Глава 8 Дополнительные элементы и функции языка XSLT
Глава 8Дополнительные элементы и функции языка XSLT
Дополнительные элементы и функции
В этой главе разбираются дополнительные элементы и функции языка XSLT, которые выполняют в преобразованиях различные задачи, непосредственно не связанные с созданием узлов выходящего документа. Дополнительные элементы и функции XSLT расширяют возможности преобразования, предоставляя разного рода вспомогательный сервис.
К дополнительным элементам XSLT мы отнесем следующие:
□
xsl:preserve-space
и
xsl:strip-space
— работа с пробельными символами;
□
xsl:message
— сообщения процессора;
□
xsl:sort
— сортировка множеств перед обработкой;
□
xsl:namespace-alias
— определение псевдонимов пространств имен;
□
xsl:key
— определение ключей;
□
xsl:number
— нумерация;
□
xsl:decimal-format
— определение десятичного формата;
□
xsl:output
— контроль сериализации.
В XSLT также определяются дополнительные функции, расширяющие базовую библиотеку функций XPath:
□
key
— использование ключей;
□
format-number
— форматирование чисел;
□
document
— обращение к внешним документам;
□
current
— обращение к текущему узлу преобразования;
□
unparsed-entity-uri
— получение URI неразбираемой сущности по ее имени;
— получение информации о свойствах системы, окружения.
Обработка пробельных символов
В XSLT выделяются четыре пробельных символа, обработка которых несколько отличается от обработки других символов. Их Unicode-коды и описания сведены в табл. 8.1.
Таблица 8.1. Unicode-коды пробельных символов
Unicode-коды
Описание
Десятичный
Шестнадцатеричный
#9
#x9
Горизонтальная табуляция
#10
#xA
Перевод строки
#13
#xD
Возврат каретки
#32
#x20
Пробел
Отличие обработки пробельных символов заключается в том, что после разбора и создания логической модели для входящего документа и для самого преобразования, узлы, которые содержат только пробельные символы, будут удалены из дерева.
Поскольку текстовые узлы этого шаблона содержат только пробельные символы, они будут удалены из дерева преобразования, и результат будет иметь вид:
Вообще, текстовый узел будет сохранен при выполнении хотя бы одного из следующих условий.
□ Он содержит хотя бы один непробельный символ.
□ Он принадлежит элементу, в котором сохранение пробельных символов задано средствами XML, а именно атрибутом
xml:space
со значением
preserve
.
□ Он принадлежит элементу, имя которого включено во множество имен элементов, для которых нужно сохранять пробельные символы.
Во всех остальных случаях текстовый узел будет удален.
Продемонстрируем все три случая сохранения текстового узла на примерах.
Первый случай довольно прост. Шаблон
¶
¶
□□¶
¶
создаст в выходящем документе фрагмент
<а/>
безо всяких пробельных символов, в то время как шаблон
¶
¶
□□||¶
¶
создаст фрагмент вида
¶
¶
□□||¶
¶
Различие двух этих шаблонов в том, что в первом текстовые узлы содержат текст "
¶ ¶ □□
" и "
¶ ¶
" соответственно, а во втором — "
¶ ¶ □□|
" и "
| ¶ ¶
". Текстовые узлы второго шаблона не будут удалены, поскольку они содержат непробельные символы (символы "
|
").
Второй случай сохранения текстовых узлов основан на использовании возможностей XML по управлению пробельными символами. Если в элементе задан атрибут
xml:space
со значением
"preserve"
, обрабатывающее программное обеспечение должно сохранять в нем и в его потомках пробельные символы. Единственным исключением из этого правила может быть опять же атрибут
xml:space
, заданный в элементе-потомке со значением
"default"
.
Пример
Шаблон
¶
□□<а>¶
□□□□¶
□□□□□□¶
□□□□□□□□¶
□□□□□□¶
□□□□¶
□□¶
создаст в выходящем документе фрагмент вида:
Если же шаблон будет определен в виде:
¶
□□<а xml:space="preserve">¶
□□□□¶
□□□□□□¶
□□□□□□□□¶
□□□□□□¶
□□□□¶
□□¶
то в выходящем фрагменте в элементах
а
и
b
пробельные символы будут сохранены, а в элементах
с
и
d
— удалены:
<а xml:space="preserve">¶
□□□□¶
□□□□□□¶
□□□□¶
□□
В третьем случае сохранение пробельных символов текстового узла зависит от того, принадлежит ли имя родительского элемента особому множеству, называемому множеством имен элементов, для которых следует сохранять пробельные символы или, для краткости, сохраняющее множество.
Для преобразований сохраняющее множество состоит из единственного элемента
xsl:text
, то есть единственный элемент в преобразовании, для которого пробельные текстовые узлы не будут удаляться, — это элемент
xsl:text
. Поэтому его часто используют для вывода в выходящем документе пробельных символов.
Для входящих документов сохраняющее множество состоит из имен всех элементов. То есть по умолчанию преобразования сохраняют все пробельные текстовые узлы. Для изменения сохраняющего множества элементов входящего документа используются элементы
xsl:preserve-space
и
xsl:strip-space
.
Элементы xsl:preserve-space и xsl:strip-space
Синтаксические конструкции этих элементов очень похожи:
elements="токены"/>
elements="токены"/>
Элемент
xsl:preserve-space
добавляет, a
xsl:strip-space
удаляет имя элемента из сохраняющего множества входящего документа.
Пример
Предположим, нам нужно сохранять пробельные символы во всех элементах
d
и удалять их в элементах
с
. Тогда в преобразовании достаточно указать
Вообще, обязательные атрибуты elements элементов
xsl:strip-space
и
xsl:preserve-space
содержат не сами имена элементов, а так называемые проверки имен. Проверка имени имеет три варианта синтаксиса.
□ Синтаксис
"*"
используется для выбора произвольных имен. Ей будут соответствовать любые имена элементов.
□ Синтаксис
"имя"
используется для выбора элементов с заданным именем. К примеру, проверке имени
"d"
будут соответствовать все элементы с именем "
d
".
□ Синтаксис
"префикс:*"
используется для выбора всех элементов в данном пространстве имен. К примеру, если в документе определен префикс пространства имен
upr
в виде атрибута
xmlns:upr="http://www.upr.com"
, проверке имени
"upr:*"
будут соответствовать все элементы пространства имен, определяемого идентификатором
"http://www.upr.com"
.
Пример
Предположим, что нам необходимо сохранить пробельные символы в элементе с именем
с
и удалить их в элементе
e
и элементах, принадлежащих пространству имен, определяемому идентификатором "
По большому счету, мы не можем контролировать процесс преобразования. Процессор может сам выбирать, как и в какой последовательности он будет выполнять те или иные шаблоны — таковы особенности декларативного программирования. Вместе с тем мы все-таки можем получить кое-какую информацию о ходе преобразования, используя механизм, называемый в XSLT сообщениями.
Элемент xsl:message
Синтаксис этого элемента дан ниже:
terminate="yes" | "no">
Элемент
xsl:message
указывает процессору на то, что он должен вывести сообщение, которое является результатом обработки шаблона, содержащегося в этом элементе. Механизм вывода сообщения зависит от реализации того или иного процессора и может быть различным — от вывода текста сообщения на экран до вызова внешнего модуля для обработки сообщения.
Пример
Иногда в процессе отладки преобразования бывает полезно выводить сообщения о том, какой элемент обрабатывается в данный момент.
Листинг 8.5. Входящий документ
Листинг 8.6. Преобразование
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
Processing element
which has a parent element
.
Листинг 8.7. Выходящий документ
Листинг 8.8. Сообщения процессора
Processing element a.
Processing element b which has a parent element a.
Processing element с which has a parent element b.
Processing element d which has a parent element c.
Атрибут
terminate
указывает на то, должен ли процессор прекратить дальнейшую обработку документа или нет. Значением этого атрибута по умолчанию является
"no"
, что означает, что процессор должен просто вывести сообщения и продолжать дальнейшее выполнение шаблона. Если же в
xsl:message
указано
terminate="yes"
, то процессор, выведя сообщение, прервет обработку. Этот прием может использоваться, например, для того, чтобы проверять входящие документы на соответствие определенной схеме.
Пример
При помощи
xsl:message
мы можем запретить обработку документов, которые не имеют в корне элемент с именем
"html"
в любом регистре символов.
Листинг 8.9. Шаблон преобразования
Document has no root HTML element.
Если мы будем обрабатывать документ вида
обработка не будет прервана, в то время как преобразование документа
будет прервано сообщением:
Document has no root HTML element:
Processing terminated using xsl:message
Сортировка
При преобразовании документа элементами
xsl:for-each
и
xsl:apply-templates
, выбранные узлы по умолчанию обрабатываются в порядке просмотра документа, который зависит от выражения, использованного в атрибуте
select
этих элементов. XSLT позволяет изменять этот порядок посредством использования механизма сортировки.
Элементы
xsl:for-each
и
xsl:apply-templates
могут содержать один или несколько элементов
xsl:sort
, которые позволяют предварительно сортировать обрабатываемое множество узлов.
Элемент xsl:sort
Синтаксис этого элемента определяется в XSLT как:
select = "выражение"
lang = "язык"
data-type = "text" | "number" | "имя"
order = "ascending" | "descending"
case-order = "upper-first" | "lower-first" />
В случае если
xsl:for-each
и
xsl:apply-templates
содержат элементы
xsl:sort
, обработка множества узлов должна производиться не в порядке просмотра документа, а в порядке, который определяется ключами, вычисленными при помощи
xsl:sort
. Первый элемент
xsl:sort
, присутствующий в родительском элементе, определяет первичный ключ сортировки, второй элемент — вторичный ключ, и так далее.
Элемент
xsl:sort
обладает атрибутом
select
, значением которого является выражение, называемое также ключевым выражением. Это выражение вычисляется для каждого узла обрабатываемого множества, преобразуется в строку и затем используется как значение ключа при сортировке. По умолчанию значением этого атрибута является
"."
, что означает, что в качестве значения ключа для каждого узла используется его строковое значение.
После этих вычислений узлы обрабатываемого множества сортируются по полученным строковым значениям своих ключей и обрабатываются в новом порядке. Если ключи некоторых узлов совпадают, они могут быть в дальнейшем отсортированы вторичными и так далее ключами.
Элемент
xsl:sort
может иметь следующие необязательные атрибуты, которые указывают некоторые параметры сортировки.
□ Атрибут
order
определяет порядок, в котором узлы должны сортироваться по своим ключам. Этот атрибут может принимать только два значения —
"ascending"
, указывающее на восходящий порядок сортировки, и
"descending"
, указывающее на нисходящий порядок. Значением по умолчанию является
"ascending"
, то есть восходящий порядок.
□ Атрибут
lang
определяет язык ключей сортировки. Дело в том, что в разных языках символы алфавита могут иметь различный порядок, что, соответственно, должно учитываться при сортировке. Атрибут
lang
в XSLT может иметь те же самые значения, что и атрибут
xml:lang
(например:
"en"
,
"en-us"
,
"ru"
и т.д.). Если значение этого атрибута не определено, процессор может либо определять язык исходя из параметров системы, либо сортировать строки исходя из порядка кодов символов Unicode.
□ Атрибут
data-type
определяет тип данных, который несут строковые значения ключей. Техническая рекомендация XSLT разрешает этому атрибуту иметь следующие значения:
•
"text"
— ключи должны быть отсортированы в лексикографическом порядке исходя из языка, определенного атрибутом
lang
или параметрами системы;
•
"number"
— ключи должны сравниваться в численном виде. Если строковое значение ключа не является числом, оно будет преобразовано к не-числу (
NaN
), и, поскольку нечисловые значения неупорядочены, соответствующий узел может появиться в отсортированном множестве где угодно;
•
"имя"
— в целях расширяемости XSLT также позволяет указывать в качестве типа данных произвольное имя. В этом случае реализация сортировки полностью зависит от процессора;
• значением атрибута
data-type
по умолчанию является
"text"
.
□ Атрибут
case-order
указывает на порядок сортировки символов разных регистров. Значениями этого атрибута могут быть
"upper-first"
, что означает, что заглавные символы должны идти первыми, или
"lower-first"
, что означает, что первыми должны быть строчные символы. К примеру, строки
"ночь"
,
"Улица"
,
"фонарь"
,
"Аптека"
,
"НОЧЬ"
,
"Фонарь"
при использовании
case-order="upper-first"
будут иметь порядок
"Аптека"
,
"НОЧЬ"
,
"ночь"
,
"Фонарь"
,
"фонарь"
,
"улица"
. При использовании
case-order="lower-first"
те же строки будут идти в порядке
"Аптека"
,
"ночь"
,
"НОЧЬ"
,
"фонарь"
,
"Фонарь"
,
"улица"
. Значение
case-order
по умолчанию зависит от процессора и языка сортировки. В большинстве случаев заглавные буквы идут первыми.
Как можно видеть, элемент
xsl:sort
определяет сортировку достаточно гибко, но вместе с тем не следует забывать, что эти возможности могут быть реализованы в процессорах далеко не полностью. Поэтому одна и та же сортировка может быть выполнена в разных процессорах по-разному.
Приведем простой пример сортировки имен и фамилий.
Рассмотрим пример.
Листинг 8.10. Входящий документ
William
Gibson
William
Blake
John
Fowles
Отсортируем этот список сначала по именам в убывающем, а затем по фамилиям в возрастающем порядке.
Листинг 8.12. Выходящий документ
William
Blake
William
Gibson
John
Fowles
К сожалению, сортировкой нельзя управлять динамически. Все атрибуты элемента
xsl:sort
должны обладать фиксированными значениями.
Псевдонимы пространств имен
Любопытным фактом является то, что XML-документ, являющийся результатом выполнения XSLT-преобразования, может и сам быть XSLT- преобразованием. Иными словами, преобразования могут генерироваться другими преобразованиями. В некоторых случаях такая возможность будет очень полезна, например, входящий XML-документ может описывать преобразование, которое нужно сгенерировать.
Приведенный выше документ описывает преобразование, которое должно удалять из входящего документа элементы
а
, а элементы
b
и
c
заменять элементами
B
и
C
соответственно. Такое преобразование может выглядеть следующим образом.
Листинг 8.14. Преобразование
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
Преобразование, генерирующее такой код, не представляет особой сложности. Например, шаблон для обработки элемента replace может иметь следующий вид:
Шаблон этот выглядит очень громоздко, потому что мы не могли просто включить в него создаваемое правило: поскольку мы создаем элементы в пространстве имен XSLT, находясь в шаблоне, они воспринимались бы не как генерируемые, а как принадлежащие генерирующему преобразованию. Очевидно, что шаблон вида
был бы некорректен. По этой причине нам пришлось генерировать все инструкции при помощи
xsl:element
и
xsl:attribute
, что сделало шаблон громоздким и малопонятным.
Если внимательно рассмотреть проблему, то окажется, что она состоит в том, что мы хотим в преобразовании использовать элементы одного пространства имен так, как если бы они относились к другому пространству.
К счастью, XSLT предоставляет легкий и удобный способ для решения такого рода задачи: пространству имен можно назначить псевдоним при помощи элемента
xsl:namespace-alias
.
Элемент xsl:namespace-alias
Синтаксическая конструкция этого элемента выглядит следующим образом:
stylesheet-prefiх="префикс" | "#default"
result-prefix="префикс" | "#default"/>
Элемент
xsl:namespace-alias
назначает пространству имен выходящего документа пространство имен, которое будет подменять его в преобразовании, иначе говоря — псевдоним.
указывает, какое пространство имен будет использоваться в качестве его псевдонима в преобразовании. Оба атрибута содержат префиксы пространств имен, которые, естественно, должны быть ранее объявлены в преобразовании.
Пример
Возвращаясь к генерации преобразования, мы можем изменить пространство имен генерируемых элементов так, чтобы они не воспринимались процессором как элементы XSLT. Для того чтобы в выходящем документе эти элементы все же принадлежали пространству имен XSLT, измененное пространство имен в преобразовании должно указываться как псевдоним этого пространства.
указывает на то, что все элементы, принадлежащие в преобразовании пространству имен с URI
http://www.w3.org/1999/XSL/Transform/Alias
в выходящем документе должны принадлежать пространству имен с URI
http://www.w3.org/1999/XSL/Transform
то есть пространству имен XSLT.
Результатом применения этого преобразования к документу из листинга 8.13 будет следующий документ.
Листинг 8.16. Выходящее преобразование
version="1.0"
xmlns:axsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
В этом сгенерированном преобразовании элементы имеют префикс
axsl
, но при этом принадлежат пространству имен XSLT.
Атрибуты
stylesheet-prefix
и
result-prefix
элемента
xsl:namespace-alias
могут иметь значения
"#default"
. Определение вида
stylesheet-prefix="a"
result-prefix="#default"/>
означает, что элементы, принадлежащие в преобразовании пространству имен
а
, в выходящем документе должны принадлежать пространству имен по умолчанию. Определение вида
stylesheet-prefix="#default"
result-prefix="a"/>
означает, что элементы, принадлежащие в преобразовании пространству имен по умолчанию, в выходящем документе должны принадлежать пространству имен
а
.
Пример
Листинг 8.17. Преобразование
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:a="urn:a"
xmlns="urn:b">
stylesheet-prefix="#default"
result-prefix="a"/>
stylesheet-prefix="a"
result-prefix="#default"/>
Листинг 8.18. Выходящий документ
Результатом этого преобразования является то, что пространство имен с URI
"urn:а"
стало пространством имен по умолчанию, а пространство имен с URI
"urn:b"
изменило префикс на
а
.
В преобразованиях можно объявлять несколько псевдонимов пространств имен при условии, что одно и то же пространство имен преобразования не должно быть объявлено элементами
xsl:namespace-alias
с одинаковым порядком импорта псевдонимом для различных пространств имен выходящего документа.
Пример
Если преобразование
a.xsl
содержит определение
stylesheet-prefix="x"
result-prefix="a"/>
а преобразование
b.xsl
— определение
stylesheet-prefix="x"
result-prefix="b"/>
где в обоих преобразованиях префикс
x
представляет одно пространство имен, а пространства имен
a
и
b
— разные, то преобразование
a.xsl
не сможет включать преобразование
b.xsl
и наоборот, потому что они будут иметь одинаковый порядок импорта и содержать элементы
xsl:namespace-alias
, назначающие разным пространствам имен одинаковые псевдонимы. В одном преобразовании такие псевдонимы также не имеют права встречаться. Если же подобное все же случилось, процессор может сигнализировать ошибку или использовать определение, которое было дано в преобразовании последним.
Совсем иначе обстоит дело с импортированием. При импортировании определения старших в порядке импорта преобразований могут переопределять определения младших преобразований. Таким образом, если преобразование
a.xsl
будет импортировать преобразование
b.xsl
, пространство имен
x
будет назначено псевдонимом пространству имен
а
и наоборот.
Ключи
Прежде чем мы приступим к разбору ключей, которые являются одной из самых мощных концепций языка XSLT, попробуем решить одну несложную задачку.
Листинг 8.19. Входящий документ
Пусть входящий документ представляет собой список объектов (элементов
item
), каждый из которых имеет имя (атрибут
name
) и источник (атрибут
source
). Требуется сгруппировать объекты по своим источникам и получить документ приблизительно следующего вида.
Листинг 8.20. Требуемый результат
Первым шагом на пути решения этой задачи является формулировка в терминах XSLT предложения "сгруппировать объекты по своим источникам". Источник каждого объекта определяется его атрибутом
source
, значит множество объектов, принадлежащих одному источнику
"а"
, будет определяться путем выборки
/items/item[@source='a']
Тогда для каждого элемента
item
в его группу войдут элементы, которые будут выбраны выражением
/items/item[@source=current()/@source]
Попробуем использовать этот факт в следующем шаблоне:
Как и ожидалось, при применении этого правила к элементам
item
для каждого из них будет создана группа, принадлежащая тому же источнику, — уже хороший результат, но в условии требуется создать по группе не для каждого объекта, а для каждого источника. Чтобы достичь этого, можно создавать группу только для первого объекта, принадлежащего ей. Провести такую проверку опять же несложно: объект будет первым в группе тогда и только тогда, когда ему не предшествуют другие, элементы
item
, принадлежащие тому же источнику. Иначе говоря, создаем группы только для тех элементов, для которых выражение
Бесспорно, решение было несложным, но довольно громоздким. Самым же узким местом в этом преобразовании является обращение к элементам
item
источника текущего элемента посредством сравнения атрибутов
source
.
Проблема совершенно стандартна для многих преобразований: нужно выбирать узлы по определенным признакам, причем делать это нужно как можно более эффективно. Хорошо, что в нашем документе было всего восемь элементов
item
, но представьте себе ситуацию, когда элементов действительно много.
Проблема, которую мы подняли, достаточно серьезна. Она состоит в оптимизации поиска узлов с определенными свойствами в древовидно организованной структуре.
Попробуем разобраться в смысле фразы "узел обладает определенными свойствами". Очевидно, это означает, что для этого узла выполняется некое логическое условие, иначе говоря, некий предикат обращается в "истину".
Однако какого именно типа условия мы чаще всего проверяем? Анализируя различные классы задач, можно придти к выводу, что в большинстве случаев предикаты являются равенствами — выражениями, которые обращаются в "истину" тогда и только тогда, когда некоторый параметр узла, не зависящий от текущего контекста, равен определенному значению. В нашем примере смысл предиката на самом деле состоит не в том, чтобы проверить на истинность выражение
@source=current()/@source
, а в том, чтобы проверить на равенство
@source
и
current()/@source
.
Если переформулировать это для общего случая, то нам нужно выбрать не те узлы, для которых истинно выражение
A=B
, скорее нужно выбрать те, для которых значение
A
равно значению
B
. Иначе говоря, узел будет идентифицироваться значением в своего свойства
A
. И если мы заранее вычислим значения свойств
A
, проблема поиска узлов в дереве сведется к классической проблеме поиска элементов множества (в нашем случае — узлов дерева) по определенным значениям ключей (в нашем случае — значениями свойств
A
).
Чтобы пояснить это, вернемся к нашему примеру: мы ищем элементы
item
со значением атрибута
source
, равным заданному. Свойством, идентифицирующим эти элементы, в данном случае будут значения их атрибутов
source
, которые мы можем заранее вычислить и включить в табл. 8.2.
Таблица 8.2. Значения атрибута
source
элементов
item
Идентификатор (значение атрибута
source
)
Элемент
item
a
a
a
b
b
b
с
с
Таким образом, значение
"с"
идентифицирует объекты с именами
D
и
G
, а значение
"а"
— объекты с именами
A
,
C
и
H
, причем находить соответствующие элементы в таблице по их ключевому свойству не составляет никакого труда.
Несмотря на то, что произведенные нами манипуляции чрезвычайно просты (и настолько же эффективны), процессор вряд ли в общем случае сможет сделать что-либо подобное сам, и потому очень важной является возможность явным образом выделять в XSLT-преобразованиях ключевые свойства множеств узлов.
В этом разделе мы будем рассматривать две конструкции, позволяющие манипулировать множествами узлов посредством ключей — это элемент
xsl:key
, который определяет в преобразовании именованный ключ, и функция
key
, которая возвращает множество узлов, идентифицирующихся заданными значениями ключей.
Элемент xsl:key
Синтаксис элемента несложен:
name="имя"
match="паттерн"
use="выражение"/>
Элемент верхнего уровня
xsl:key
определяет в преобразовании ключ именем, заданным в значении атрибута
name
, значением которого для каждого узла документа, соответствующего паттерну
match
, будет результат вычисления выражения, заданного в атрибуте
use
. Ни атрибут
use
, ни атрибут
match
не могут содержать переменных.
Пример
В нашем примере элементы
item
идентифицируются значениями своих атрибутов
source
. Для их идентификации мы можем определить ключ с именем
src
следующим образом:
Следуя строгому определению, данному в спецификации языка, ключом называется тройка вида
(node, name, value)
, где
node
— узел,
name
— имя и
value
— строковое значение ключа. Тогда элементы
xsl:key
, включенные в преобразование, определяют множество всевозможных ключей обрабатываемого документа. Если этому множеству принадлежит ключ, состоящий из узла
x
, имени
у
и значения
z
, говорят, что узел
x
имеет ключ с именем
у
и значением
z
или что ключ
у
узла
x
равен
z
.
Пример
Ключ
src
из предыдущего примера определяет множество, которое состоит из следующих троек:
(<item name="A".../>, 'src', 'a')
(<item name="B".../>, 'src', 'b')
(<item name="C".../>, 'src', 'a')
(<item name="D".../>, 'src', 'c')
...
(<item name="H".../>, 'src', 'a')
В соответствии с нашими определениями мы можем сказать, что элемент
имеет ключ с именем
"src"
и значением
"b"
или что ключ
"src"
элемента
равен
"a"
.
Для того чтобы обращаться к множествам узлов по значениям их ключей, в XSLT существует функция
key
, о которой мы сейчас и поговорим.
Функция key
Ниже приведена синтаксическая конструкция данной функции:
node-set key(string, object)
Итак, элементы
xsl:key
нашего преобразования определили множество троек
(node, name, value)
. Функция
key(key-name, key-value)
выбирает все узлы x такие, что значение их ключа с именем
key-name
(первым аргументом функции) равно
key-value
(второму аргументу функции).
Пример
Значением выражения
key('src', 'a')
будет множество элементов
item
таких, что значение их ключа
"src"
будет равно
"а"
. Попросту говоря, это будет множество объектов источника
"а"
.
Концепция ключей довольно проста, и существует великое множество аналогий в других языках программирования: от хэш-функций до ключей в реляционных таблицах баз данных. По всей вероятности, читателю уже встречалось что-либо подобное.
Но не следует забывать, что язык XSLT — довольно нетрадиционный язык и с точки зрения синтаксиса, и с точки зрения модели данных. Как следствие, ключи в нем имеют довольно много скрытых нюансов, которые очень полезно знать и понимать. Мы попытаемся как можно более полно раскрыть все эти особенности.
Определение множества ключей
Не представляет особой сложности определение множества ключей в случае, если в определении они идентифицируются строковыми выражениями. Например, в следующем определении
атрибут
use
показывает, что значением ключа
src
элемента
item
будет значение атрибута
source
. Но что можно сказать о следующем определении:
Очевидно, это уже гораздо более сложный, но, тем не менее, вполне реальный случай, не вписывающийся в определения, которые давались до сих пор. Мы говорили лишь о том, что множество ключей определяется элементами
xsl:key
преобразования, но как именно оно определяется — оставалось доселе загадкой. Восполним этот пробел, дав строгое определение множеству ключей.
Узел
x
обладает ключом с именем
у
и строковым значением
z
тогда и только тогда, когда в преобразовании существует элемент
xsl:key
такой, что одновременно выполняются все нижеперечисленные условия:
□ узел
x
соответствует паттерну, указанному в его атрибуте
match
;
□ значение его атрибута
name
равно имени
y
;
□ результат
u
вычисления выражения, указанного в значении атрибута
use
в контексте текущего множества, состоящего из единственного узла
x
, удовлетворяет одному из следующих условий:
•
u
является множеством узлов и
z
равно одному из их строковых значений;
•
u
не является множеством узлов и
z
равно его строковому значению.
Без сомнения, определение не из простых. Но как бы мы действовали, если бы физически создавали в памяти множество ключей? Ниже представлен один из возможных алгоритмов:
□ для каждого элемента
xsl:key
найти множество узлов документа, удовлетворяющих его паттерну
match
(множество
X
);
□ для каждого из найденных узлов (
x
∈
X
) вычислить значение выражения атрибута
use
(значение
u(x)
);
□ если
u(x)
является множеством узлов (назовем его
Uх
), то для каждого
uxi
∈
Uх
создать ключ
(x, n, string(uxi))
, где
n
— имя ключа (значение атрибута
name
элемента
xsl:key
);
□ если
u(x)
является объектом другого типа (назовем его
ux
), создать ключ
(x, n, string(ux))
.
Пример
Найдем множество ключей, создаваемое определением
Имена всех ключей будут одинаковы и равны
"src"
. Множество
x
узлов, удовлетворяющих паттерну
item
, будет содержать все элементы
item
обрабатываемого документа. Значением выражения, заданного в атрибуте use, будет множество всех узлов атрибутов каждого из элементов
item
. Таким образом, множество узлов будет иметь следующий вид:
(<item name="А".../>, 'src', 'a')
(<item name="А".../>, 'src', 'A')
(<item name="В".../>, 'src', 'b')
(<item name="В".../>, 'src', 'В')
(<item name="С".../>, 'src', 'а')
(<item name="С".../>, 'src', 'С')
(<item name="D".../>, 'src', 'с')
(<item name="D".../>, 'src', 'D')
...
(<item name="H".../>, 'src', 'a')
(<item name="H".../>, 'src', 'H')
В итоге функция
key('src', 'a')
будет возвращать объекты с именами
A
,
C
и
H
, а функция
key('src', 'A')
— единственный объект с именем
A
(поскольку ни у какого другого элемента
item
нет атрибута со значением
"A"
).
Необходимо сделать следующее замечание: совершенно необязательно, чтобы процессор действительно физически создавал в памяти множества ключей. Это множество определяется чисто логически — чтобы было ясно, что же все-таки будет возвращать функция
key
. Процессоры могут вычислять значения ключей и искать узлы в документе и во время выполнения, не генерируя ничего заранее. Но большинство процессоров, как правило, все же создают в памяти определенные структуры для манипуляций с ключами. Это могут быть хэш-таблицы, списки, простые массивы или более сложные нелинейные структуры, упрощающие поиск, — важно другое. Важно то, что имея явное определение ключа в
xsl:key
, процессор может производить такую оптимизацию.
Использование нескольких ключей в одном преобразовании
В случае, когда к узлам в преобразовании нужно обращаться по значениям различных свойств, можно определить несколько ключей — каждый со своим именем. Например, если мы хотим в одном случае обращаться к объектам, принадлежащим одному источнику, а во втором — к объектам с определенными именами, мы можем определить в документе два ключа — один с именем
src
, второй — с именем
name
:
Множество ключей, созданных этими двумя определениями, будет выглядеть следующим образом:
(<item name="А".../>, 'src', 'а')
(<item name="А".../>, 'name', 'А')
(<item name="В".../>, 'src', 'b')
(<item name="В".../>, 'name', 'В')
(<item name="C".../>, 'src', 'a')
(<item name="C".../>, 'name', 'С')
(<item name="D".../>, 'src', 'с')
(<item name="D".../>, 'name', 'D')
...
(<item name="H".../>, 'src', 'a')
(<item name="H".../>, 'name', 'H')
В этом случае функция
key('src', 'а')
возвратит объекты с именами
A
,
C
и
H
, а функция
key('name', 'а')
— объект с именем
А
.
Имя ключа является расширенным именем. Оно может иметь объявленный префикс пространства имен, например
name="data:src"
match="item"
use="@source"
xmlns:data="urn:user-data"/>
В этом случае функция
key(key-name, key-value)
будет возвращать узлы, значение ключа с расширенным именем
key-name
которых равно
key-value
. Совпадение расширенных имен определяется как обычно — по совпадению локальных частей и URI пространств имен.
Использование нескольких определений одного ключа
Процессор должен учитывать все определения ключей данного преобразования — даже если некоторые из них находятся во включенных или импортированных модулях. Порядок импорта элементов
xsl:key
не имеет значения: дело в том, что определения ключей с одинаковыми именами для одних и тех же узлов, но с разными значениями ключа не переопределяют, а дополняют друг друга.
Пример
Предположим, что в нашем документе имеется несколько элементов
item
, в которых не указано значение атрибута
source
, но по умолчанию мы будем причислять их к источнику
а
. Соответствующие ключи будут определяться следующим образом:
To есть для тех элементов
item
, у которых есть атрибут
source
, значением ключа будет значение этого атрибута, для тех же элементов, у которых атрибута
source
нет, его значением будет
"а"
.
Для входящего документа вида
...
соответствующее множество ключей будет определяться следующим образом:
(<item name="А".../>, 'src', 'а')
(<item name="В".../>, 'src', 'b')
(<item name="С".../>, 'src', 'а')
(<item name="D".../>, 'src', 'c')
...
(<item name="H".../>, 'src', 'a')
(<item name="I".../>, 'src', 'a')
(<item name="J".../>, 'src', 'a')
(<item name="K".../>, 'src', 'a')
Функция
key('src', 'a')
возвратит объекты с именами
A
,
C
,
H
,
I
,
J
и
K
.
То, что одни и те же узлы могут иметь разные значения одного ключа, является также очень удобным свойством. Например, два определения ключей, приведенные выше, можно дополнить третьим:
Это определение позволит по значению
"#default"
обращаться к объектам, принадлежащим источнику по умолчанию.
Использование множеств узлов в функции key
Функция
key
принимает на вход два аргумента: первым аргументом является строка, задающая имя ключа, в то время как вторым аргументом может быть объект любого типа. В том случае, если аргумент
key-value
в функции
key(key-name, key-value)
является множеством узлов, функция
key
возвратит все узлы, имеющие ключ
key-name
со значением, равным хотя бы одному из строковых значений узла множества
key-value
.
Пример
Предположим, что источники объектов будут сгруппированы следующим образом:
Для того чтобы вычислить множество элементов
item
, принадлежащих любому из источников данной группы, достаточно будет воспользоваться выражением вида
key('src', sources/source/@name)
Множество узлов, выбираемое путем
sources/source/@name
, будет содержать атрибуты
name
элементов
source
. Их строковые значения будут равны
а
и
с
, значит, наше выражение возвратит множество элементов
item
, значение атрибута
source
которых равно либо
а
либо
с
.
Использование ключей в нескольких документах
Ключи, определенные в преобразовании, могут использоваться для выбора узлов в различных обрабатываемых документах. Функция
key
возвращает узлы, которые принадлежат текущему документу, то есть документу, содержащему текущий узел. Значит, для того, чтобы выбирать узлы из внешнего документа, необходимо сделать текущим узлом один из узлов этого внешнего документа. Контекстный документ может быть легко изменен элементом
xsl:for-each
, например, для того, чтобы текущим документом стал документ
a.xml
, достаточно написать
Пример
Предположим, что нам нужно выбрать объекты, принадлежащие источнику
a
, причем принадлежность объектов определена в двух внешних документах,
a.xml
и
b.xml
.
Листинг 8.22. Входящий документ
Листинг 8.23. Документ a.xml
Листинг 8.24. Документ b.xml
Листинг 8.25. Преобразование
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
Листинг 8.26. Выходящий документ
Составные ключи
В теории реляционных баз данных существует такое понятие, как составной ключ. Согласно определению К. Дж. Дейта [Дейт 1999], составной ключ — это "потенциальный ключ; состоящий из более чем одного атрибута".
Хотя концепция ключей в XSLT сильно отличается от того, что называется ключом в реляционных БД, идея весьма и весьма интересна: использовать при обращении к множествам узлов не одно свойство, а некоторую их комбинацию.
Главная проблема состоит в том, что значение ключа в XSLT всегда является строкой, одним из самых примитивных типов. И выбирать множества узлов можно только по одному строковому значению за один раз. Ничего похожего на
key(key-name, key-value-1, key-value-2, ...)
для выбора узлов, первое свойство которых равно
key-value-1
, второе —
key-value-2
и так далее, XSLT не предоставляет.
Выход достаточно очевиден: если значение ключа не может быть сложной структурой, оно должно выражать сложную структуру. Иными словами, раз значением составного ключа может быть только строка, то эта строка должна состоять из нескольких частей.
Пример
Предположим, что объекты с одинаковыми именами могут принадлежать различным источникам. Покажем, как с помощью ключей можно решить следующие задачи:
□ найти объект с определенным именем и источником;
□ найти объекты с определенным именем;
□ найти объекты с определенным источником.
Листинг 8.27. Входящий документ
Для элементов
item
мы будем генерировать ключи, значения которых будут состоять из двух частей — источника и имени, разделенных символом "
-
". Для того чтобы решить одним ключом все три поставленные задачи, мы будем использовать для его определения три элемента
xsl:key
.
Листинг 8.28. Входящий документ
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
Листинг 8.29. Выходящий документ
У приведенного здесь способа формирования ключа есть определенные ограничения: необходимо иметь априорную информацию о строковых значениях каждого из свойств, составляющих наш композитный ключ для того, чтобы корректно формировать его строковые представления. Например, если бы в приведенном выше документе имена объектов и источников могли бы содержать символ "
-
", было бы непонятно, к какому объекту относится составной ключ "
a-b-c
": к объекту с источником
a-b
и именем
с
или к объекту с источником
а
и именем
b-c
. К счастью, в большинстве случаев такая информация имеется, и генерировать составные ключи не очень сложно.
Функция key в паттернах
Разбирая синтаксические правила построения паттернов, мы встретились с особой формой паттерна, в котором могла использоваться функция
key
. Приведем еще раз эту продукцию:
[PT3] IdKeyPattern ::= 'id' '(' Literal ')'
| 'key' '(' Literal ',' Literal ')'
Функция
key(key-name, key-value)
в паттерне будет соответствовать узлам, значение ключа
key-name
которых равняется или принадлежит объекту
key-value
. Это позволяет использовать возможности ключей при проверке узлов на соответствие образцу.
Пример
Предположим, что нам нужно по-особому обработать объекты, принадлежащие источнику
а
. Для этого мы можем создать шаблон следующего вида.
Листинг 8.30. Шаблон, использующий функцию key в паттерне
Этот шаблон будет применяться к любым узлам, имеющим ключ
src
со значением
а
.
Нумерация
Нумерация, несомненно, является одной из самых естественных проблем, решаемых при помощи XSLT. Задача нумерации состоит в том, чтобы, исходя из позиции обрабатываемого узла в дереве документа, вычислить по заданным критериям его порядковый номер. В качестве примера такого рода задачи можно привести вывод номеров частей, разделов и глав книги, указание номеров элементов списка или строк таблицы.
Для вычисления порядковых номеров узлов в дереве в XSLT существует несколько способов. В простых случаях для достижения цели бывает достаточно воспользоваться одним из следующих XPath-выражений.
□ Для того чтобы получить порядковый номер текущего узла в обрабатываемом множестве, можно использовать функцию
position
. Обратим внимание, что это будет позиция узла в обрабатываемом в данный момент множестве, а не в дереве исходящего документа.
□ Функция
count(preceding-sibling::*)+1
возвращает порядковый номер текущего элемента среди других элементов его родителя, иначе говоря, среди его братьев. Путь выборки
preceding-sibling::*
выбирает множество братских элементов, предшествующих текущему узлу, а функция
count
вычисляет их количество. Таким образом, значение
count(preceding-sibling::*)+1
будет равно
1
для первого элемента (поскольку ему другие элементы не предшествуют),
2
— для второго (ему предшествует один элемент) и так далее.
□ Для того чтобы учитывать при подсчете только определенные элементы, можно переписать предыдущее выражение в чуть более строгом виде. Например, выражение, считающее только элементы
chapter
, будет задаваться следующим образом:
(preceding-sibling::chapter) +1
.
□ Глубина текущего узла от корня дерева может быть вычислена выражением count(ancestor-or-self::node()). Это выражение будет возвращать
1
для корневого узла,
2
для элемента документа и так далее.
Вычислять выражения и выводить вычисленные значения в результирующее дерево следует, как и обычно — при помощи элемента
xsl:value-of
.
Пример
В более сложных ситуациях бывает необходимо подсчитывать узлы, находящиеся на разных уровнях вложенности или удовлетворяющие определенным условиям, начинать отсчет с заданной позиции в документе и использовать при вычислении номера сложные выражения. Использование XPath в таких случаях может быть очень неудобным — выражения будут слишком громоздкими и вычислять их придется в несколько этапов.
Другим, несравненно более легким и удобным способом нумерации и индексирования узлов является использование элемента
вычисляет номер узла в соответствии с заданными критериями, форматирует его и затем вставляет в результирующее дерево в виде текстового узла. То, что все это выполняется в одном элементе преобразования, имеет существенные преимущества по сравнению с использованием XPath-выражений: программа становится более простой и понятной, причем далеко не в ущерб функциональности.
К сожалению, в этом случае, как и во многих других, универсальность использования повлекла за собой семантическую сложность. Несмотря на то, что
xsl:number
имеет всего девять атрибутов (причем ни один из них не является обязательным), мы посвятим их описанию значительное количество страниц. Пока же, чтобы сориентировать читателя, мы кратко перечислим назначения атрибутов
xsl:number
.
□ Атрибут
level
указывает, на каких уровнях дерева следует искать нумеруемые узлы.
□ Атрибут
count
указывает, какие именно узлы следует считать при вычислении номера.
□ Атрибут
from
указывает, в какой части документа будет производиться нумерация.
□ Атрибут
value
задает выражения, которые следует использовать для вычисления значения номера.
□ Атрибут
format
определяет, как номер будет форматироваться в строку.
□ Атрибут
lang
задает языковой контекст нумерации.
□ Атрибут
letter-value
определяет параметры буквенных методов нумерации.
□ Атрибут
grouping-separator
задает символ, разделяющий группы цифр в номере.
□ Атрибут
grouping-size
определяет количество цифр в одной группе.
Выполнение элемента
xsl:number
можно условно разделить на два этапа — вычисление номера и его строковое форматирование. На этапе вычисления активными являются элементы
level
,
count
,
from
и
value
. Форматирование производится с учетом значений атрибутов
format
,
lang
,
letter-value
,
grouping-separator
и
grouping-size
. Результатом первого этапа является список номеров, который форматируется в текстовый узел на втором этапе.
Вычисление номеров
Пожалуй, самым простым для понимания (но не самым простым в использовании) способом вычисления номера является использование XPath-выражений. Этот способ практически идентичен использованию
xsl:value-of
, как было показано в начале этой главы. Единственным отличием
xsl:number
является то, что после вычисления номера он сначала форматируется, а потом уже вставляется в результирующее дерево в виде текстового узла.
Результатом первого этапа форматирования при определенном атрибуте
value
является список, состоящий из числа, полученного в результате вычисления выражения, указанного в значении этого атрибута.
Пример
В этом и нескольких следующих примерах мы будем вычислять номера в одном и том же документе, который представлен в листинге 8.31.
Листинг 8.31. Входящий документ для примеров преобразований с использованием xsl:number
paragraph 1
paragraph 2
paragraph 3
paragraph 4
paragraph 5
paragraph 6
paragraph 7
paragraph 8
paragraph 9
paragraph 10
paragraph 11
paragraph 12
paragraph 13
paragraph 14
paragraph 15
paragraph 16
paragraph 17
paragraph 18
В качестве первого примера приведем два шаблона, обрабатывающих элементы
chapter
: один с использованием
xsl:value-of
, а второй с использованием
xsl:number
.
Листинг 8.32. Вариант нумерующего шаблона с использованием xsl:value-of
.
Листинг 8.33. Вариант нумерующего шаблона с использованием xsl:number
Результат обоих шаблонов имеет следующий вид:
1. First chapter
2. Second chapter
3. Third chapter
Использование
xsl:number
даже в этом простом случае сэкономило одну строчку в коде. Однако, если бы вместо нумерации арабскими цифрами (
1
,
2
,
3
и т.д.) нужно было применить нумерацию римскими цифрами (
I
,
II
,
III
и т.д.), в преобразовании с
xsl:number
мы бы изменили всего один символ (вместо
format="1. "
указали бы
format="I. "
), в то время как в преобразовании с
xsl:value-of
пришлось бы писать сложную процедуру преобразования числа в римскую запись.
В том случае, если атрибут
value
опущен, номера элементов вычисляются исходя из значений атрибутов
level
,
count
и
from
.
Атрибут
level
имеет три варианта значений:
single
,
multiple
и
any
, значением по умолчанию является
single
. Процедура вычисления номеров существенным образом зависит от того, какой из этих вариантов используется — при методе
single
считаются элементы на одном уровне, при методе
multiple
— на нескольких уровнях и при методе
any
— на любых уровнях дерева. Алгоритм вычисления списка номеров в каждом из случаев не слишком сложен, но понять его только по формальному описанию довольно непросто. Поэтому каждый из методов будет дополнительно проиллюстрирован примерами вычисления.
Атрибут
count
содержит паттерн, которому должны удовлетворять нумеруемые узлы. Узлы, не соответствующие этому образцу, просто не будут приниматься в расчет. Значением этого атрибута по умолчанию является паттерн, выбирающий узлы с тем же типом и именем, что и у текущего узла (если, конечно, у него есть имя).
Атрибут
from
содержит паттерн, который определяет так называемую область нумерации, или область подсчета. При вычислении номера будут приниматься во внимание только те нумеруемые узлы, которые принадлежат этой области. По умолчанию областью подсчета является весь документ.
Метод single
Метод
single
используется для того, чтобы вычислить номер узла, основываясь на его позиции среди узлов того же уровня. Нумерацию, в которой используется метод
single
, также называют одноуровневой нумерацией.
Областью нумерации этого метода будет множество всех потомков ближайшего предка текущего узла, удовлетворяющего паттерну, указанному в атрибуте
from
.
Вычисление номера производится в два шага.
□ На первом шаге находится узел уровня дерева. Узлом уровня будет узел, удовлетворяющий следующим условиям:
• он является первым (то есть ближайшим к текущему) узлом, принадлежащим оси
ancestor-or-self
текущего узла;
• он удовлетворяет паттерну
count
;
• он принадлежит области подсчета;
• если такого узла нет, список номеров будет пустым.
□ На втором шаге вычисляется номер узла уровня. Этот номер будет равен
1
плюс количество узлов, принадлежащих оси навигации
preceding-sibling
и удовлетворяющих паттерну
count
.
Надо сказать, от атрибута
from
в методе
single
мало пользы. Единственный эффект, который можно от него получить, — это пустой список номеров в случае, если первый узел, принадлежащий оси
ancestor-or-self
и удовлетворяющий паттерну
count
, не будет иметь предка, соответствующего паттерну атрибута
from
.
Пример
Разберем функционирование одноуровневой нумерации в следующем шаблоне:
Мы продемонстрируем вычисление номера одного из элементов
para
на схематическом изображении дерева обрабатываемого документа (рис. 8.1). Узел обрабатываемого элемента мы выделим полужирной линией, узел элемента
doc
пометим буквой
d
, узлы элементов
chapter
— буквой
с
, элементов
section
и para — буквами
s
и
p
соответственно.
Рис. 8.1. Дерево обрабатываемого документа
В качестве первого примера приведем вычисление номера элементом
На первом шаге нам нужно найти узел уровня дерева. Этим узлом будет первый элемент
section
, являющийся предком текущего узла. На рис. 8.2 он обведен пунктиром.
Рис. 8.2. Первый шаг вычисления номера
Номер этого элемента будет равен
1
плюс количество предшествующих ему братских элементов
section
. Это множество выделено пунктиром на рис. 8.3.
Рис. 8.3. Второй шаг вычисления номера
Выделенное множество содержит два узла. Таким образом, искомый номер будет равен
3
.
Проведем такой же разбор для определения
В этом случае паттерну, указанному в элементе
count
удовлетворяет сам текущий узел, значит, он и будет являться узлом уровня, как это показано на рис. 8.4.
Рис. 8.4. Первый шаг вычисления номера
Выделим множество элементов
para
, являющихся братьями узла уровня и предшествующих ему (рис. 8.5).
Рис. 8.5. Второй шаг вычисления номера
Выделенное множество содержит всего один узел, значит, искомый номер будет равен
2
.
Таким образом, результатом обработки выделенного элемента
para
будет следующая строка:
3.2.paragraph 14
Метод multiple
Метод
multiple
похож на метод
single
, но при этом он немного сложнее, поскольку вычисляет номера узлов сразу на нескольких уровнях дерева. Нумерацию с применением метода
multiple
называют также многоуровневой нумерацией.
Область нумерации метода
multiple
определяется так же, как и в случае с методом
single
: учитываются только потомки ближайшего предка текущего узла, удовлетворяющего паттерну, указанному в атрибуте
from
.
Вычисление списка номеров узлов выполняется в два этапа:
□ На первом этапе выбирается множество нумеруемых узлов, удовлетворяющее следующим условиям:
• его узлы принадлежат оси навигации
ancestor-or-self
текущего узла;
• его узлы соответствуют паттерну
count
;
• его узлы принадлежат области подсчета.
□ На втором этапе для каждого узла нумеруемого множества вычисляется позиция среди собратьев. Позиция нумеруемого узла будет равна
1
плюс количество узлов, принадлежащих его оси навигации
preceding-sibling
и соответствующих паттерну
count
.
Пример
Для демонстрации вычисления номеров на нескольких уровнях дерева документа проследим за выполнением инструкции
format=" 1.1."
level="multiple"
count="doc|chapter|para"
from="doc"/>
при обработке того же элемента
para
.
Прежде всего, надо определить область подсчета. Значением атрибута
from
является паттерн
doc
, значит, подсчет будет вестись среди всех потомков ближайшего к текущему элементу
para
предка, который является элементом
doc
. Это множество выделено на рис. 8.6 штрих-пунктирной линией.
Рис. 8.6. Определение области подсчета
Следующим шагом выберем узлы, принадлежащие оси навигации
ancestor-or-self
текущего узла para и удовлетворяющие паттерну
doc|chapter|para
. Это множество будет включать сам текущий элемент, а также его предки
chapter
и
doc
. На рис. 8.7 они обведены пунктиром.
Рис. 8.7. Первый шаг вычисления номера
Следующим шагом оставим только те из выбранных узлов, которые входят в область подсчета. Эти узлы обведены на рис. 8.8 пунктиром.
Рис. 8.8. Второй шаг вычисления номера
Мы получили множество узлов, состоящее всего из двух элементов —
chapter
и
para
вследствие того, что элемент
doc
был исключен как не входящий в область подсчета. Выделим множества пересчитываемых узлов, предшествующих нумеруемым элементам (рис. 8.9).
Рис. 8.9. Третий шаг вычисления номера
В этом примере элемент
chapter
, так же как и элемент
para
, будет иметь номер
2
. Соответственно, результатом выполнения инструкции
xsl:number
в этом случае будет строка
2.2.paragraph 14
Метод any
Метод
any
используется для того, чтобы вычислить номер узла, основываясь на его позиции среди всех учитываемых узлов элемента.
Областью нумерации этого метода будет множество всех узлов, следующих в порядке просмотра документа за первым предком текущего узла, который удовлетворяет паттерну, указанному в атрибуте
from
.
Номер вычисляется как
1
плюс количество узлов области подсчета, удовлетворяющих паттерну
count
и предшествующих в порядке просмотра документа текущему узлу.
Пример
В качестве примера применения метода
any
вычислим порядковый номер элемента
para
среди всех элементов документа, начиная со второй главы. Инструкцию такого рода мы запишем в виде
format=" 1."
level="any"
count="*"
from="chapter[2]"/>
При ее выполнении мы сначала определим область, в которой будут подсчитываться узлы (обведены штрих-пунктирной линией на рис. 8.10).
Рис. 8.10. Определение области подсчета узлов
Следующим шагом выделим подмножество области подсчета, предшествующее в порядке просмотра текущему узлу
para
(рис. 8.11).
Рис. 8.11. Первый шаг вычисления номера
Выделенное множество содержит 11 узлов, значит, искомый номер будет равен
12
.
Перед тем, как перейти к рассмотрению способов форматирования номеров, приведем итоговый пример (листинг 8.34), в котором в шаблонах будут использоваться все три метода нумерации.
Листинг 8.34. Шаблон, использующий разные методы нумерации
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"»
Resulting document
==================
level="multiple"
count="chapter|section"/>
format=" a) "
level="any"
count="para"/>
Опишем словесно нумерацию, которая будет применяться в этом преобразовании.
□ Элементы
chapter
будут нумероваться в соответствии со своей позицией среди других элементов
chapter
того же уровня.
□ Элементы
section
будут нумероваться при помощи многоуровневой нумерации — номер будет состоять из номера элемента
chapter
и номера самого элемента
section
.
□ Элементы
para
будут нумероваться исходя из своей позиции среди всех остальных элементов
para
вне зависимости от того, на каких уровнях в документе они находятся.
Результатом применения этого преобразования к документу, приведенному в листинге 8.31, будет следующий текст.
Листинг 8.35. Выходящий документ
Resulting document
==================
1. First chapter
1.1 First section
a) paragraph 1
b) paragraph 2
c) paragraph 3
1.2. Second section
d) paragraph 4
e) paragraph 5
2. Second chapter
2.1 Third section
f) paragraph 6
g) paragraph 7
h) paragraph 8
i) paragraph 9
2.2 Forth section
j) paragraph 10
k) paragraph 11
l) paragraph 12
2.3 Fifth section
m) paragraph 13
n) paragraph 14
o) paragraph 15
p) paragraph 16
3. Third chapter
3.1 Sixth section
q) paragraph 17
r) paragraph 18
Форматирование номеров
Возвращаясь немного назад, напомним, что результатом первого этапа выполнения
xsl:number
является список номеров, который может быть пустым или содержать одно или несколько чисел. Несложно увидеть, что количество номеров в этом списке будет зависеть от следующих условий.
□ Список номеров будет пустым, если в области нумерации не оказалось нумеруемых узлов.
□ Список номеров будет состоять не более чем из одного числа при использовании методов
single
и
any
.
□ Список номеров будет состоять из нуля или более чисел (по одному на каждый уровень нумерации) при использовании метода
multiple
.
На этапе форматирования список номеров преобразуется в строку и вставляется результирующее дерево в виде текстового узла.
Преобразование номеров из списка в строку имеет совершенно иной характер, нежели чем приведение числа к строковому типу. При форматировании номера нужно получить не просто строковое представление числа, здесь требуется сгенерировать значащий текстовый индекс, который совершенно необязательно должен иметь цифровую запись.
Форматирование списка номеров производится в соответствии со значениями атрибутов
format
,
lang
,
letter-value
,
grouping-separator
и
grouping-size
, назначение и использование которых мы и будем разбирать в этом разделе.
Основным атрибутом форматирования является атрибут
format
, который содержит последовательность форматирующих токенов. Каждый форматирующий токен состоит из букв и цифр; он определяет процедуру форматирования для каждого числа из списка форматируемых номеров. В значении атрибута
format
форматирующие токены отделяются друг от друга сочетаниями символов, которые не являются буквами и цифрами. Такие сочетания называются разделяющими последовательностями. При форматировании они остаются в строковом выражении номера без изменений.
Пример
В примере к методу
multiple
мы использовали следующий элемент
xsl:number
:
format=" 1.1."
level="multiple"
count="doc|chapter|para"
from="doc"/>
Разберем строение атрибута
format
этого элемента (на рис. 8.12 пробелы обозначены символами "
□
"):
Рис. 8.12. Строение атрибута
format
элемента
xsl:number
Список номеров в том примере состоял из номера элемента
chapter
(числа 2) и номера элемента
para
(тоже 2). Номер, генерируемый элементом
xsl:number
, будет состоять из:
□ разделяющей последовательности "
□□□□□
", которая будет скопирована, как есть;
□ числа
2
, которое получается в результате форматирования номера 2 форматирующим токеном "
1
";
□ разделяющего символа "
.
";
□ числа
2
, которое получается в результате форматирования номера 2 вторым форматирующим токеном "
1
";
□ разделяющего символа "
.
".
Объединив все эти части, мы получим отформатированный номер "
□□□□□2.2
".
Несложно заметить, что главную роль при преобразовании списка номеров в их строковое представление играют форматирующие токены. Каждый такой токен преобразовывает соответствующий ему номер в строку. В табл. 8.3 мы приведем описания этих преобразований.
Таблица 8.3. Форматирующие токены
Токен
Описание
Примеры
Токен
Преобразование
1
Форматирует номер в виде строкового представления десятичного числа
1
1
→
'1'
1
2
→
'2'
1
10
→
'10'
1
999
→
'999'
1
1000
→
'1000'
0...01
Форматирует номер в виде строкового представления десятичного числа; если получившая строка короче токена, она дополняется предшествующими нулями
0001
1
→
'0001'
001
2
→
'002'
001
10
→
'010'
01
999
→
'999'
00001
1000
→
'01000'
A
Форматирует номер в виде последовательности заглавных букв латинского алфавита
A
1
→
'A'
A
2
→
'B'
A
10
→
'J'
A
27
→
'AA'
A
999
→
'ALK'
A
1000
→
'ALL'
a
Форматирует номер в виде последовательности строчных букв латинского алфавита
a
1
→
'a'
a
2
→
'b'
a
10
→
'j'
a
27
→
'aa'
a
999
→
'alk'
a
1000
→
'all'
I
Форматирует номер заглавными римскими цифрами
I
1
→
'I'
I
2
→
'II'
I
10
→
'X'
I
27
→
'XXVII'
I
999
→
'IM'
I
1000
→
'M'
i
Форматирует номер строчными римскими цифрами
i
1
→
'i'
i
2
→
'ii'
i
10
→
'x'
i
27
→
'xxvii'
i
999
→
'im'
i
1000
→
'm'
Другой
Форматирует номер
k
как
k
-й член последовательности, начинающейся этим токеном. Если нумерация таким токеном не поддерживается, вместо него используется токен
1
.
Не поддерживающийся токен
1
→
'1'
b
10
→
'k'
Б
2
→
'В'
Б
27
→
'Ы'
á
999
→
'ανψ'
å
1000
→
'βζο'
При использовании алфавитной нумерации процессор может учитывать значение атрибута
lang
элемента
xsl:number
для того, чтобы использовать буквы алфавита соответствующего языка. Однако на практике возможность эта поддерживается очень слабо: большинство процессоров поддерживают алфавитную нумерацию только с использованием латиницы. Поэтому для того, чтобы использовать при алфавитной нумерации кириллицу, вместо атрибута
lang
следует использовать форматирующие токены "
А
" (русская заглавная буква "
А
") и "
&#х430;
" (русская строчная буква "
а
").
Пример
Для форматирования номеров в последовательности
1.1.a
,
1.1.б
,
1.1.в
, …,
1.2.а
и так далее можно использовать объявление вида:
format="1.&#х430;"
level="multiple"
count="chapter|section"
from="doc"/>
Представим теперь себе следующую ситуацию: нам нужно начать нумерацию с латинской буквы
i
для того, чтобы получить последовательность номеров вида
i
,
j
,
k
,
l
,
m
и так далее. Первое, что приходит в голову — это запись вида
Однако вместо требуемой последовательности мы получим последовательность строчных римских цифр:
i
,
ii
,
iii
и так далее. Иными словами, некоторые форматирующие токены определяют нумерующую последовательность двусмысленно: одним вариантом является алфавитная последовательность, начинающаяся этим токеном, другим — некая традиционная для данного языка (например, последовательность римских цифр для английского).Для того чтобы различать эти последовательности в двусмысленных ситуациях, в
xsl:number
существует атрибут
letter-value
. Если его значением является
"alphabetic"
, нумерующая последовательность является алфавитной, значение
"traditional"
указывает на то, что следует использовать традиционный для данного языка способ. Если атрибут
letter-value
опущен, процессор может сам выбирать между алфавитным и традиционным способами нумерации.
При использовании цифровых форматов нумерации (иными словами, токенов вида
1
,
01
,
001
и так далее) цифры в номере можно разделить на группы, получив, например, такие номера как "
2.00.00
" из
20000
или "
0-0-0-2
" из 2. Для этой цели в
xsl:number
используется пара атрибутов
grouping-separator
и
grouping-size
.
Атрибут
grouping-separator
задает символ, который следует использовать для разбивки номера на группы цифр, в то время как
grouping-size
указывает размер группы. Эти атрибуты всегда должны быть вместе — если хотя бы один из них опущен, второй просто игнорируется.
Пример
Элемент
xsl:number
вида
format="[00000001]"
grouping-separator="."
grouping-size="2"/>
будет генерировать номера в следующей последовательности:
1
→
'[00.00.00.01]'
2
→
'[00.00.00.02]'
...
999
→
'[00.00.09.99]'
1000
→
'[00.00.10.00]'
Пожалуй, следует упомянуть, что в значениях атрибутов
format
,
lang
, l
etter-value
,
grouping-size
и
grouping-separator
могут быть указаны шаблоны значений, иными словами могут использоваться выражения в фигурных скобках. Это может быть полезно, например, для того, чтобы сгенерировать форматирующие токены во время выполнения преобразования.
Пример
В следующем шаблоне формат номера секции зависит от значения атрибута
format
ее родительского узла:
format="{../@format}-1 "
level="multiple"
count="chapter|section"/>
При обработке входящего документа
нумерация секций будет выглядеть как
I-1 First Section
I-2 Second Section
I-3 Third Section
Если же атрибут
format
элемента
chapter
будет иметь значение
1
, секции будут пронумерованы в виде
1-1 First Section
1-2 Second Section
1-3 Third Section
Форматирование чисел
Мы уже познакомились с функцией языка XPath
string
, которая конвертирует свой аргумент в строку. Эта функция может преобразовать в строку и численное значение, но возможности ее при этом сильно ограничены.
К счастью, XSLT предоставляет мощные возможности для форматирования строкового представления чисел при помощи функции
format-number
и элемента
xsl:decimal-format
.
Функция format-number
Запись функции имеет следующий вид:
string format-number(number, string, string?)
Функция
format-number
принимает на вход три параметра. Первым параметром является число, которое необходимо преобразовать в строку, применив при этом форматирование. Вторым параметром является образец, в соответствии с которым будет форматироваться число. Третий параметр указывает название десятичного формата, который следует применять.
Образец форматирования в XSLT определяется точно так же, как в классе
DecimalFormat
языка Java. Для того чтобы читателю, не знакомому с Java, не пришлось изучать документацию этого языка, мы приведем полный синтаксис образцов форматирования. Продукции образца форматирования мы будем помечать номерами с префиксом
NF
, чтобы не путать их с другими продукциями.
Прежде всего, образец форматирования может состоять из двух частей: первая часть определяет форматирование положительного числа, вторая часть — отрицательного. Запишем это в виде EBNF-продукции:
Двум частям образца форматирования соответствуют нетерминалы
NFSubpattern
, которые разделены нетерминалом
NFSubpatternDelim
.
В случае если вторая часть образца форматирования опушена, отрицательные числа форматируются точно так же, как и положительные, но им предшествует префикс отрицательного числа (по умолчанию — знак "минус", "
-
").
Примеры
format-number(1234.567,'#.00;negative #.00')
→
'1234.57'
format-number(-1234.567,'#.00/negative #.00')
→
'negative 1234.57'
format-number(-1234.567,'#.00')
→
'-1234.57'
Каждая из частей образца форматирования состоит из префикса (
К специальным форматирующим символам относятся следующие:
□ символ обязательной позиции цифры (по умолчанию "
0
");
□ символ необязательной позиции цифры (по умолчанию "
#
");
□ символ-разделитель образцов форматирования для положительного и отрицательного числа (по умолчанию "
;
");
□ символ-разделитель целой и дробной части (по умолчанию "
.
");
□ символ процента (по умолчанию "
%
").
Перечислим их продукции:
[NF 8] NFSymbol ::= NFReqDigit
| NFOptDigit
| NFSubpatternDelim
| NFFractionDelim
| NFGroupDelim
| NFPercent
[NF 9] NFReqDigit ::= '0'
[NF 10] NFOptDigit ::= '#'
[NF 11] NFSubpatternDelim ::= ';'
[NF 12] NFFractionDelim ::= '.'
[NF 13] NFGroupDelim ::= ','
[NF 14] NFPercent ::= '%'
Синтаксические правила, которые мы привели выше, пока не являются стандартными. Они корректно передают синтаксис образца форматирования, но являются более строгими, чем определения в документации языка Java.
Элемент xsl:decimal-format
Синтаксис элемента задан конструкцией вида:
name="имя"
decimal-separator="символ"
grouping-separator="символ"
infinity="строка"
minus-sign="символ"
NaN="строка"
percent="символ"
per-mille="символ"
zero-digit="символ"
digit="символ"
pattern-sераrator="символ"/>
XSLT позволяет изменять специальные символы, влияющие на форматирование строки. Именованный набор таких символов и некоторых других указаний называется десятичным форматом и определяется элементом
xsl:decimal-format
. От атрибутов этого элемента зависит, как будут обрабатываться символы образца форматирования и как число будет отображаться на выходе:
Атрибут
name
элемента
xsl:decimal-format
задает расширенное имя десятичного формата. Если имя не указано, это означает, что элемент
xsl:decimal-format
определяет десятичный формат по умолчанию.
Остальные атрибуты контролируют интерпретацию форматирующего образца и вывод строкового представления числа следующим образом:
□
decimal-separator
— задает символ, разделяющий целую и дробную части числа. Значением этого атрибута по умолчанию является символ "
.
", с Unicode-кодом
#x2e
. Атрибут
decimal-separator
рассматривается как специальный символ образца форматирования. Кроме того, он будет использован как разделяющий символ при выводе;
□
grouping-separator
— задает символ, группирующий цифры в целой части записи числа. Такие символы используются, например, для группировки тысяч ("
1,234,567.89
"). Значением по умолчанию является символ "
,
", код
#x2c
.
grouping-separator
рассматривается как специальный символ образца форматирования. Помимо этого, он будет использован как разделяющий символ групп цифр при выводе числа;
□
percent
— задает символ процента. Значением по умолчанию является символ "
%
", код
#x25
. Этот символ будет распознаваться в образце форматирования и использоваться при выводе;
□
per-mille
— задает символ промилле. Значением по умолчанию является символ "
‰
", код
#х2030
. Символ промилле распознается в образце форматирования и используется в строковом представлении числа;
□
zero-digit
— задает символ нуля. Значением по умолчанию является символ "
0
", код
#x30;
. В качестве цифр при отображении числа будут использоваться символ нуля и 9 символов, следующих за ним. Символ нуля распознается в образце форматирования и используется при выводе строкового представления числа;
□
digit
— определяет символ, который используется в образце форматирования для определения позиции необязательного символа. Значением по умолчанию является символ "
#
". Этот символ распознается как форматирующий символ необязательной цифры. Он не включается в строковое представление числа;
□
pattern-separator
— определяет символ, который используется в образце форматирования для разделения положительного и отрицательного форматов числа. Он не включается в строковое представление числа. Значением этого атрибута по умолчанию является символ "
;
";
□
infinity
— задает строку, которая будет представлять бесконечность. Значением по умолчанию является строка "
Infinity
";
□
NaN
— задает строку, которая будет представлять не-числа. Значением по умолчанию является строка "
NaN
";
□
minus-sign
— задает символ, который будет использоваться для обозначения отрицательных чисел. Значением по умолчанию является символ "
-
", код
#x2D
.
Элемент
xsl:decimal-format
не имеет смысла без функции
format-number
. Все, на что влияют его атрибуты — это формат, который будет использоваться при преобразовании чисел в строку функцией
, в отличие от многих других элементов не может переопределяться в преобразованиях со старшим порядком импорта. Элементы
xsl:decimal-format
должны определять десятичные форматы с различными именами (за исключением тех случаев, когда значения их атрибутов полностью совпадают).
Контроль вывода документа
Несмотря на то, что XSLT-процессоры должны лишь только преобразовывать логические модели документов, организованные в виде деревьев, многие из них имеют также возможность выдавать результат преобразования в виде последовательности символов.
Элемент xsl:output
Синтаксис этого элемента приведен ниже:
method = "xml" | "html" | "text" | "имя"
version = "токен"
encoding = "строка"
omit-xml-declaration = "yes" | "no"
standalone = "yes" | "no"
doctype-public = "строка"
doctype-system = "строка"
cdata-section-elements = "имена"
indent = "yes" | "no"
media-type = "строка"/>
Элемент верхнего уровня
xsl:output
позволяет указывать, каким образом должно быть выведено результирующее дерево.
Главным атрибутом элемента
xsl:output
является атрибут
method
, который определяет, какой метод должен использоваться для вывода документа. Значением этого атрибута может быть любое имя, но при этом техническая рекомендация XSLT определяет только три стандартных метода вывода —
"xml"
,
"html"
и
"text"
. В том случае, если процессор поддерживает нестандартный метод вывода, его реализация полностью зависит от производителя.
Если в преобразовании не определен элемент
xsl:output
или в нем не указан атрибут
method
, метод преобразования выбирается по умолчанию исходя из следующих условий.
□ Если корень выходящего документа имеет дочерний элемент с локальным именем "
html
" (в любом регистре символов), которому предшествуют только пробельные символы, методом вывода по умолчанию становится
"html
".
□ Во всех остальных случаях методом вывода по умолчанию является
"xml"
.
Пример
Для документа
XSL Transformations (XSLT)
XSL Transformations (XSLT) Version 1.0
Методом вывода по умолчанию будет
"html"
, а для документа
XSL Transformations (XSLT) Version 1.0
будет выбран метод вывода
"xml"
.
Помимо главного атрибута
method
, элемент
xsl:output
имеет следующие атрибуты:
□
version
(версия) — определяет версию языка выходящего документа;
□
indent
(индентация) — определяет, должен ли процессор добавлять пробельные символы для более наглядного форматирования документа;
□
encoding
(кодировка) — определяет, в какой кодировке должен быть выведен документ. Значение этого атрибута не зависит от регистра символов, то есть значения
encoding="utf-8"
и
encoding="UtF-8"
будут эквивалентны. В атрибуте
encoding
можно использовать только печатаемые символы ASCII, то есть символы интервала от
#x21
до
#x7e
. Значением
encoding
должно быть название набора символов, определенное в стандартах IANA (Internet Assigned Numbers Authority) или RFC2278. В противном случае, атрибут должен начинаться символами "
x-
";
□
media-type
— определяет тип содержимого MIME выходящего документа;
□
doctype-system
— определяет системный идентификатор, который должен быть использован в декларации типа документа (DTD);
□
doctype-public
— определяет публичный идентификатор, который должен быть использован в декларации типа документа (DTD);
□
omit-xml-declaration
(пропустить декларацию XML) — определяет, нужно ли включать декларацию XML в выходящий документ или нет. Значением этого атрибута должно быть либо
"yes"
(пропустить декларацию), либо
"no"
(включить декларацию в выходящий документ);
□
standalone
(самостоятельный документ) — определяет, должен ли процессор выводить указание на самостоятельность документа (standalone declaration). Значением этого атрибута может быть либо
"yes"
(выводить указание), либо
"no"
(не выводить указание на самостоятельность);
□
cdata-section-elements
— определяет список элементов, текстовое содержимое которых должно быть выведено с использованием секций CDATA.
Использование этих атрибутов зависит от того, какой из методов выбран для вывода преобразованного документа.
Метод вывода "xml"
Для того чтобы вывести результирующее дерево в виде XML-документа, следует использовать в элементе
xsl:output
метод
"xml"
. Ниже мы подробно опишем, каким образом на выход должны влиять другие атрибуты этого элемента.
Атрибут version
Этот атрибут определяет версию языка XML, которая должна использоваться для вывода результирующего документа. В случае если процессор не поддерживает указанную версию, он может либо выдать ошибку, либо использовать одну из поддерживаемых версий. На данный момент единственной действующей версией языка является версия 1.0 и потому, если в атрибуте в
version
будет указано другое значение, единственным эффектом от этого будет измененный параметр
version
в декларации XML.
Пример
Предположим, что в преобразовании версия выходящего документа задана как 1.2:
Тогда процессор может вывести декларацию XML в следующем виде:
Значением атрибута version по умолчанию является
"1.0"
, то есть, для того, чтобы получить декларацию XML вида
и т. д. ?>
достаточно опустить определение атрибута
version
:
Атрибут encoding
Атрибут
encoding
указывает на то, какая кодировка предпочтительна для выходящего документа. Множество кодировок зависит от используемого процессора, но при этом в соответствии с технической рекомендацией все они обязаны поддерживать Unicode-формы кодировок UTF-8 и UTF-16.
В случае если процессор не поддерживает кодировку, указанную в атрибуте
encoding
, процессор может либо выдать ошибку, либо использовать UTF-8 или UTF-16.
Если атрибут
encoding
опущен, процессор должен по умолчанию использовать UTF-8 или UTF-16. На практике абсолютное большинство процессоров используют по умолчанию кодировку UTF-8.
При выводе содержимого выходящего документа может возникнуть ситуация, когда в выходящем потоке будут находиться символы, которые невозможно будет отобразить при используемой кодировке. В этом случае непечатаемые символы должны быть заменены символьными сущностями.
Пример
Представим себе входящий документ в кодировке UTF-8, содержащий символ кириллицы "
Э
" с Unicode-кодом
#x42d
(или
#1069
в десятичной системе счисления):
Э
Если преобразование будет использовать для вывода кодировку, которая не может отображать символы кириллического алфавита, например ISO-8859-1, то символ "
Э
" в выходящем документе должен быть заменен символьной сущностью.
Листинг 8.36. Преобразование
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
method="xml"
encoding="ISO-8859-1"
indent="yes"/>
Листинг 8.37. Выходящий документ
Э
Вместе с тем синтаксис XML не разрешает использовать символьные сущности в именах элементов и атрибутов, и наличие в них символов, не отображаемых кодировкой вывода, будет являться ошибкой. Если в предыдущем примере документ будет иметь вид
<страница>Э
то вывести результирующее дерево в кодировке ISO-8859-1 будет невозможно.
Атрибут indent
Индентацией называют форматирование исходного текста, не влияющее на семантику, но облегчающее читаемость. К примеру, один и тот же XML-документ можно написать как
Очевидно, что второй случай гораздо легче для понимания, поскольку в нем легко можно видеть принадлежность элементов одного другому. Подобное форматирование можно использовать и при выводе преобразованного документа при помощи атрибута
indent
элемента
xsl:output
. Если этот атрибут имеет значение
"yes"
, процессор может добавить один или несколько пробельных символов или символов перевода строки — в зависимости от реализации. Как правило, каждый дочерний элемент помещают на новой строке, добавляя впереди два пробела на каждый уровень вложенности.
Пример
Листинг 8.38. Входящий документ
Листинг 8.39. Преобразование
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
Листинг 8.40. Выходящий документ
Следует быть осторожными при использовании
indent="yes"
там, где в содержимом документа могут встречаться значащие пробелы. Индентация позволяет процессору при выводе документа добавлять пробельные символы по собственному усмотрению. В случаях, когда при последующей обработке преобразованного документа пробельные символы могут быть восприняты неадекватно, лучше индентацию не использовать.
Атрибут cdata-section-elements
Для того чтобы вывести текстовое содержимое некоторых элементов в виде секций CDATA, XSLT предлагает простой механизм — следует лишь перечислить в атрибуте
cdata-section-elements
элемента
xsl:output
элементы, которые на выходе должны содержать секции символьных данных.
Пример
Листинг 8.41. Входящий документ
<br/>
Листинг 8.42. Преобразование
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
indent="yes"
cdata-section-elements="page"/>
Листинг 8.43. Выходящий документ
]]>
В соответствии с синтаксисом XML, секции CDATA не могут содержать последовательности символов "
]]>
". Потому, встретив такую комбинацию в тексте элемента, имя которого включено в
cdata-section-elements
, процессор заменит ее двумя секциями CDATA. Одна будет содержать "
]]
", вторая – "
>
".
Пример
Листинг 8.44. Входящий документ
]]>
<!-- Comment -->
Листинг 8.45. Преобразование
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
indent="yes"
cdata-section-elements="data pre"/>
Листинг 8.46. Выходящий документ
]]>
]]>
Атрибут doctype-system
Для определения логической структуры документов в XML используются DTD — определения типов документов. В большинстве случаев определения типов содержатся во внешних ресурсах, которые включаются в документ в виде системных или публичных идентификаторов.
XSLT позволяет создавать ссылки на внешние определения типов при помощи атрибута
doctype-system
элемента
xsl:output
.
Пример
Предположим, что мы создаем документ, логическая схема которого определена во внешнем файле по адресу
"/dtds/document.dtd"
. Тогда, определив в преобразовании элемент
xsl:output
с атрибутом
doctype-system
, равным
"/dtds/document.dtd"
, мы получим в выходящем документе определение типа в виде
элемент SYSTEM "/dtds/document.dtd">
где
элемент
— первый элемент выходящего документа.
Листинг 8.47. Входящий документ
content
Листинг 8.48. Преобразование
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
Листинг 8.49. Выходящий документ
content
Атрибут doctype-public
Если в преобразовании атрибутом
doctype-system
элемента
xsl:output
задано внешнее определение логического типа документа, это определение может быть расширено также и публичным идентификатором. Публичный идентификатор указывается в атрибуте
doctype-public
элемента
xsl:output
. Его использование может быть продемонстрировано следующим примером.
Листинг 8.50. Входящий документ
content
Листинг 8.51. Преобразование
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
doctype-system="/dtds/document.dtd"
doctype-public="-//Document//Description" />
Листинг 8.52. Выходящий документ
PUBLIC "-//Document//Description" "/dtds/document.dtd">
content
Атрибут media-type
Атрибут
media-type
позволяет задавать медиа-тип содержимого выходящего документа. Для метода вывода
"xml"
значением
media-type
по умолчанию является
"text/xml"
. Несмотря на то, что
media-type
не оказывает никакого влияния на содержимое самого документа, XSLT-процессоры, используемые на стороне сервера, могут в зависимости от значения этого атрибута изменять MIME-тип исходящих данных при использовании, к примеру, такого протокола, как HTTP.
Атрибут omit-xml-declaration
XML-документы, в принципе, могут быть корректными и без декларации XML. Поэтому XSLT позволяет опускать эту декларацию в выходящем документе, для чего значению атрибута
omit-xml-declaration
должно быть присвоено
"yes"
:
omit-xml-declaration="yes"/>
В случае если значение атрибута
omit-xml-declaration
опущено или не равно
"yes"
, процессор будет выводить в выходящем документе декларацию XML, которая включает информацию о версии (по умолчанию
"1.0"
) и кодировке документа (по умолчанию
"utf-8"
или
"utf-16"
в зависимости от процессора).
Атрибут standalone
Для того чтобы объявить документ как самостоятельный или несамостоятельный (standalone или non-standalone соответственно), следует использовать атрибут
standalone
элемента
xsl:output
. Если этот атрибут будет присутствовать в
xsl:output
, то процессор включит в декларацию XML объявление
standalone
с соответствующим значением. Если атрибут
standalone
не указан, объявление
standalone
в декларацию XML выходящего документа включено не будет.
Метод вывода "html"
В нынешнем состоянии языки XML и HTML сильно похожи синтаксически, но при этом имеют некоторые довольно весомые различия. Метод вывода
"html"
используется для того, чтобы выводить документы в формате, который будет понятен большинству существующих на данный момент Web-браузеров.
Одно из основных различий HTML и XML состоит в том, что в XML пустые элементы имеют формат
<имя/>
, в то время как в HTML тот же элемент был бы выведен, как
<имя>
— без косой черты. Метод вывода
"html"
учитывает эти различия и выводит теги пустых элементов HTML без косой черты после имени. В соответствии с технической рекомендацией языка HTML 4.0, пустыми элементами являются
распознает элементы HTML вне зависимости от регистра символов — в нашем примере пустой элемент
был выведен как
, что соответствует синтаксису HTML.
Документы, которые преобразуются в HTML, могут также иметь программы, определенные внутри элемента
script
или стили, заданные внутри элемента
style
. В случае если внутри этих элементов оказываются символы, считающиеся в XML специальными — такие как "
<
", "
&
" и так далее, процессор не должен заменять их символьными или встроенными сущностями.
Пример
Предположим, что в преобразуемом документе элемент
script
определен с использованием специальных символов, которые заменены сущностями:
или с использованием секций символьных данных:
При использовании метода вывода
"html"
оба варианта будут выведены, как
Пожалуй, стоит еще раз повторить, что это относится только к элементам
style
и
script
. Специальные символы, использованные в других элементах, будут заменены символьными или встроенными сущностями.
Пример
This >o< is a black hole of this page!
будет выведено как
This >o< is a black hole of this page!
В соответствии со спецификацией, некоторые атрибуты в HTML могут и не иметь значений — как правило, это атрибуты с булевыми значениями, такие, к примеру, как атрибут
selected
элемента
option
, присутствие которого в элементе означает то, что опция выбрана, отсутствие — то, что она не выбрана. Для того чтобы получить в выходящем документе
следует в преобразовании указывать
то есть присваивать булевому атрибуту значение, равное собственному имени. Такие значения будут выведены в минимизированной форме, как это и требовалось.
HTML и XML также имеют небольшие различия в формате вывода инструкций по обработке. В то время как в XML эти инструкции имеют вид
приложение содержимое?>
в HTML инструкции по обработке заканчиваются не "
?>
", а просто правой угловой скобкой ("
>
"):
приложение содержимое>
Таким образом, результатом выполнения кода
content
при использовании метода XML будет
а при использовании метода HTML
Атрибут version
Атрибут
version
элемента
xsl:output
в методе
"html"
обозначает версию языка HTML, которая должна использоваться в выходящем документе. По умолчанию значением этого атрибута является
"4.0"
, что означает соответствие выходящего документа спецификации языка HTML версии 4.0. Отметим, что последней версией языка HTML на момент написания этой книги является версия 4.02, однако отличия между этими версиями незначительны.
Атрибут encoding
Кодировка выходящего документа определяется в HTML несколько иначе, чем в XML. Если в XML мы использовали определение
encoding
в декларации XML, то в HTML кодировка описывается в элементе
meta
следующим образом:
content="text/html; charset=windows-1251">
...
Поэтому, если в выходящем документе внутри корневого элемента
html
присутствует элемент
head
, процессор должен добавить в него элемент meta с соответствующим определением кодировки.
Пример
Элемент
добавит в элемент
head
выходящего HTML-документа элемент
meta
в следующем виде:
content="text/html; charset=ISO-8859-1">
Таким образом, для определения кодировки выходящего HTML-документа не следует вручную создавать соответствующий элемент
meta
— нужно просто указать требуемую кодировку в атрибуте
encoding
элемента
xsl:output
.
Атрибут indent
XSLT позволяет использовать в HTML документах индентацию точно так же, как мы бы использовали ее в методе
"xml"
.
Атрибуты doctype-system и doctype-public
Декларация типа документа с внешними системными или публичными идентификаторами может быть использована в HTML точно так же, как в XML. Поскольку в объявлении типа документа после
должно стоять имя корневого элемента, при методе вывода
"html"
этим именем будет
"HTML"
или
"html"
в зависимости от регистра символов имени корневого элемента документа.
Атрибут media-type
Атрибут
media-type
определяет медиа-тип содержимого выходящего документа. Для HTML-документов значением
media-type
по умолчанию будет
"text/html"
.
Метод вывода "text"
XSLT позволяет выводить результат преобразования как простой текст. При использовании
method="text"
результирующее дерево приводится к строке, то есть в этом случае результатом преобразования будет строковое сложение всех текстовых узлов дерева.
Пример
Входящий документ
My heart's in the Highlands
My heart is not here
одним и тем же шаблоном:
при использовании метода вывода
"xml"
будет преобразован к виду
My heart's in the Highlands
My heart is not here
а при использовании метода
"text"
к виду
My heart's in the Highlands
My heart is not here
Атрибут encoding
Атрибут
encoding
указывает на предпочтительную кодировку вывода текста документа. Значение атрибута
encoding
по умолчанию зависит от программной платформы, на которой производится преобразование. В большинстве процессоров по умолчанию используются кодировки UTF-8, ASCII и ISO-8859-1.
В случае если кодировка, используемая для вывода текста, не отображает некоторые символы документа, процессор может выдать ошибку.
Атрибут media-type
По умолчанию в качестве значения атрибута
media-type
, используемого для простого текста, указывается
"text/plain"
. Значение атрибута
media-type
может быть использовано сервером, преобразующим документ в качестве MIME-типа.
Другие методы вывода
Как уже было сказано раньше, спецификация XSLT позволяет помимо основных методов
"xml"
,
"html"
и
"text"
использовать также и другие методы, реализация которых будет зависеть от производителя того или иного процессора. Кажется вполне логичной и закономерной возможность использования, к примеру, такого метода, как
"pdf"
для создания документов в Adobe Portable Document Format (переносимом формате документов) или метода
"bin"
для создания двоичного потока данных. Однако, на данном этапе, процесс сериализации (создания физической сущности из логической модели) пока еще не определен в общем виде для произвольного метода. Возможно, в будущем, по аналогии с объектной моделью документа (DOM) будут созданы схожие интерфейсы для более легкого определения методов сериализации и интеграции преобразований в другие программы, но в настоящее время следует ограничиваться тремя основными методами.
Отметим также, что спецификация языка XSLT определяет функциональность элемента
xsl:output
как возможную, но не обязательную. Процессоры обязаны манипулировать логическими моделями XML-документов, но при этом они не обязаны поддерживать сериализацию и уметь выводить преобразованный XML-документ как последовательность байт. Конечно же, абсолютное большинство процессоров поддерживает такую возможность, но при всем том она остается не более чем возможностью.
Поэтому из соображений переносимости можно лишь только надеяться, что документ будет выведен так, как было задумано. Не следует исключать возможности, что в определённых условиях процессор не сможет контролировать процесс вывода документа.
Типичным примером такой ситуации может быть использование процессора совместно с другими компонентами, которые обмениваются с процессором документами в виде DOM-структур, но сами загружают и выводят документы. В этом примере компоненты, занимающиеся выводом преобразованного документа, могут спокойным образом игнорировать все то, что было указано в элементе
xsl:output
или в атрибутах
disable-output-escaping
других элементов преобразования. Более того, они даже не будут знать, что было там указано, поскольку эти значения не касаются процесса преобразования как такового — они относятся к выводу, контролировать который процессор в данном случае не может.
Отсюда следует однозначный вывод: не нужно чересчур злоупотреблять возможностями
xsl:output
и
disable-output-escaping
.
Замена специальных символов
Как мы уже знаем, в XML есть несколько специальных символов, которые, как правило, заменяются процессором при выводе документа на соответствующие символьные или встроенные сущности. К примеру, для того, чтобы вывод был корректным XML-документом, процессор обязан заменять символы "
<
" и "
&
" на встроенные (
<
и
&
) или символьные (
<
и
&
) сущности.
Между тем довольно часто бывает необходимым выводить в выходящем документе символы разметки.
Пример
Пусть входящий документ содержит описание товара, заданное в секции CDATA:
An elephant
big and grey animal!]]>
Если мы будем преобразовывать этот документ с использованием шаблона
то в выходящем документе специальные символы будут заменены:
An elephant
This is a <em>big</em> and <b>grey</b> animal!
Для того чтобы избежать замены, можно воспользоваться атрибутом
disable-output-escaping
(отменить замену символов) элементов
xsl:value-of
и xsl:text. Этот атрибут может принимать значения
"yes"
и
"no"
("no" — значение по умолчанию). Значение
"yes"
означает, что процессор при выводе текста, создаваемого
xsl:text
или
xsl:value-of
не должен заменять специальные символы. Если бы в предыдущем примере мы использовали преобразование.
налагает ряд ограничений на использование текстовых узлов, генерируемых элементами
xsl:text
и
xsl:value-of
: эти узлы не могут входить в качестве текстового содержимого в узлы атрибутов, комментариев или инструкций по обработке. Кроме того, дерево, содержащее текстовые узлы, для которых была отменена замена специальных символов, не может быть приведено к строке или числу. И в том и в другом случае процессор может либо выдать ошибку преобразования, либо проигнорировать отмену замены специальных символов.
Атрибут
disable-output-escaping
имеет также и более концептуальное ограничение. Процессор сможет отменить замену символов только в том случае, когда он сам будет контролировать процесс вывода. Как мы уже обсуждали в предыдущем разделе, ситуации, когда процесс вывода не будет выполняться самим процессором, не такая уж и редкость. Поэтому следует использовать
disable-output-escaping
только в тех случаях, когда другой альтернативы нет или когда имеется полная уверенность, что этот метод будет работать.
Атрибут
disable-output-escaping
работает с методами вывода
"xml"
и
"html"
, но не оказывает никакого влияния на метод
"text"
, поскольку при этом методе все специальные символы и так выводятся без замены.
Кодировки в XSLT-преобразованиях
Несмотря на то, что в логических деревьях, которыми манипулирует XSLT, текстовые узлы представляются в кодировке Unicode, очень часто в обрабатываемых документах бывает необходимо использовать также другие кодировки. К примеру, большинство русскоязычных документов хранятся в кодировках Windows-1251 и KOI8-R.
Если внимательно присмотреться к преобразованиям, можно заметить, что, как правило, в них участвуют минимум три документа — входящий (преобразовываемый) документ, документ преобразования (преобразующий) и выходящий (преобразованный документ). Соответственно, каждый из них может иметь собственную кодировку.
Кодировка входящего документа указывается в его xml-декларации. Например, документы в кодировке Windows-1251 должны иметь xml-декларацию вида
Возможно, небольшим сюрпризом окажется то, что в соответствии со стандартом XML, имена тегов вовсе не обязаны состоять исключительно из латинских букв. В имени элемента можно использовать весь кириллический алфавит, а также множество других символов. Совершенно корректным будет документ
<страница>
<содержимое/>
Аналогичным образом кириллицу, а также другие наборы символов и алфавиты можно использовать и в самих преобразованиях, поскольку те в свою очередь также являются XML-документами.
Пример
Листинг 8.57. Входящий документ
<каждый>
<охотник>
<желает>
<знать>
<где>
<сидит>
<фазан/>
Листинг 8.58. Преобразование
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<редкий>
<рыболов>
<может>
<забыть>
<как>
<плавает>
<щука>
Листинг 8.59. Выходящий документ
<редкий>
<рыболов>
<может>
<забыть>
<как>
<плавает>
<щука/>
Напомним, что кодировка выходящего документа определяется атрибутом
encoding
элемента
xsl:output
и не зависит от кодировок преобразования и обрабатываемых документов. Например, можно легко создать преобразование, которое будет изменять кодировку входящего документа. Это будет идентичное преобразование с элементом
xsl:output
, определяющим целевой набор символов.
Листинг 8.60. Преобразование, изменяющее кодировку документа на KOI8-R
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
Как можно видеть, XSLT довольно гибко поддерживает кодировки — входящие и выходящие документы, а также сами преобразования могут иметь разные наборы символов. Единственным ограничением является множество кодировок, поддерживаемое самим процессором, вернее парсером, который он использует для разбора входящих документов, и сериализатором, который служит для создания физического экземпляра выходящего документа.
Практически во всех процессорах поддерживаются кодировки UTF-8, US- ASCII и ISO-8859-1, но далеко не все могут работать с Windows-1251 или KOI8-R. Поэтому, создавая документы и преобразования в нестандартных кодировках, мы заведомо ограничиваем переносимость решений. В случаях, когда XML/XSLT приложения создаются под конкретный процессор с заведомо известными возможностями, это не является большой проблемой, однако в тех случаях, когда требуется универсальность или точно не известно, каким процессором будет производиться обработка, единственным выходом будет использовать UTF-8 — как во входящих документах, так и в самих преобразованиях.
Случай нескольких входящих документов
Базовая архитектура преобразования подразумевает один входящий документ. Несмотря на это, в преобразованиях можно использовать и обрабатывать информацию, хранящуюся в других, внешних документах. Доступ к этим документам можно получить при помощи функции
document
.
Функция document
Запись функции:
node-set document(object, node-set?)
Функция
document
позволяет обращаться к внешним документам по их URI, например
скопирует в выходящий документ содержимое главной страницы Консорциума W3.
Функция
document
возвращает множество узлов. В простейшем случае это множество будет состоять из корневого узла внешнего документа. Функцию
document
можно использовать в более сложных XPath-выражениях, например в выражениях фильтрации. Так функция
скопирует все элементы а, находящиеся в теле (
/html/body
) внешнего документа.
Базовый сценарий использования функции
document
очень прост: ей передается строка, содержащая URI внешнего ресурса, а результатом является множество узлов, состоящее из корня внешнего документа. Однако на этом возможности
document
не заканчиваются. Мы рассмотрим несколько вариантов вызова функции
document
с параметрами различного типа.
Вызов document(string)
В случае если функции
document
передана строка, возвращаемое множество будет состоять из корневого узла внешнего документа. URI этого документа как раз и сообщается строковым аргументом функции
document
.
Интересной особенностью является возможность передать пустую строку:
document('')
В этом случае
document
возвратит корневой узел самого преобразования. При помощи
document('')
можно получать доступ к информации, хранящейся в самом преобразовании (оно ведь тоже является ХМL-документом). К сожалению, перед обращением к документу не существует способа проверить его существование. Процессор может либо выдать ошибку, либо возвратить пустое множество.
множество узлов, можно получить доступ к нескольким документам, URI которых являются строковыми значениями узлов множества. Это, в частности, позволяет обращаться к документам, URI которых указаны в узлах обрабатываемого документа. Например, в контексте элемента
<а href="http://www.w3.org">...
вполне корректным вызовом функции
document
будет
document (@href)
.
Выражение
@href
— здесь возвращает множество, состоящее из единственного узла атрибута. Его строковое значение (
"http://www.w3.org"
) будет использовано как URI внешнего документа. Результирующее множество узлов будет содержать единственный корневой узел документа, расположенного по адресу http://www.w3.org.
Приведем еще один пример. XPath-выражение
//a/@href
возвращает множество всех атрибутов
href
элементов
а
текущего документа. Тогда множество document(
//a/@href
) будет содержать корневые узлы всех документов, на которые ссылается посредством элементов а текущий документ.
Вызов document(string, node-set)
URI, которые передаются функции
document
, могут быть как абсолютными, так и относительными, например
document('doc.xml')
возвратит корень документа
doc.xml
, находящегося в том же каталоге, что и само преобразование.
Функция
document
позволяет менять "точку отсчета" относительных URI. Если в качестве второго аргумента функции document передано множество узлов, то относительные идентификаторы ресурсов будут отсчитываться от базового адреса первого (в порядке просмотра документа) узла этого множества.
Базовым URI узла дерева является:
□ если элемент или инструкция по обработке принадлежит внешней сущности, базовым URI соответствующего узла будет URI внешней сущности;
□ иначе базовым URI является URI документа;
□ базовым URI текстового узла, узла атрибута, комментария или пространства имен является базовый URI родительского элемента.
Поясним вышесказанное на примерах.
Конструкция
копирует в выходящий документ
doc.xml
, находящийся в одном каталоге вместе с преобразованием.
Несмотря на то, что в следующем определении
xsl:for-each
меняет контекст,
document('doc.xml')
все равно возвращает корень документа
doc.xml
, находящегося в одном с преобразованием каталоге:
В следующей конструкции
document('doc.xml', /)
копирует документ
a/doc.xml,
поскольку в качестве базового URI используется URI корня документа
a/data.xml
:
Того же самого эффекта можно достичь следующим образом:
В следующей конструкции за базовый URI опять принимается URI самого преобразования (вернее, его корневого узла):
Протестируем теперь все это вместе в одном преобразовании.
Листинг 8.63. Преобразование
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
Листинг 8.64. Документ doc.xml
doc.xml
Листинг 8.65. Документ a/doc.xml
a/doc.xml
Листинг 8.66. Выходящий документ
doc.xml
doc.xml
a/doc.xml
a/doc.xml
doc.xml
Вызов document(node-set, node-set)
Если функции
document
передаются два множества узлов, то вычисление результата можно описать примерно следующим образом:
□ каждый из узлов первого аргумента преобразуется в строковый вид;
□ для каждого из полученных значений выполняется вызов типа
document(string, node-set)
;
□ результирующие множества объединяются.
Иными словами,
document(node-set, node-set)
работает через
document(string, node-set)
точно так же, как
document(node-set)
работает через
document(string)
. Разница лишь в том, что в первом случае базовый URI будет изменен.
Другие дополнительные функции XSLT
Функция current
Выражение для этой функции имеет вид:
node-set current()
Функция
current
возвращает множество, состоящее из текущего узла преобразования.
Мы часто использовали термины текущий узел и узел контекста как синонимы: действительно, в большинстве случаев между ними нет никакой разницы, текущий узел преобразования совпадает с узлом контекста вычисления выражений. Однако бывают ситуации, когда они являются двумя различными узлами.
Представим себе, что нам нужно выбрать элементы
item
со значением атрибута
source
, равным значению этого атрибута текущего узла. Очевидно, путь выборки будет выглядеть как
item[предикат]
, где предикат определяет условие равенства атрибутов текущего и выбираемого. Но как записать это условие? Предикат будет вычисляться в контексте проверяемого элемента
item
, значит, все относительные пути выборки типа
@source
или
./@source
или
self::item/@source
будут отсчитываться именно от проверяемого элемента. В этом случае узел контекста и текущий узел преобразования — не одно и то же.
Для того чтобы обратиться в предикате именно к текущему узлу, следует использовать функцию
current
:
item[@source=current()/@source]
Это выражение выберет все дочерние элементы
item
текущего узла, значение атрибута
source
которых будет таким же, как и у него.
Функция unparsed-entity-uri
Выражение для этой функции следующее:
string unparsed-entity-uri(string)
Функция
unparsed-entity-uri
возвращает уникальный идентификатор ресурса, который соответствует неразбираемой внешней сущности, имя которой передано как аргумент.
Пример
Описывая синтаксис XML, мы приводили пример документа, который использовал неразбираемые внешние сущности.
Для того чтобы вычислить местоположение графических файлов, соответствующих пунктам этого меню, нужно будет использовать функцию
unparsed- entity-uri
. Аргументом этой функции в данном случае будет значение атрибута
image
, ведь именно этот атрибут задает имя неразбираемой сущности, которая соответствует изображению пункта меню. Преобразование такого документа в HTML будет иметь приблизительно следующий вид.
Результат преобразования приведен на следующем листинге.
Листинг 8.69. Выходящий документ
Остается только добавить, что
unparsed-entity-uri
— это единственная функция, которая позволяет работать с неразбираемыми сущностями. Никаких средств для обработки нотаций и вспомогательных приложений, которые им соответствуют, в XSLT нет. Сказывается тот факт, что неразбираемые сущности и нотации очень редко используются в документах, поэтому их поддержка в XSLT минимальна.
Функция generate-id
Синтаксическая конструкция этой функции:
string generate-id(node-set?)
Функция
generate-id
возвращает уникальный строковый идентификатор первого в порядке просмотра документа узла, передаваемого ей в виде аргумента. Если аргумент опущен, функция возвращает уникальный идентификатор контекстного узла. Если аргументом является пустое множество, функция должна возвращать пустую строку.
Функция
generate-id
обладает следующими свойствами.
□ Функция
generate-id
возвращает для двух узлов один и тот же идентификатор тогда и только тогда, когда эти два узла совпадают. Это означает, что во время выполнения одного преобразования функция
generate-id
будет возвращать один идентификатор для одного и того же узла, а для разных узлов
generate-id
обязательно возвратит разные идентификаторы.
□ Возвращаемый идентификатор состоит только из цифр и букв ASCII и начинается буквой, то есть синтаксически является корректным XML-именем и может использоваться как имя элемента, атрибута, как значение ID-атрибута или в любом другом месте, где могут использоваться имена XML.
Кроме этого спецификация оговаривает следующие важные положения, которые мы приведем ниже.
□ Процессор не обязан генерировать один и тот же идентификатор при разных выполнениях преобразования одного и того же документа. Иными словами, если в понедельник процессор
X
при выполнении преобразования
Y
сгенерирует для узла
Z
документа
D
идентификатор
I
, то во вторник тот же процессор
X
при выполнении того же преобразования
Y
с тем же документом
D
может сгенерировать для того же самого узла
Z
совершенно другой, отличный от
I
идентификатор.
□ Форма возвращаемого идентификатора может быть произвольной, но при этом она должна удовлетворять описанному выше синтаксису. Это означает, что каждый процессор может по-своему генерировать идентификатор. Спецификация не определяет никакого стандартного метода реализации функции
generate-id
.
□ Генерируемый идентификатор может совпадать, а может и не совпадать со значениями уникальных атрибутов, то есть атрибутов, тип данных которых объявлен в блоке DTD как
ID
.
Помимо очевидного применения, например, для явного задания уникального идентификатора в выходящем документе, функция
generate-id
совершено неожиданным образом облегчает задачи группировки. Подробнее об этом мы расскажем в главе 11.
Пример
Предположим, что в наших XML-документах изменилась логическая схема: теперь каждый элемент
item
должен обладать уникальным атрибутом
id
.
Выполнить задачу конвертации может простое преобразование.
Листинг 8.70. Преобразование
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
В выходящем документе элементы
item
будут иметь уникальные идентификаторы.
Листинг 8.71. Выходящий документ
...
Сразу оговоримся, что этот способ будет работать не всегда:
generate-id
создает идентификатор, который является уникальным среди всех остальных идентификаторов узлов, а не среди всех значений уникальных атрибутов документа. Так что если бы какой-либо элемент имел ID-атрибут со значением
b1b1b4
, выходящий документ перестал бы быть правильным. Однако же, если в документе до преобразования вообще не было уникальных атрибутов, все будет в порядке.
Функция system-property
Синтаксис этой функции приведен ниже:
object system-property(string)
Функция
system-property
возвращает значение свойства, которое определяется ее строковым параметром. Аргумент этой функции должен представлять расширенное имя системного свойства. Если процессор не поддерживает свойство с таким именем, функция должна вернуть пустую строку.
Эта функция предназначена для получения информации об окружении, в котором производится преобразование. В стандарте языка указано, что все процессоры в обязательном порядке должны поддерживать следующие системные свойства:
□
xsl:version
— это свойство должно возвращать номер версии языка XSLT, которую поддерживает данный процессор.
□
xsl:vendor
— это свойство должно возвращать текстовую информацию о производителе используемого процессора.
□
xsl:vendor-uri
— это свойство должно возвращать URL производителя — как правило,
xsl:vendor-uri
— это адрес Web-сайта производителя процессора.
К сожалению, в первой версии языка XSLT процессоры обязаны поддерживать только эти свойства. Очень полезным, было бы, например, свойство, возвращающее имя преобразования или преобразовываемого файла. К сожалению, ничего подобного в стандарте не предусмотрено.
Пример
В качестве примера приведем небольшой шаблон, выводящий в виде комментария информацию о процессоре.
Листинг 8.72. Шаблон, выводящий системную информацию
Процессор SAXON, написанный Майклом Кеем (Michael Kay), выводит следующий комментарий:
Ожидается, что в будущих версиях XSLT набор системных свойств будет расширен. Кроме того, многие процессоры поддерживают дополнительные системные свойства, не оговоренные в спецификации.
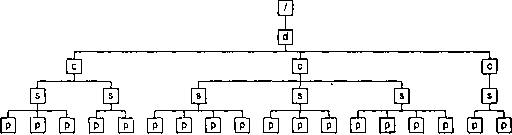


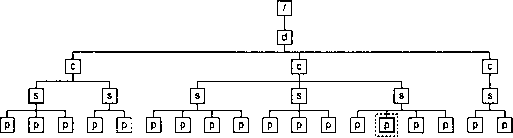

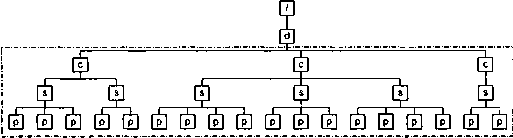

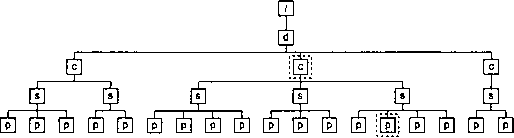
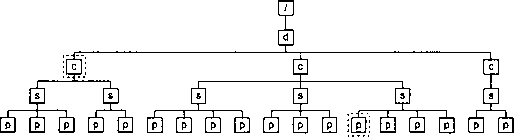



})



 Книжный Вестник
Книжный Вестник
 Поиск книг
Поиск книг
 Любовные романы
Любовные романы
 Саморазвитие
Саморазвитие
 Детективы
Детективы
 Фантастика
Фантастика
 Классика
Классика
 ВКОНТАКТЕ
ВКОНТАКТЕ