы графический пользовательский интерфейс просто состоял из обращений к точно определенному интерфейсу главной программы. Иначе говоря, графический пользовательский интерфейс просто предоставляет возможности ввода-вывода, а любая важная обработка данных выполняется отдельно от ввода-вывода. Для этого можно создать другой (неграфический) интерфейс.

Это позволяет писать или генерировать сценарии для главной программы так, как мы это делали при тестировании отдельных модулей (см. раздел 26.3.2). Затем мы можем протестировать главную программу отдельно от графического пользовательского интерфейса.

Интересно, что это позволяет нам наполовину систематически тестировать графический пользовательский интерфейс: мы можем запускать сценарии, используя текстовый ввод-вывод, и наблюдать за его влиянием на графический пользовательский интерфейс (предполагая, что мы посылаем результаты работы главной программы и графическому пользовательскому интерфейсу, и системе текстового ввода-вывода). Мы можем поступить еще более радикально и обойти главное приложение, тестируя графический пользовательский интерфейс, посылая ему текстовые команды непосредственно с помощью небольшого транслятора команд.
Приведенный ниже рисунок иллюстрирует два важных аспекта хорошего тестирования.

• Части системы следует (по возможности) тестировать по отдельности. Только модули с четко определенным интерфейсом допускают тестирование по отдельности.
• Тесты (по возможности) должны быть воспроизводимыми. По существу, ни один тест, в котором задействованы люди, невозможно воспроизвести в точности.
Рассмотрим также пример проектирования с учетом тестирования, которое мы уже упоминали: некоторые программы намного легче тестировать, чем другие, и если бы мы с самого начала проекта думали о его тестировании, то могли бы создать более хорошо организованную и легче поддающуюся тестированию систему (см. раздел 26.2). Более хорошо организованную? Рассмотрим пример.

Эта диаграмма намного проще, чем предыдущая. Мы можем начать конструирование нашей системы, не заглядывая далеко вперед, — просто используя свою любимую библиотеку графического интерфейса в тех местах, где необходимо обеспечить взаимодействие пользователя и программы. Возможно, для этого понадобится меньше кода, чем в нашем гипотетическом приложении, содержащем как текстовый, так и графический интерфейс. Как наше приложение, использующее явный интерфейс и состоящее из большего количества частей, может оказаться лучше организованной, чем простое и ясное приложение, в котором логика графического пользовательского интерфейса разбросана по всему коду?
Для того чтобы иметь два интерфейса, мы должны тщательно определить интерфейс между главной программой и механизмом ввода-вывода. Фактически мы должны определить общий слой интерфейса ввода-вывода (аналогичный транслятору, который мы использовали для изоляции графического пользовательского интерфейса от главной программы).
Мы уже видели такой пример: классы графического интерфейса из глав 13–16. Они изолируют главную программу (т.е. код, который вы написали) от готовой системы графического пользовательского интерфейса: FLTK, Windows, Linux и т.д. При такой схеме мы можем использовать любую систему ввода-вывода.

Важно ли это? Мы считаем, что это чрезвычайно важно. Во-первых, это облегчает тестирование, а без систематического тестирования трудно серьезно рассуждать о корректности. Во-вторых, это обеспечивает переносимость программы. Рассмотрим следующий сценарий. Вы организовали небольшую компанию и написали ваше первое приложение для системы Apple, поскольку (так уж случилось) вам нравится именно эта операционная система. В настоящее время дела вашей компании идут успешно, и вы заметили, что большинство ваших потенциальных клиентов выполняют свои программы под управлением операционной систем Windows или Linux. Что делать? При простой организации кода с командами графического интерфейса (Apple Mac), разбросанными по всей программе, вы будете вынуждены переписать всю программу. Эта даже хорошо, потому что она, вероятно, содержит много ошибок, не выявленных в ходе несистематического тестирования. Однако представьте себе альтернативу, при которой главная программа отделена от графического пользовательского интерфейса (для облегчения систематического тестирования). В этом случае вы просто свяжете другой графический пользовательский интерфейс со своими интерфейсными классами (транслятор на диаграмме), а большинство остального кода системы останется нетронутым.
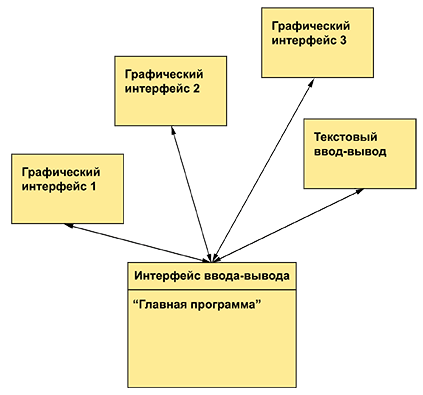
На самом деле эта схема представляет собой пример использования “тонких” явных интерфейсов, которые явным образом отделяют части программы друг от друга. Это похоже на использование уровней, которые мы видели в разделе 12.4. Тестирование усиливает желание разделить программу на четкие отдельные модули (с интерфейсами, которые можно использовать для тестирования).
26.3.5. Тестирование классов
С формальной точки зрения тестирование классов представляет собой тестирование модулей, но с учетом того, что у каждого класса обычно есть несколько функций-членов и некоторое состояние, тестирование классов имеет признаки тестирования систем. Особенно это относится к базовым классам, которые необходимо рассматривать в разных контекстах (определенных разными производными классами). Рассмотрим класс
Shapeclass Shape { // задает цвет и стиль, хранит последовательность линийpublic: void draw() const; // задает цвет и рисует линии virtual void move(int dx, int dy); // перемещает фигуру // на +=dx и +=dy void set_color(Color col); Color color() const; void set_style(Line_style sty); Line_style style() const; void set_fill_color(Color col); Color fill_color() const; Point point(int i) const; // доступ к точкам без права // модификации int number_of_points() const; virtual ~Shape() { }protected: Shape(); virtual void draw_lines() const; // рисует соответствующие точки void add(Point p); // добавляет точку p void set_point(int i,Point p); // points[i]=p;private: vector points; // не используется всеми // фигурами Color lcolor; // цвет для линий и символов Line_style ls; Color fcolor; // цвет заполнения Shape(const Shape&); // предотвращает копирование Shape& operator=(const Shape&);};Как приступить к тестированию этого класса? Сначала рассмотрим, чем класс
Shapebinary_search• Класс
Shape• Состояние объекта класса
Shape• Класс
ShapeShape• Класс
Shape• Изменение объекта класса
Shape Последний момент особенно неприятный. По существу, это значит, что мы должны посадить перед компьютером человека, который будет смотреть, правильно ли ведет себя объект класса
Shape Отметим важную деталь: пользователь может добавлять точки, но не может их удалять. Пользователь или функции класса
ShapeЧто мы можем тестировать, а что не можем? Для того чтобы тестировать класс
ShapeShapeРанее мы уже отметили, что объект класса
Shapevector points; Color lcolor; // цвет линий и символовLine_style ls;Color fcolor; // цвет заполненияВсе, что мы можем сделать с объектом класса
ShapeПростейшим объектом класса
ShapeLineLine ln(Point(10,10), Point(100, 100));ln.draw(); // смотрим, что произошло// проверка точек:if (ln.number_of_points() != 2) cerr << "Неправильное количество точек ";if (ln.point(0)!=Point(10,10)) cerr << "Неправильная точка 1";if (ln.point(1)!=Point(100,100)) cerr << "Неправильная точка 2";for (int i=0; i<10; ++i) { // смотрим на перемещения объекта ln.move(i+5,i+5); ln.draw();}for (int i=0; i<10; ++i) { // проверяем, возвращается ли объект // в исходное положение ln.move(i–5,i–5); ln.draw();}if (point(0)!=Point(10,10)) cerr << "Неправильная точка 1 после перемещения";if (point(1)!=Point(100,100)) cerr << "Неправильная точка 2 после перемещения";for (int i = 0; i<100; ++i) { // смотрим, правильно ли изменяются // цвета ln.set_color(Color(i*100)); if (ln.color() != Color(i*100)) cerr << "Неправильное значение set_color"; ln.draw();}for (int i = 0; i<100; ++i) { // смотрим, правильно ли изменяется // стиль ln.set_style(Line_style(i*5)); if (ln.style() != Line_style(i*5)) cerr << "Неправильное значение set_style"; ln.draw();}В принципе эта программа тестирует создание, перемещение, цвет и стиль. На практике мы должны учесть много больше факторов (с учетом отклонений от сценария), как мы это делали при тестировании функции
binary_searchКроме того, мы выясним, что совершенно не обязательно усаживать перед экраном компьютера человека, который отслеживал бы изменения состояния объектов класса
Shape• замедлить работу программы, чтобы за ней мог следить наблюдатель;
• найти такое представление класса
ShapeОтметим, что мы еще не тестировали функцию
add(Point)Open_polyline26.3.6. Поиск предположений, которые не выполняются
Спецификация класса
binary_search К сожалению, нет. Поскольку мы являемся тестировщиками, мы не можем изменять код, а для того чтобы выявить нарушение требований интерфейса (предусловий), их надо проверять либо перед каждым вызовом, либо сделать частью реализации каждого вызова (см. раздел 5.5). Если же мы тестируем свой собственный код, то можем вставлять такие тесты. Если мы являемся тестировщиками, и люди, написавшие код, прислушиваются к нам (что бывает не всегда), то можем сообщить им о непроверяемых требованиях и убедить их вставить в код такие проверки.
Рассмотрим функцию
binary_search[first:last]templatebool b2(Iter first, Iter last, const T& value){ // проверяем, является ли диапазон [first:last) // последовательностью: if (last // проверяем, является ли последовательность упорядоченной : for (Iter p = first+1; p if (*p<*(p–1)) throw Not_ordered(); // все хорошо, вызываем функцию binary_search: return binary_search(first,last,value);}Перечислим причины, по которым функция
binary_search• Условие
laststd::list<firstlast• Просмотр последовательности для проверки того, что ее значения упорядочены, является более затратным, чем выполнение самой функции
binary_searchbinary_searchstd::findЧто же мы могли бы сделать? Мы могли бы при тестировании заменить функцию
binary_searchb2binary_searchbinary_searchtemplate // предупреждение: // содержит псевдокодbool binary_search (Iter first, Iter last, const T& value){ if ( тест включен ) { if (Iter является итератором произвольного доступа) { // проверяем, является ли [first:last) // последовательностью : if (last } // проверяем является ли последовательность // упорядоченной: if (first!=last) { Iter prev = first; for (Iter p = ++first; p!=last; ++p, ++ prev) if (*p<*prev) throw Not_ordered(); } } // теперь выполняем функцию binary_search}Поскольку смысл условия тест включен зависит от способа организации тестирования (для конкретной системы в конкретной организации), можем оставить его в виде псевдокода: при тестировании своего собственного кода можете просто использовать переменную
test_enabled26.4. Проектирование с учетом тестирования
Приступая к написанию программы, мы знаем, что в итоге она должна быть полной и правильной. Мы также знаем, что для этого ее необходимо тестировать. Следовательно, разрабатывая программу, мы должны учитывать возможности ее тестирования с первого дня. Многие хорошие программисты руководствуются девизом “Тестируй заблаговременно и часто” и не пишут программу, если не представляют себе, как ее тестировать. Размышление о тестировании на ранних этапах разработки программы позволяет избежать ошибок (и помогает найти их позднее). Мы разделяем эту точку зрения. Некоторые программисты даже пишут тесты для модулей еще до реализации самих модулей.
Примеры из разделов 26.3.2.1 и 26.3.3 иллюстрируют эти важные положения.
• Пишите точно определенные интерфейсы так, чтобы вы могли написать для них тесты.
• Придумайте способ описать операции в виде текста, чтобы их можно было хранить, анализировать и воспроизводить. Это относится также к операциям вывода.
• Встраивайте тесты для непроверяемых предположений (assertions) в вызывающем коде, чтобы перехватить неправильные аргументы до системного тестирования.
• Минимизируйте зависимости и делайте их явными.
• Придерживайтесь ясной стратегии управления ресурсами.
С философской точки зрения это можно рассматривать как применение методов модульного тестирования для проверки подсистем и полных систем.
Если производительность работы программы не имеет большого значения, то в ней можно навсегда оставить проверку предположений (требований, предусловий), которые в противном случае остались бы непроверяемыми. Однако существуют причины, по которым это не делают постоянно. Например, мы уже указывали, что проверка упорядоченности последовательности сложна и связана с гораздо большими затратами, чем сама функция
binary_sort26.5. Отладка
Отладка — это вопрос техники и принципов, в котором принципы играют ведущую роль. Пожалуйста, перечитайте еще раз главу 5. Обратите внимание на то, чем отладка отличается от тестирования. В ходе обоих процессов вылавливаются ошибки, но при отладке это происходит не систематически и, как правило, связано с удалением известных ошибок и реализацией определенных свойств. Все, что мы делаем на этапе отладки, должно выполняться и при тестировании. С небольшим преувеличением можно сказать, что мы любим тестирование, но определенно ненавидим отладку. Хорошее тестирование модулей на ранних этапах их разработки и проектирования с учетом тестирования помогает минимизировать отладку.
26.6. Производительность
Для того чтобы программа оказалась полезной, мало, чтобы она была правильной. Даже если предположить, что она имеет все возможности, чтобы быть полезной, она к тому же должна обеспечивать приемлемый уровень производительности. Хорошая программа является достаточно эффективной; иначе говоря, она выполняется за приемлемое время и при доступных ресурсах. Абсолютная эффективность никого не интересует, и стремление сделать программу как можно более быстродействующей за счет усложнения ее кода может серьезно повредить всей системе (из-за большего количества ошибок и большего объема отладки), повысив сложность и дороговизну ее эксплуатации (включая перенос на другие компьютеры и настройку производительности ее работы).
Как же узнать, что программа (или ее модуль) является достаточно эффективной? Абстрактно на этот вопрос ответить невозможно. Современное аппаратное обеспечение работает настолько быстро, что для многих программ этот вопрос вообще не возникает. Нам встречались программы, намеренно скомпилированные в режиме отладки (т.е. работающие в 25 раз медленнее, чем требуется), чтобы повысить возможности диагностики ошибок, которые могут возникнуть после их развертывания (это может произойти даже с самым лучшим кодом, который вынужден сосуществовать с другими программами, разработанными “где-то еще”).
Следовательно, ответ на вопрос “Достаточно ли эффективной является программа?” звучит так: “Измерьте время, за которое выполняется интересный тест”. Очевидно, что для этого необходимо очень хорошо знать своих конечных пользователей и иметь представление о том, что именно они считают интересным и какую продолжительность работы считают приемлемой для такого интересного теста. Логически рассуждая, мы просто отмечаем время на секундомере при выполнении наших тестов и проверяем, не работали ли они дольше разумного предела. С помощью функции
clock() Варианты, продемонстрировавшие худшие показатели производительности, обычно обусловлены неудачным выбором алгоритма и могут быть обнаружены на этапе отладки. Одна из целей тестирования программ на крупных наборах данных заключается в выявлении неэффективных алгоритмов. В качестве примера предположим, что приложение должно суммировать элементы, стоящие в строках матрицы (используя класс
MatrixНекто предложил использовать подходящую функцию.
double row_sum(Matrix m, int n); // суммирует элементы в m[n] Потом этот некто стал использовать эту функцию для того, чтобы сгенерировать вектор сумм, где
v[n]ndouble row_accum(Matrix m, int n) // сумма элементов // в m[0:n){ double s = 0; for (int i=0; i return s;} // вычисляет накопленные суммы по строкам матрицы m: vector v; for (int i = 0; i v.push_back(row_accum(m,i+1));Представьте себе, что этот код является частью модульного теста или выполняется как часть системного теста. В любом случае вы заметите нечто странное, если матрица станет действительно большой: по существу, время, необходимое для выполнения программы, квадратично зависит от размера матрицы
mrow_sum()Вы можете возразить: “Никто никогда не сможет сделать нечто настолько глупое!” Извините, но мы видели вещи и похуже, и, как правило, плохой (с точки зрения производительности) алгоритм очень нелегко выявить, если он глубоко скрыт в коде приложения. Заметили ли вы проблемы с производительностью, когда в первый раз увидели этот код? Проблему бывает трудно выявить, если не искать ее целенаправленно. Рассмотрим простой реальный пример, найденный на одном сервере.
for (int i=0; iЧасто переменная
sНе все проблемы, связанные с производительностью программы, объясняются плохим алгоритмом. Фактически (как мы указывали в разделе 26.3.3) большую часть кода, который мы пишем, нельзя квалифицировать как плохой алгоритм.
Такие “неалгоритмические” проблемы обычно связаны с неправильным проектированием. Перечислим некоторые из них.
• Повторяющееся перевычисление информации (как, например, в приведенном выше примере).
• Повторяющаяся проверка одного и того же факта (например, проверка того, что индекс не выходит за пределы допустимого диапазона при каждом его использовании в теле цикла, или повторяющаяся проверка аргумента, который передается от одной функции другой без каких-либо изменений).
• Повторяющиеся обращения к диску (или к сети).
Обратите внимание на слово “повторяющиеся”. Очевидно, что мы имеем в виду “напрасно повторяющееся”, поскольку на производительность оказывают влияние лишь те действия, которые выполняются много раз. Мы являемся горячими сторонниками строгой проверки аргументов функций и переменных циклов, но если мы миллионы раз проверяем одну и ту же переменную, то такие излишние проверки могут нанести ущерб производительности программы. Если в результате измерений выяснится, что производительность упала, мы должны изыскать возможность удалить повторяющиеся действия. Не делайте этого, пока не убедитесь, что производительность программы действительно стала неприемлемо низкой. Дело в том, что преждевременная оптимизация часто является источником многих ошибок и занимает много времени.
26.6.1. Измерение времени
Как понять, достаточно ли быстро работает фрагмент кода? Как узнать, насколько быстро работает данная операция? Во многих ситуациях, связанных с измерением времени, можете просто посмотреть на часы (секундомер, стенные или наручные часы). Это не научно и не точно, но, если не произойдет чего-то непредвиденного, вы можете прийти к выводу, что программа работает достаточно быстро. Тем не менее этот подход неприемлем для тех, кого беспокоят вопросы производительности программ.
Если вам необходимо измерять более мелкие интервалы времени или вы не хотите сидеть с секундомером, вам следует научиться использовать возможности компьютера, так как он знает, как измерить время. Например, в системе Unix достаточно просто поставить перед командой слово
timetimex.cppg++ x.cppДля того чтобы измерить продолжительность компиляции, поставьте перед ней слово
timetime g++ x.cppСистема откомпилирует файл
x.cpp А что, если вы хотите измерить интервал времени, длящийся всего несколько миллисекунд? Что, если вы хотите выполнить свои собственные, более подробные измерения, связанные с работой части вашей программы? Продемонстрируем использование функции
clock()do_something()#include #include using namespace std;int main(){ int n = 10000000; // повторяем do_something() n раз clock_t t1 = clock(); // начало отсчета if (t1 == clock_t(–1)) { // clock_t(–1) значит "clock() // не работает" cerr << "Извините, таймер не работает \n"; exit(1); } for (int i = 0; i clock_t t2 = clock(); // конец отсчета if (t2 == clock_t(–1)) { cerr << "Извините, таймер переполнен \n"; exit(2); } cout << "do_something() " << n << " раз занимает " << double(t2–t1)/CLOCKS_PER_SEC << " сек " << " (точность измерений: " << CLOCKS_PER_SEC << " сек)\n";}Функция
clock()clock_tdouble(t2–t1)clock_tclock()clock()t1t2clock()double(t2–t1)/CLOCKS_PER_SECclock()CLOCKS_PER_SECЕсли функция
clock()clock()clock_t(–1)clock()clock_tintCLOCKS_PER_SEC1000000clock() Напоминаем: нельзя доверять любым измерениям времени, которые нельзя повторить, получив примерно одинаковые результаты. Что значит “примерно одинаковые результаты”? Примерно 10%. Как мы уже говорили, современные компьютеры являются быстрыми: они выполняют миллиард инструкций в секунду. Это значит, что вы не можете измерить продолжительность ни одной операции, если она не повторяется десятки тысяч раз или если программа не работает действительно очень медленно, например, записывая данные на диск или обращаясь в веб. В последнем случае вы должны повторить действие несколько сотен раз, но медленная работа программы должна вас насторожить.
26.7. Ссылки
Stone, Debbie, Caroline Jarrett, MarkWoodroffe, and Shailey Minocha. User Interface Design and Evaluation. Morgan Kaufmann, 2005. ISBN 0120884364.
Whittaker, James A. How to Break Software: A Practical Guide to Testing. Addison-Wesley, 2003. ISBN 0321194330.
Задание
Протестируйте функцию
binary_search1. Реализуйте оператор ввода для класса
Test2. Заполните файл тестов для последовательностей из раздела 26.3.
2.1.
{ 1 2 3 5 8 13 21 } // "обычная последовательность"2.2.
{ }2.3.
{ 1 }2.4.
{ 1 2 3 4 } // нечетное количество элементов2.5.
{ 1 2 3 4 5 } // четное количество элементов2.6.
{ 1 1 1 1 1 1 1 } // все элементы равны2.7.
{ 0 1 1 1 1 1 1 1 1 1 1 1 1 } // другой элемент в начале2.8.
{ 0 0 0 0 0 0 0 0 0 0 0 0 0 1 } // другой элемент в конце3. Основываясь на разделе 26.3.1.3, выполните программу, генерирующую следующие варианты.
3.1. Очень большая последовательность (что считать большой последовательностью и почему?).
3.2. Десять последовательностей со случайным количеством элементов.
3.3. Десять последовательностей с 0, 1, 2 ... 9 со случайными элементами (но упорядоченные).
4. Повторите эти тесты для последовательностей строк, таких как
{ Bohr Darwin Einstein Lavoisier Newton Turing }Контрольные вопросы
1. Создайте список приложений, сопровождая их кратким описанием наихудшего события, которое может произойти из-за ошибки; например, управление самолетом — авиакатастрофа: гибель 231 человека; потеря оборудования на 500 млн. долл.
2. Почему мы не можем просто доказать, что программа работает правильно?
3. В чем заключается разница между модульным и системным тестированием?
4. Что такое регрессивное тестирование и почему оно является важным?
5. Какова цель тестирования?
6. Почему функция
binary_search7. Если мы не можем проверить все возможные ошибки, то какие ошибки следует искать в первую очередь?
8. В каких местах кода, манипулирующего последовательностью элементов, вероятнее обнаружить ошибки?
9. Почему целесообразно тестировать программу при больших значениях?
10. Почему часто тесты представляются в виде данных, а не в виде кода?
11. Почему и когда мы используем многочисленные тесты, основанные на случайных величинах?
12. Почему трудно тестировать программы, использующие графический пользовательский интерфейс?
13. Что необходимо тестировать при проверке отдельного модуля?
14. Как связаны между собой тестируемость и переносимость?
15. Почему классы тестировать труднее, чем функции?
16. Почему важно, чтобы тесты были воспроизводимыми?
17. Что может сделать тестировщик, обнаружив, что модуль основан на непроверяемых предположениях (предусловиях)?
18. Как проектировщик/конструктор может улучшить тестирование?
19. Чем тестирование отличается от отладки?
20. В чем заключается важность производительности?
21. Приведите два (и больше) примера того, как легко возникают проблемы с производительностью.
Ключевые слова

Упражнения
1. Выполните ваш алгоритм
binary search2. Настройте тестирование функции
binary_searchstring3. Повторите упражнение 1 с вариантом функции
binary_search4. Изобретите формат для тестовых данных, чтобы можно было один раз задать последовательность и выполнить для нее несколько тестов.
5. Добавьте новый тест в набор тестов для функции
binary_search6. Слегка модифицируйте калькулятор из главы 7, предусмотрев ввод из файла и вывод в файл (или используя возможности операционной системы для перенаправления ввода-вывода). Затем изобретите для него исчерпывающий набор тестов.
7. Протестируйте простой текстовый редактор из раздела 20.6.
8. Добавьте текстовый интерфейс к библиотеке графического пользовательского интерфейса из глав 12–15. Например, строка
Circle(Point(0,1),15)Circle(Point(0,1),15)9. Добавьте формат текстового вывода к библиотеке графического интерфейса. Например, при выполнении вызова
Circle(Point(0,1),15)Circle(Point(0,1),15)10. Используя текстовый интерфейс из упр. 9, напишите более качественный тест для библиотеки графического пользовательского интерфейса.
11. Оцените время выполнения суммирования в примере из раздела 26.6, где
m[–10:10]vO(n2)12. Напишите программу, генерирующую случайные числа с плавающей точкой, и отсортируйте их с помощью функции
std::sort()double13. Повторите эксперимент из предыдущего упражнения, но со случайными строками, длина которых лежит в интервале
[0:100]14. Повторите предыдущее упражнение, но на этот раз используйте контейнер
mapvectorПослесловие
Как программисты мы мечтаем о прекрасных программах, которые бы просто работали и желательно с первой же попытки. Реальность иная: трудно сразу написать правильную программу и предотвратить внесение в нее ошибок по мере того, как вы (и ваши коллеги) станете ее улучшать. Тестирование, включая проектирование с учетом тестирования, — это главный способ, гарантирующий, что система в итоге действительно будет работать. Живя в высокотехнологичном мире, мы должны в конце рабочего дня с благодарностью вспомнить о тестировщиках (о которых часто забывают).
Глава 27 Язык программирования С
“С — это язык программирования
со строгим контролем типов и слабой проверкой”.
Деннис Ритчи (Dennis Ritchie)
Данная глава представляет собой краткий обзор языка программирования С и его стандартной библиотеки с точки зрения человека, знающего язык С++. В ней перечислены свойства языка С++, которых нет в языке C, и приведены примеры того, как программистам на языке С обойтись без них. Рассмотрены различия между языками C и C++, а также вопросы их одновременного использования. Приведены примеры ввода-вывода, список операций, управление памятью, а также иллюстрации операций над строками.
27.1. Языки С и С++: братья
Язык программирования С был изобретен и реализован Деннисом Ритчи (Dennis Ritchie) из компании Bell Labs. Он изложен в книге The C Programming Language Брайана Кернигана (Brian Kernighan) и Денниса Ритчи (Dennis Ritchie) (в разговорной речи известной как “K&R”), которая, вероятно, является самым лучшим введением в язык С и одним из лучших учебников по программированию (см. раздел 22.2.5). Текст исходного определения языка С++ был редакцией определения языка С, написанного в 1980 году Деннисом Ритчи. После этого момента оба языка стали развиваться самостоятельно. Как и язык C++, язык C в настоящее время определен стандартом ISO.
Мы рассматриваем язык С в основном как подмножество языка С++. Следовательно, с точки зрения языка С++ проблемы описания языка С сводятся к двум вопросам.
• Описать те моменты, в которых язык С не является подмножеством языка C++.
• Описать те свойства языка С++, которых нет в языке C, и те возможности и приемы, с помощью которых этот недостаток можно компенсировать.
Исторически современный язык С++ и современный язык С являются “братьями”. Они оба являются наследниками “классического С”, диалекта языка С, описанного в первом издании книги Кернигана и Ритчи The C Programming Language, в который были добавлены присваивание структур и перечислений.

В настоящее время практически повсеместно используется версия C89 (описанная во втором издании книги K&R[12]). Именно эту версию мы излагаем в данном разделе. Помимо этой версии, кое-где все еще по-прежнему используется классический С, и есть несколько примеров использования версии C99, но это не должно стать проблемой для читателей, если они знают языки C++ и C89.
Языки С и С++ являются детищами Исследовательского центра компьютерных наук компании Bell Labs (Computer Science Research Center of Bell Labs), МюррейХилл, штат Нью-Джерси (Murray Hill, New Jersey) (кстати, мой офис находился рядом с офисом Денниса Ритчи и Брайана Кернигана).

Оба языка в настоящее время определены и контролируются комитетами по стандартизации ISO. Для каждого языка разработано множество реализаций. Часто эти реализации поддерживают оба языка, причем желаемый язык устанавливается путем указания расширения исходного файла. По сравнению с другими языками, оба языка, С и С++, распространены на гораздо большем количестве платформ.
Оба языка были разработаны и в настоящее время интенсивно используются для решения сложных программистских задач. Перечислим некоторые из них.
• Ядра операционных систем.
• Драйверы устройств.
• Встроенные системы.
• Компиляторы.
• Системы связи.
Между эквивалентными программами, написанными на языках С и С++, нет никакой разницы в производительности.
Как и язык C++, язык C очень широко используется. Взятые вместе, они образуют крупнейшее сообщество по разработке программного обеспечения на Земле.
27.1.1. Совместимость языков С и С++
Часто приходится встречать название “C/C++.” Однако такого языка нет. Употребление такого названия обычно является признаком невежества. Мы используем такое название только в контексте вопросов совместимости и когда говорим о крупном сообществе программистов, использующих оба этих языка.
Язык С++ в основном, но не полностью, является надмножеством языка С. За несколькими очень редкими исключениями конструкции, общие для языков С и С++, имеют одинаковый смысл (семантику). Язык С++ был разработан так, чтобы он был “как можно ближе к языку С++, но не ближе, чем следует”. Он преследовал несколько целей.
• Простота перехода.
• Совместимость.
Многие свойства, оказавшиеся несовместимыми с языком С, объясняются тем, что в языке С++ существует более строгая проверка типов.
Примером программы, являющейся допустимой на языке С, но не на языке С++, является программа, в которой ключевые слова из языка С++ используются в качестве идентификаторов (раздел 27.3.2).
int class(int new, int bool); /* C, но не C++ */Примеры, в которых семантика конструкции, допустимой в обоих языках, отличается в них, найти труднее, но все же они существуют.
int s = sizeof('a'); /* sizeof(int), обычно 4 в языке C и 1 в языке C++ */Строковый литерал, такой как
'a'intcharchcharsizeof(ch)==1.Информация, касающаяся совместимости и различий между языками, не так интересна. В языке С нет никаких изощренных методов программирования, которые стоило бы изучать специально. Вам может понравиться вывод данных с помощью функции
printf()Большинство программистов, работающих на языке С++, рано или поздно так или иначе сталкиваются с программами, написанными на языке С. Аналогично, программисты, создающие программы на языке С, часто вынуждены работать с программами, написанными на языке С++. Большинство из того, что мы описываем в этой главе, уже знакомо программистам, работающим на языке С, но некоторые из этих сведений могут быть отнесены к уровню экспертов. Причина проста: не все имеют одинаковое представление об уровне экспертов, поэтому мы описываем то, что часто встречается в реальных программах. Рассуждения о вопросах совместимости может быть дешевым способом добиться незаслуженной репутации “эксперта по языку С”. Однако следует помнить: реальный опыт достигается благодаря практическому использованию языка (в данном случае языка С), а не изучению эзотерических правил языка (как это излагается в разделах, посвященных совместимости).
Библиография
ISO/IEC 9899:1999. Programming Languages — C. В этой книге описан язык C99; большинство компиляторов реализует язык C89 (часто с некоторыми расширениями).
ISO/IEC 14882:2003-27-01 (2-е издание). Programming Languages — C++. Эта книга написана с точки зрения программиста, идентична версии 1997 года.
Kernighan, Brian W., and Dennis M. Ritchie. The C Programming Language. Addison-Wesley, 1988. ISBN 0131103628.
Stroustrup, Bjarne. “Learning Standard C++ as a New Language”. C/C++ Users Journal,May 1999.
Stroustrup, Bjarne. “C and C++: Siblings”; “C and C++: A Case for Compatibility”; and “C and C++: Case Studies in Compatibility”. The C/C++ Users Journal, July, Aug., and Sept. 2002.
Статьи Страуструпа легко найти на его домашней странице.
27.1.2. Свойства языка С++, которых нет в языке С
С точки зрения языка C++ в языке C (т.е. в версии C89) нет многих свойств.
• Классы и функции-члены.
• В языке С используются структуры и глобальные функции.
• Производные классы и виртуальные функции
• В языке С используются структуры, глобальные функции и указатели на функции (раздел 27.2.3).
• Шаблоны и подставляемые функции
• В языке С используются макросы (раздел 27.8).
• Исключения
• В языке С используются коды ошибок, ошибочные возвращаемые значения и т.п.
• Перегрузка функций
• В языке С каждой функции дается отдельное имя.
• Операторы
new/delete• В языке С используются функции
malloc()/free()• Ссылки
• В языке С используются указатели.
• Ключевое слово
const• В языке С используются макросы.
• Объявления в инструкциях
for• В языке С все объявления должны быть расположены в начале блока, а для каждого набора определений начинается новый блок.
• Тип
bool• В языке С используется тип
int• Операторы
static_castreinterpret_castconst_cast• В языке С используются приведения вида
(int)astatic(a) • // комментарии
• В языке С используются комментарии
/* ... */ На языке С написано много полезных программ, поэтому этот список должен напоминать нам о том, что ни одно свойство языка не является абсолютно необходимым. Большинство языковых возможностей — и даже большинство свойств языка С — разработано только для удобства программистов. В конце концов, при достаточном запасе времени, мастерстве и терпении любую программу можно написать на ассемблере. Обратите внимание на то, что благодаря близости моделей языков С и С++ к реальным компьютерам они позволяют имитировать многие стили программирования.
Остальная часть этой главы посвящена объяснению того, как писать полезные программы без помощи этих свойств. Наши основные советы по использованию языка С++ сводятся к следующему.
• Имитируйте стили программирования, для которых разработаны свойства языка С++, чтобы поддерживать возможности, предусмотренные языком C.
• Когда пишете программу на языке C, считайте его подмножеством языка C++.
• Используйте предупреждения компилятора для проверки аргументов функций.
• Контролируйте стиль программирования на соответствие стандартам, когда пишете большие программы (см. раздел 27.2.2).
Многие детали, касающиеся несовместимости языков С и С++, устарели и носят скорее технический характер. Однако, для того чтобы читать и писать на языке С, вы не обязаны помнить об этом.
• Компилятор сам напомнит вам, если вы станете использовать средства языка С, которых нет в языке C.
• Если вы следуете правилам, перечисленным выше, то вряд ли столкнетесь с чем-либо таким, что в языке С имеет другой смысл по сравнению с языком С++.
В отсутствие всех возможностей языка С++ некоторые средства в языке С приобретают особое значение.
• Массивы и указатели.
• Макросы.
• Оператор
typedef• Оператор
sizeof• Операторы приведения типов.
В этой главе будет приведено несколько примеров использования таких средств.
Я ввел в язык С++ комментарии
///* ... *////* ... */27.1.3. Стандартная библиотека языка С
Естественно, возможности библиотек языка С++, зависящие от классов и шаблонов, в языке С недоступны. Перечислим некоторые из них.
• Класс
vector• Класс
map• Класс
set• Класс
string• Алгоритмы библиотеки STL: например,
sort()find()copy()• Потоки ввода-вывода
iostream• Класс
regexИз-за этого библиотеки языка С часто основаны на массивах, указателях и функциях. К основной части стандартной библиотеки языка С относятся следующие заголовочные файлы.
•
malloc()free()•
•
•
•
•
•
•
•
•
Полное описание стандартной библиотеки языка С можно найти в соответствующем учебнике, например в книге K&R. Все эти библиотеки (и заголовочные файлы) также доступны и в языке С++.
27.2. Функции
В языке C есть несколько особенностей при работе с функциями.
• Может существовать только одна функция с заданным именем.
• Проверка типов аргументов функции является необязательной.
• Ссылок нет (а значит, нет и механизма передачи аргументов по ссылке).
• Нет функций-членов.
• Нет подставляемых функций (за исключением версии C99).
• Существует альтернативный синтаксис объявления функций.
Помимо этого, все остальное мало отличается от языка С++. Изучим указанные отличия по отдельности.
27.2.1. Отсутствие перегрузки имен функций
Рассмотрим следующий пример:
void print(int); /* печать целого числа */void print(const char*); /* печать строки */ /* ошибка! */Второе объявление является ошибкой, потому что в программе, написанной на языке С, не может быть двух функций с одним и тем же именем. Итак, нам необходимо придумать подходящую пару имен.
void print_int(int); /* печать целого числа int */void print_string(const char*); /* печать строки */Иногда это свойство называют преимуществом: теперь вы не сможете случайно использовать неправильную функцию для вывода целого числа! Очевидно, что нас такой аргумент убедить не сможет, а отсутствие перегруженных функций усложняет реализацию идей обобщенного программирования, поскольку они основаны на семантически похожих функциях, имеющих одинаковые имена.
27.2.2. Проверка типов аргументов функций
Рассмотрим следующий пример:
int main(){ f(2);} Компилятор языка С допускает такой код: вы не обязаны объявлять функции до их использования (хотя можете и должны). Определение функции
f()f()К сожалению, это определение в другом исходном файле может выглядеть следующим образом:
/* other_file.c: */int f(char* p){ int r = 0; while (*p++) r++; return r;}Редактор связей не сообщит об этой ошибке. Вместо этого вы получите ошибку на этапе выполнения программы или случайный результат.
Как решить эту проблему? На практике программисты придерживаются согласованного использования заголовочных файлов. Если все функции, которые вы вызываете или определяете, объявлены в заголовке, поставленном в соответствующее место программы с помощью директивы
#includelintВы можете попросить включить проверку аргументов функций в языке С. Для этого достаточно объявить функцию с заданными типами аргументов (точно так же, как в языке С++). Такое объявление называется прототипом функции (function prototype). Тем не менее следует избегать объявлений, не задающих аргументы; они не являются прототипами функций и не включают механизм проверки типов.
int g(double); /* прототип — как в языке С ++ */int h(); /* не прототип — типы аргументов не указаны */void my_fct(){ g(); /* ошибка: пропущен аргумент */ g("asdf"); /* ошибка: неправильный тип аргумента */ g(2); /* OK: 2 преобразуется в 2.0 */ g(2,3); /* ошибка: один аргумент лишний */ h(); /* Компилятор допускает! Результат непредсказуем */ h("asdf"); /* Компилятор допускает! Результат непредсказуем */ h(2); /* Компилятор допускает! Результат непредсказуем */ h(2,3); /* Компилятор допускает! Результат непредсказуем */} В объявлении функции
h()h()lint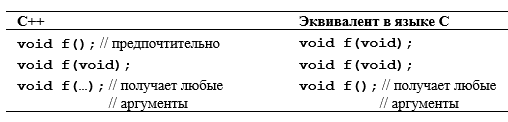
Существует специальный набор правил, регламентирующих преобразование аргументов, если в области видимости нет прототипа функции. Например, переменные типов
charshortintfloatdoublelongОбратите внимание на то, что, хотя компилятор допускает передачу аргументов неправильного типа, например параметр типа
char*27.2.3. Определения функций
Можете определять функции точно так же, как в языке С++. Эти определения являются прототипами функций.
double square(double d){ return d*d;}void ff(){ double x = square(2); /* OK: переводим 2 в 2.0 и вызываем */ double y = square(); /* пропущен аргумент */ double y = square("Hello"); /* ошибка: неправильный тип аргументов */ double y = square(2,3); /* ошибка: слишком много аргументов */}Определение функции без аргументов не является прототипом функции.
void f() { /* что-то делает */ }void g(){ f(2); /* OK в языке C; ошибка в языке C++ */}Код
void f(); /* не указан тип аргумента */означающий, что функция
f()voidvoid f(void); /* не принимает никаких аргументов */ Впрочем, вскоре я об этом пожалел, потому что эта конструкция выглядит странно и при последовательной проверке типов аргументов является излишней. Что еще хуже, Деннис Ритчи (автор языка C) и Дуг Мак-Илрой (Doug McIlroy) (законодатель мод в Исследовательском центре компьютерных наук в компании Bell Labs (Bell Labs Computer Science Research Center; см. раздел 22.2.5) назвали это решение “отвратительным”. К сожалению, оно стало очень популярным среди программистов, работающих на языке С. Тем не менее не используйте его в программах на языке С++, в которых оно выглядит не только уродливо, но и является совершенно излишним.
В языке C есть альтернативное определение функции в стиле языка Algol-60, в котором типы параметров (не обязательно) указываются отдельно от их имен.
int old_style(p,b,x) char* p; char b;{ /* ... */} Это определение “в старом стиле” предвосхищает конструкции языка С++ и не является прототипом. По умолчанию аргумент без объявленного типа считается аргументов типа
intxold_style()intold_style()old_style(); /* OK: пропущены все аргументы */old_style("hello",'a',17); /* OK: все аргументы имеют правильный тип */old_style(12,13,14); /* OK: 12 — неправильный тип */ /* но old_style() может не использовать p */Компилятор должен пропустить эти вызовы (но мы надеемся, что он предупредит о первом и третьем аргументах).
Мы рекомендуем придерживаться следующих правил проверки типов аргументов функций.
• Последовательно используйте прототипы функций (используйте заголовочные файлы).
• Установите уровень предупреждений компилятора так, чтобы перехватывать ошибки, связанные с типами аргументов.
• Используйте (какую-нибудь) программу
lintВ результате вы получите код, который одновременно будет кодом на языке C++.
27.2.4. Вызов функций, написанных на языке С, из программы на языке С++, и наоборот
Вы можете установить связи между файлами, скомпилированными с помощью компилятора языка С, и файлами, скомпилированными с помощью компилятора языка С++, только если компиляторы предусматривают такую возможность. Например, можете связать объектные файлы, сгенерированные из кода на языке С и С++, используя компиляторы GNU C и GCC. Можете также связать объектные файлы, сгенерированные из кода на языке С и С++, используя компиляторы Microsoft C и C++ (MSC++). Это обычная и полезная практика, позволяющая использовать больше библиотек, чем это возможно при использовании только одного из этих языков.
В языке C++ предусмотрена более строгая проверка типов, чем в языке C. В частности, компилятор и редактор связей для языка C++ проверяют, согласованно ли определены и используются функции
f(int)f(double)// вызов функции на языке C из кода на языке C++:extern "C" double sqrt(double); // связь с функцией языка Cvoid my_c_plus_plus_fct(){ double sr = sqrt(2);}По существу, выражение
extern "C"sqrt(double)Мы можем также использовать выражение
extern "C"// вызов функции на языке C++ из кода на языке C:extern "C" int call_f(S* p, int i){ return p–>f(i);}Теперь в программе на языке C можно косвенно вызвать функцию-член
f()/* вызов функции на языке C++ из функции на языке C: */int call_f(S* p, int i);struct S* make_S(int,const char*);void my_c_fct(int i){ /* ... */ struct S* p = make_S(x, "foo"); int x = call_f(p,i); /* ... */}Для того чтобы эта конструкция работала, больше о языке С++ упоминать не обязательно.
Выгоды такого взаимодействия очевидны: код можно писать на смеси языков C и C++. В частности, программы на языке C++ могут использовать библиотеки, написанные на языке C, а программы на языке C могут использовать библиотеки, написанные на языке С++. Более того, большинство языков (особенно Fortran) имеют интерфейс вызова функций, написанных на языке С, и допускают вызов своих функций в программах, написанных на языке С.
В приведенных выше примерах мы предполагали, что программы, написанные на языках C и C++, совместно используют объект, на который ссылается указатель
p// В языке C++:class complex { double re, im;public: // все обычные операции};Тогда можете не передавать указатель на объект в программу, написанную на языке С, и наоборот. Можете даже получить доступ к членам
reim/* В языке C: */struct complex { double re, im; /* никаких операций */}; Правила компоновки в любом языке могут быть сложными, а правила компоновки модулей, написанных на нескольких языках, иногда даже трудно описать. Тем не менее функции, написанные на языках C и C++, могут обмениваться объектами встроенных типов и классами (структурами) без виртуальных функций. Если класс содержит виртуальные функции, можете просто передать указатели на его объекты и предоставить работу с ними коду, написанному на языке C++. Примером этого правила является функция
call_f()f()virtualКроме встроенных типов, простейшим и наиболее безопасным способом совместного использования типов является конструкция
struct27.2.5. Указатели на функции
Что можно сделать на языке С, если мы хотим использовать объектно-ориентированную технологию (см. разделы 14.2–14.4)? По существу, нам нужна какая-то альтернатива виртуальным функциям. Большинству людей в голову в первую очередь приходит мысль использовать структуру с “полем типа” (“type field”), описывающим, какой вид фигуры представляет данный объект. Рассмотрим пример.
struct Shape1 { enum Kind { circle, rectangle } kind; /* ... */};void draw(struct Shape1* p){ switch (p–>kind) { case circle: /* рисуем окружность */ break; case rectangle: /* рисуем прямоугольник */ break; }}int f(struct Shape1* pp){ draw(pp); /* ... */}Этот прием срабатывает. Однако есть две загвоздки.
• Для каждой псевдовиртуальной функции (такой как функция
draw()switch• Каждый раз, когда мы добавляем новую фигуру, мы должны модифицировать каждую псевдовиртуальную функцию (такую как функция
draw()switchВторая проблема носит довольно неприятный характер, поскольку мы не можем включить псевдовиртуальные функции ни в какие библиотеки, так как наши пользователи должны будут довольно часто модифицировать эти функции. Наиболее эффективной альтернативой является использование указателей на функции.
typedef void (*Pfct0)(struct Shape2*);typedef void (*Pfct1int)(struct Shape2*,int);struct Shape2 { Pfct0 draw; Pfct1int rotate; /* ... */};void draw(struct Shape2* p){ (p–>draw)(p);}void rotate(struct Shape2* p, int d){ (p–>rotate)(p,d);}Структуру
Shape2Shape1int f(struct Shape2* pp){ draw(pp); /* ... */}Проделав небольшую дополнительную работу, мы можем добиться, чтобы объекту было не обязательно хранить указатель на каждую псевдовиртуальную функцию. Вместо этого можем хранить указатель на массив указателей на функции (это очень похоже на то, как реализованы виртуальные функции в языке С++). Основная проблема при использовании таких схем в реальных программах заключается в том, чтобы правильно инициализировать все эти указатели на функции.
27.3. Второстепенные языковые различия
В этом разделе приводятся примеры незначительных различий между языками С и С++, которые могут вызвать у читателей затруднения, если они впервые о них слышат. Некоторые из них оказывают серьезное влияние на программирование, поскольку их надо явным образом учитывать.
27.3.1. Дескриптор пространства имен struct
В языке C имена структур (в нем нет ключевого слова
classstructstructstruct pair { int x,y; };pair p1; /* ошибка: идентификатора pair не в области /* видимости */struct pair p2; /* OK */int pair = 7; /* OK: дескриптора структуры pair нет в области /* видимости */struct pair p3; /* OK: дескриптор структуры pair не маскируется /* типом int*/pair = 8; /* OK: идентификатор pair ссылается на число типа /* int */Довольно интересно, что, применив обходной маневр, этот прием можно заставить работать и в языке С++. Присваивание переменным (и функциям) тех же имен, что и структурам, — весьма распространенный трюк, используемый в программах на языке С, хотя мы его не рекомендуем.
Если вы не хотите писать ключевое слово
structtypedeftypedef struct { int x,y; } pair;pair p1 = { 1, 2 };В общем, оператор
typedef В языке C имена вложенных структур находятся в том же самом пространстве имен, что и имя структуры, в которую они вложены. Рассмотрим пример.
struct S { struct T { /* ... */ }; / * ... */};struct T x; /* OK в языке C (но не в C++) */В программе на языке C++ этот фрагмент следовало бы написать так:
S::T x; // OK в языке C++ (но не в C)При малейшей возможности не используйте вложенные структуры в программах на языке C: их правила разрешения области видимости отличаются от наивных (и вполне разумных) предположений большинства людей.
27.3.2. Ключевые слова
Многие ключевые слова в языке C++ не являются ключевыми словами в языке С (поскольку язык С не обеспечивает соответствующие функциональные возможности) и поэтому могут использоваться как идентификаторы в программах на языке C.

Не используйте эти имена как идентификаторы в программах на языке C, иначе ваш код станет несовместимым с языком C++. Если вы используете одно из этих имен в заголовочном файле, то не сможете использовать его в программе на языке C++.
Некоторые ключевые слова в языке C++ являются макросами в языке C.

В языке C они определены в заголовочных файлах
booltruefalse27.3.3. Определения
Язык C++ допускает определения в большем количестве мест программы по сравнению с языком C. Рассмотрим пример.
for (int i = 0; i // недопустимое в языке Cwhile (struct S* p = next(q)) { // определение указателя p, // недопустимое в языке C /* ... */}void f(int i){ if (i< 0 || max<=i) error("Ошибка диапазона"); int a[max]; // ошибка: объявление после инструкции // в языке С не разрешено /* ... */}Язык C (C89) не допускает объявлений в разделе инициализации счетчика цикла
forint i;for (i = 0; istruct S* p;while (p = next(q)) { /* ... */}void f(int i){ if (i< 0 || max<=i) error("Ошибка диапазона"); { int a[max]; /* ... */ }}В языке С++ неинициализированное объявление считается определением; в языке С оно считается простым объявлением, поэтому его можно дублировать.
int x;int x; /* определяет или объявляет одну целочисленную переменную с именем x в программе на языке C; ошибка в языке C++ */ В языке С++ сущность должна быть определена только один раз. Ситуация становится интереснее, если эти две переменные типа
int/* в файле x.c: */int x;/* в файле y.c: */int x;Ни компилятор языка С, ни компилятор языка С++ не найдет никаких ошибок в файлах
x.cy.cx.cy.cx.cy.cxx.cy.cx/* в файле x.c: */int x = 0; /* определение *//* в файле y.c: */extern int x; /* объявление, но не определение */Впрочем, лучше используйте заголовочный файл.
/* в файле x.h: */extern int x; /* объявление, но не определение *//* в файле x.c: */#include "x.h"int x = 0; /* определение *//* в файле y.c: */#include "x.h"/* объявление переменной x находится в заголовочном файле */А еще лучше: избегайте глобальных переменных.
27.3.4. Приведение типов в стиле языка С
В языке C (и в языке C++) можете явно привести переменную
vT(T)v Это так называемое “приведение в стиле языка С”, или “приведение в старом стиле”. Его любят люди, не умеющие набирать тексты (за лаконичность) и ленивые (потому что они не обязаны знать, что нужно для того, чтобы из переменной
vTint* p = (int*)7; /* интерпретирует битовую комбинацию: reinterpret_cast(7) */ int x = (int)7.5; /* усекает переменную типа: static_cast(7.5) */ typedef struct S1 { /* ... */ } S1;typedef struct S2 { /* ... */ } S2;S1 a;const S2 b; /* в языке С допускаются неинициализированные /* константы */S1* p = (S2*)&a; /* интерпретирует битовую комбинацию: reinterpret_cast(&a) */ S2* q = (S2*)&b; /* отбрасывает спецификатор const: const_cast(&b) */ S1* r = (S1*)&b; /* удаляет спецификатор const и изменяет тип; похоже на ошибку */Мы не рекомендуем использовать макросы даже в программах на языке C (раздел 27.8), но, возможно, описанные выше идеи можно было бы выразить следующим образом:
#define REINTERPRET_CAST(T,v) ((T)(v))#define CONST_CAST(T,v) ((T)(v))S1* p = REINTERPRET_CAST (S1*,&a);S2* q = CONST_CAST(S2*,&b);Это не обеспечит проверку типов при выполнении операторов
reinterpret_castconst_cast27.3.5. Преобразование указателей типа void*
В языке указатель типа
void*void* alloc(size_t x); /* выделяет x байтов */void f (int n){ int* p = alloc(n*sizeof(int)); /* OK в языке C; ошибка в языке C++ */ /* ... */}Здесь указатель типа
void*alloc()int*int* p = (int*)alloc(n*sizeof(int)); /* OK и в языке C, и в языке C++ */Мы использовали приведение в стиле языка C (раздел 27.3.4), чтобы оно оказалось допустимым как в программах на языке C, так и в программах на языке C++.
Почему неявное преобразование
void*T*void f(){ char i = 0; char j = 0; char* p = &i; void* q = p; int* pp = q; /* небезопасно; разрешено в языке C, ошибка в языке C++ */ *pp = –1; /* перезаписываем память, начиная с адреса &i */В данном случае мы даже не уверены, какой фрагмент памяти будет перезаписан: переменная
jpf()ff()Обратите внимание на то, что (обратное) преобразование указателя типа
T*void*К сожалению, неявное преобразование
void*T*27.3.6. Перечисление
В языке C можно присваивать целое число перечислению без приведения
intenumenum color { red, blue, green };int x = green; /* OK в языках C и C++ */enum color col = 7; /* OK в языке C; ошибка в языке C++ */Одним из следствий этого факта является то, что в программах на языке С мы можем применять операции инкрементации (
++––enum color x = blue;++x; /* переменная x становится равной значению green; ошибка в языке C++ */++x; /* переменная x становится равной 3; ошибка в языке C++ */Выход за пределы перечисления может входить в наши планы, а может быть неожиданным.
Обратите внимание на то, что, подобно дескрипторам структур, имена перечислений пребывают в своем собственном пространстве имен, поэтому каждый раз при указании имени перечисления перед ним следует ставить ключевое слово
enumcolor c2 = blue; /* ошибка в языке C: переменная color не находится в пределах области видимости; OK в языке C++ */enum color c3 = red; /* OK */27.3.7. Пространства имен
В языке С нет пространств имен (в том смысле, как это принято в языке С++). Так что же можно сделать, чтобы избежать коллизий имен в больших программах, написанных на языке С? Как правило, для этого используются префиксы и суффиксы. Рассмотрим пример.
/* в bs.h: */typedef struct bs_string { /* ... */ } bs_string; /* строка Бьярне */typedef int bs_bool; /* булев тип Бьярне *//* in pete.h: */typedef char* pete_string; /* строка Пита */typedef char pete_bool; /* булев тип Пита */Этот прием настолько широко используется, что использовать одно- и двухбуквенные префиксы обычно уже недостаточно.
27.4. Свободная память
В языке С нет операторов
newdeletevoid* malloc(size_t sz); /* выделить sz байтов */void free(void* p); /* освободить область памяти, на которую ссылается указатель p */void* calloc(size_t n, size_t sz); /* выделить n*sz байтов, инициализировав их нулями */void* realloc(void* p, size_t sz); /* вновь выделить sz байтов в памяти, на которую ссылается указатель p*/Тип
typedef size_t Почему функция
malloc()void*struct Pair { const char* p; int val;};struct Pair p2 = {"apple",78};struct Pair* pp = (struct Pair*) malloc(sizeof(Pair)); /* выделить память */pp–>p = "pear"; /* инициализировать */pp–>val = 42;Теперь мы не можем написать инструкцию
*pp = {"pear", 42}; /* ошибка: не C и не C++98 */ни в программе на языке C, ни в программе на языке C++. Однако в языке С++ мы могли бы определить конструктор для структуры
PairPair* pp = new Pair("pear", 42)В языке C (но не в языке C++; см. раздел 27.3.4) перед вызовом функции malloc() можно не указывать приведение типа, но мы не рекомендуем это делать.
int* p = malloc(sizeof(int)*n); /* избегайте этого */Игнорирование приведения довольно часто встречается в программах, потому что это экономит время и позволяет выявить редкую ошибку, когда программист забывает включить в текст программы заголовочный файл
malloc()p = malloc(sizeof(char)*m); /* вероятно, ошибка — нет места для m целых */ Не используйте функции
malloc()/free()new/deletemalloc()deletefree()int* p = new int[200];// ...free(p); // ошибкаX* q = (X*)malloc(n*sizeof(X));// ...delete q; // errorЭтот код может оказаться вполне работоспособным, но он не является переносимым. Более того, для объектов, имеющих конструкторы и деструкторы, смешение стилей языков C и C++ при управлении свободной памятью может привести к катастрофе. Для расширения буферов обычно используется функция
realloc()int max = 1000;int count = 0;int c;char* p = (char*)malloc(max);while ((c=getchar())!=EOF) { /* чтение: игнорируются символы в конце файла */ if (count==max–1) { /* необходимо расширить буфер */ max += max; /* удвоить размер буфера */ p = (char*)realloc(p,max); if (p==0) quit(); } p[count++] = c;}Объяснения операторов ввода в языке С приведены в разделах 27.6.2 и Б.10.2.
Функция
realloc()realloc()newИспользуя стандартную библиотеку языка C++, этот код можно переписать примерно так:
vector buf; char c;while (cin.get(c)) buf.push_back(c);Более подробное обсуждение стратегий ввода и распределения памяти можно найти в статье “Learning Standard C++ as a New Language” (см. список библиографических ссылок в конце раздела 27.1).
27.5. Строки в стиле языка С
Строка в языке C (в литературе, посвященной языку С++, ее часто называют С-строкой (C-string), или строкой в стиле языка С (C-style)) — это массив символов, завершающийся нулем. Рассмотрим пример.
char* p = "asdf";char s[ ] = "asdf";
В языке C нет функций-членов, невозможно перегружать функции и нельзя определить оператор (такой как
==size_t strlen(const char* s); /* определяет количество символов */char* strcat(char* s1, const char* s2); /* копирует s2 в конец s1 */int strcmp(const char* s1, const char* s2); /* лексикографическое сравнение */char* strcpy(char* s1,const char* s2); /* копирует s2 в s1 */char* strchr(const char *s, int c); /* копирует c в s */char* strstr(const char *s1, const char *s2); /* находит s2 в s1 */char* strncpy(char*, const char*, size_t n); /* сравнивает n символов */char* strncat(char*, const char, size_t n); /* strcat с n символами */int strncmp(const char*, const char*, size_t n); /* strcmp с n символами */Это не полный список функций для работы со строками, но он содержит самые полезные и широко используемые функции. Кратко проиллюстрируем их применение.
Мы можем сравнивать строки. Оператор проверки равенства (
==strcmp()const char* s1 = "asdf";const char* s2 = "asdf";if (s1==s2) { /* ссылаются ли указатели s1 и s2 на один и тот же массив? */ /* (обычно это нежелательно) */}if (strcmp(s1,s2)==0) { /* хранят ли строки s1 и s2 одни и те же символы? */}Функция
strcmp()s1s2strcmp(s1,s2)s1s2s1s2strcmp("dog","dog")==0strcmp("ape","dodo")<0 /* "ape" предшествует "dodo" в словаре */strcmp("pig","cow")>0 /* "pig" следует после "cow" в словаре */Результат сравнения указателей
s1==s2falsetruestrcmp()Длину С-строки можно найти с помощью функции
strlen()int lgt = strlen(s1);Обратите внимание на то, что функция
strlen()strlen(s1)==4asdfМы можем копировать одну С-строку (включая завершающий нуль) в другую.
strcpy(s1,s2); /* копируем символы из s2 в s1 */Программист должен сам гарантировать, что целевая строка (массив) имеет достаточный размер, чтобы в ней поместились символы исходной строки.
Функции
strncpy()strncat()strncmp()strcpy()strcat()strcmp()nnstrncpy()strchr()strstr()find()std::stringstring s = id + '@' + addr;С помощью стандартных функций для работы с С-строками этот код можно написать следующим образом:
char* cat(const char* id, const char* addr){ int sz = strlen(id)+strlen(addr)+2; char* res = (char*) malloc(sz); strcpy(res,id); res[strlen(id)+1] = '@'; strcpy(res+strlen(id)+2,addr); res[sz–1]=0; return res;}Правильный ли ответ мы получили? Кто вызовет функцию
free()cat()ПОПРОБУЙТЕ
Протестируйте функцию
cat()cat()27.5.1. Строки в стиле языка С и ключевое слово const
Рассмотрим следующий пример:
char* p = "asdf";p[2] = 'x'; В языке С так писать можно, а в языке С++ — нет. В языке C++ строковый литерал является константой, т.е. неизменяемой величиной, поэтому оператор p
[2]='x'pconst char* p = "asdf"; // теперь вы не сможете записать символ // в строку "asdf" с помощью указателя pЭта рекомендация относится как к языку C, так и к языку C++.
Функция
strchr()char* strchr(const char* s,int c); /* найти c в константной строке s (не C++) */const char aa[] = "asdf"; /* aa — массив констант */char* q = strchr(aa,'d'); /* находит символ 'd' */*q = 'x'; /* изменяет символ 'd' в строке aa на 'x' */ Опять-таки, этот код является недопустимым ни в языке С, ни в языке С++, но компиляторы языка C не могут найти ошибку. Иногда это явление называют трансмутацией (transmutation): функция превращает константы в не константы, нарушая разумные предположения о коде.
В языке C++ эта проблема решается с помощью немного измененного объявления стандартной библиотечной функции
strchr()char const* strchr(const char* s, int c); // найти символ c // в константной строке schar* strchr(char* s, int c); // найти символ c в строке sАналогично объявляется функция
strstr()27.5.2. Операции над байтами
В далеком средневековье (в начале 1980-х годов), еще до изобретения указателя
void*void*void*/* копирует n байтов из строки s2 в строку s1 (как функция strcpy): */void* memcpy(void* s1, const void* s2, size_t n);/* копирует n байтов из строки s2 в строку s1 (диапазон [s1:s1+n] может перекрываться с диапазоном [s2:s2+n]): */void* memmove(void* s1, const void* s2, size_t n);/* сравнивает n байтов из строки s2 в строку s1 (как функция strcmp): */int memcmp(const void* s1, const void* s2, size_t n);/* находит символ c (преобразованный в тип unsigned char) среди первых n байтов строки s: */void* memchr(const void* s, int c, size_t n);/* копирует символ c (преобразованный в тип unsigned char) в каждый из n байтов строки, на который ссылается указатель s: */void* memset(void* s, int c, size_t n);Не используйте эти функции в программах на языке C++. В частности, функция
memset()27.5.3. Пример: функция strcpy()
Определение функции
strcpy()char* strcpy(char* p, const char* q){ while (*p++ = *q++); return p;}Объяснение, почему этот код на самом деле копирует С-строку
qpПОПРОБУЙТЕ
Является ли корректной реализация функции
strcpy() Если вы не можете аргументировать свой ответ, то не вправе считать себя программистом, работающим на языке C (однако вы можете быть компетентным в других языках программирования). Каждый язык имеет свои собственные идиомы, это относится и к языку C.
27.5.4. Вопросы стиля
Мы потихоньку втягиваемся в длинные и часто яростно оспариваемые вопросы стиля, которые, впрочем, часто не имеют большого значения. Мы объявляем указатель следующим образом:
char* p; // p — указатель на переменную типа charМы не принимаем стиль, продемонстрированный ниже.
char *p; /* p — нечто, что можно разыменовать, чтобы получить символ */Пробел совершенно игнорируется компилятором, но для программиста он имеет значение. Наш стиль (общепринятый среди программистов на языке С++) подчеркивает тип объявляемой переменной, в то время как альтернативный стиль (общепринятый среди программистов на языке С) делает упор на использовании переменной. Мы не рекомендуем объявлять несколько переменных в одной строке.
char c, *p, a[177], *f(); /* разрешено, но может ввести в заблуждение */Такие объявления часто можно встретить в старых программах. Вместо этого объявления следует размещать в нескольких строках, используя свободное место для комментариев и инициализации.
char c = 'a'; /* символ завершения ввода для функции f() */char* p = 0; /* последний символ, считанный функцией f() */char a[177]; /* буфер ввода */char* f(); /* считывает данные в буфер a; возвращает указатель на первый считанный символ */Кроме того, выбирайте осмысленные имена.
27.6. Ввод-вывод: заголовок stdio
В языке С нет потоков ввода-вывода
iostreamcincoutstdinstdoutiostreamios_base::sync_with_stdio()27.6.1. Вывод
Наиболее популярной и полезной функцией библиотеки
stdioprintf()printf()#includevoid f(const char* p){ printf("Hello, World!\n"); printf(p);}Это не очень интересно. Намного интереснее то, что функция
printf()printf()int printf(const char* format, ...);Многоточие (
...printf()void f1(double d, char* s, int i, char ch){ printf("double %g string %s int %d char %c\n", d, s, i, ch);}где символы
%g%s%d%c%gd%ss%di%cchprintf() К сожалению, функция
printf()char a[] = { 'a', 'b' }; /* нет завершающего нуля */void f2(char* s, int i){ printf("goof %s\n", i); /* неперехваченная ошибка */ printf("goof %d: %s\n", i); /* неперехваченная ошибка */ printf("goof %s\n", a); /* неперехваченная ошибка */}Интересен эффект последнего вызова функции printf(): она выводит на экран каждый байт участка памяти, следующего за элементом a[1], пока не встретится нуль. Такой вывод может состоять из довольно большого количества символов.
Недостаток проверки типов является одной из причин, по которым мы предпочитаем потоки
iostreamstdiostdioprintf()iostream%Ystruct YСуществует полезная версия функции
printf()int fprintf(FILE* stream, const char* format, ...);Рассмотрим пример.
fprintf(stdout,"Hello, World!\n"); // идентично // printf("Hello,World!\n");FILE* ff = fopen("My_file","w"); // открывает файл My_file // для записиfprintf(ff,"Hello, World!\n"); // запись "Hello,World!\n" // в файл My_fileДескрипторы файлов описаны в разделе 27.6.3.
27.6.2. Ввод
Ниже перечислены наиболее популярные функции из библиотеки
stdioint scanf(const char* format, ...); /* форматный ввод из потока stdin */int getchar(void); /* ввод символа из потока stdin */int getc(FILE* stream); /* ввод символа из потока stream*/char* gets(char* s); /* ввод символов из потока stdin */Простейший способ считывания строки символов — использовать функцию
gets()char a[12];gets(a); /* ввод данных в массив символов a вплоть до символа '\n' */ Никогда не делайте этого! Считайте, что функция
gets()scanf("%s")gets()gets()Функция
scanf()printf()printf()void f(){ int i; char c; double d; char* s = (char*)malloc(100); /* считываем данные в переменные, передаваемые как указатели: */ scanf("%i %c %g %s", &i, &c, &d, s); /* спецификатор %s пропускает первый пробел и прекращает действие на следующем пробеле */} Как и функция
printf()scanf()s%sgets()scanf("%s") Итак, как же безопасно ввести символы? Мы можем использовать вид формата %s, устанавливающий предел количества считываемых символов. Рассмотрим пример.
char buf[20];scanf("%19s",buf);Нам требуется участок памяти, заканчивающийся нулем (содержание которого вводится функцией
scanf()bufПроблема с функцией
scanf()getchar()getchar()while((x=getchar())!=EOF) { /* ... */}Макрос
EOFstdioАльтернативы функций
scanf("%s")gets()string s;cin >> s; // считываем словоgetline(cin,s); // считываем строку27.6.3. Файлы
В языке C (и C++) файлы можно открыть с помощью функции
fopen()fclose()FILEEOFFILE *fopen(const char* filename, const char* mode);int fclose(FILE *stream);По существу, мы используем файлы примерно так:
void f(const char* fn, const char* fn2){ FILE* fi = fopen(fn, "r"); /* открываем файл fn для чтения */ FILE* fo = fopen(fn2, "w"); /* открываем файл fn для записи */ if (fi == 0) error("невозможно открыть файл для ввода"); if (fo == 0) error("невозможно открыть файл для вывода"); /* чтение из файла с помощью функций ввода из библиотеки stdio, например, getc() */ /* запись в файл с помощью функций вывода из библиотеки stdio, например, fprintf() */ fclose(fo); fclose(fi);}Учтите: в языке С нет исключений, потому вы не можете узнать, что при обнаружении ошибок файлы были закрыты.
27.7. Константы и макросы
В языке С константы не являются статическими.
const int max = 30;const int x; /* неинициализированная константа: OK в C (ошибка в C++) */void f(int v){ int a1[max]; /* ошибка: граница массива не является константой (OK в языке C++) */ /* (слово max не допускается в константном выражении!) */ int a2[x]; /* ошибка: граница массива не является константой */ switch (v) { case 1: /* ... */ break; case max: /* ошибка: метка раздела case не является константой (OK в языке C++) */ /* ... */ break; }}По техническим причинам в языке С (но не в языке C++) неявно допускается, чтобы константы появлялись из других модулей компиляции.
/* файл x.c: */const int x; /* инициализирована в другом месте *//* файл xx.c: */const int x = 7; /* настоящее определение */В языке С++ в разных файлах могут существовать два разных объекта с одним и тем же именем
xconst#define MAX 30void f(int v){ int a1[MAX]; /* OK */ switch (v) { case 1: /* ... */ break; case MAX: /* OK */ /* ... */ break; }} Имя макроса
MAX30a13030MAX27.8. Макросы
Берегитесь макросов: в языке С нет по-настоящему эффективных способов избежать макросов, но их использование имеет серьезные побочные эффекты, поскольку они не подчиняются обычным правилам разрешения области видимости и типов, принятым в языках С и С++. Макросы — это вид текстуальной подстановки. См. также раздел А.17.2.
Как защититься от потенциальных проблем, связанных с макросами, не отказываясь от них навсегда (и не прибегая к альтернативам, предусмотренным в языке С++?
• Присваивайте всем макросам имена, состоящие только из прописных букв:
ALL_CAPS• Не присваивайте имена, состоящие только из прописных букв, объектам, которые не являются макросами.
• Никогда не давайте макросам короткие или “изящные” имена, такие как
maxmin• Надейтесь, что остальные программисты следуют этим простым и общеизвестным правилам.
В основном макросы применяются в следующих случаях:
• определение “констант”;
• определение конструкций, напоминающих функции;
• улучшение синтаксиса;
• управление условной компиляцией.
Кроме того, существует большое количество менее известных ситуаций, в которых могут использоваться макросы.
Мы считаем, что макросы используются слишком часто, но в программах на языке С у них нет разумных и полноценных альтернатив. Их даже трудно избежать в программах на языке С++ (особенно, если вам необходимо написать программу, которая должна подходить для очень старых компиляторов или выполняться на платформах с необычными ограничениями).
Мы приносим извинения читателям, считающим, что приемы, которые будут описаны ниже, являются “грязными трюками”, и полагают, что о них лучше не говорить в приличном обществе. Однако мы думаем, что программирование должно учитывать реалии и что эти (очень простые) примеры использования и неправильного использования макросов сэкономят часы страданий для новичков. Незнание макросов не приносит счастья.
27.8.1. Макросы, похожие на функции
Рассмотрим типичный макрос, напоминающий функцию.
#define MAX(x, y) ((x)>=(y)?(x):(y))Мы используем прописные буквы в имени
MAXmaxreturnint aa = MAX(1,2);double dd = MAX(aa++,2);char cc = MAX(dd,aa)+2;Он разворачивается в такой фрагмент программы:
int aa = ((1)>=( 2)?(1):(2));double dd = ((aa++)>=(2)?( aa++):(2));char cc = ((dd)>=(aa)?(dd):(aa))+2;Если бы всех этих скобок не было, то последняя строка выглядела бы следующим образом.
char cc = dd>=aa?dd:aa+2;Иначе говоря, переменная
cc С другой стороны, не всегда скобки могут спасти нас от второго варианта развертывания. Параметру макроса x было присвоено значение
aa++MAXКакой-то “гений” определил макрос следующим образом и поместил его в широко используемый заголовочный файл. К сожалению, он также назвал его
maxMAXtemplate inline T max(T a, T b) { return a имя
maxT aT btemplate inline T ((T a)>=(T b)?(T a):(T b)) { return aСообщения об ошибке, выдаваемые компилятором, интересны, но не слишком информативны. В случае опасности можете отменить определение макроса.
#undef maxК счастью, этот макрос не привел к большим неприятностям. Тем не менее в широко используемых заголовочных файлах существуют десятки тысяч макросов; вы не можете отменить их все, не вызвав хаоса.
Не все параметры макросов используются как выражения. Рассмотрим следующий пример:
#define ALLOC(T,n) ((T*)malloc(sizeof(T)*n))Это реальный пример, который может оказаться очень полезным для предотвращения ошибок, возникающих из-за согласованности между желательным типом выделяемой памяти и использованием оператора
sizeofdouble* p = malloc(sizeof(int)*10); /* похоже на ошибку */К сожалению, написать макрос, который позволял бы выявить исчерпание памяти, — нетривиальная задача. Это можно было бы сделать, если бы мы в каком-то месте программы соответствующим образом определили переменную
error_varerror()#define ALLOC(T,n) (error_var = (T*)malloc(sizeof(T)*n), \ (error_var==0)\ ?(error("Отказ выделения памяти"),0)\ :error_var)Строки, завершающиеся символом
\new27.8.2. Синтаксис макросов
Можно определить макрос, который приводит текст исходного кода в приятный для вас вид. Рассмотрим пример.
#define forever for(;;)#define CASE break; case#define begin {#define end } Мы резко протестуем против этого. Многие люди пытались делать такие вещи. Они (и люди, которым пришлось поддерживать такие программы) пришли к следующим выводам.
• Многие люди не разделяют ваших взглядов на то, что считать лучшим синтаксисом.
• Улучшенный синтаксис является нестандартным и неожиданным; остальные люди будут сбиты с толку.
• Использование улучшенного синтаксиса может вызвать непонятные ошибки компиляции.
• Текст программы, который вы видите перед собой, не совпадает с текстом, который видит компилятор, и компилятор сообщает об ошибках, используя свой словарный запас, а не ваш.
Не пишите синтаксические макросы, для того чтобы улучшить внешний вид вашего кода. Вы и ваши лучшие друзья могут считать его превосходным, но опыт показывает, что вы окажетесь в крошечном меньшинстве среди более крупного сообщества программистов, поэтому кому-то придется переписать ваш код (если он сможет просуществовать до этого момента).
27.8.3. Условная компиляция
Представьте себе, что у вас есть два варианта заголовочного файла, например, один — для операционной системы Linux, а другой — для операционной системы Windows. Как выбрать правильный вариант в вашей программе? Вот как выглядит общепринятое решение этой задачи:
#ifdef WINDOWS #include "my_windows_header.h"#else #include "my_linux_header.h"#endifТеперь, если кто-нибудь уже определил
WINDOWS#include "my_windows_header.h"В противном случае будет включен другой заголовочный файл.
#include "my_linux_header.h"Директива
#ifdef WINDOWSWINDOWSВ большинстве крупных систем (включая все версии операционных систем) существуют макросы, поэтому вы можете их проверить. Например, можете проверить, как компилируется ваша программа: как программа на языке C++ или программа на языке C.
#ifdef __cplusplus // в языке C++#else /* в языке C */#endifАналогичная конструкция, которую часто называют стражем включения (include guard), обычно используется для предотвращения повторного включения заголовочного файла.
/* my_windows_header.h: */#ifndef MY_WINDOWS_HEADER#define MY_WINDOWS_HEADER /* информация о заголовочном файле */#endifДиректива
#ifndef#ifndef#ifdef27.9. Пример: интрузивные контейнеры
Контейнеры из стандартной библиотеки языка С++, такие как
vectormapОпределим двухсвязный список с девятью операциями.
void init(struct List* lst); /* инициализирует lst пустым */struct List* create(); /* создает новый пустой список в свободной памяти */void clear(struct List* lst); /* удаляет все элементы списка lst */void destroy(struct List* lst); /* удаляет все элементы списка lst, а затем удаляет сам lst */void push_back(struct List* lst, struct Link* p); /* добавляет элемент p в конец списка lst */void push_front(struct List*, struct Link* p); /* добавляет элемент p в начало списка lst *//* вставляет элемент q перед элементом p in lst: */void insert(struct List* lst, struct Link* p, struct Link* q);struct Link* erase(struct List* lst, struct Link* p); /* удаляет элемент p из списка lst *//* возвращает элемент, находящийся за n до или через n узлов после узла p:*/struct Link* advance(struct Link* p, int n);Мы хотим определить эти операции так, чтобы их пользователям было достаточно использовать только указатели
List*Link*ListLinkstruct List { struct Link* first; struct Link* last;};struct Link { /* узел двухсвязного списка */ struct Link* pre; struct Link* suc;};Приведем графическое представление контейнера
List
В наши намерения на входит демонстрация изощренных методов или алгоритмов, поэтому ни один из них на рисунке не показан. Тем не менее обратите внимание на то, что мы не упоминаем о данных, которые хранятся в узлах (элементах списков). Оглядываясь на функции-члены этой структуры, мы видим, что сделали нечто подобное, определяя пару абстрактных классов
LinkListLink*List*Link*List*ListLinkListДля реализации функций структуры
List#include#include#includeВ языке C нет пространств имен, поэтому можно не беспокоиться о декларациях или директивах
usingLinkinsertinitИнициализация тривиальна, но обратите внимание на использование функции
assert()void init(struct List* lst) /* инициализируем *lst пустым списком */{ assert(lst); lst–>first = lst–>last = 0;}Мы решили не связываться с обработкой ошибок, связанных с некорректными указателями на списки, во время выполнения программы. Используя макрос
assert()assert()assert()Функция
create()Listinit()newmalloc()struct List* create() /* создает пустой список */{ struct List* lst = (struct List*)malloc(sizeof(struct List)); init(lst); return lst;}Функция
clear()free()void clear(struct List* lst) /* удаляет все элементы списка lst */{ assert(lst); { struct Link* curr = lst–>first; while(curr) { struct Link* next = curr–>suc; free(curr); curr = next; } lst–>first = lst–>last = 0; }}Обратите внимание на способ, с помощью которого мы обходим список, используя член
sucLinkfree()nextListLinkfree()Если не все объекты структуры
Linkclear()Функция
destroy()create()deletevoid destroy(struct List* lst) /* удаляет все элементы списка lst; затем удаляет сам список lst */{ assert(lst); clear(lst); free(lst);}Обратите внимание на то, что перед вызовом функции очистки памяти (деструктора) мы не делаем никаких предположений об элементах, представленных в виде узлов списка. Эта схема не является полноценной имитацией методов языка С++ — она для этого не предназначена.
Функция
push_back()Linkvoid push_back(struct List* lst, struct Link* p) /* добавляет элемент p в конец списка lst */{ assert(lst); { struct Link* last = lst–>last; if (last) { last–>suc = p; /* добавляет узел p после узла last */ p–>pre = last; } else { lst–>first = p; /* p — первый элемент */ p–>pre = 0; } lst–>last = p; /* p — новый последний элемент */ p–>suc = 0; }}Весь этот код было бы трудно написать, не нарисовав схему, состоящую из нескольких прямоугольников и стрелок. Обратите внимание на то, что мы забыли рассмотреть вариант, в котором аргумент
pФункцию
erase()struct Link* erase(struct List* lst, struct Link* p)/* удаляет узел p из списка lst; возвращает указатель на узел, расположенный после узла p*/{ assert(lst); if (p==0) return 0; /* OK для вызова erase(0) */ if (p == lst–>first) { if (p–>suc) { lst–>first = p–>suc; /* последователь становится первым */ p–>suc–>pre = 0; return p–>suc; } else { lst–>first = lst–>last = 0; /* список становится пустым */ return 0; } } else if (p == lst–>last) { if (p–>pre) { lst–>last = p–>pre; /* предшественник становится последним */ p–>pre–>suc = 0; } else { lst–>first = lst–>last = 0; /* список становится пустым */ return 0; } } else { p–>suc–>pre = p–>pre; p–>pre–>suc = p–>suc; return p–>suc; }}Остальные функции читатели могут написать в качестве упражнения, поскольку для нашего (очень простого) теста они не нужны. Однако теперь мы должны разрешить основную загадку этого проекта: где находятся данные в элементах списка? Как реализовать простой список имен, представленных в виде С-строк. Рассмотрим следующий пример:
struct Name { struct Link lnk; /* структура Link нужна для выполнения ее операций */ char* p; /* строка имен */};До сих пор все было хорошо, хотя остается загадкой, как мы можем использовать этот член
LinkListLinkNamestruct Name* make_name(char* n){ struct Name* p = (struct Name*)malloc(sizeof(struct Name)); p–>p = n; return p;}Эту ситуацию можно проиллюстрировать следующим образом:

Попробуем использовать эти структуры.
int main(){ int count = 0; struct List names; /* создает список */ struct List* curr; init(&names); /* создаем несколько объектов Names и добавляем их в список: */ push_back(&names,(struct Link*)make_name("Norah")); push_back(&names,(struct Link*)make_name("Annemarie")); push_back(&names,(struct Link*)make_name("Kris")); /* удаляем второе имя (с индексом 1): */ erase(&names,advance(names.first,1)); curr = names.first; /* выписываем все имена */ for (; curr!=0; curr=curr–>suc) { count++; printf("element %d: %s\n", count, ((struct Name*)curr)–>p); }}Итак, мы смошенничали. Мы использовали приведение типа, чтобы работать с указателем типа
Name*Link*LinkNameОчевидно, что этот пример можно также скомпилировать с помощью компилятора языка С++.
ПОПРОБУЙТЕ
Программисты, работающие на языке C++, разговаривая с программистами, работающими на языке C, рефреном повторяют: “Все, что делаешь ты, я могу сделать лучше!” Итак, перепишите пример интрузивного контейнера
ListЗадание
1. Напишите программу “Hello World!” на языке C, скомпилируйте ее и выполните.
2. Определите две переменные, хранящие строки “Hello” и “World!” соответственно; конкатенируйте их с пробелом между ними и выведите в виде строки
Hello World!3. Определите функцию на языке C, получающую параметр
pchar*xintp is "foo" and x is 7Контрольные вопросы
В следующих вопросах предполагается выполнение стандарта ISO C89.
1. Является ли язык C++ подмножеством языка C?
2. Кто изобрел язык C?
3. Назовите высокоавторитетный учебник по языку С.
4. В какой организации были изобретены языки C и C++?
5. Почему язык С++ (почти) совместим с языком C?
6. Почему язык C++ только почти совместим с языком C?
7. Перечислите десять особенностей языка C++, отсутствующих в языке C.
8. Какой организации “принадлежат” языки C и C++?
9. Перечислите шесть компонентов стандартной библиотеки языка C++, которые не используются в языке C.
10. Какие компоненты стандартной библиотеки языка C можно использовать в языке C++?
11. Как обеспечить проверку типов аргументов функций в языке C?
12. Какие свойства языка C++, связанные с функциями, отсутствуют в языке C? Назовите по крайней мере три из них. Приведите примеры.
13. Как вызвать функцию, написанную на языке C, в программе, написанной на языке C++?
14. Как вызвать функцию, написанную на языке C++, в программе, написанной на языке C?
15. Какие типы совместимы в языках C и C++? Приведите примеры.
16. Что такое дескриптор структуры?
17. Перечислите двадцать ключевых слов языка C++, которые не являются ключевыми словами языка C.
18. Является ли инструкция
int x19. В чем заключается приведение в стиле языка С и чем оно опасно?
20. Что собой представляет тип
void*21. Чем отличаются перечисления в языках C и C++?
22. Что надо сделать в программе на языке C, чтобы избежать проблем, связанных с совпадением широко распространенных имен?
23. Назовите три наиболее широко используемые функции для работы со свободной памятью в языке C.
24. Как выглядит определение в стиле языка С?
25. Чем отличаются оператор
==strcmp()26. Как скопировать С-строки?
27. Как определить длину С-строки?
28. Как скопировать большой массив целых чисел типа
int29. Назовите преимущества и недостатки функции
printf()30. Почему никогда не следует использовать функцию
gets()31. Как открыть файл для чтения в программе на языке C?
32. В чем заключается разница между константами (
const33. Почему мы не любим макросы?
34. Как обычно используются макросы?
35. Что такое “страж включения”?
Термины

Упражнения
Для этих упражнений может оказаться полезным скомпилировать все программы с помощью компиляторов и языка C, и языка C++. Если использовать только компилятор языка C++, можно случайно использовать свойства, которых нет в языке C. Если вы используете только компилятор языка C, то ошибки, связанные с типами, могут остаться незамеченными
1. Реализуйте варианты функций
strlen()strcmp()strcpy()2. Завершите пример с интрузивным контейнером
List3. Усовершенствуйте пример с интрузивным контейнером List из раздела 27.9 по своему усмотрению. Предусмотрите перехват и обработку как можно большего количества ошибок. При этом можно изменять детали определений структур, использовать макросы и т.д.
4. Если вы еще на переписали пример с интрузивным контейнером
List5. Сравните результаты упр. 3 и 4.
6. Измените представление структур
LinkListfirstlastpresucint7. Назовите преимущества и недостатки интрузивных контейнеров по сравнению с неинтрузивными контейнерами из стандартной библиотеки языка С++. Составьте списки аргументов за и против этих контейнеров.
8. Какой лексикографический порядок принят на вашем компьютере? Выведите на печать каждый символ вашей клавиатуры и ее целочисленный код; затем выведите на печать символы в порядке, определенном их целочисленными кодами.
9. Используя только средства языка C, включая его стандартную библиотеку, прочитайте последовательность слов из потока
stdinstdoutqsort()10. Составьте список свойств языка C, заимствованных у языков C++ или C with Classes (раздел 27.1).
11. Составьте список свойств языка C, не заимствованных у языка C++.
12. Реализуйте (либо с помощью С-строк, либо с помощью типа
intfind(struct table*, const char*)insert(struct table*, const char*, int)remove(struct table*, const char*)const char*[]int*13. Напишите программу на языке С, которая является эквивалентом инструкций
string scin>>s14. Напишите функцию, получающую на вход массив целых чисел типа
int15. Сымитируйте одиночное наследование в языке C. Пусть каждый базовый класс содержит указатель на массив указателей на функции (для моделирования виртуальных функций как самостоятельных функций, получающих указатель на объект базового класса в качестве своего первого аргумента); см. раздел 27.2.3. Реализуйте вывод производного класса, сделав базовый класс типом первого члена производного класса. Для каждого класса соответствующим образом инициализируйте массив виртуальных функций. Для проверки реализуйте вариант старого примера с классом
Shapedraw()16. Для запутывания реализации предыдущего примера (за счет упрощения обозначений) используйте макросы.
Послесловие
Мы уже упоминали выше, что не все вопросы совместимости решены наилучшим образом. Тем не менее существует много программ на языке С (миллиарды строк), написанных кем-то, где-то и когда-то. Если вам придется читать и писать такие программы, эта глава подготовит вас к этому. Лично мы предпочитаем язык C++ и в этой главе частично объяснили почему. Пожалуйста, не недооценивайте пример интрузивного списка
ListListКанал с обзорами, анонсами новинок и книжными подборками
 Книжный Вестник
Книжный Вестник
Бот для удобного поиска книг (если не нашлось на сайте)
 Поиск книг
Поиск книг
Свежие любовные романы в удобных форматах
 Любовные романы
Любовные романы
О психологии, саморазвитии и личностном росте
 Саморазвитие
Саморазвитие
Детективы и триллеры, все новинки
 Детективы
Детективы
Фантастика и фэнтези, все новинки
 Фантастика
Фантастика
Отборные классические книги
 Классика
Классика
 ВКОНТАКТЕ
ВКОНТАКТЕБиблиотека с любовными романами, которая наверняка придётся по вкусу женской части аудитории
Любовные романы
Библиотека с фантастикой и фэнтези, а также смежных жанров
Фантастика
Самые популярные книги в формате фб2
Топ фб2
книги