которое возвращало непустое множество только тогда, когда элемент не был первым в группе.
В этом разделе мы приведем гораздо более эффективное и остроумное решение задачи группировки, впервые предложенное Стивом Мюнхом (Steve Muench), техническим гуру из Oracle Corporation. Оно основывается на двух посылках.
□ Мы можем выбрать множество узлов по их свойствам при помощи ключей.
□ Мы можем установить, является ли узел первым узлом множества в порядке просмотра документа при помощи функции
generate-id
.
С первым пунктом все, пожалуй, ясно — выбор множества узлов по определенному критерию — это самое прямое предназначение ключей. Второй же пункт оставляет легкое недоумение: функция
generate-id
вроде бы предназначена только для генерации уникальных значений.
Для того чтобы развеять все сомнения, напомним, как ведет себя эта функция, если аргументом является множество узлов. В этом случае
generate-id
возвращает уникальный идентификатор первого в порядке просмотра документа узла переданного ей множества. Значит для того, чтобы проверить, является ли некий узел первым узлом группы, достаточно сравнить его уникальный идентификатор со значением выражения
generate-id($group)
, где
$group
— множество узлов этой группы.
С учетом приведенных выше возможностей группирующее преобразование переписывается удивительно элегантным образом.
Результат выполнения этого преобразования уже был приведен в листинге 11.2.
Перечисление узлов
Функции
name
и
local-name
предоставляют возможности для работы с документом, имена элементов и атрибутов в котором заранее неизвестны. Например, если шаблон определен как:
...
то обрабатываться им будут все элементы, локальные части имен которых начинаются на
"чеб"
(например,
"чебуреки"
,
"Чебоксары"
,
"чебурашка"
).
Следующее преобразование демонстрирует, как при помощи функции
local-name
и ключей сосчитать количество элементов и атрибутов документа с различными именами.
Листинг 11.4. Входящий документ
Листинг 11.5. Преобразование
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
Node '
' found
times.
Листинг 11.6. Выходящий документ
Node 'foo' found 5 times.
Node 'bar' found 7 times.
Именованный шаблон как функция
Сложно переоценить возможности механизмов расширений языка XSLT. Они позволяют сочетать простоту и гибкость обработки XML-документов при помощи элементов XSLT и выражений XPath. Практически любая функция, которая отсутствует в XSLT, может быть написана на подходящем языке программирования и подключена к процессору.
Но как уже отмечалось ранее, функции расширения ограничивают переносимость преобразований. Во-первых, функции расширения одного процессора совсем необязательно будут присутствовать в другом процессоре — скорее наоборот. Во-вторых, не приходится надеяться, что пользовательские модули, написанные на одном языке или с использованием одного интерфейса, смогут использоваться любым процессором. Поэтому часто перед разработчиком стоит проблема решить определенную задачу, используя только стандартные функции и элементы XSLT.
В этом разделе мы рассмотрим возможность использования именованных шаблонов в качестве функций, которые принимают на вход несколько параметров и возвращают некоторое вычисленное значение.
Использование именованных шаблонов как функций обуславливается следующими тезисами.
□ Именованный шаблон можно вызывать вне зависимости от того, какая часть документа обрабатывается в данный момент.
□ Именованному шаблону можно передавать параметры.
□ Результат выполнения именованного шаблона можно присваивать переменной.
Вызов именованного шаблона выполняется элементом
xsl:call-template
, в атрибуте
name
которого указывается имя вызываемого шаблона. Такой вызов не зависит от того, какая часть документа обрабатывается в данный момент и может производиться по необходимости.
Параметры именованному шаблону передаются точно так же, как и обычному — при помощи элементов
xsl:with-param
, которые могут быть включены в вызывающий элемент
xsl:call-template
. Примером вызова именованного шаблона с параметрами может быть конструкция вида
которая вызывает шаблон с именем
foo
и передает ему параметр
x
со значением, равным
1
и параметр
y
со значением, равным
2
.
Вызов именованного шаблона может также производиться при инициализации переменной — внутри элемента xsl:variable. В этом случае с переменной связывается результирующий фрагмент дерева, возвращаемый именованным шаблоном.
Пример
В качестве примера приведем простой шаблон, который вычисляет квадрат переданного ему параметра
x
:
Для того чтобы присвоить переменной
у
квадрат числа
6
мы можем записать следующее:
Обратим внимание, что значение переменной
y
будет иметь вовсе не численный тип. Несмотря на то, что элемент
выведет строку "
36
", переменная у содержит не число, а дерево, и
36
лишь является результатом конвертации в строку при выполнении
xsl:value-of
.
Для того чтобы присвоить переменной результат выполнения именованного шаблона в виде булевого значения, строки или числа, следует воспользоваться промежуточной переменной для явного преобразования типов.
Пример
После выполнения действий
переменные
sqr-string
и
sqr-number
будут содержать строковое и численное значение результата вычисления соответственно.
Немного сложнее обстоит дело с булевым типом. При приведении дерева к булевому типу результатом всегда будет "истина", поэтому такое преобразование необходимо выполнить в два шага: сначала преобразовать дерево в число, только затем число в булевый тип.
Пример
В следующем преобразовании шаблон с именем
less-than
сравнивает значения параметров
x
и
y
. Переменной
less-than
присваивается булевое значение результата сравнения.
Листинг 11.7. Вычисление булевого значения функции
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
Пример
Простым примером шаблона-функции может быть шаблон, который форматирует дату в нужном виде, например 7 августа 93 года как "
07-Aug-1993
".
В качестве параметров этот шаблон будет принимать численные значения дня, месяца и года. Год, имеющий значение меньшее 25, мы будем считать принадлежащим новому тысячелетию.
Листинг 11.8. Шаблон, форматирующий дату
-
Jan
Feb
Mar
Apr
May
Jun
Jul
Aug
Sen
Oct
Nov
Dec
-
Рекурсия
Отсутствие в XSLT изменяемых переменных (оценим красоту этой тавтологии) как, впрочем, и многое другое, делает этот язык совершенно непохожим на многие классические языки программирования. В этом разделе мы опишем рекурсию [Кормен и др. 2000, Кнут 2000] — чрезвычайно простую, но в то же время исключительно мощную технику, которая в большинстве случаев компенсирует нехватку в XSLT переменных и других процедурных конструкций.
Не вдаваясь в строгие определения дискретной математики, можно сказать, что рекурсия это всего лишь описание объекта или вычисления в терминах самого себя. Пожалуй, самым простым примером рекурсии является факториал, функция, которая математически определяется как:
0!=1
n!=n×(n-1)!
Программа на процедурном языке (например, таком, как Java), вычисляющая факториал совершенно тривиальна:
int factorial(int n) {
if (n == 0) return 1;
else return n * factorial(n-1);
}
Попробуем запрограммировать факториал на XSLT. Мы уже научились создавать собственные функции (вернее, конструкции, похожие на них) с помощью одних только именованных шаблонов, значит написать функцию, которая бы вызывала сама себя, будет не так уж и сложно.
мы получим текстовый узел, значение которого будет равно "
720
".
Очевидным требованием к рекурсивным функциям является возможность выхода из рекурсии. Если бы в определении факториала не было указано, что 0!=1, вычисления так бы и продолжались без конца.
Главным минусом рекурсии является требовательность к ресурсам. Каждый раз, при вызове именованного шаблона, процессор должен будет каким-то образом сохранять в памяти передаваемые ему формальные параметры. Например, если мы попробуем сосчитать факториал от 170, процессору понадобится держать в памяти сразу 170 чисел. Безусловно, в случае с факториалом это не является большой проблемой — точность 64-битных чисел исчерпается гораздо раньше, чем закончится память, но в случае хранения в переменных действительно больших объемов информации (например, частей деревьев) такая угроза существует. Кроме того, рекурсивные решения, как правило, работают медленнее, чем решения, не использующие рекурсию.
Так в чем же смысл использования рекурсии? Дело в том, что вследствие определенных ограничений (связанных, в частности с неизменяемыми переменными) в XSLT существуют задачи, которые не могут быть реализованы иначе кроме как через рекурсию. Самым характерным примером такой задачи являются циклы.
Циклы
Цикл в общем смысле слова это повторение одних и тех же действий несколько раз. Если говорить об XSLT, то цикл это многократное выполнение одного и того же шаблона. Для подавляющего большинства случаев в преобразованиях достаточно бывает использовать такие элементы, как
xsl:apply-templates
и
xsl:for-each
, которые заставляют процессор выполнять одни и те же действия несколько раз в контексте каждого из узлов определенного множества.
Весомым ограничением такого рода циклической обработки является невозможность генерировать множества узлов. В текущей версии языка никакой другой тип не может быть приведен ко множеству узлов, значит, в любое из них могут входить только те узлы, которые изначально присутствуют в одном из обрабатываемых документов. Это означает, что ни
xsl:apply-templates
, ни
xsl:for-each
не могут быть использованы для того, чтобы реализовать простые
while
- или
for
-циклы для произвольных множеств.
Цикл while
Наиболее примитивной циклической конструкцией во многих языках программирования является цикл
while
(англ. пока). Цикл
while
, как правило, имеет следующий вид:
пока
верно условие
выполнять
действия
В качестве примера
while
-цикла напишем на языке Java программу вычисления факториала в итеративном стиле:
int factorial(int n) {
int i = n;
int result = 1;
while (i != 0) {
result = result * i;
i--;
}
return result;
}
В этой функции
условием
является отличие значения переменной
i
от 0, а действиями — умножение значения переменной
result
на значение переменной
i
, и уменьшение значения этой переменной на 1.
Цикл
while
не может быть запрограммирован в XSLT итеративно потому как действия, как правило, изменяют значения переменных, в контексте которых вычисляется условие, определяющее, продолжать выполнение цикла или нет. Дадим другую общую запись цикла
while
, выделив изменение переменных:
пока
верно условие(x1,x2, ...,xn)
выполнить
x1' := функция1(x1,x2,...,xn)
х2' := функция2(x1,x2,...,xn)
...
xn' := функцияn(x1,x2,...,xn)
действия(x1,x2,...,хn)
x1 := x1'
x2 := x2'
...
xn := xn'
иначе
вернуть результат(x1,...,хn)
Переопределение значений переменных
x
1, … ,
х
n в этом случае выполняют
n
функций:
функция
1 …,
функция
n. И если изменить значение переменной мы не могли, переопределить связанное с ней значение мы вполне в состоянии, добавив в контекст новый параметр или переменную с тем же именем.
Теперь мы можем записать весь цикл
while
как одну рекурсию:
while(x1, ..., xn) ::=
если
выполняется условие(x1, ..., xn)
то
действия(x1, ..., хn)
while(функция1(x1, ..., хn),
функция2(x1, ..., хn),
...,
функцияn(x1, ..., xn))
иначе
результат(x1, ..., хn)
Теперь уже совершенно очевидно, как
while
-цикл должен выглядеть в преобразовании.
Листинг 11.10. Шаблон цикла while в общем виде
В качестве примера приведем
while
-цикл для программы, вычисляющей факториал. Java-код был следующим:
while (i != 0) {
result = result * i;
i--;
}
В этом цикле участвуют две переменные —
i
и
result
. Функции, использующиеся в этом цикле, запишутся следующим образом:
условие($1, $result) ::= ($i != 0)
функцияi($i, $result) ::= ($i - 1)
функцияresult($i, $result) ::= ($i * $result)
результат($I, $result) ::= ($result)
Именованный шаблон для этого случая будет иметь вид.
Листинг 11.11. Пример шаблона цикла while
Вызвать этот шаблон можно следующим образом:
Результатом будет, естественно, число
720
.
Цикл for
Частным случаем цикла
while
является цикл
for
. В разных языках программирования
for
имеет различную семантику; мы будем рассматривать циклы
for
вида
for (int i = 0; i < n; i++) { ... }
в языках Java и С или
for i := 0 to n-1 do begin ... end;
в Pascal. Иными словами, нас будет интересовать циклическое выполнение определенных действий при изменении значения некоторой переменной (называемой иногда индексом цикла) в интервале целых чисел от 0 до n включительно.
Цикл
for
может быть определен через
while
с использованием следующих условных и изменяющих функций:
условие($i, $n,$x1,...,$хk) :: = ($i < $n)
функцияi($i, $n, $x1, ... , $xk) ::= ($i + 1)
функцияn($i, $n, $x1, ..., $xk) :: = ($n)
Шаблон цикла
for
в общем виде будет выглядеть как.
Листинг 11.12. Шаблон цикла for в общем виде
функция1($i, $n, $x1, ..., $xk) "/>
В качестве примера цикла
for
приведем шаблон, вычисляющий
n
первых чисел Фибоначчи.
Числа Фибоначчи — это рекуррентная последовательность вида
1 1 2 3 5 8 13 21 ...
и так далее, где каждое последующее число определяется как сумма двух предыдущих.
Для вычисления
n
первых чисел Фибоначчи мы можем использовать две переменные
current
и
last
, соответствующих текущему число и числу, полученному на предыдущем шаге соответственно. Функции, переопределяющие эти переменные, совершенно очевидны:
Пожалуй, этим примером мы и закончим рассмотрение рекурсии. Осталось лишь добавить, что при всей своей простоте и вычислительной мощи, рекурсия является гораздо более требовательной к ресурсам техникой программирования, чем обычная итеративная обработка. Поэтому всегда следует тщательно оценивать, во что может вылиться использование рекурсии. В любом случае следует избегать глубоких рекурсий (функций, количество рекурсивных вызовов в которых может быть большим) и рекурсий, неэкономно использующих память.
Кроме того, большинство действий, выполнение которых в XSLT затруднено, в классических языках программирования выполняется, как правило, намного легче и эффективней. Поэтому, каждый раз, когда стоит вопрос об использовании рекурсии, наряду с ней следует рассматривать такую альтернативу, как использование расширений XSLT, написанных на обычном императивном языке.
Метод Пиза для for-цикла
Для простых
for
-циклов, которые должны выполниться строго определенное число раз, вместо рекурсии можно использовать весьма остроумный метод, предложенный Венделлом Пизом (Wendell Piez, Mullberry Technologies, Inc). Суть метода состоит в том, что хоть мы и не можем сгенерировать множество узлов, выбрать множество с определенным количеством узлов нам вполне по силам.
Для начала выберем какое-нибудь множество узлов документа преобразования:
Затем для повторения определенных действий несколько раз используем конструкцию вида
где
number
указывает требуемое число итераций.
При использовании метода Пиза следует учитывать следующие особенности.
□ Множество узлов
set
не должно быть слишком большим — иначе его выбор будет неэффективным.
□ Множество узлов
set
обязательно должно содержать число итераций (
number
) узлов.
В целом же метод Пиза — классический пример эффективного применения инструментов не по назначению.
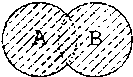
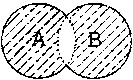
Операции над множествами
Рассматривая такой тип данных, как множества узлов, мы отмечали ограниченность операций, которые можно с ними производить. В частности, XSLT не предоставляет стандартных операторов для определения принадлежности одного множества другому, нахождения пересечений, разности множеств и так далее. Возможности, которые были представлены при описании этого типа данных, основанные на использовании оператора равенства, на самом деле реализуют далеко не математические операции над множествами.
В этом разделе мы рассмотрим иной подход к реализации операций над множествами, основанный на очень простом определении принадлежности узла множеству. Узел
node
принадлежит множеству
nodeset
тогда и только тогда, когда выполняется равенство
count($nodeset) = count($node | $nodeset)
Учитывая это обстоятельство, операции над множествами можно представить, как показано в табл. 11.1. Результирующее множество выделено штриховкой.
Приведенные выше методы были разработаны Майклом Кеем (Michael Kay, Software AG), Оливером Беккером (Oliver Becker, Humboldt-Universitat zu Berlin), Кеном Холманом (Ken Holman, Crane Softwrights Ltd.) и публикуются с любезного разрешения авторов.
Перенос строк и элементы BR
Большинству читателей, скорее всего, хорошо знаком такой элемент языка HTML, как
BR
, который используется для обозначения разрыва строки. В обычных текстовых файлах для той же самой цели используются символы с кодами
#xA
,
#xD
или их комбинации в зависимости от платформы. При совместном использовании неразмеченного текста и HTML часто возникает задача преобразования символов перевода строки в элементы
BR
и наоборот.
Замену элемента
BR
на текстовый узел, содержащий перевод строки, можно проиллюстрировать следующим тривиальным шаблоном.
Листинг 11.16. Шаблон замены элементов BR на перенос строки
Гораздо сложнее написать шаблон, делающий обратную операцию, — замену символов переноса строки на элементы BR. В XSLT нет встроенного механизма для замены подстроки в строке (тем более на элемент), поэтому нам придется создать для этой цели собственный шаблон.
Для этой цели мы можем воспользоваться функциями
substring-before
и
substring-after
. Функция
substring-before($str, $search-for)
возвратит часть строки
str
, которая предшествует первому вхождению в нее подстроки
search-for
, а функция
substring-after($str, $search-for)
— последующую часть. То есть заменить первое вхождение можно шаблоном вида
Для того же, чтобы заменить все вхождения, достаточно рекурсивно повторить операцию замены первого вхождения с той частью строки, которая следует за ним. Приведем шаблон, который выполняет эту операцию.
Листинг 11.17. Шаблон для замены подстроки в строке
select="substring-after($str, $search-for)"/>
Шаблон, приведенный в этом листинге, может быть вызван двумя способами: элементом
xsl:apply-templates
в режиме
replace
(в этом случае он будет обрабатывать текстовые узлы выбранного множества), или при помощи именного вызова элементом
xsl:call-template
. Шаблон принимает на вход три параметра.
□ Параметр
str
, содержащий строку, в которой нужно произвести замену. По умолчанию этому параметру присваивается текстовое значение текущего узла.
□ Параметр
search-for
, содержащий подстроку, которую требуется найти и заменить в строке
str
. По умолчанию замене будут подлежать символы переноса строки, "
&#хА;
".
□ Параметр
replace-with
, содержащий объект, на который следует заменять подстроки
search-for
. По умолчанию эти подстроки будут заменяться на элемент
BR
и следующий за ним перенос строки, добавленный для лучшей читаемости.
В качестве примера отформатируем содержание следующего элемента:
One little rabbit
Two little rabbits
Three little rabbits
Запишем шаблон для обработки элемента
pre
:
Результат его выполнения будет иметь следующий вид:
One little rabbit
Two little rabbits
Three little rabbits
Данные, разделенные запятыми (CSV)
Рекурсивную методику замены, которую мы представили выше, можно использовать для того, чтобы разметить данные, разделенные запятыми (или CSV, comma-separated values). CSV — это старый простой формат представления данных, в котором они просто перечисляются через запятую, например:
a, b, с, d, e, f, g
и так далее. Формат CSV был одним из первых шагов к созданию языков разметки: данные в нем уже размечались запятыми.
Покажем на простом примере, как можно преобразовать CSV-данные в XML-документ. Пусть входящий документ выглядит как:
a, b, с, d, e, f
Для того чтобы решение было как можно более общим, вынесем создание XML-разметки для каждого из элементов этой последовательности в отдельный шаблон:
Тогда головной размечающий шаблон запишется в виде.
Листинг 11.18. Шаблон, размечающий данные в строковом формате
select="substring-before($str, $delimiter)"/>
select="substring-after($str, $delimiter)"/>
На вход шаблон markup принимает два параметра —
str
, строка, которую нужно разметить (по умолчанию — значение текущего узла) и
delimiter
— строка, разделяющая отдельные значения в
str
(по умолчанию — запятая "
,
").
Шаблон, форматирующий содержимое элемента
data
, будет в таком случае выглядеть следующим образом:
Результат этого преобразования будет иметь следующий вид:
a
b
c
d
e
f
Обратим внимание на то, что в элементах
item
присутствуют лишние пробелы, которые в начальной последовательности шли за запятыми. Избавиться от них можно, указав в качестве разделяющей строки символ "
,
":
Результатом, как и следовало ожидать, будет:
a
b
c
d
e
f
Кстати сказать, того же эффекта можно было добиться, изменив шаблон
item
, который отвечает за XML-представление каждого из элементов последовательности.


 Книжный Вестник
Книжный Вестник
 Поиск книг
Поиск книг
 Любовные романы
Любовные романы
 Саморазвитие
Саморазвитие
 Детективы
Детективы
 Фантастика
Фантастика
 Классика
Классика
 ВКОНТАКТЕ
ВКОНТАКТЕ