7. Конфигурация системы: журнал, системное время, пакетные задания и пользователи
Когда вы в первый раз заглянете в каталог /etc, вы испытаете потрясение. Практически все файлы в определенной степени влияют на работу системы, а часть из них являются фундаментальными.
Основной материал этой главы охватывает те части системы, которые делают доступной инфраструктуру, описанную в главе 4, для инструментов уровня пользователя, рассмотренных в главе 2. В частности, мы будем исследовать следующее:
• конфигурационные файлы, к которым обращаются системные библиотеки для получения информации о сервере и пользователе;
• серверные приложения (иногда называемые демонами), запускающиеся при загрузке системы;
• конфигурационные утилиты, которые можно использовать для изменения настроек серверных приложений и файлов конфигурации;
• утилиты администрирования.
Как и в предыдущих главах, здесь практически нет материала о сети, поскольку сеть является отдельным «строительным блоком» системы. В главе 9 вы увидите, куда встраивается сеть.
7.1. Структура каталога /etc
Большинство файлов конфигурации Linux располагается в каталоге /etc. Исторически сложилось так, что для каждого приложения здесь один или несколько файлов конфигурации, а поскольку пакетов программ в системе Unix довольно много, каталог /etc быстро наполняется файлами.
Такой подход сталкивается с двумя проблемами: в работающей системе сложно найти конкретные файлы конфигурации и выполнять обслуживание системы, сконфигурированной подобным образом. Если, например, вы желаете изменить конфигурацию системного журнала, необходимо отредактировать файл /etc/syslog.conf. Однако после этого, когда произойдет обновление системы, ваши пользовательские настройки могут быть утрачены.
Основной тенденцией последних лет является размещение файлов системной конфигурации в подкаталогах каталога /etc, как вы уже видели на примере каталогов загрузки системы (/etc/init для варианта Upstart и /etc/systemd для systemd). В каталоге /etc по-прежнему есть несколько отдельных файлов конфигурации, но если вы запустите команду ls — F /etc, вы увидите, что эти элементы теперь в основном являются подкаталогами.
Чтобы справиться с проблемой перезаписывания файлов конфигурации, можно поместить пользовательские настройки в отдельных файлах внутри подкаталогов конфигурации вроде тех, которые присутствуют в каталоге /etc/grub.d.
Какие типы файлов конфигурации можно обнаружить в каталоге /etc? Основной принцип такой: настраиваемая конфигурация для одного компьютера, например информация о пользователе (/etc/passwd) и параметры сети (/etc/network), попадает в каталог /etc. Однако общие параметры приложений, например установки по умолчанию для пользовательского интерфейса, не располагаются в каталоге /etc. Зачастую файлы системной конфигурации, которые не подлежат настройке, находятся где-либо в другом месте, как это сделано для подготовленных файлов модулей systemd в каталоге /usr/lib/systemd.
Вы уже видели некоторые файлы конфигурации, которые имеют отношение к загрузке системы. Сейчас мы рассмотрим типичную системную службу и способы просмотра и настройки ее конфигурации.
7.2. Системный журнал
Большинство системных приложений передает свой диагностический вывод в службу syslog. Традиционный демон syslogd ожидает сообщения и в зависимости от типа полученного сообщения направляет вывод в файл, на экран, пользователям или в виде какой-либо комбинации перечисленного, но может и игнорировать сообщение.
7.2.1. Системный регистратор
Системный регистратор является одной из важнейших частей системы. Когда что-либо происходит не так и вы не знаете, с чего начать, загляните сначала в файлы системного журнала. Вот пример сообщения из него:
Aug 19 17:59:48 duplex sshd[484]: Server listening on 0.0.0.0 port 22.
В большинстве версий Linux используется новая версия службы syslogd под названием rsyslogd, которая выполняет намного больше, чем простая запись сообщений в файлы. Например, можно использовать ее для загрузки модуля, чтобы отправлять сообщения журнала в базу данных. Однако, приступая к изучению системных журналов, проще всего начать с файлов журналов, обычно хранящихся в каталоге /var/log. Просмотрите несколько таких файлов — когда вы будете знать, как они выглядят, вы будете готовы выяснить, как они здесь появились.
Многие из файлов в каталоге /var/log обслуживаются не с помощью системного регистратора. Единственный способ точно установить, какие из них принадлежат службе rsyslogd, — посмотреть ее файл конфигурации.
7.2.2. Файлы конфигурации
Основным файлом конфигурации службы rsyslogd является /etc/rsyslog.conf, но некоторые настройки вы обнаружите также в других каталогах, например /etc/rsyslog.d. Формат конфигурации представляет собой смесь обычных правил и специфичных для службы rsyslog расширений. Один из признаков такой: если что-либо начинается с символа доллара ($), то это расширение.
Традиционное правило состоит из селектора и действия, которые описывают, как перехватывать сообщения журнала и куда их направлять (пример 7.1).
Пример 7.1. Правила службы syslog
kern.* /dev/console
*.info;authpriv.none /var/log/messages
/var/log/messages
authpriv.* /var/log/secure,root
mail.* /var/log/maillog
cron.* /var/log/cron
*.emerg *
local7.* /var/log/boot.log
Селектор располагается слева. Это тип информации, которая должна быть занесена в журнал. Список в правой части содержит действия: куда отправлять журнал. Большинство действий из примера 7.1 — обычные файлы, но есть некоторые исключения. Так, например, действие /dev/console ссылается на специальное устройство для системной консоли, действие root означает отправку сообщения пользователю superuser, если он подключен, а действие * означает отправку сообщения всем пользователям, находящимся сейчас в системе. Можно также отправлять сообщения другому сетевому хосту с помощью параметра @host.
Источник и приоритет
Селектор является шаблоном, которому удовлетворяют источник и приоритет сообщений журнала. Источник — это общая категория сообщения (см. полный список источников на странице rsyslog.conf(5) руководства).
Функция большинства источников достаточно хорошо видна из их имен. Файл конфигурации, приведенный в примере 7.1, относится к сообщениям, источниками которых являются службы kern, authpriv, mail, cron и local7. В этом же списке звездочкой отмечен ( ) джокерный символ, который перехватывает вывод, относящийся ко всем источникам.
) джокерный символ, который перехватывает вывод, относящийся ко всем источникам.
Приоритет следует после точки (.) за источником. Приоритеты располагаются в таком порядке, от низшего к высшему: debug, info, notice, warning, err, crit, alert или emerg.
примечание
Чтобы исключить сообщения журнала от какого-либо источника, укажите в файле rsyslog.conf приоритет none, как отмечено символом  в примере 7.1.
в примере 7.1.
Когда вы указываете приоритет в селекторе, служба rsyslogd отправляет сообщения с данным приоритетом и приоритетами выше указанного по назначению в данной строке. То есть в примере 7.1 селектор *.info в строке с символом  в действительности перехватывает большинство сообщений журнала и помещает их в файл /var/log/messages, поскольку приоритет info является низким.
в действительности перехватывает большинство сообщений журнала и помещает их в файл /var/log/messages, поскольку приоритет info является низким.
Расширенный синтаксис
Синтаксис службы rsyslogd расширяет традиционный синтаксис службы syslogd. Расширения конфигурации называются директивами и обычно начинаются с символа $. Одно из самых распространенных расширений позволяет вам загружать дополнительные файлы конфигурации. Попробуйте найти в вашем файле rsyslog.conf директиву, подобную приведенной ниже. Она вызывает загрузку всех файлов конфигурации. conf, расположенных в каталоге /etc/rsyslog.d:
$IncludeConfig /etc/rsyslog.d/*.conf
Названия большинства других расширенных директив не требуют дополнительных объяснений. Например, такие директивы относятся к работе с пользователями и правами доступа:
$FileOwner syslog
$FileGroup adm
$FileCreateMode 0640
$DirCreateMode 0755
$Umask 0022
примечание
Дополнительные расширения в файлах конфигурации службы rsyslogd определяют шаблоны и каналы вывода. Если вам необходимо их использовать, страница руководства rsyslogd(5) предоставит достаточно объемную информацию, однако онлайн-документация является более полной.
Устранение неполадок
Один из простейших способов проверить системный регистратор — вручную отправить сообщение журнала с помощью команды logger, как показано ниже:
$ logger — p daemon.info something bad just happened
Со службой rsyslogd возникает мало проблем. Наиболее часто это случается, когда конфигурация не соответствует некоторому источнику или приоритету, а также при заполнении разделов диска файлами журналов. В большинстве версий системы Linux файлы в каталоге /var/log укорачиваются с помощью автоматического вызова утилиты logrotate или подобной ей, однако, если в течение короткого интервала времени возникнет слишком много сообщений, по-прежнему есть вероятность заполнить ими весь диск или очень сильно загрузить систему.
примечание
Журналы, которые перехватывает служба rsyslogd, — не единственные записываемые различными частями системы. Мы обсуждали в главе 6 сообщения журнала запуска, которые отслеживают команды systemd и Upstart, однако вы обнаружите множество других источников, например веб-сервер Apache, который, как правило, ведет собственный журнал доступа и ошибок. Чтобы найти такие журналы, загляните в конфигурацию сервера.
Журналы: прошлое и будущее
Служба syslog развивается с течением времени. Ранее, например, существовал демон klogd, который перехватывал диагностические сообщения ядра для службы syslogd. Именно эти сообщения вы можете увидеть с помощью команды dmesg. Эта возможность была внедрена в версию rsyslogd.
Практически наверняка системные журналы Linux в будущем изменятся. В Unix для системных журналов никогда не существовало настоящего стандарта. Сейчас предпринимаются попытки изменить эту ситуацию.
7.3. Файлы управления пользователями
Системы Unix позволяют независимо работать нескольким пользователям. На уровне ядра пользователи являются всего лишь идентификаторами (пользовательскими ID), но поскольку гораздо проще запомнить имя, чем номер, то при управлении Linux вы будете иметь дело с именами пользователей (или зарегистрированными именами). Имена пользователей существуют только в пространстве пользователя, поэтому любому приложению, работающему с именем пользователя, как правило, необходима возможность сопоставления имени пользователя его идентификатору ID, если приложение собирается сослаться на пользователя при обращении к ядру.
7.3.1. Файл /etc/passwd
Простой текстовый файл /etc/passwd содержит соответствия имен пользователей идентификаторам ID. Он может выглядеть так (пример 7.2).
Пример 7.2. Перечень пользователей в файле /etc/passwd
root: x:0:0:Superuser:/root:/bin/sh
daemon:*:1:1:daemon:/usr/sbin:/bin/sh
bin:*:2:2:bin:/bin:/bin/sh
sys:*:3:3:sys:/dev:/bin/sh
nobody:*:65534:65534:nobody:/home:/bin/false
juser: x:3119:1000:J. Random User:/home/juser:/bin/bash
beazley: x:143:1000:David Beazley:/home/beazley:/bin/bash
Каждая строка представляет одного пользователя и состоит из семи полей, разделенных двоеточиями. Эти поля таковы.
• Имя пользователя.
• Зашифрованный пароль пользователя. В большинстве систем Linux пароль в действительности не хранится в файле passwd, а помещается в файл shadow (см. подраздел 7.3.3). Формат файла shadow похож на формат файла passwd, однако у обычных пользователей нет разрешения на чтение файла shadow. Второе поле в файле passwd или shadow является зашифрованным паролем, он выглядит как нечитаемый набор символов, например d1CVEWiB/oppc. Пароли в системе Unix никогда не хранятся в виде простого текста.
Символ x во втором поле файла passwd говорит о том, что зашифрованный пароль хранится в файле shadow. Звездочка (*) сообщает, что этот пользователь не может совершать вход в систему, а если это поле пусто (то есть вы видите два двоеточия подряд,:), то для входа в систему пароля не требуется. Остерегайтесь пустых паролей. Никогда не следует регистрировать пользователя без пароля.
Идентификатор пользователя (UID), который представляет данного пользователя ядру. Можно создать две записи с одинаковым идентификатором пользователя, но это будет сбивать с толку и вас, и ваше программное обеспечение. Старайтесь использовать уникальные идентификаторы.
Идентификатор группы (GID) представляет собой одну из нумерованных записей в файле /etc/group. Группы задают права доступа к файлам и кое-что еще. Данная группа называется также первичной группой пользователя.
• Реальное имя пользователя (часто называется полем GECOS). В этом поле вы можете встретить запятые, которые отделяют номер комнаты и номер телефона.
• Домашний каталог пользователя.
• Оболочка пользователя (команда, которая запускается при работе пользователя в терминале).
На рис. 7.1 обозначены различные поля в одной из записей примера 7.2.
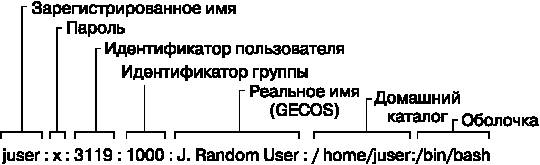
Рис. 7.1. Запись из файла паролей
Синтаксис файла /etc/passwd является довольно строгим и не допускает применения комментариев или пустых строк.
примечание
Пользователь, указанный в файле /etc/passwd, и соответствующий ему домашний каталог известны под обобщающим названием «учетная запись».
7.3.2. Особые пользователи
В файле /etc/passwd можно найти несколько особых пользователей. Пользователь superuser (корневой) всегда обладает идентификаторами UID 0 и GID 0, как в примере 7.2. У некоторых пользователей, таких как демоны, нет привилегий на вход в систему. Пользователь nobody («никто») является непривилегированным. Некоторые процессы запускаются как пользователь nobody, поскольку такой пользователь не может записывать что-либо в систему.
Пользователи, которые не могут входить в систему, именуются псевдопользователями. Хотя они и не могут войти в систему, система может запускать процессы с их идентификаторами. Такие пользователи, как nobody, обычно создаются в целях безопасности.
7.3.3. Файл /etc/shadow
Файл паролей shadow (/etc/shadow) в системе Linux обычно содержит информацию об аутентификации пользователя, включая зашифрованные пароли и сведения об окончании срока действия паролей, соответствующих пользователям из файла /etc/passwd.
Файл shadow был введен для обеспечения более гибкого (и более защищенного) способа хранения паролей. Он содержит набор библиотек и утилит, многие из которых скоро будут заменены на модули PАМ (см. раздел 7.10). Вместо того чтобы вводить совершенно новый набор файлов для системы Linux, стандарт PAM использует файл /etc/shadow, а не конкретные файлы конфигурации, такие как /etc/login.defs.
7.3.4. Управление пользователями и паролями
Обычные пользователи взаимодействуют с файлом /etc/passwd с помощью команды passwd. По умолчанию команда passwd изменяет пароль данного пользователя, но можно также указать флаг — f, чтобы изменить реальное имя пользователя, или флаг — s, чтобы изменить оболочку пользователя на одну из перечисленных в файле /etc/shells. Можно также использовать команды chfn и chsh для изменения реального имени и оболочки. Команда passwd относится к разряду suid-root-команд, поскольку только пользователь superuser может изменять файл /etc/passwd.
Изменение файла /etc/passwd с правами пользователя superuser
Поскольку файл /etc/passwd является простым текстовым файлом, пользователь superuser может выполнить изменения в любом текстовом редакторе. Чтобы создать пользователя, просто добавьте соответствующую строку и создайте домашний каталог для нового пользователя; чтобы его удалить, выполните обратные действия. Однако для редактирования этого файла лучше использовать команду vipw, которая в целях дополнительной предосторожности создает резервную копию файла /etc/passwd и блокирует его, пока вы занимаетесь редактированием. Чтобы отредактировать файл /etc/shadow вместо файла /etc/passwd, воспользуйтесь командой vipw — s. Хотя вам, скорее всего, это никогда не потребуется.
В большинстве организаций неодобрительно относятся к прямому редактированию файла passwd, поскольку при этом очень легко совершить ошибку. Гораздо проще (и безопаснее) выполнять изменения с помощью отдельных команд, доступных в терминале или в графическом интерфейсе пользователя.
Например, чтобы указать пароль для пользователя, запустите команду passwd user с правами администратора. Используйте команды adduser и userdel для добавления или удаления пользователей.
7.3.5. Работа с группами
Группы в Unix предназначены для организации совместного доступа определенных пользователей к файлам, при этом доступ всем остальным пользователям запрещен. Идея заключается в установке битов на чтение или запись для конкретной группы, исключая кого-либо еще. В свое время такая функция была важна, поскольку одним компьютером пользовалось несколько человек, однако за последние годы эта функция становится менее важной, так как рабочие станции реже предоставляются для совместного доступа.
Файл /etc/group определяет идентификаторы групп (подобные тем, которые находятся в файле /etc/passwd file). Ниже приведен пример такого файла (пример 7.3).
Пример 7.3. Пример файла /etc/group
root:*:0:juser
daemon:*:1:
bin:*:2:
sys:*:3:
adm:*:4:
disk:*:6:juser,beazley
nogroup:*:65534:
user:*:1000:
Так же как в файле /etc/passwd, каждая строка файла /etc/group является набором полей, разделенных двоеточиями. Эти поля в каждой записи следуют в таком порядке.
• Имя группы. Отображается, если вы запустите такую команду, как ls — l.
Пароль группы. Практически не используется, поэтому вам не следует его применять (вместо него воспользуйтесь командой sudo). Указывайте * или любое другое значение по умолчанию.
Идентификатор группы (число). Идентификатор GID должен быть уникальным в файле group. Это число указывается также в поле группы пользователя в записи файла /etc/passwd для данного пользователя.
Необязательный перечень пользователей, принадлежащих данной группе. В дополнение к перечисленным здесь пользователям в данную группу будут также включены пользователи с соответствующим идентификатором группы, указанном в файле passwd.
На рис. 7.2 отмечены поля в записи из файла group.
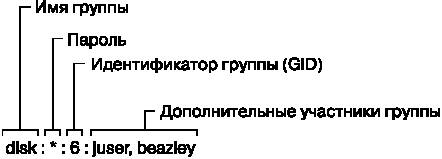
Рис. 7.2. Запись из файла group
Чтобы увидеть, в какие группы вы входите, запустите команду groups.
примечание
В Linux для каждого добавляемого пользователя часто создается новая группа, имя которой совпадает с именем пользователя.
7.4. Команды getty и login
Команда getty прикрепляется к терминалам для отображения строки приглашения. В большинстве версий Linux команда getty не усложнена, поскольку система использует ее только для входа в виртуальных терминалах. В списке процессов она обычно выглядит следующим образом (например, после запуска в терминале /dev/tty1):
$ ps ao args | grep getty
/sbin/getty 38400 tty1
В этом примере число 38400 является значением скорости двоичной передачи в бодах. Для некоторых команд getty значение этой скорости необязательно. Виртуальные терминалы игнорируют его; оно присутствует только для обратной совместимости с программным обеспечением, которое подключено к реальным последовательным каналам.
После ввода зарегистрированного имени команда getty сменится на команду login, которая запросит пароль. Если пароль указан верно, команда login сменится с помощью команды exec() на оболочку. В противном случае будет выдано сообщение о некорректном входе в систему.
Теперь вы знаете, что делают команды getty и login, но вам, вероятно, никогда не приходилось конфигурировать или изменять их. На самом деле вам даже вряд ли понадобится их использовать, поскольку теперь большинство пользователей входит в систему либо с помощью графического интерфейса, вроде gdm, либо удаленно, с помощью оболочки SSH, и ни в одном из этих способов не задействованы команды getty или login. Основная доля работы по аутентификации при входе в систему осуществляется с использованием стандарта PAM (см. раздел 7.10).
7.5. Настройка времени
Компьютеры с Unix зависят от точного хронометрирования. Ядро обслуживает системные часы, с которыми сверяются, например, при запуске команды date. Системные часы можно также настроить с помощью команды date, но такая идея является, как правило, пагубной, поскольку вы никогда не сможете узнать время абсолютно точно. Системные часы должны быть близки к точному времени, насколько это возможно.
Аппаратные средства ПК содержат часы реального времени (RTC, real-time clock) с питанием от батареи. Это не самые точные часы в мире, но они лучше, чем совсем ничего. Ядро обычно устанавливает время на основе показаний RTC во время загрузки системы, и можно выполнить сброс показания системных часов до текущего значения аппаратного времени с помощью команды hwclock. Настройте аппаратные часы на время UTC (Universal Coordinated Time, всеобщее скоординированное время), чтобы избежать различных сложностей, связанных с часовыми поясами или переходом на летнее время. Можно настроить часы RTC в соответствии с UTC-часами ядра с помощью следующей команды:
# hwclock — hctosys — utc
К сожалению, ядро хранит время еще хуже, чем часы RTC, и поскольку компьютеры Unix часто работают в течение нескольких месяцев или лет после единственной загрузки, возрастает смещение по времени. Смещение по времени — это текущая разность между временем ядра и истинным временем (которое определено по атомным или каким-либо еще очень точным часам).
Не следует пытаться исправлять смещение по времени с помощью команды hwclock, поскольку системные события, основанные на времени, могут быть потеряны или искажены. Можно было бы запустить утилиту вроде adjtimex, чтобы аккуратно обновить показания часов, но обычно правильность системного времени лучше всего поддерживать с помощью сетевого демона времени (см. подраздел 7.5.2).
7.5.1. Представление времени в ядре и часовые пояса
Системные часы ядра представляют текущее время в виде количества секунд, протекших с полуночи 1 января 1970 года по времени UTC. Чтобы увидеть это значение для данного момента, запустите такую команду:
$ date +%s
Чтобы представить это число в приемлемом для человека формате, команды из пространства пользователя переводят его в местное время с учетом перехода на летнее время, а также других необычных обстоятельств (таких как проживание в штате Индиана2). Местный часовой пояс настраивается с помощью файла /etc/localtime. Не пытайтесь заглянуть в него, поскольку этот файл является двоичным.
Файлы часовых поясов для вашей системы расположены в каталоге /usr/share/zoneinfo. Этот каталог содержит множество файлов часовых поясов и псевдонимов для них. Чтобы настроить часовой пояс вручную, скопируйте один из таких файлов из каталога /usr/share/zoneinfo в каталог /etc/localtime, или создайте символическую ссылку, или же измените его с помощью инструмента для работы с часовыми поясами. Команда tzselect может помочь вам при определении файла часового пояса.
Чтобы использовать лишь на один сеанс оболочки часовой пояс, который отличается от установленного в системе по умолчанию, укажите в переменной окружения TZ имя файла из каталога /usr/share/zoneinfo и проверьте изменения, например, так:
$ export TZ=US/Central
$ date
Как и в случае с другими переменными окружения, можно указать часовой пояс только на время работы единственной команды:
$ TZ=US/Central date
7.5.2. Сетевое время
Если ваш компьютер постоянно подключен к сети Интернет, можно запустить демон NTP (Network Time Protocol, протокол сетевого времени), чтобы настраивать время с помощью удаленного сервера. Во многие версии ОС встроена поддержка демона NTP, однако он может быть не включен по умолчанию. Может потребоваться установка пакета ntpd, чтобы привести его в действие.
Если вам необходимо выполнить конфигурацию вручную, справочную информацию можно найти на основной странице NTP (http://www.ntp.org/), но если вы предпочитаете не копаться в документации, выполните следующее.
1. Отыщите ближайший к вам сервер NTP, узнав его от поставщика интернет-услуг или на странице ntp.org.
2. Поместите имя сервера времени в файл /etc/ntpd.conf.
3. Запустите во время загрузки системы команду ntpdate server.
4. После команды ntpdate запустите во время загрузки системы команду ntpd.
Если ваш компьютер не подключен к Интернету постоянно, можно использовать демон вроде chronyd, чтобы поддерживать время, когда подключение отсутствует.
Можно также настроить аппаратные часы на основе сетевого времени, чтобы обеспечить связность отсчета времени в системе при ее перезагрузке. Во многих версиях ОС это происходит автоматически. Чтобы выполнить это, возьмите системное время из сети с помощью команды ntpdate (или ntpd), а затем запустите команду, которую вы уже видели ранее:
# hwclock — systohc — utc
7.6. Планирование повторяющихся задач с помощью службы cron
Служба cron в Unix повторно запускает команды на основе постоянного расписания. Большинство опытных администраторов считают службу cron особо важной для системы, поскольку она способна выполнять автоматическое обслуживание системы. Например, она выполняет запуск утилит для чистки файлов журналов, чтобы ваш жесткий диск не переполнялся старыми файлами журналов. Вам следует знать, как использовать службу cron, поскольку она, безусловно, полезна.
С помощью службы cron можно запустить любую команду в любое удобное для вас время. Команда, запущенная с помощью службы cron, называется заданием cron. Чтобы создать задание cron, необходимо внести запись в файл crontab, обычно с помощью команды crontab.
Например, для настройки ежедневного запуска команды /home/juser/bin/spmake в 9:15 утра запись выглядит так:
15 09 * * * /home/juser/bin/spmake
Пять разделенных пробелами полей в начале этой строки определяют запланированное время (см. также рис. 7.3). Эти поля обозначают следующее:
• минута (от 0 до 59). Приведенное выше задание cron настроено на запуск в 15-ю минуту;
• час (от 0 до 23). Задание настроено на запуск в 9-й час;
• день месяца (от 1 до 31);
• месяц (от 1 до 12);
• день недели (от 0 до 7). Числа 0 и 7 соответствуют воскресенью.
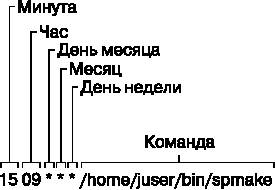
Рис. 7.3. Запись из файла crontab
Звездочка (*) в любом поле соответствует любому значению. В приведенном примере команда spmake запускается ежедневно, поскольку поля для дня месяца, месяца и дня недели заполнены звездочками, которые служба cron интерпретирует как «запускать данное задание каждый день, каждый месяц и каждый день недели».
Чтобы запускать команду spmake только на 14-й день каждого месяца, можно воспользоваться такой строкой в файле crontab:
15 09 14 * * /home/juser/bin/spmake
Можно указывать более одного значения в каждом поле. Чтобы, например, запускать команду по 5-м и 14-м числам каждого месяца, следует ввести числа 5,14 в третье поле:
15 09 5,14 * * /home/juser/bin/spmake
примечание
Если задание cron создает стандартный вывод, ошибку или некорректно завершает работу, служба cron отправит вам по электронной почте сообщение об этом. Если такие электронные письма вам надоедают, перенаправьте вывод в устройство /dev/null или в какой-либо файл журнала.
Страница руководства crontab(5) содержит полную информацию о формате файла crontab.
7.6.1. Установка файлов crontab
У каждого пользователя может быть свой файл crontab. Это значит, что в системе может быть несколько таких файлов, которые, как правило, располагаются в каталоге /var/spool/cron/crontabs. Обычным пользователям не разрешено выполнять запись в данный каталог. Пользовательский файл crontab можно разместить, просмотреть, отредактировать и удалить с помощью команды crontab.
Простейший способ установить файл crontab — поместить записи в какой-либо файл, а затем воспользоваться командой crontab file, чтобы установить этот файл в качестве текущего файла crontab. Команда crontab проверяет формат файла, чтобы убедиться в отсутствии ошибок в нем. Чтобы вывести список заданий cron, запустите команду crontab — l. Чтобы удалить файл crontab, воспользуйтесь командой crontab — r.
Тем не менее, после того как вы создали начальный файл crontab, использование временных файлов при дальнейшем его редактировании может вызвать неудобства. Вместо этого можно отредактировать и установить файл crontab за один шаг с помощью команды crontab — e. Если вы допустите ошибку, команда crontab сообщит вам о том, где она находится, и предложит вам повторно отредактировать файл.
7.6.2. Системные файлы crontab
Чтобы при планировании повторяющихся системных задач не использовать файл crontab для пользователя с правами superuser, в системах Linux обычно предусмотрен файл /etc/crontab. Не применяйте команду crontab для редактирования этого файла, поскольку в его записях присутствует дополнительное поле, вставленное перед командой, предназначенной для запуска. В этом поле указан пользователь, который должен запустить задание. Вот, например, задание cron, которое определено в файле /etc/crontab и будет запускаться в 6:42 утра с правами корневого пользователя (root, отмечен символом  ):
):
42 6 * * * root /usr/local/bin/cleansystem > /dev/null 2>&1
/usr/local/bin/cleansystem > /dev/null 2>&1
примечание
В некоторых версиях системные файлы crontab хранятся в каталоге /etc/cron.d. Такие файлы могут быть названы как угодно, но все они обладают тем же форматом, что и файл /etc/crontab.
7.6.3. Будущее службы cron
Утилита cron является одним из старейших компонентов системы Linux, она используется уже десятки лет (задолго до самой Linux). За эти годы формат конфигурации изменился ненамного. Сегодня пытаются выполнить замену данной утилиты.
Предлагаемые замены на самом деле являются лишь частями новых версий команды init: для варианта systemd это модули таймера, а для варианта Upstart идея заключается в возможности создания повторяющихся событий для запуска заданий. В конечном итоге оба варианта команды init могут запускать задачи от имени любого пользователя; они обладают также некоторыми преимуществами, такими как специальный вход в систему.
Однако реальность такова, что ни версия systemd, ни версия Upstart не обладают в данный момент всеми возможностями утилиты cron. Более того, когда они будут способны к этому, потребуется обратная совместимость для поддержки всего, что основано на службе cron. По этим причинам формат cron вряд ли исчезнет в ближайшее время.
7.7. Планирование единовременных задач с помощью службы at
Чтобы запустить задание в будущем один раз без помощи службы cron, воспользуйтесь службой at. Например, чтобы запустить команду myjob в 22:30 вечера, введите такую команду:
$ at 22:30
at> myjob
Завершите ввод, нажав сочетание клавиш Ctrl+D. Утилита at считывает команды из стандартного ввода.
Чтобы убедиться в том, что задание запланировано, используйте команду atq. Чтобы его удалить, запустите команду atrm. Можно также указать день для выполнения задания, добавив дату в формате ДД.ММ.ГГ, например, так: 22:30 30.09.15.
О команде at больше нечего добавить. Хотя она используется нечасто, она может пригодиться тогда, когда вам необходимо сообщить системе, чтобы она выключилась в будущем.
7.8. Идентификаторы пользователей и переключение между пользователями
Мы рассказывали о том, каким образом setuid-команды вроде sudo и su позволяют вам сменить пользователя, а также упомянули о системных компонентах типа login, которые контролируют пользовательский доступ. Возможно, вам интересно, как работают эти составляющие и какую роль играет ядро в переключении между пользователями.
Существует два способа изменить идентификатор пользователя, и оба они используются ядром. Первый способ — с помощью исполняемого файла setuid, о котором рассказано в разделе 2.17. Второй способ — используя семейства системных вызовов setuid(). Есть несколько различных версий таких вызовов, которые охватывают всевозможные идентификаторы пользователей, связанные с процессами, как вы узнаете далее.
Ядро обладает набором правил относительно того, что дозволено процессу, а что — нет. Приведу три основных правила.
• Процесс, запущенный как корневой (userid 0), может использовать команду setuid(), чтобы стать любым другим пользователем.
• На процесс, запущенный не в качестве корневого, накладываются строгие ограничения по использованию команды setuid(); в большинстве случаев он не может ее использовать.
• Любой процесс может выполнить setuid-команду, если у него есть соответствующие права доступа к файлам.
примечание
Переключение между пользователями никак не затрагивает пароли или имена пользователей. Эти понятия относятся исключительно к пространству пользователя, как вы уже видели на примере файла /etc/passwd в подразделе 7.3.1. Дополнительные подробности о том, как это работает, — в разделе 7.9.
Принадлежность процессов, эффективный, реальный и сохраненный идентификатор пользователя. Наш рассказ об идентификаторах пользователя до сего момента был упрощенным. В действительности каждый процесс снабжен несколькими идентификаторами пользователя. Мы описали эффективный идентификатор пользователя (euid), который определяет права доступа для процесса. Второй идентификатор пользователя, реальный идентификатор пользователя (ruid), указывает на инициатора процесса. При запуске setuid-команды система Linux устанавливает для владельца команды значение эффективного идентификатора пользователя во время исполнения, но она сохраняет исходный идентификатор в качестве реального идентификатора пользователя.
В современных системах различие между эффективным и реальным идентификаторами пользователя приводит к такой путанице, что большая часть документации, посвященной принадлежности процессов, является неверной.
Представляйте себе эффективный идентификатор пользователя как исполнителя, а реальный идентификатор — как владельца. Реальный идентификатор пользователя определяет того пользователя, который может взаимодействовать с запущенным процессом, и, что наиболее важно, пользователя, который может прерывать процесс и отправлять ему сигналы. Если, например, пользователь А запускает новый процесс от имени пользователя B (на основе разрешений setuid), то пользователь A по-прежнему владеет этим процессом и может его прервать.
В обычных системах Linux у большинства процессов совпадают эффективный и реальный идентификаторы пользователя. По умолчанию команда ps и другие команды диагностики системы показывают эффективный идентификатор пользователя. Чтобы увидеть оба идентификатора в своей системе, попробуйте ввести приведенную ниже команду, но не удивляйтесь, если вы обнаружите, что для всех процессов окажутся одинаковыми два столбца с идентификаторами пользователя:
$ ps — eo pid,euser,ruser,comm
Чтобы создать исключение только для того, чтобы увидеть различные значения в столбцах, попробуйте поэкспериментировать: создайте setuid-копию команды sleep, запустите эту копию на несколько секунд, а затем выполните приведенную выше команду ps в другом окне, прежде чем копия прекратит работу.
Чтобы усугубить путаницу, в дополнение к реальному и эффективному идентификаторам пользователя есть также сохраненный идентификатор пользователя (для которого обычно не используют сокращение). Во время выполнения процесс может переключить свой эффективный идентификатор пользователя на реальный или сохраненный. Чтобы вещи стали еще более сложными, в системе Linux присутствует идентификатор пользователя файловой системы (fsuid), который определяет пользователя, имеющего доступ к файловой системе. Однако этот идентификатор используется редко.
Типичное поведение команды setuid. Идея, заложенная в реальный идентификатор пользователя, может противоречить вашему предшествующему опыту. Почему вам не приходится часто иметь дело с другими идентификаторами пользователя? Например, если после запуска процесса с помощью команды sudo вам необходимо его остановить, вы также используете команду sudo; обычный пользователь не может остановить процесс. Не должен ли в таком случае обычный пользователь обладать реальным идентификатором пользователя, чтобы получить правильные права доступа?
Причина такого поведения заключается в том, что команда sudo и многие другие setuid-команды явным образом изменяют эффективный и реальный идентификаторы пользователя с помощью системных вызовов команды setuid(). Эти команды поступают так потому, что зачастую возникают непреднамеренные побочные эффекты и проблемы с доступом, если не совпадают все идентификаторы пользователя.
примечание
Если вам интересны подробности и правила, относящиеся к переключению идентификаторов пользователя, прочитайте страницу руководства setuid(2), а также загляните на страницы, перечисленные в секции SEE ALSO («см. также»). Для различных ситуаций существует множество разных системных вызовов.
Некоторым командам не нравится корневой реальный идентификатор пользователя. Чтобы запретить команде sudo изменение реального идентификатора пользователя, добавьте следующую строку в файл /etc/sudoers (и остерегайтесь побочных эффектов на другие команды, которые вы желаете запускать с корневыми правами!):
Defaults stay_setuid
Привлечение функций безопасности. Поскольку ядро Linux обрабатывает все переключения между пользователями (и как результат права доступа к файлам) с помощью команд setuid и последующих системных вызовов, системные программисты и администраторы должны быть исключительно внимательны по отношению:
• к командам, у которых есть права доступа к setuid;
• к тому, что эти команды выполняют.
Если вы создадите копию оболочки bash, которая будет наделена корневыми правами setuid, любой локальный пользователь сможет получить полное управление системой. Это действительно просто. Более того, даже специальная команда, которой предоставлены корневые права setuid, способна создать риск, если в ней есть ошибки. Использование слабых мест программы, работающей с корневыми правами, является основным методом вторжения в систему, и количество попыток такого использования очень велико.
Поскольку существует множество способов проникновения в систему, предотвращение вторжения является многосторонней задачей. Один из самых важных способов избежать нежелательной активности в системе состоит в обязательной аутентификации пользователей с помощью имен пользователей и паролей.
7.9. Идентификация и аутентификация пользователей
Многопользовательская система должна обеспечивать базовую поддержку безопасности пользователей в терминах идентификации и аутентификации. Идентификация отвечает на вопрос, что за пользователи перед нами. При аутентификации система просит пользователей доказать, что они являются теми, кем они себя называют. Наконец, авторизация используется для определения границ того, что дозволено пользователям.
Когда дело доходит до идентификации пользователя, ядро системы Linux знает только численный идентификатор пользователя для процесса и владения файлами. Ядро знает о правилах авторизации, относящихся к тому, как запускать исполняемые файлы setuid и как совершать системные вызовы из семейства setuid(), чтобы выполнить переход от одного пользователя к другому. Однако ядро ничего не знает об аутентификации: именах пользователей, паролях и т. п. Практически все, что относится к аутентификации, происходит в пространстве пользователя.
В подразделе 7.3.1 мы рассматривали соответствие между идентификаторами пользователей и паролями. Сейчас я объясню, как пользовательские процессы получают доступ к этому соответствию. Начнем с предельно упрощенного случая, при котором пользовательский процесс желает узнать свое имя пользователя (имя, которое соответствует эффективному идентификатору пользователя). В традиционной системе Unix процесс мог бы выполнить для этого что-либо подобное.
1. Процесс спрашивает у ядра свой эффективный идентификатор пользователя с помощью системного вызова geteuid().
2. Процесс открывает файл /etc/passwd и начинает его чтение с самого начала.
3. Процесс читает строки в файле /etc/passwd. Если читать больше нечего, попытка поиска имени пользователя завершается неудачей.
4. Процесс выполняет анализ строки по полям (вытаскивая все, что находится между двоеточиями). Третье поле является идентификатором пользователя в текущей строке.
5. Процесс сравнивает идентификатор, полученный на четвертом шаге, с тем, который был получен на первом шаге. Если они совпадают, первое поле, найденное на четвертом шаге, является искомым именем пользователя; процесс может прекратить поиски и воспользоваться данным именем.
6. Процесс переходит к следующей строке файла /etc/passwd и возвращается к третьему шагу.
Процедура довольно длинная, а в реальности она обычно гораздо более сложная.
Применение библиотек для получения информации о пользователе. Если каждому разработчику, которому потребовалось узнать текущее имя пользователя, приходилось бы создавать весь код, который вы только что видели, система стала бы ужасающе несвязной, раздутой и совершенно неуправляемой. К счастью, мы можем использовать стандартные библиотеки, чтобы выполнять повторяющиеся задачи. Чтобы узнать имя пользователя, необходимо лишь вызвать функцию вроде getpwuid() из стандартной библиотеки после получения ответа от команды geteuid(). Обратитесь к страницам руководства по этим вызовам, чтобы узнать о том, как они работают.
Когда стандартная библиотека является используемой совместно, можно осуществить значительные изменения в реализации системы, не меняя никаких других команд. Например, можно полностью уйти от применения файла /etc/passwd для ваших пользователей и применять вместо него сетевую службу, подобную LDAP (Lightweight Directory Access Protocol, облегченный (упрощенный) протокол доступа к (сетевым) каталогам).
Такой подход прекрасно работает при идентификации имен пользователей, связанных с идентификаторами, однако для паролей дела обстоят сложнее. В подразделе 7.3.1 описано, каким обычно образом зашифрованный пароль становится частью файла /etc/passwd, поэтому, если бы вам понадобилось проверить введенный пользователем пароль, пришлось бы шифровать все, что вводит пользователь, и сравнивать с содержимым файла /etc/passwd.
Традиционная реализация обладает следующими ограничениями.
• Не устанавливается общесистемный стандарт на протокол шифрования.
• Предполагается, что у вас есть доступ к зашифрованному паролю.
• Предполагается, что пользователю будет предлагаться ввести пароль всякий раз, когда он будет пытаться получить доступ к чему-либо, требующему аутентификации.
• Предполагается, что вы намерены использовать именно пароли. Если вы желаете применять одноразовые жетоны, смарт-карты, биометрическую или какую-либо еще аутентификацию пользователя, вам придется добавлять такую поддержку самостоятельно.
Некоторые ограничения, посодействовавшие развитию пакета shadow-паролей, рассмотрены в подразделе 7.3.3. Этот файл сделал первый шаг к тому, чтобы разрешить конфигурирование паролей на уровне системы в целом. Однако решение большинства проблем пришло вместе с разработкой и реализацией стандарта PAM.
7.10. Стандарт PAM
Чтобы обеспечить гибкость при аутентификации пользователей, в 1995 году корпорация Sun Microsystems предложила новый стандарт под названием PAM (Pluggable Authentication Modules, подключаемые модули аутентификации) — систему совместно используемых библиотек для аутентификации (рабочие предложения Open Source Software Foundation, выпуск 86.0, октябрь 1995 года). Для аутентификации пользователя приложение «вручает» пользователя утилите PAM, чтобы определить, может ли пользователь успешно идентифицировать себя. Таким образом сравнительно легко добавить поддержку дополнительных методов, таких как двухфакторная аутентификация или ключи на материальных носителях. В дополнение к поддержке механизма аутентификации стандарт PAM также обеспечивает ограниченную степень контроля авторизации для служб (если, например, вы желаете, чтобы у некоторых пользователей не было службы cron).
Поскольку существуют различные типы аутентификации, стандарт PAM использует несколько динамически загружаемых модулей аутентификации. Каждый модуль выполняет специальную задачу; например, модуль pam_unix.so проверяет пароль пользователя.
Занятие это довольно сложное. Программный интерфейс непростой, и неясно, действительно ли стандарт PAM справляется со всеми существующими проблемами. Однако поддержка стандарта PAM присутствует практически в каждой команде, для которой требуется аутентификация в системе Linux, и большинство версий системы используют этот стандарт. Поскольку он работает поверх интерфейса API для аутентификации, существующего в Unix, интеграция поддержки в клиент требует незначительной (а то и совсем никакой не требует) дополнительной работы.
7.10.1. Конфигурация PAM
Мы изучим основы стандарта PAM, рассмотрев его конфигурацию. Файлы конфигурации PAM обычно можно найти в каталоге /etc/pam.d (в старых системах может использоваться единственный файл /etc/pam.conf). Во многих версиях содержится несколько файлов, и может быть неясно, с чего начать. Определенные имена файлов должны соответствовать частям системы, которые вы уже знаете, например cron и passwd.
Поскольку специальная конфигурация в таких файлах может сильно различаться в разных версиях системы, трудно подыскать общий пример. Рассмотрим образец строки конфигурации, который вы можете обнаружить для команды chsh (команда смены оболочки):
auth requisite pam_shells.so
Эта строка говорит о том, что оболочка пользователя должна располагаться в каталоге /etc/shells, чтобы пользователь мог успешно пройти аутентификацию команды chsh. Посмотрим, каким образом. Каждая строка конфигурации содержит три поля в таком порядке: тип функции, управляющий аргумент и модуль. Вот что они означают для данного примера.
• Тип функции. Это функция, которую пользовательское приложение просит выполнить утилиту PAM. В данном случае это команда auth, задание аутентификации пользователя.
Управляющий аргумент. Этот параметр контролирует то, что будет делать PAM-приложение после успешного или неудачного завершения действия в данной строке (requisite в этом примере). Скоро мы перейдем к этому.
Модуль. Это модуль аутентификации, который запускается для данной строки и определяет, что именно делает строка. Здесь модуль pam_shells.so проверяет, упоминается ли текущая оболочка пользователя в файле /etc/shells.
Конфигурация PAM детально описана на странице руководства pam.conf(5). Рассмотрим некоторые основные части.
Типы функций
Пользовательское приложение может попросить PAM-утилиту выполнить одну из четырех перечисленных ниже функций:
• auth — выполнить аутентификацию пользователя (проверить, является ли пользователь тем, кем он себя называет);
• account — проверить статус учетной записи пользователя (авторизован ли, например, пользователь на выполнение каких-либо действий);
• session — выполнить что-либо только для текущего сеанса пользователя (например, отобразить сообщение дня);
• password — изменить пароль пользователя или другую информацию в учетной записи.
Для любой строки конфигурации модуль и функция совместно определяют действие PAM-утилиты. У модуля может быть несколько типов функции, поэтому при определении назначения строки конфигурации всегда помните о том, что функцию и модуль следует рассматривать в виде пары. Например, модуль pam_unix.so проверяет пароль, когда выполняет функцию auth, но если он выполняет функцию password, то пароль устанавливается.
Управляющие аргументы и стек правил
Одним важным свойством стандарта PAM является то, что правила, которые определены в строках конфигурации, образуют стек, это значит, что можно применять несколько правил при выполнении функции. Именно поэтому важен управляющий аргумент: успешное или неудачное завершение действия в одной строке может повлиять на следующие строки или привести к тому, что сама функция завершит работу корректно или нет.
Существуют два типа управляющих аргументов: с простым и более сложным синтаксисом. Приведу три главных управляющих аргумента с простым синтаксисом, которые вы можете найти в правиле.
• sufficient. Если данное правило выполняется успешно, аутентификация также проходит успешно и PAM-утилите не нужно проверять следующие правила. Если правило не выполняется, утилита PAM переходит к дополнительным правилам.
• requisite. Если правило выполняется успешно, PAM-утилита переходит к следующим правилам. Если правило не выполняется, аутентификация завершается неудачей и PAM-утилите не нужно проверять следующие правила.
• required. Если данное правило выполняется успешно, PAM-утилита переходит к следующим правилам. Если правило не выполняется, PAM-утилита переходит к следующим правилам, но всегда вернет отрицательный результат аутентификации, вне зависимости от результатов выполнения дополнительных правил.
Продолжая предыдущий пример, приведу образец стека для функции аутентификации chsh:
auth sufficient pam_rootok.so
auth requisite pam_shells.so
auth sufficient pam_unix.so
auth required pam_deny.so
В соответствии с этой конфигурацией, после того как команда chsh запрашивает PAM-утилиту о выполнении функции аутентификации, утилита выполняет следующее (см. блок-схему на рис. 7.4).
1. Модуль pam_rootok.so проверяет, не пытается ли пройти аутентификацию корневой пользователь. Если это так, то происходит немедленное успешное завершение и дальнейшая аутентификация не предпринимается. Это срабатывает, поскольку для управляющего аргумента установлено значение sufficient, которое означает, что успешного завершения данного действия достаточно, чтобы утилита PAM немедленно возвратила результат команде chsh. В противном случае она переходит ко второму шагу.
2. Модуль pam_shells.so проверяет, есть ли оболочка пользователя в файле /etc/shells. Если ее там нет, модуль возвращает отказ, а управляющий аргумент requisite говорит о том, что утилита PAM должна немедленно сообщить об отказе команде chsh и не пытаться продолжать аутентификацию. В противном случае, когда оболочка есть в файле /etc/shells, модуль возвращает результат, который удовлетворяет флагу required, переходя к третьему шагу.
3. Модуль pam_unix.so запрашивает у пользователя пароль и проверяет его. Для управляющего аргумента указано значение sufficient, поэтому успешной проверки (пароль верный) достаточно для утилиты PAM, чтобы она сообщила об этом команде chsh. Если пароль неверный, утилита PAM переходит к четвертому шагу.
4. Модуль pam_deny.so всегда вызывает отказ, а поскольку присутствует управляющий аргумент required, утилита PAM возвращает отказ команде chsh. Этот вариант применяется по умолчанию в тех случаях, когда больше нечего пробовать. Обратите внимание на то, что управляющий аргумент required не приводит к моментальному отказу функции PAM — она обработает все остальные строки стека, — однако в результате в приложение всегда вернется отказ.
примечание
Не смешивайте термины «функция» и «действие», когда работаете с утилитой PAM. Функция является целью верхнего уровня: что ожидает пользовательское приложение от утилиты PAM (например, выполнить аутентификацию пользователя). Действие является отдельным шагом, который выполняет утилита, чтобы достичь цели. Запомните лишь то, что сначала пользовательское приложение вызывает функцию, а утилита PAM заботится обо всех деталях, связанных с действиями.
Сложный синтаксис управляющего аргумента, помещаемый внутри квадратных скобок ([]), позволяет вручную контролировать реакцию, основываясь на специальном значении, которое возвращает модуль (не только успех или отказ). Подробности см. на странице pam.conf(5) руководства. Когда вы разберетесь с простым синтаксисом, у вас не возникнет затруднений и со сложным.
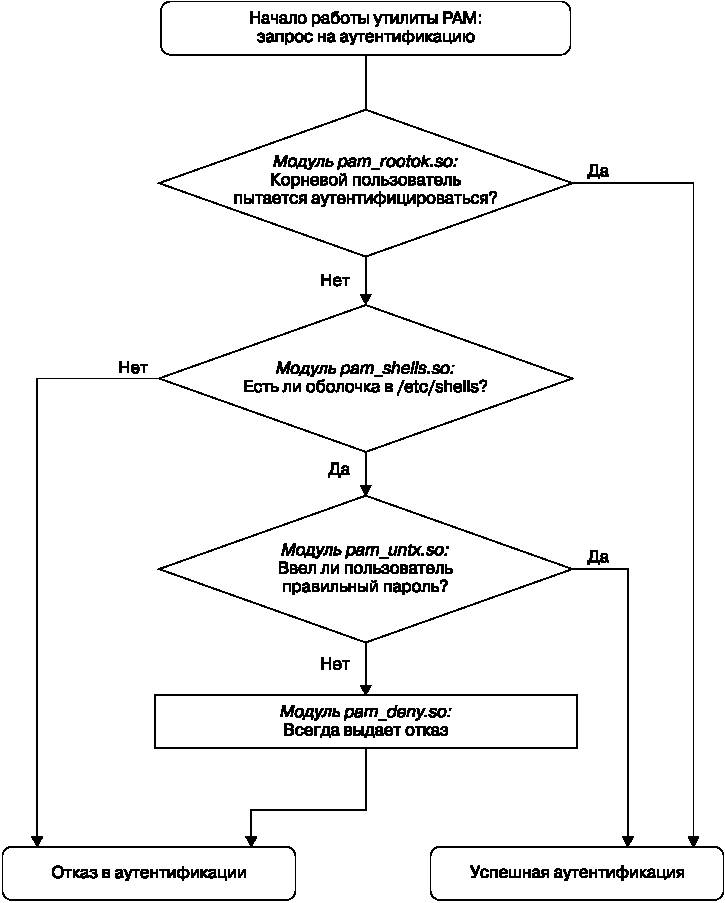
Рис. 7.4. Процесс исполнения правила PAM
Аргументы модуля
Модули PAM могут задействовать аргументы после имени модуля. Вам часто будет встречаться такой вариант для модуля pam_unix.so:
auth sufficient pam_unix.so nullok
Здесь аргумент nullok сообщает о том, что у пользователя может не быть пароля (по умолчанию в таком случае возник бы отказ).
7.10.2. Примечания о стандарте PAM
Благодаря возможности управления процессом и модульному синтаксису аргументов синтаксис PAM-конфигурации обладает многими чертами языка программирования и некоторыми функциональными возможностями. Мы лишь слегка затронули эту тему, однако приведу еще несколько моментов, относящихся к стандарту PAM.
• Чтобы выяснить, какие модули PAM присутствуют в вашей системе, воспользуйтесь командой man — k pam_ (обратите внимание на символ подчеркивания). Может оказаться непросто выяснить местоположение модулей. Попробуйте команду locate unix_pam.so и посмотрите, к чему это приведет.
• Страницы руководства содержат описание функций и аргументов для каждого модуля.
• Многие версии системы автоматически генерируют некоторые файлы конфигурации PAM, поэтому неразумно изменять их напрямую в каталоге /etc/pam.d. Прочитайте комментарии в этих файлах перед их редактированием; если они были сгенерированы, комментарии скажут вам, откуда взялись файлы.
• Конфигурационные файлы в каталоге /etc/pam.d/other определяют конфигурацию по умолчанию для любого приложения, у которого нет собственного файла конфигурации. Часто по умолчанию на все следует отказ.
• Существуют разные способы включения дополнительных файлов конфигурации в файл конфигурации PAM. Синтаксис @include загружает весь файл конфигурации, но можно также использовать управляющий аргумент, чтобы загрузить только конфигурацию для конкретной функции. Способ использования разный для различных версий системы.
• Конфигурация PAM не ограничивается лишь аргументами модуля. Некоторые модули могут иметь доступ к дополнительным файлам в каталоге /etc/security, как правило, для настройки ограничений для отдельного пользователя.
7.10.3. Стандарт PAM и пароли
В результате эволюции системы проверки паролей в Linux сохранилось несколько артефактов, которые иногда могут привести к путанице. Во-первых, следует опасаться файла /etc/login.defs. Это файл конфигурации для исходного набора shadow-паролей. Он содержит информацию об алгоритме шифрования, использованном для файла shadow, однако редко применяется в современных системах с установленными модулями PAM, поскольку конфигурация PAM уже содержит данную информацию. Учитывая сказанное, алгоритм шифрования, указанный в файле /etc/login.defs, должен совпадать с конфигурацией PAM — для тех редких случаев, когда вам встретится приложение, не поддерживающее стандарт PAM.
Откуда утилита PAM получает информацию о схеме шифрования пароля? Вспомните о том, что она может взаимодействовать с паролями двумя способами: с помощью функции auth (для проверки пароля) и функции password (для установки пароля). Проще отследить параметр, устанавливающий пароль. Лучшим способом будет, вероятно, простое использование команды grep:
$ grep password.*unix /etc/pam.d/*
Соответствующие строки должны содержать имя pam_unix.so и выглядеть, например, так:
password sufficient pam_unix.so obscure sha512
Аргументы obscure и sha512 говорят утилите PAM о том, что следует делать при установке пароля. Сначала утилита проверяет, является ли пароль достаточно «скрытным» (то есть, среди прочего, не напоминает ли он предыдущий пароль), а затем использует алгоритм SHA512, чтобы зашифровать новый пароль.
Однако так происходит только тогда, когда пользователь устанавливает пароль, а не когда утилита PAM проверяет его. Как же ей узнать, какой алгоритм использовать при аутентификации? К сожалению, конфигурация не сообщит ничего; у модуля pam_unix.so нет аргументов шифрования для функции auth.
Оказывается (на момент написания книги), модуль pam_unix.so просто пытается угадать алгоритм, как правило призывая на выполнение этой грязной работы библиотеку libcrypt, которая перебирает множество различных вариантов, пока что-либо не сработает или будет нечего пробовать. Следовательно, вам не придется заботиться об алгоритме шифрования при верификации.
7.11. Заглядывая вперед
Рассмотрев многие из жизненно важных блоков системы Linux, сейчас мы прошли половину этой книги. Обсуждение процесса входа в систему и управления пользователями Linux познакомило вас с тем, что позволяет разбивать службы и задачи на маленькие независимые фрагменты, которые до определенной степени обладают способностью взаимодействовать.
Данная глава практически полностью была посвящена пространству пользователя, теперь необходимо уточнить наши представления о процессах из пространства пользователя и о потребляемых ими ресурсах. Для этого в главе 8 мы возвращаемся обратно в ядро.
2 Большая часть штата, включая столицу, входит в Восточную зону времени, где принято так называемое Северо-Американское восточное стандартное время. В некоторых округах на западе штата принято так называемое Центральное стандартное время. — Примеч. пер.
Канал с обзорами, анонсами новинок и книжными подборками
 Книжный Вестник
Книжный Вестник
Бот для удобного поиска книг (если не нашлось на сайте)
 Поиск книг
Поиск книг
Свежие любовные романы в удобных форматах
 Любовные романы
Любовные романы
О психологии, саморазвитии и личностном росте
 Саморазвитие
Саморазвитие
Детективы и триллеры, все новинки
 Детективы
Детективы
Фантастика и фэнтези, все новинки
 Фантастика
Фантастика
Отборные классические книги
 Классика
Классика
 ВКОНТАКТЕ
ВКОНТАКТЕБиблиотека с любовными романами, которая наверняка придётся по вкусу женской части аудитории
Любовные романы
Библиотека с фантастикой и фэнтези, а также смежных жанров
Фантастика
Самые популярные книги в формате фб2
Топ фб2
книги