II
Нельзя ли по частоте таких частиц узнавать авторов, как-будто по чертам их портретов?
Для этого прежде всего надо перевести их на графики, обозначая каждую распорядительную частицу на горизонтальной линии, а число её повторения на вертикальной, и сравнить эти графики между собой у различных авторов.
Ещё в первые годы моей сознательной жизни, задолго до того, как я познакомился с трудами Гомперца и других стилеметристов, мне пришла такая идея и даже ясно представились её вероятные детали. Мне было ясно, что у авторов различных эпох такие графики в некоторых служебных частицах должны сильно различаться. Возьмём хотя бы частицу ибо, часто встречающуюся в русском языке ещё в первой четверти XIX века. Очевидно, что вместо неё на графике современных нам писателей будет зияющая зазубрина, так как её теперь нет. Точно также слово весьма оставит вместо себя пустоту, потому что оно заменилось теперь почти нацело словом очень, и т. д., и т. д.
Даже у современных друг другу писателей должны появляться свои оригинальные зазубрины, свойственные лишь им одним, благодаря антипатии того или другого автора к той или другой служебной частице.
Всё это, думалось мне, делает такие графики подобными световым спектрам химических элементов, в которых каждый элемент характеризуется своими особыми зазубринами, так что астроном легко и надёжно определяет по ним химический состав недоступных нашим летательным аппаратам небесных светил.
Тогда же мне пришла в голову и мысль назвать подобные графики лингвистическими спектрами, и исследование по ним авторов назвать лингвистическим анализом, соответственно спектральному анализу состава небесных светил.
Однако, разработать эти идеи мне было долго невозможно в Шлиссельбургской крепости, где они впервые пришли мне в голову, хотя в последние годы мне вновь пришлось возвратиться там невольно к этому предмету. Астрономическое исследование Апокалипсиса и библейских пророков привело меня по имеющимся там астрономическим данным к неожиданному для меня самого заключению, что черновик этой книги написан в промежуток от 30 сентября по 1 октября 395 года нашей эры, а библейские пророки ещё позднее: в V веке нашей же эры. Это приводило меня к выводу, что все дошедшие до нас сочинения «Иоанна Хризостома», «Оригена», «Тертулиаиа» и других христианских авторов первых четырёх веков нашей эры апокрифичны, так как они упоминают и об Апокалипсисе, и о пророках.
Идея об исследовании их лингвистическим анализом сама собой пришла мне в голову. Но для этого необходимо было прочно установить основные приёмы такого анализа на современных общеизвестных авторах, показав, что каждый из них обладает какими-либо особенностями в своём лингвистическом спектре.
Однако, моё время так было заполнено другими делами, что только летом 1915 г. я нашёл несколько свободных дней, чтобы составить лингвистические спектры хотя бы нескольких писателей. Я взял сначала Гоголя («Майскую ночь», «Страшную месть» и «Тараса Бульбу»), Пушкина («Капитанскую дочку», «Дубровского» и «Барышню-крестьянку»), Толстого («Смерть Ивана Ильича», «Корнея Васильева», «Три смерти» и «Три старца»), Тургенева («Малиновую воду»), Карамзина («Бедную Лизу») и Загоскина («Юрия Милославского»).
В каждом из этих рассказов я отсчитывал (исключая эпиграфы или вводные цитаты из посторонних авторов) первую тысячу слов, подчёркивая в ней красным карандашом все служебные частицы, а потом сосчитывал число каждой.[4]
Прежде всего сейчас же обнаружились некоторые резкие оригинальности.
У Карамзина в беллетристических произведениях очень часто употребляется восклицание «Ах!», почти совершенно отсутствующее у Гоголя, Пушкина, Толстого, Тургенева и Загоскина.
Служебная частица «было» (например, чуть-было) – только у Пушкина; «близ» – только у Тургенева (у других «около»); «ведь» – отсутствует у Карамзина и Загоскина; «вдруг» и «даже» – редки у Толстого; «еле» – только у Гоголя; «заместо» – только у Тургенева; «ибо» – ещё употребляется часто Карамзиным и Гоголем, изредка Пушкиным, но уже совсем отсутствует у Толстого, Тургенева и Загоскина; «коли» (вместо «если») – часто у Толстого в речи простых людей, но нет у Тургенева и у других; «может» (без «быть») – только у Гоголя; «нежели» – только у Пушкина; «оттого» – у Толстого; «про» (например, «про него») – довольно часто у Гоголя, Толстого и Пушкина и отсутствует у Тургенева и Загоскина; «против» – часто у Гоголя; «подле» (вместо «рядом») – у Загоскина; «среди» (вместо «между») – у Гоголя и Карамзина; «словно» – часто у Толстого; «точно» – у Тургенева; «через» – часто у Пушкина; «этак» – только у Гоголя.
А в числе употребляемых ими служебных частиц (союзов и предлогов) оказались ясные процентные различия (слоговые типы).
Чтоб не давать очень сложных общих спектров при нанесении этих цифр на графики, я разделил их здесь на предложные, союзные, местоименные спектры и т. д., судя по тому, что они представляют.
Наиболее часто повторяющимися оказались у всех русских авторов предлоги в, на[5]с, почему их графики я и назвал главным предложным спектром. Они даны на рис. 29[6], из которого читатель и без цифр видит по вертикальному ряду чисел, что на тысячу слов у Гоголя предлог в повторился в «Тарасе Бульбе» 23 раза, в «Майской ночи» 15, а в «Страшной мести» 16 раз; предлог на повторился 24 раза в «Майской ночи» и 26 в «Бульбе» и «Страшной мести» и т. д. А когда я соединил эти точки линиями, то во всех (взятых мною совершенно случайно) трёх произведениях Гоголя получились очень сходные ломаные линии в виде острых крыш с ясным преобладанием предлога на над бис (см. рис. 29). У Пушкина же во всех трёх (взятых мною также совершенно случайно) произведениях, наоборот, оказалось, на такую же тысячу слов, сильное преобладание предлога в над предлогами на и с, почти равными по частоте своего повторения.
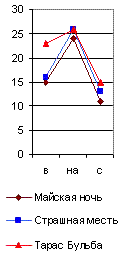

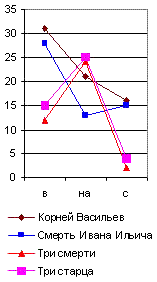

Рис. 29. Образчики главного предложного спектра. (На 1000 слов.)
Отсюда ясно, что по одному простому взгляду на главный предложный спектр какого-либо произведения Пушкина, по недоразумению приписанного Гоголю, мы заподозрили бы неправильность такого утверждения и сделали бы догадку о принадлежности его Пушкину, хотя ещё и не решили бы этим дела окончательно.
Действительно, сравнивая на нашей графике главный предложный спектр Пушкина с таким же спектром «Малиновой воды» Тургенева (в последней колонке рис. 29), мы видим, что они очень сходны, и потому для отличия Тургенева от Пушкина главный предложный спектр негоден и надо искать других.
Да и вообще нельзя решать вопроса об авторстве по какому-либо одному небольшому спектру, в роде взятого нами и состоящего лишь из трёх членов. Необходимо составить очень длинный многочленный спектр, или несколько коротких, но разнородных по своему содержанию спектров, и это тем более необходимо, что не всякий член спектра абсолютно постоянен у данного автора по частоте своего употребления. Здесь в полной мере господствует закон случайных отклонений от средней нормы, дающей вместо средней частоты употребления вариационную с размахом АВ, который, однако, тем более суживается, чем больше тысяч слов отсчитано нами в исследуемом отрывке, т. е. если при числе N слов (рис. 30) вариационный криволинейный треугольник будет иметь вид АВС, то при числе 2N слов он получит вид A1В1C1, а при большем числе слов его основание ещё больше сузится за счёт вырастающей высоты, так как площадь его всегда одна и та же, если перечислена на промилли (пли на проценты).
Рис. 30. Широкая или узкая вариационная дуга вероятных отступлений многократно повторяющихся фактов от средней нормы, при малом или большом количестве их подсчитанных повторений.
Но и при меньшем числе слов неправильное определение по причине значительной величины вероятной ошибки возможно лишь тогда, когда мы исследуем только три-четыре распорядительные частицы, а при десятке их всегда обнаружится общий характер лингвистического спектра для данного писателя.
Особенно обязательно это для старых авторов рукописного периода, которые не могли десятки раз «исправлять свой слог в корректурах», заменяя другими как раз те распорядительные частицы, которые для них слишком привычны.
Очень интересно отметить, например, что те самые члены главного предложного спектра (в, на, с), которые обнаружили постоянство у Пушкина и у Гоголя, совсем не обнаруживают этого у Толстого, и главный предложный спектр у него является в двух вариациях. Первая (например, в «Смерти Ивана Ильича» и в «Корнее Васильеве») напоминает спектр Пушкина, хотя и с несравненно меньшим числом частицы в (рис. 29), а вторая вариация (например, в «Трёх смертях» и «Трёх старцах») напоминает Гоголя, но с несравненно меньшим числом предлога с.
Здесь является вопрос: отчего зависит это расчленение главного лингвистического спектра Толстого на два типа? Оттого ли, что он сильно корректировал свои произведения и этим сделал свой главный предложный спектр неопределённым, пли те перевороты, которые он переживал в своём мировоззрении и направлении своего творчества, отзывались и на слоге его речи? Конечно, у каждого автора, писавшего более полувека, лингвистический спектр не может оставаться всё время совершенно неизменным. Он должен подвергаться медленной эволюции, как и световые спектры физических тел, изменяющиеся по мере повышения температуры. Однако, у Толстого обе вариации так резко различились на приведённых мною графиках, что наводят на мысль о специальной корректурной обработке автором их частоты, и исследование в этом отношении всех других его произведений является в высшей степени желательным.
Перейдём теперь к другим спектрам тех же писателей в тех же их произведениях. Рассмотрим, например, один из многих возможных союзных спектров (рис. 31). Я взял для его составления, как видно по таблице, сначала союз а, затем союз и, когда он употребляется в выражениях в роде «был и он», «я и знал», т. е. служит не обозначением конца перечня, а чисто слоговой приставкой, вследствие чего я и поставил его в кавычках («и»). Затем я взял тот же союз и в начале фраз, когда он пишется с большой буквы. В спектре Библии этот член дал бы преобладание над предыдущими, а у взятых мною писателей он всегда в минимуме, как видно по его графике. Этот спектр тоже оказался различен у них всех. У Гоголя и Пушкина здесь преобладает слоговое «и», у Толстого же «а»; кроме того, Пушкин отличается от Гоголя почти полным отсутствием библейского предфразного И (как оно употребляется во фразах в роде: «И был вечер, и было утро», «И пошёл Иисус» и т. д.).



Рис. 31. Один из союзных спектров.
Спектр пз наиболее часто встречающихся местоимений: этот, свой, тот оказался уже несоставимым у современных писателей при подсчёте только одной тысячи слов, так как этих местоимений у них оказалось лишь по нескольку на тысячу, а малое количество повторений какого-либо случайного фактора, как известно из статистики, не даёт возможности для вывода в нём закономерностей, благодаря уже отмеченному мною закону случайных отклонений от средней нормы тем более широких, чем меньше взято слов для подсчёта. Для того, чтобы местоименные и другие спектры дали достаточно типичные графики, нужно подсчитать их число по крайней мере среди пяти тысяч слов (а потом разделить полученную цифру на пять, с целыо приведения их к однородности с вышеприведёнными спектрами).
Но, даже и при значительной частоте повторения некоторых служебных частиц речи, могут обнаруживаться, как мы уже видели у Толстого, значительные колебания их числа в различных произведениях того же самого автора, если мы будем брать всего лишь тысячу слов. Образчиком такого неопределённого спектра является, между прочим, и приводимый мною на рис. 32, где я сопоставил отрицательную частицу не с союзом и, в его двух вариациях: первая (и') соединяет между собою существительные или прилагательные имена, вторая (и") – глаголы или пелые фразы. Мы видим, что колебания их числа в различных произведениях у того же самого автора настолько же резки, как и у двух различных писателей. Однако и тут могут найтись авторы, у которых этот спектр обнаружит явное постоянство во всех произведениях.


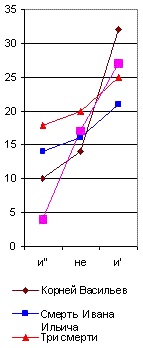
Рис. 32. Спектр и"-не-и'.
Все лингвистические спектры, где, как у предыдущих, лишь высчитывается прямое среднее число той или другой служебной частицы на тысячу слов, можно назвать естественными. Они не всегда удобны для наглядного выражения слоговой физиономии автора и, кроме того, с ними надо уметь обращаться при их подборе для спектра. Составьте, например, спектр из каких-либо двух часто употребляемых служебных частиц и из одной мало употребительной. Поставив её на графике в середине между двумя первыми, вы получите всегда фигуру в роде V, в которой сольются все индивидуальные особенности слога различных авторов. Но особенности каждого из них станут ясно определёнными, когда мы расположим все такие частицы не в случайном порядке, а по мере уменьшения или по мере увеличения их средней употребимости у писателей данной эпохи. Так я и сделал в предыдущих таблицах, иначе мои графики обнаружили бы лишь ложное сходство.
Канал с обзорами, анонсами новинок и книжными подборками
 Книжный Вестник
Книжный Вестник
Бот для удобного поиска книг (если не нашлось на сайте)
 Поиск книг
Поиск книг
Свежие любовные романы в удобных форматах
 Любовные романы
Любовные романы
О психологии, саморазвитии и личностном росте
 Саморазвитие
Саморазвитие
Детективы и триллеры, все новинки
 Детективы
Детективы
Фантастика и фэнтези, все новинки
 Фантастика
Фантастика
Отборные классические книги
 Классика
Классика
 ВКОНТАКТЕ
ВКОНТАКТЕБиблиотека с любовными романами, которая наверняка придётся по вкусу женской части аудитории
Любовные романы
Библиотека с фантастикой и фэнтези, а также смежных жанров
Фантастика
Самые популярные книги в формате фб2
Топ фб2
книги